 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOcean: Object-aware Anchor-free Tracking
Jul 09, 2020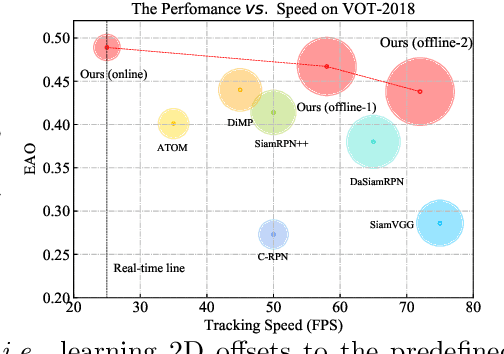
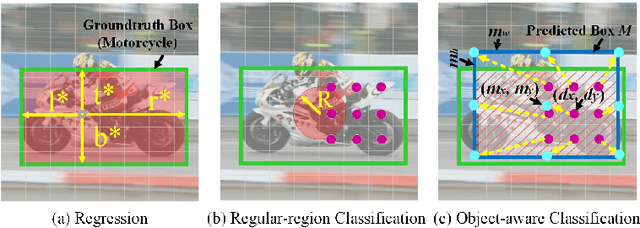
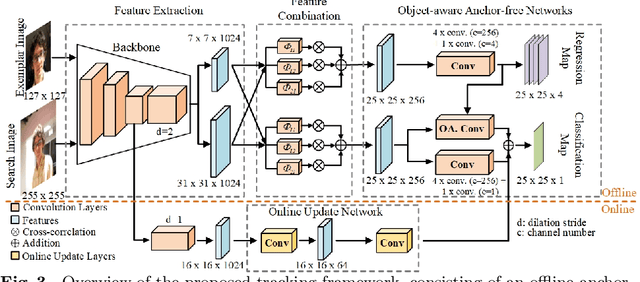
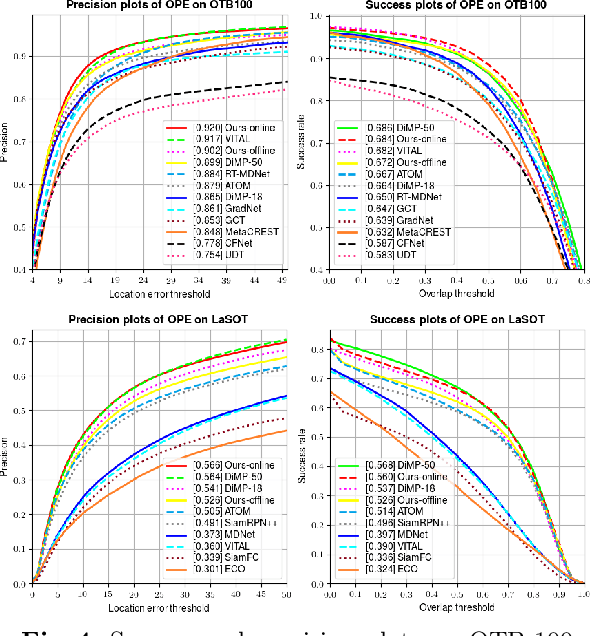
Anchor-based Siamese trackers have achieved remarkable advancements in accuracy, yet the further improvement is restricted by the lagged tracking robustness. We find the underlying reason is that the regression network in anchor-based methods is only trained on the positive anchor boxes (i.e., $IoU \geq0.6$). This mechanism makes it difficult to refine the anchors whose overlap with the target objects are small. In this paper, we propose a novel object-aware anchor-free network to address this issue. First, instead of refining the reference anchor boxes, we directly predict the position and scale of target objects in an anchor-free fashion. Since each pixel in groundtruth boxes is well trained, the tracker is capable of rectifying inexact predictions of target objects during inference. Second, we introduce a feature alignment module to learn an object-aware feature from predicted bounding boxes. The object-aware feature can further contribute to the classification of target objects and background. Moreover, we present a novel tracking framework based on the anchor-free model. The experiments show that our anchor-free tracker achieves state-of-the-art performance on five benchmarks, including VOT-2018, VOT-2019, OTB-100, GOT-10k and LaSOT. The source code is available at https://github.com/researchmm/TracKit.
* Accepted by ECCV2020
Learning Texture Transformer Network for Image Super-Resolution
Jun 22, 2020
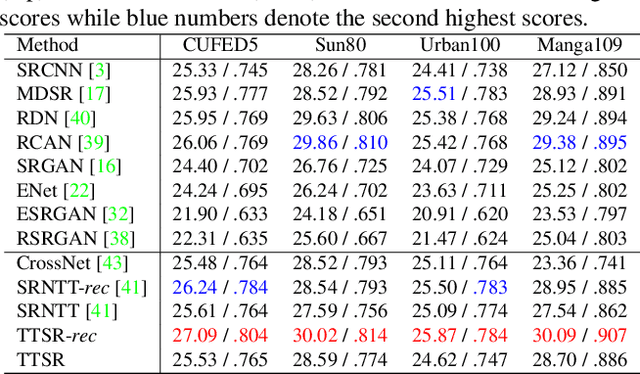
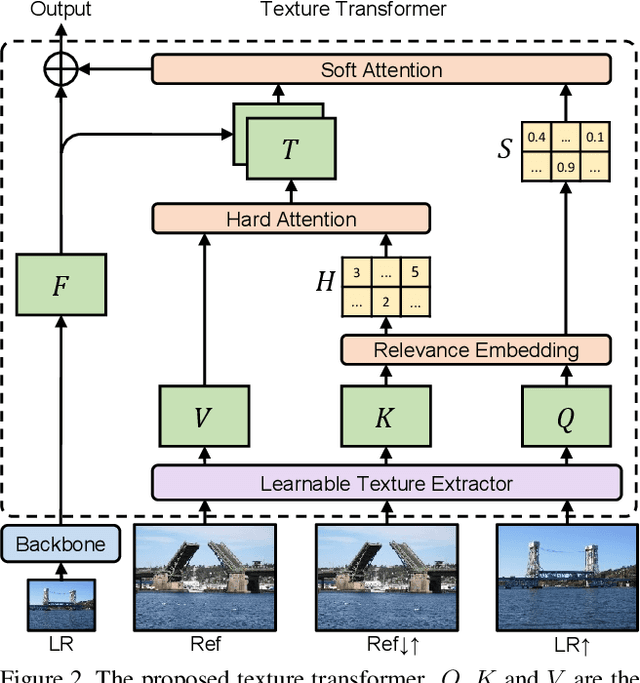
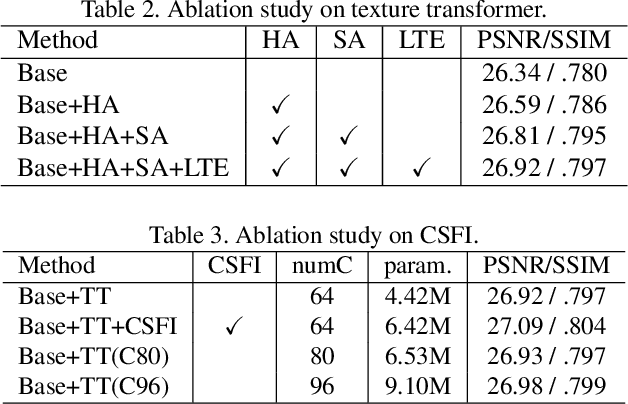
We study on image super-resolution (SR), which aims to recover realistic textures from a low-resolution (LR) image. Recent progress has been made by taking high-resolution images as references (Ref), so that relevant textures can be transferred to LR images. However, existing SR approaches neglect to use attention mechanisms to transfer high-resolution (HR) textures from Ref images, which limits these approaches in challenging cases. In this paper, we propose a novel Texture Transformer Network for Image Super-Resolution (TTSR), in which the LR and Ref images are formulated as queries and keys in a transformer, respectively. TTSR consists of four closely-related modules optimized for image generation tasks, including a learnable texture extractor by DNN, a relevance embedding module, a hard-attention module for texture transfer, and a soft-attention module for texture synthesis. Such a design encourages joint feature learning across LR and Ref images, in which deep feature correspondences can be discovered by attention, and thus accurate texture features can be transferred. The proposed texture transformer can be further stacked in a cross-scale way, which enables texture recovery from different levels (e.g., from 1x to 4x magnification). Extensive experiments show that TTSR achieves significant improvements over state-of-the-art approaches on both quantitative and qualitative evaluations.
M3P: Learning Universal Representations via Multitask Multilingual Multimodal Pre-training
Jun 04, 2020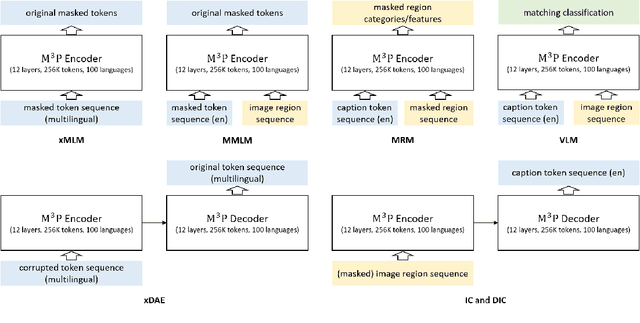


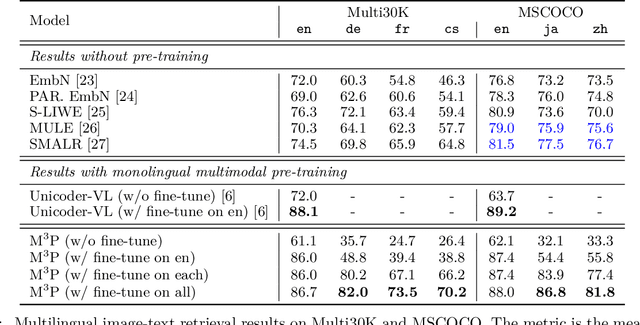
This paper presents a Multitask Multilingual Multimodal Pre-trained model (M3P) that combines multilingual-monomodal pre-training and monolingual-multimodal pre-training into a unified framework via multitask learning and weight sharing. The model learns universal representations that can map objects that occurred in different modalities or expressed in different languages to vectors in a common semantic space. To verify the generalization capability of M3P, we fine-tune the pre-trained model for different types of downstream tasks: multilingual image-text retrieval, multilingual image captioning, multimodal machine translation, multilingual natural language inference and multilingual text generation. Evaluation shows that M3P can (i) achieve comparable results on multilingual tasks and English multimodal tasks, compared to the state-of-the-art models pre-trained for these two types of tasks separately, and (ii) obtain new state-of-the-art results on non-English multimodal tasks in the zero-shot or few-shot setting. We also build a new Multilingual Image-Language Dataset (MILD) by collecting large amounts of (text-query, image, context) triplets in 8 languages from the logs of a commercial search engine
NTIRE 2020 Challenge on Perceptual Extreme Super-Resolution: Methods and Results
May 03, 2020
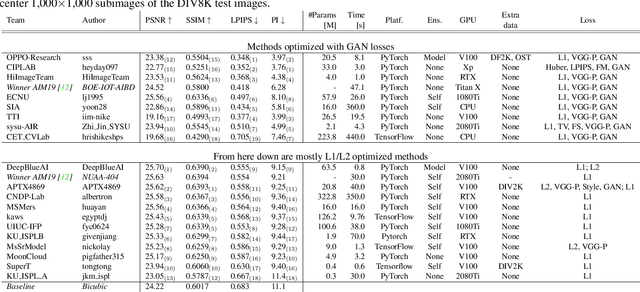

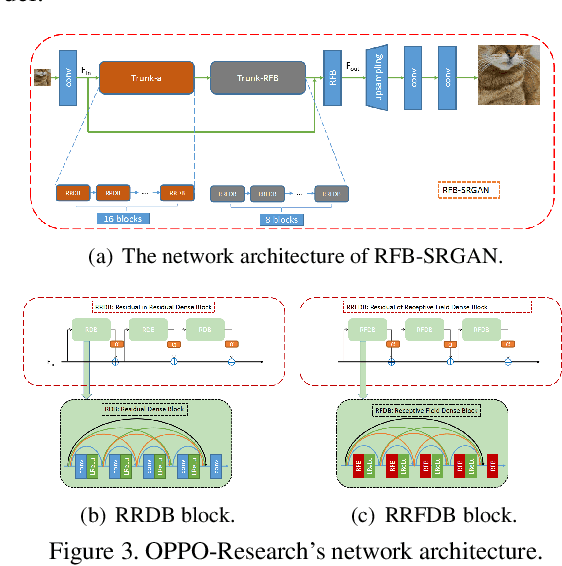
This paper reviews the NTIRE 2020 challenge on perceptual extreme super-resolution with focus on proposed solutions and results. The challenge task was to super-resolve an input image with a magnification factor 16 based on a set of prior examples of low and corresponding high resolution images. The goal is to obtain a network design capable to produce high resolution results with the best perceptual quality and similar to the ground truth. The track had 280 registered participants, and 19 teams submitted the final results. They gauge the state-of-the-art in single image super-resolution.
Pixel-BERT: Aligning Image Pixels with Text by Deep Multi-Modal Transformers
Apr 02, 2020
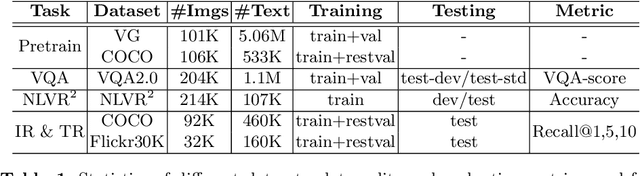
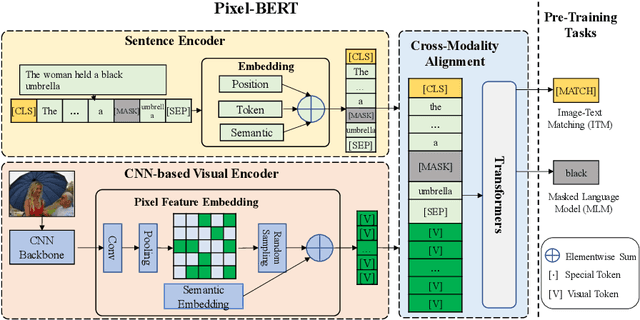
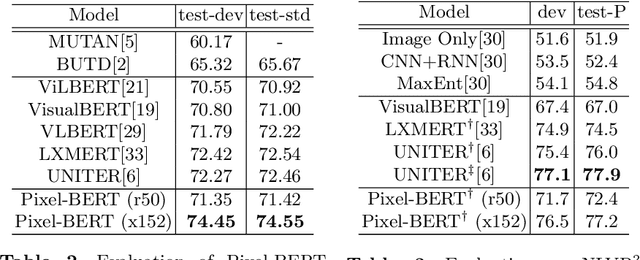
We propose Pixel-BERT to align image pixels with text by deep multi-modal transformers that jointly learn visual and language embedding in a unified end-to-end framework. We aim to build a more accurate and thorough connection between image pixels and language semantics directly from image and sentence pairs instead of using region-based image features as the most recent vision and language tasks. Our Pixel-BERT which aligns semantic connection in pixel and text level solves the limitation of task-specific visual representation for vision and language tasks. It also relieves the cost of bounding box annotations and overcomes the unbalance between semantic labels in visual task and language semantic. To provide a better representation for down-stream tasks, we pre-train a universal end-to-end model with image and sentence pairs from Visual Genome dataset and MS-COCO dataset. We propose to use a random pixel sampling mechanism to enhance the robustness of visual representation and to apply the Masked Language Model and Image-Text Matching as pre-training tasks. Extensive experiments on downstream tasks with our pre-trained model show that our approach makes the most state-of-the-arts in downstream tasks, including Visual Question Answering (VQA), image-text retrieval, Natural Language for Visual Reasoning for Real (NLVR). Particularly, we boost the performance of a single model in VQA task by 2.17 points compared with SOTA under fair comparison.
Learning Sparse 2D Temporal Adjacent Networks for Temporal Action Localization
Dec 08, 2019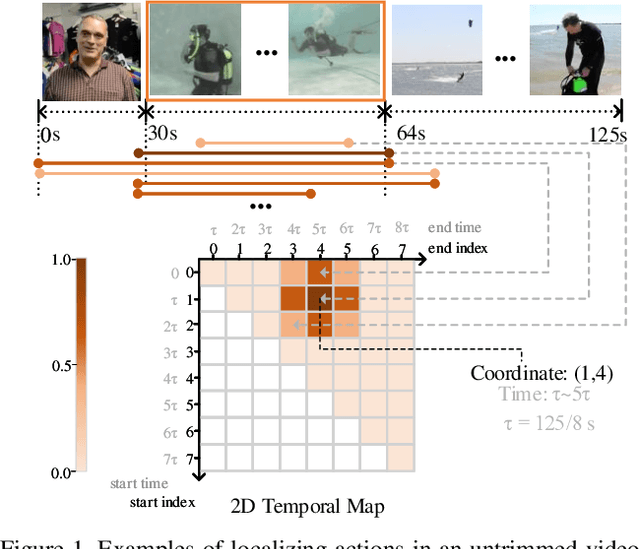
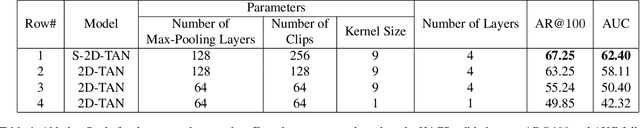
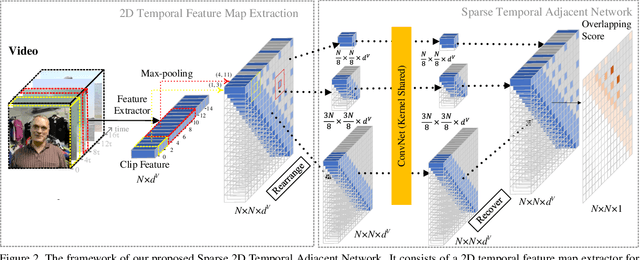
In this report, we introduce the Winner method for HACS Temporal Action Localization Challenge 2019. Temporal action localization is challenging since a target proposal may be related to several other candidate proposals in an untrimmed video. Existing methods cannot tackle this challenge well since temporal proposals are considered individually and their temporal dependencies are neglected. To address this issue, we propose sparse 2D temporal adjacent networks to model the temporal relationship between candidate proposals. This method is built upon the recent proposed 2D-TAN approach. The sampling strategy in 2D-TAN introduces the unbalanced context problem, where short proposals can perceive more context than long proposals. Therefore, we further propose a Sparse 2D Temporal Adjacent Network (S-2D-TAN). It is capable of involving more context information for long proposals and further learning discriminative features from them. By combining our S-2D-TAN with a simple action classifier, our method achieves a mAP of 23.49 on the test set, which win the first place in the HACS challenge.
Learning 2D Temporal Adjacent Networks for Moment Localization with Natural Language
Dec 08, 2019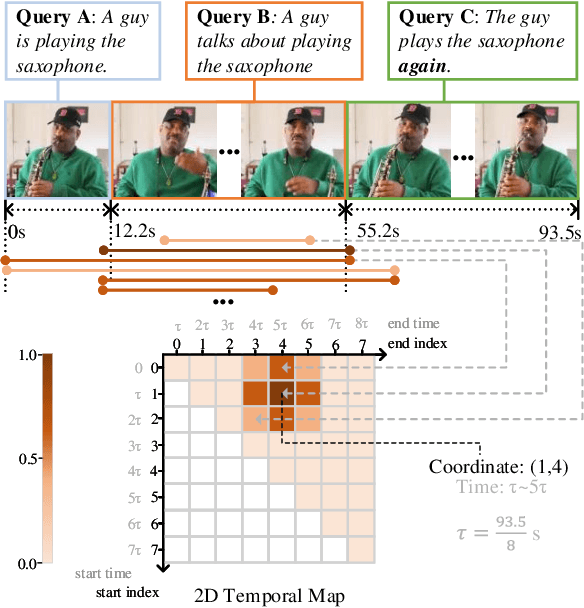
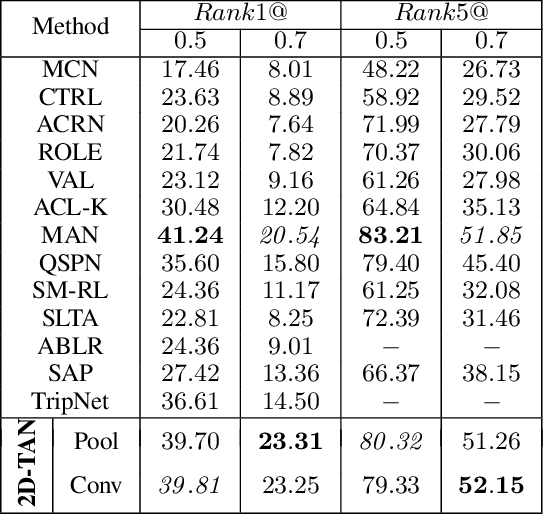
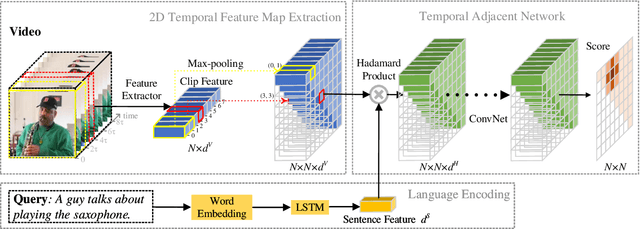
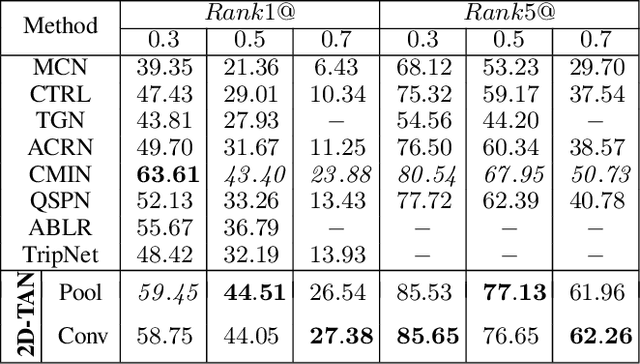
We address the problem of retrieving a specific moment from an untrimmed video by a query sentence. This is a challenging problem because a target moment may take place in relations to other temporal moments in the untrimmed video. Existing methods cannot tackle this challenge well since they consider temporal moments individually and neglect the temporal dependencies. In this paper, we model the temporal relations between video moments by a two-dimensional map, where one dimension indicates the starting time of a moment and the other indicates the end time. This 2D temporal map can cover diverse video moments with different lengths, while representing their adjacent relations. Based on the 2D map, we propose a Temporal Adjacent Network (2D-TAN), a single-shot framework for moment localization. It is capable of encoding the adjacent temporal relation, while learning discriminative features for matching video moments with referring expressions. We evaluate the proposed 2D-TAN on three challenging benchmarks, i.e., Charades-STA, ActivityNet Captions, and TACoS, where our 2D-TAN outperforms the state-of-the-art.
Neural Storyboard Artist: Visualizing Stories with Coherent Image Sequences
Nov 24, 2019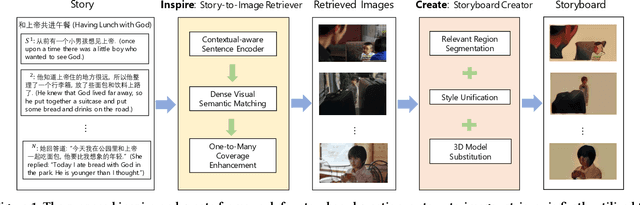
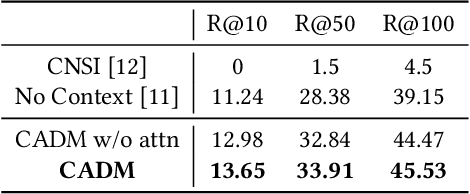
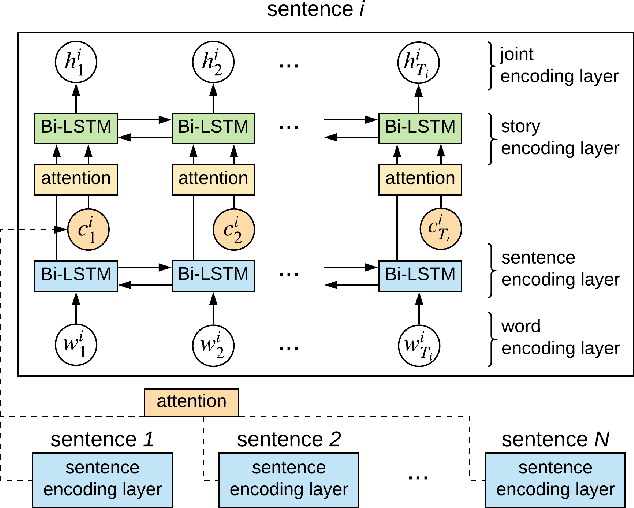
A storyboard is a sequence of images to illustrate a story containing multiple sentences, which has been a key process to create different story products. In this paper, we tackle a new multimedia task of automatic storyboard creation to facilitate this process and inspire human artists. Inspired by the fact that our understanding of languages is based on our past experience, we propose a novel inspire-and-create framework with a story-to-image retriever that selects relevant cinematic images for inspiration and a storyboard creator that further refines and renders images to improve the relevancy and visual consistency. The proposed retriever dynamically employs contextual information in the story with hierarchical attentions and applies dense visual-semantic matching to accurately retrieve and ground images. The creator then employs three rendering steps to increase the flexibility of retrieved images, which include erasing irrelevant regions, unifying styles of images and substituting consistent characters. We carry out extensive experiments on both in-domain and out-of-domain visual story datasets. The proposed model achieves better quantitative performance than the state-of-the-art baselines for storyboard creation. Qualitative visualizations and user studies further verify that our approach can create high-quality storyboards even for stories in the wild.
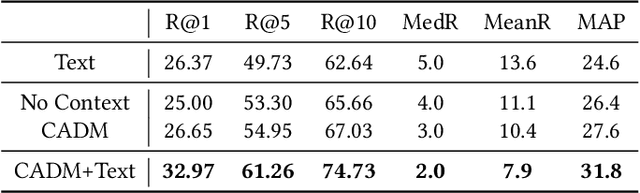
Learning Deep Bilinear Transformation for Fine-grained Image Representation
Nov 09, 2019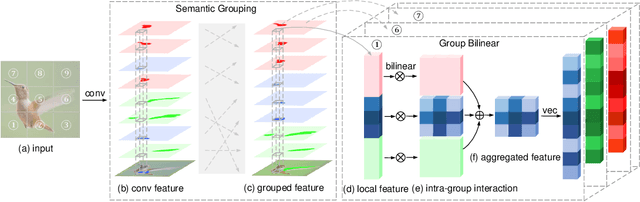
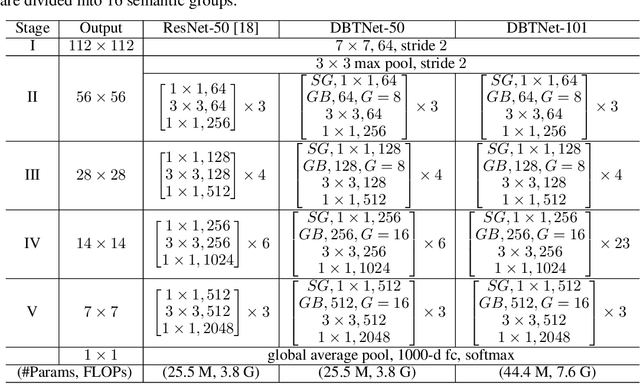
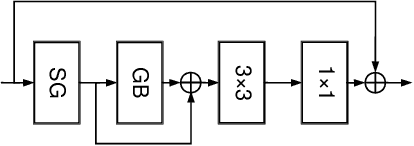
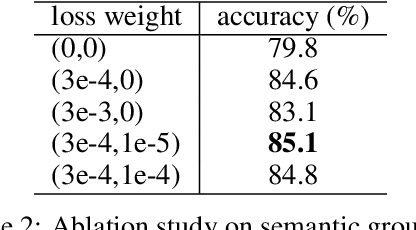
Bilinear feature transformation has shown the state-of-the-art performance in learning fine-grained image representations. However, the computational cost to learn pairwise interactions between deep feature channels is prohibitively expensive, which restricts this powerful transformation to be used in deep neural networks. In this paper, we propose a deep bilinear transformation (DBT) block, which can be deeply stacked in convolutional neural networks to learn fine-grained image representations. The DBT block can uniformly divide input channels into several semantic groups. As bilinear transformation can be represented by calculating pairwise interactions within each group, the computational cost can be heavily relieved. The output of each block is further obtained by aggregating intra-group bilinear features, with residuals from the entire input features. We found that the proposed network achieves new state-of-the-art in several fine-grained image recognition benchmarks, including CUB-Bird, Stanford-Car, and FGVC-Aircraft.
Learning Rich Image Region Representation for Visual Question Answering
Oct 29, 2019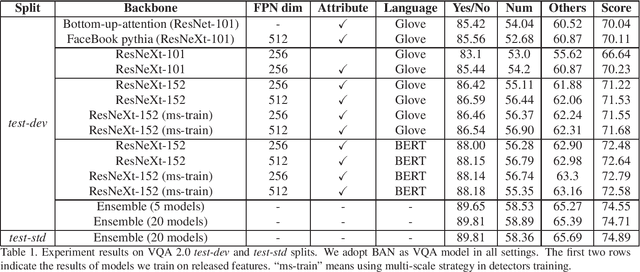
We propose to boost VQA by leveraging more powerful feature extractors by improving the representation ability of both visual and text features and the ensemble of models. For visual feature, some detection techniques are used to improve the detector. For text feature, we adopt BERT as the language model and find that it can significantly improve VQA performance. Our solution won the second place in the VQA Challenge 2019.