 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward Accurate Person-level Action Recognition in Videos of Crowded Scenes
Oct 16, 2020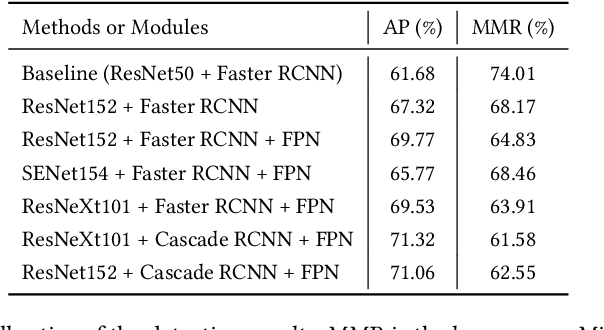
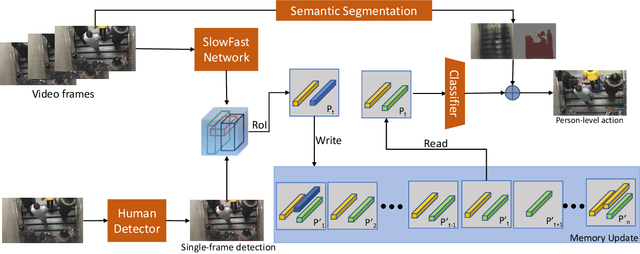
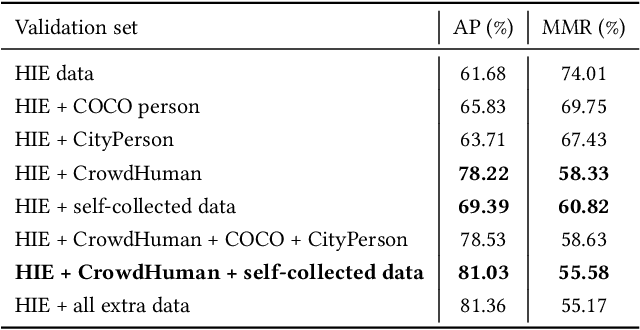

Detecting and recognizing human action in videos with crowded scenes is a challenging problem due to the complex environment and diversity events. Prior works always fail to deal with this problem in two aspects: (1) lacking utilizing information of the scenes; (2) lacking training data in the crowd and complex scenes. In this paper, we focus on improving spatio-temporal action recognition by fully-utilizing the information of scenes and collecting new data. A top-down strategy is used to overcome the limitations. Specifically, we adopt a strong human detector to detect the spatial location of each frame. We then apply action recognition models to learn the spatio-temporal information from video frames on both the HIE dataset and new data with diverse scenes from the internet, which can improve the generalization ability of our model. Besides, the scenes information is extracted by the semantic segmentation model to assistant the process. As a result, our method achieved an average 26.05 wf\_mAP (ranking 1st place in the ACM MM grand challenge 2020: Human in Events).
* 1'st Place in ACM Multimedia Grand Challenge: Human in Events, Track4: Person-level Action Recognition in Complex Events
Towards Theoretically Understanding Why SGD Generalizes Better Than ADAM in Deep Learning
Oct 12, 2020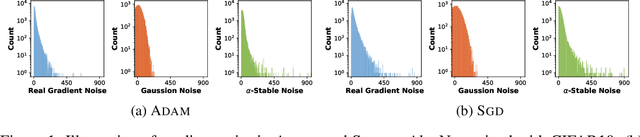
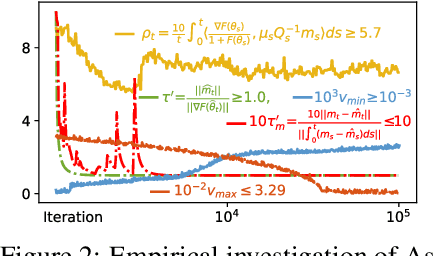

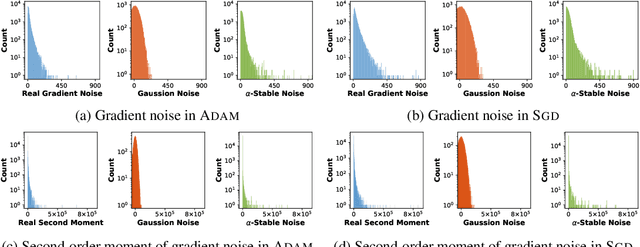
It is not clear yet why ADAM-alike adaptive gradient algorithms suffer from worse generalization performance than SGD despite their faster training speed. This work aims to provide understandings on this generalization gap by analyzing their local convergence behaviors. Specifically, we observe the heavy tails of gradient noise in these algorithms. This motivates us to analyze these algorithms through their Levy-driven stochastic differential equations (SDEs) because of the similar convergence behaviors of an algorithm and its SDE. Then we establish the escaping time of these SDEs from a local basin. The result shows that (1) the escaping time of both SGD and ADAM~depends on the Radon measure of the basin positively and the heaviness of gradient noise negatively; (2) for the same basin, SGD enjoys smaller escaping time than ADAM, mainly because (a) the geometry adaptation in ADAM~via adaptively scaling each gradient coordinate well diminishes the anisotropic structure in gradient noise and results in larger Radon measure of a basin; (b) the exponential gradient average in ADAM~smooths its gradient and leads to lighter gradient noise tails than SGD. So SGD is more locally unstable than ADAM~at sharp minima defined as the minima whose local basins have small Radon measure, and can better escape from them to flatter ones with larger Radon measure. As flat minima here which often refer to the minima at flat or asymmetric basins/valleys often generalize better than sharp ones~\cite{keskar2016large,he2019asymmetric}, our result explains the better generalization performance of SGD over ADAM. Finally, experimental results confirm our heavy-tailed gradient noise assumption and theoretical affirmation.
RVL-BERT: Visual Relationship Detection with Visual-Linguistic Knowledge from Pre-trained Representations
Sep 10, 2020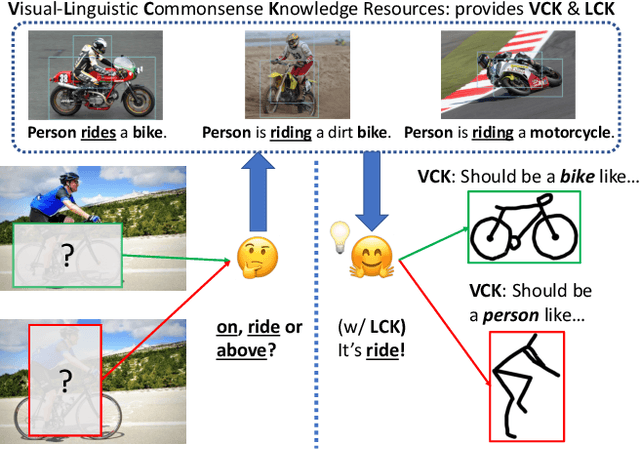

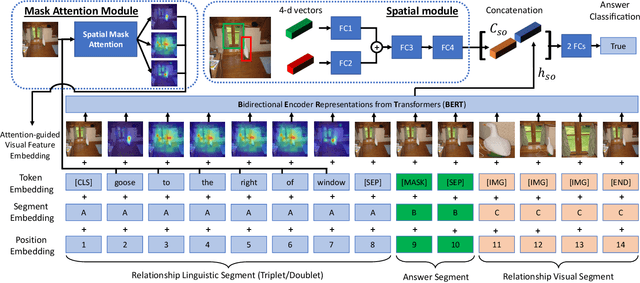
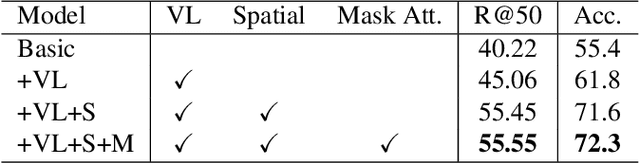
Visual relationship detection aims to reason over relationships among salient objects in images, which has drawn increasing attention over the past few years. Inspired by human reasoning mechanism, it is believed that external visual commonsense knowledge is beneficial for reasoning visual relationships of objects in images, which is however rarely considered in existing methods. In this paper, we propose a novel approach named Relational Visual-Linguistic Bidirectional Encoder Representations from Transformers (RVL-BERT), which performs relational reasoning with both visual and language commonsense knowledge learned via self-supervised pre-training with multimodal representations. RVL-BERT also uses an effective spatial module and a novel mask attention module to explicitly capture spatial information among the objects. Moreover, our model decouples object detection from visual relationship recognition by taking in object names directly, enabling it to be used on top of any object detection system. We show through quantitative and qualitative experiments that, with the transferred knowledge and novel modules, RVL-BERT surpasses previous state-of-the-art on two challenging visual relationship detection datasets. The source code will be publicly available soon.
Dual Adversarial Auto-Encoders for Clustering
Aug 23, 2020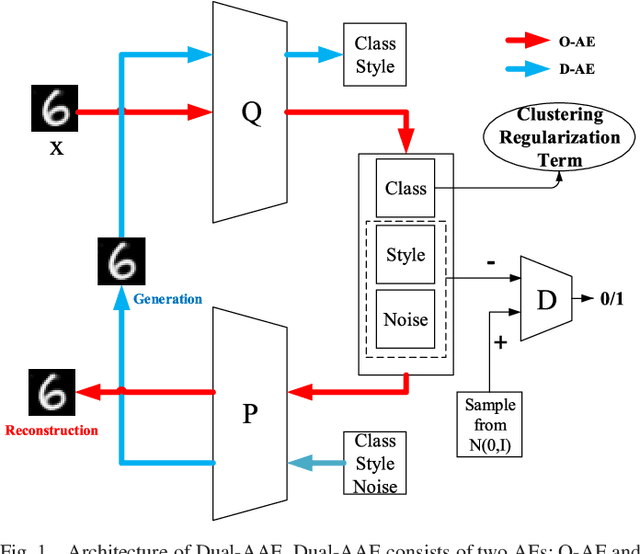
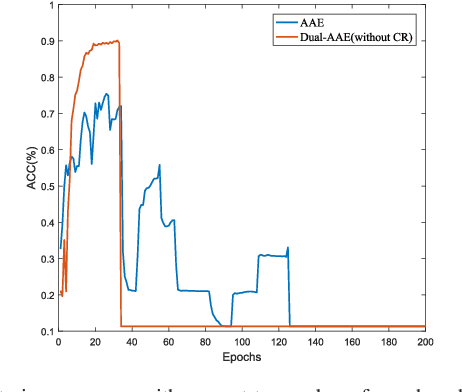
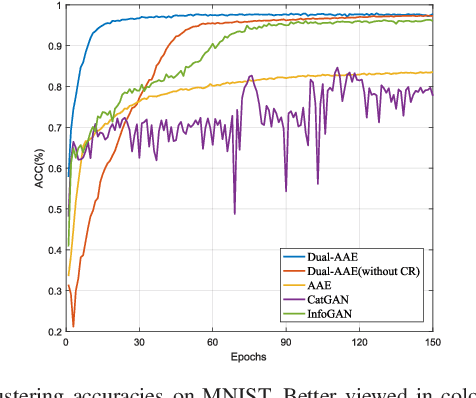

As a powerful approach for exploratory data analysis, unsupervised clustering is a fundamental task in computer vision and pattern recognition. Many clustering algorithms have been developed, but most of them perform unsatisfactorily on the data with complex structures. Recently, Adversarial Auto-Encoder (AAE) shows effectiveness on tackling such data by combining Auto-Encoder (AE) and adversarial training, but it cannot effectively extract classification information from the unlabeled data. In this work, we propose Dual Adversarial Auto-encoder (Dual-AAE) which simultaneously maximizes the likelihood function and mutual information between observed examples and a subset of latent variables. By performing variational inference on the objective function of Dual-AAE, we derive a new reconstruction loss which can be optimized by training a pair of Auto-encoders. Moreover, to avoid mode collapse, we introduce the clustering regularization term for the category variable. Experiments on four benchmarks show that Dual-AAE achieves superior performance over state-of-the-art clustering methods. Besides, by adding a reject option, the clustering accuracy of Dual-AAE can reach that of supervised CNN algorithms. Dual-AAE can also be used for disentangling style and content of images without using supervised information.
ConvBERT: Improving BERT with Span-based Dynamic Convolution
Aug 06, 2020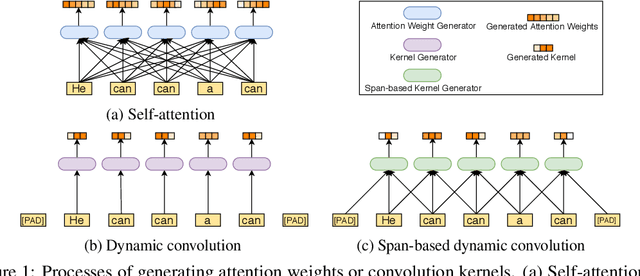
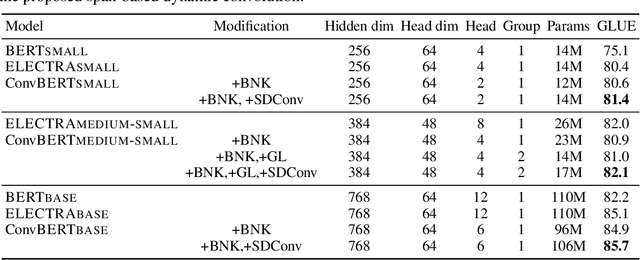
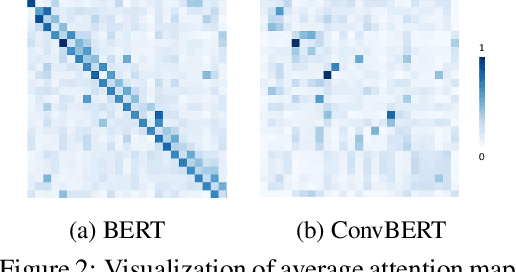
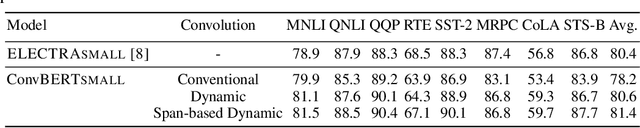
Pre-trained language models like BERT and its variants have recently achieved impressive performance in various natural language understanding tasks. However, BERT heavily relies on the global self-attention block and thus suffers large memory footprint and computation cost. Although all its attention heads query on the whole input sequence for generating the attention map from a global perspective, we observe some heads only need to learn local dependencies, which means the existence of computation redundancy. We therefore propose a novel span-based dynamic convolution to replace these self-attention heads to directly model local dependencies. The novel convolution heads, together with the rest self-attention heads, form a new mixed attention block that is more efficient at both global and local context learning. We equip BERT with this mixed attention design and build a ConvBERT model. Experiments have shown that ConvBERT significantly outperforms BERT and its variants in various downstream tasks, with lower training cost and fewer model parameters. Remarkably, ConvBERTbase model achieves 86.4 GLUE score, 0.7 higher than ELECTRAbase, while using less than 1/4 training cost. Code and pre-trained models will be released.
Few-shot Classification via Adaptive Attention
Aug 06, 2020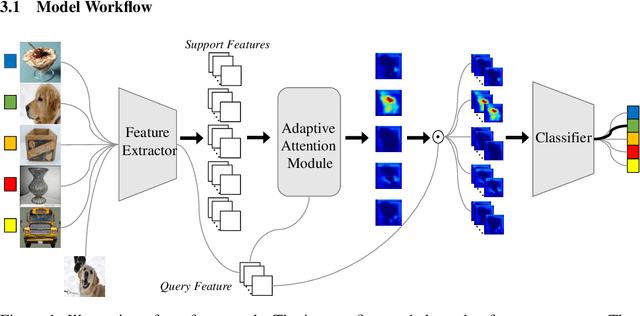
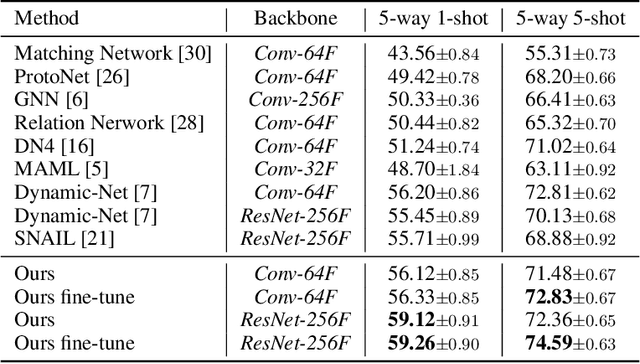
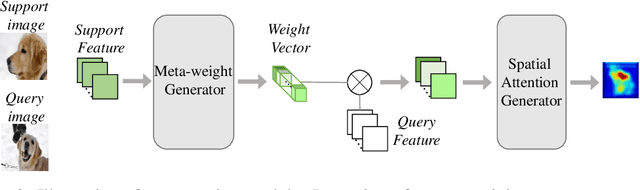
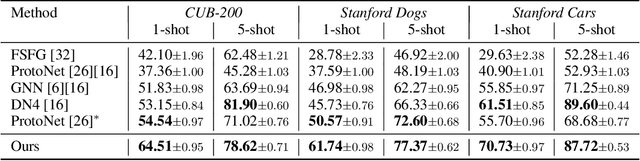
Training a neural network model that can quickly adapt to a new task is highly desirable yet challenging for few-shot learning problems. Recent few-shot learning methods mostly concentrate on developing various meta-learning strategies from two aspects, namely optimizing an initial model or learning a distance metric. In this work, we propose a novel few-shot learning method via optimizing and fast adapting the query sample representation based on very few reference samples. To be specific, we devise a simple and efficient meta-reweighting strategy to adapt the sample representations and generate soft attention to refine the representation such that the relevant features from the query and support samples can be extracted for a better few-shot classification. Such an adaptive attention model is also able to explain what the classification model is looking for as the evidence for classification to some extent. As demonstrated experimentally, the proposed model achieves state-of-the-art classification results on various benchmark few-shot classification and fine-grained recognition datasets.
The Devil is in Classification: A Simple Framework for Long-tail Instance Segmentation
Jul 31, 2020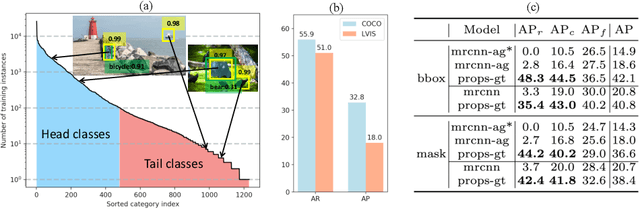

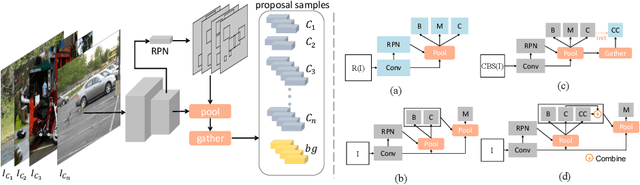
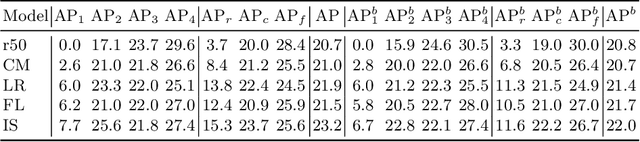
Most existing object instance detection and segmentation models only work well on fairly balanced benchmarks where per-category training sample numbers are comparable, such as COCO. They tend to suffer performance drop on realistic datasets that are usually long-tailed. This work aims to study and address such open challenges. Specifically, we systematically investigate performance drop of the state-of-the-art two-stage instance segmentation model Mask R-CNN on the recent long-tail LVIS dataset, and unveil that a major cause is the inaccurate classification of object proposals. Based on such an observation, we first consider various techniques for improving long-tail classification performance which indeed enhance instance segmentation results. We then propose a simple calibration framework to more effectively alleviate classification head bias with a bi-level class balanced sampling approach. Without bells and whistles, it significantly boosts the performance of instance segmentation for tail classes on the recent LVIS dataset and our sampled COCO-LT dataset. Our analysis provides useful insights for solving long-tail instance detection and segmentation problems, and the straightforward \emph{SimCal} method can serve as a simple but strong baseline. With the method we have won the 2019 LVIS challenge. Codes and models are available at \url{https://github.com/twangnh/SimCal}.
Adversarial Self-Supervised Learning for Semi-Supervised 3D Action Recognition
Jul 12, 2020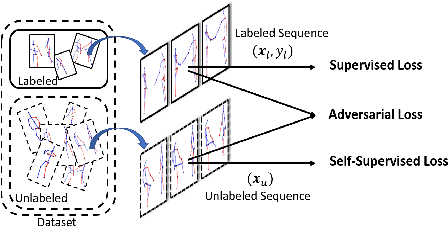
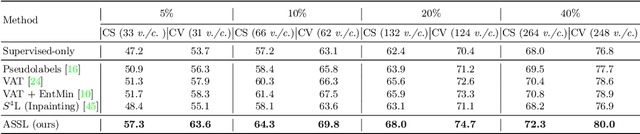
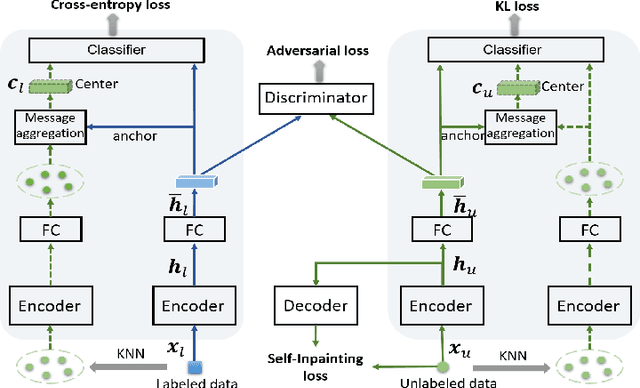
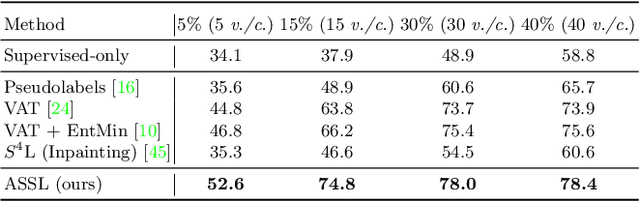
We consider the problem of semi-supervised 3D action recognition which has been rarely explored before. Its major challenge lies in how to effectively learn motion representations from unlabeled data. Self-supervised learning (SSL) has been proved very effective at learning representations from unlabeled data in the image domain. However, few effective self-supervised approaches exist for 3D action recognition, and directly applying SSL for semi-supervised learning suffers from misalignment of representations learned from SSL and supervised learning tasks. To address these issues, we present Adversarial Self-Supervised Learning (ASSL), a novel framework that tightly couples SSL and the semi-supervised scheme via neighbor relation exploration and adversarial learning. Specifically, we design an effective SSL scheme to improve the discrimination capability of learned representations for 3D action recognition, through exploring the data relations within a neighborhood. We further propose an adversarial regularization to align the feature distributions of labeled and unlabeled samples. To demonstrate effectiveness of the proposed ASSL in semi-supervised 3D action recognition, we conduct extensive experiments on NTU and N-UCLA datasets. The results confirm its advantageous performance over state-of-the-art semi-supervised methods in the few label regime for 3D action recognition.
Combating Domain Shift with Self-Taught Labeling
Jul 08, 2020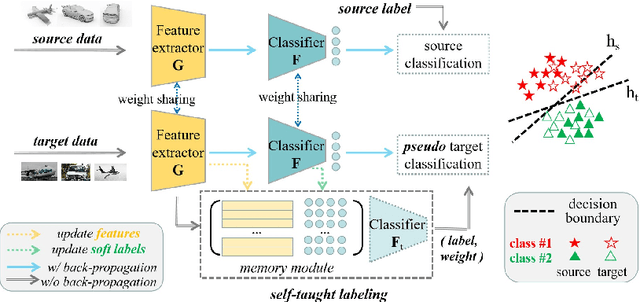
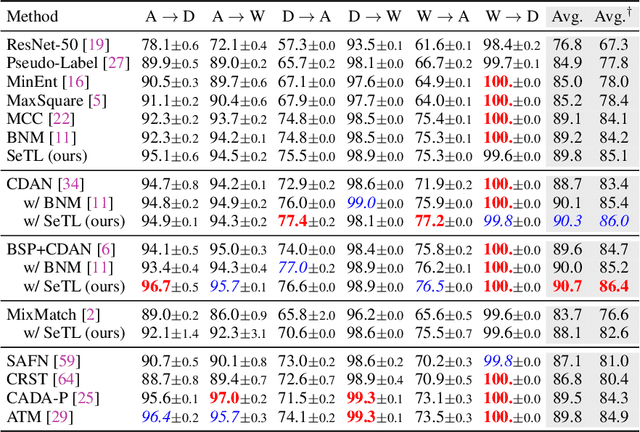
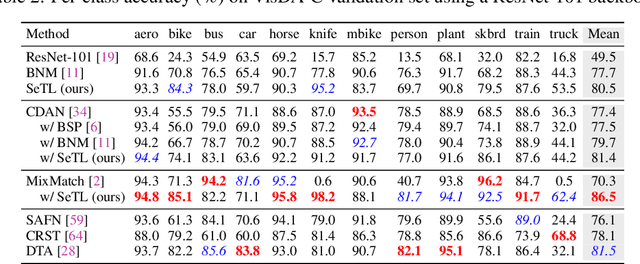
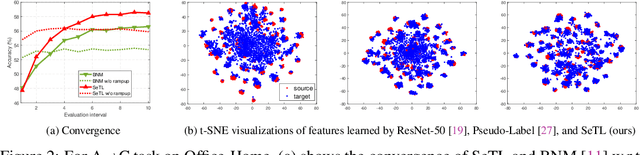
We present a novel method to combat domain shift when adapting classification models trained on one domain to other new domains with few or no target labels. In the existing literature, a prevailing solution paradigm is to learn domain-invariant feature representations so that a classifier learned on the source features generalizes well to the target features. However, such a classifier is inevitably biased to the source domain by overlooking the structure of the target data. Instead, we propose Self-Taught Labeling (SeTL), a new regularization approach that finds an auxiliary target-specific classifier for unlabeled data. During adaptation, this classifier is able to teach the target domain itself by providing \emph{unbiased accurate} pseudo labels. In particular, for each target data, we employ the memory bank to store the feature along with its soft label from the domain-shared classifier. Then we develop a non-parametric neighborhood aggregation strategy to generate new pseudo labels as well as confidence weights for unlabeled data. Though simply using the standard classification objective, SeTL significantly outperforms existing domain alignment techniques on a large variety of domain adaptation benchmarks. We expect that SeTL can provide a new perspective of addressing domain shift and inspire future research of domain adaptation and transfer learning.
Rethinking Bottleneck Structure for Efficient Mobile Network Design
Jul 07, 2020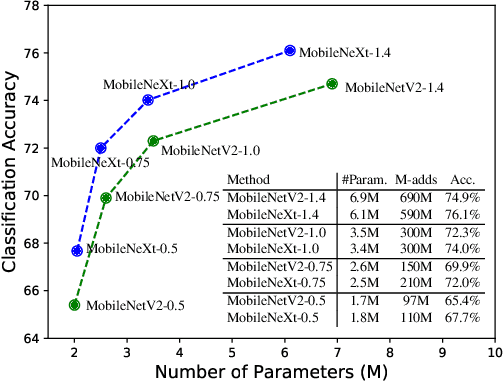

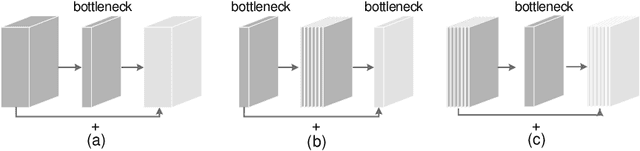
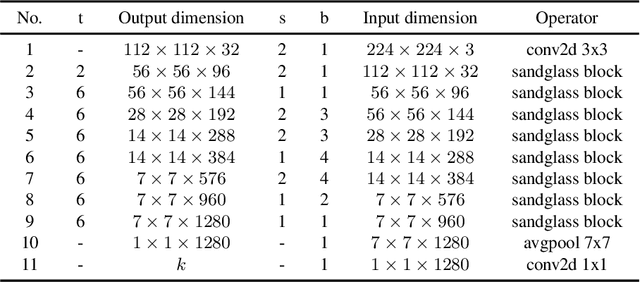
The inverted residual block is dominating architecture design for mobile networks recently. It changes the classic residual bottleneck by introducing two design rules: learning inverted residuals and using linear bottlenecks. In this paper, we rethink the necessity of such design changes and find it may bring risks of information loss and gradient confusion. We thus propose to flip the structure and present a novel bottleneck design, called the sandglass block, that performs identity mapping and spatial transformation at higher dimensions and thus alleviates information loss and gradient confusion effectively. Extensive experiments demonstrate that, different from the common belief, such bottleneck structure is more beneficial than the inverted ones for mobile networks. In ImageNet classification, by simply replacing the inverted residual block with our sandglass block without increasing parameters and computation, the classification accuracy can be improved by more than 1.7% over MobileNetV2. On Pascal VOC 2007 test set, we observe that there is also 0.9% mAP improvement in object detection. We further verify the effectiveness of the sandglass block by adding it into the search space of neural architecture search method DARTS. With 25% parameter reduction, the classification accuracy is improved by 0.13% over previous DARTS models. Code can be found at: https://github.com/zhoudaquan/rethinking_bottleneck_design.