 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJianfeng Gao
Learning Visual Relation Priors for Image-Text Matching and Image Captioning with Neural Scene Graph Generators
Sep 22, 2019
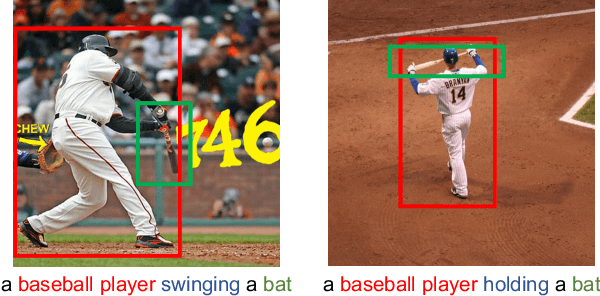
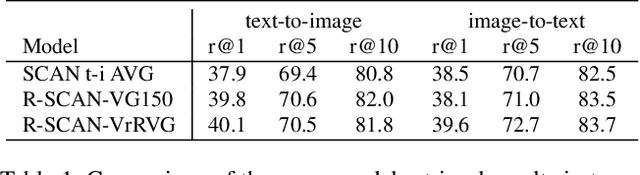
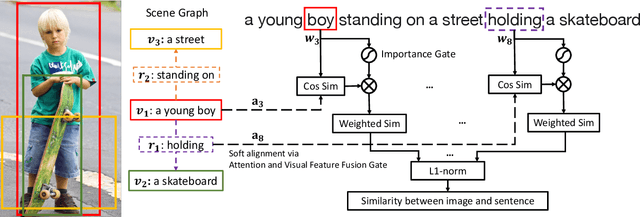
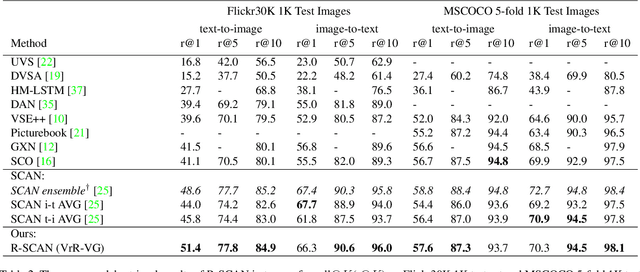
Grounding language to visual relations is critical to various language-and-vision applications. In this work, we tackle two fundamental language-and-vision tasks: image-text matching and image captioning, and demonstrate that neural scene graph generators can learn effective visual relation features to facilitate grounding language to visual relations and subsequently improve the two end applications. By combining relation features with the state-of-the-art models, our experiments show significant improvement on the standard Flickr30K and MSCOCO benchmarks. Our experimental results and analysis show that relation features improve downstream models' capability of capturing visual relations in end vision-and-language applications. We also demonstrate the importance of learning scene graph generators with visually relevant relations to the effectiveness of relation features.
Implicit Deep Latent Variable Models for Text Generation
Sep 18, 2019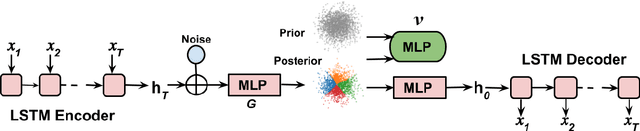
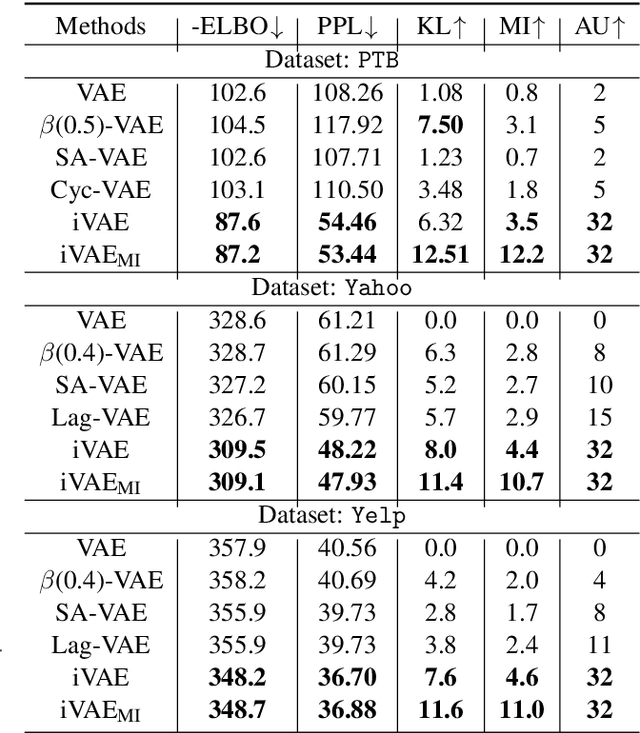
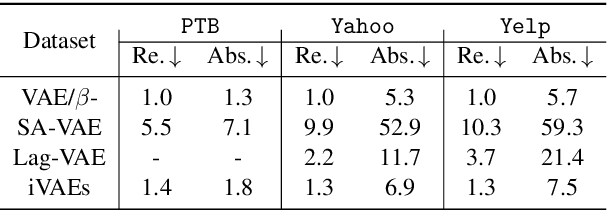
Deep latent variable models (LVM) such as variational auto-encoder (VAE) have recently played an important role in text generation. One key factor is the exploitation of smooth latent structures to guide the generation. However, the representation power of VAEs is limited due to two reasons: (1) the Gaussian assumption is often made on the variational posteriors; and meanwhile (2) a notorious "posterior collapse" issue occurs. In this paper, we advocate sample-based representations of variational distributions for natural language, leading to implicit latent features, which can provide flexible representation power compared with Gaussian-based posteriors. We further develop an LVM to directly match the aggregated posterior to the prior. It can be viewed as a natural extension of VAEs with a regularization of maximizing mutual information, mitigating the "posterior collapse" issue. We demonstrate the effectiveness and versatility of our models in various text generation scenarios, including language modeling, unaligned style transfer, and dialog response generation. The source code to reproduce our experimental results is available on GitHub.
What Makes A Good Story? Designing Composite Rewards for Visual Storytelling
Sep 11, 2019
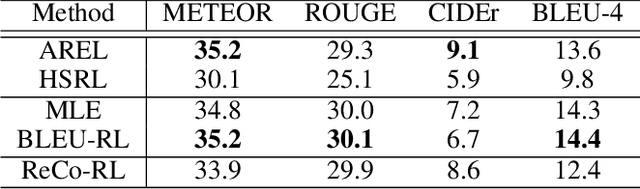
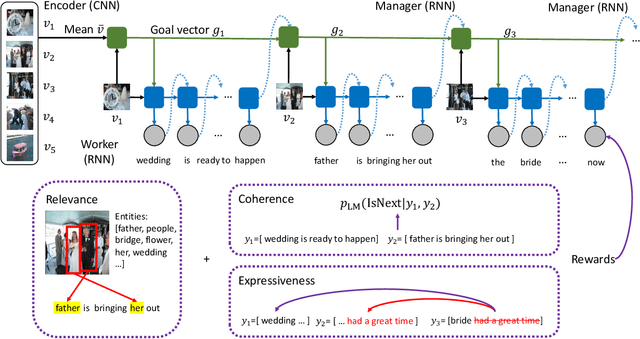

Previous storytelling approaches mostly focused on optimizing traditional metrics such as BLEU, ROUGE and CIDEr. In this paper, we re-examine this problem from a different angle, by looking deep into what defines a realistically-natural and topically-coherent story. To this end, we propose three assessment criteria: relevance, coherence and expressiveness, which we observe through empirical analysis could constitute a "high-quality" story to the human eye. Following this quality guideline, we propose a reinforcement learning framework, ReCo-RL, with reward functions designed to capture the essence of these quality criteria. Experiments on the Visual Storytelling Dataset (VIST) with both automatic and human evaluations demonstrate that our ReCo-RL model achieves better performance than state-of-the-art baselines on both traditional metrics and the proposed new criteria.
Robust Navigation with Language Pretraining and Stochastic Sampling
Sep 05, 2019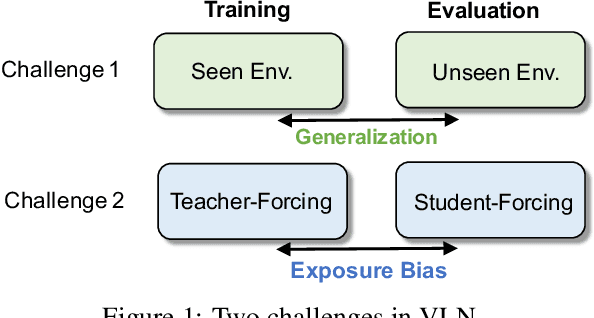
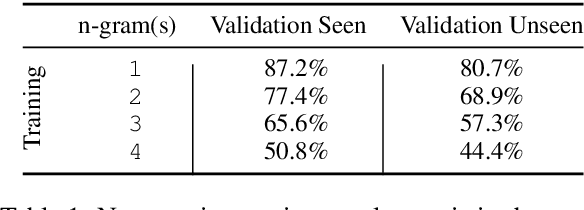
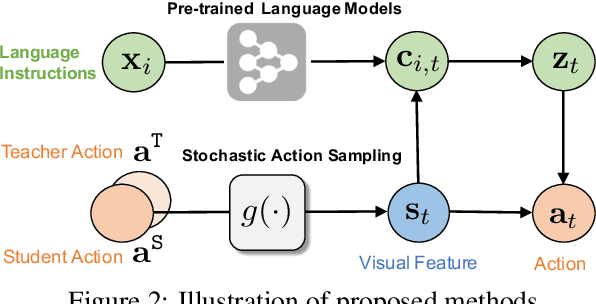
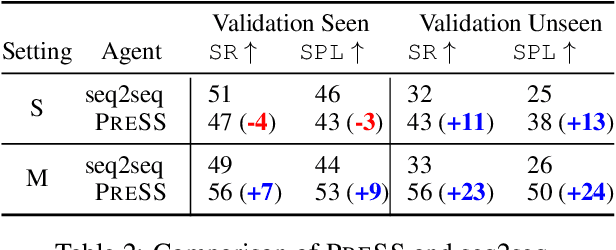
Core to the vision-and-language navigation (VLN) challenge is building robust instruction representations and action decoding schemes, which can generalize well to previously unseen instructions and environments. In this paper, we report two simple but highly effective methods to address these challenges and lead to a new state-of-the-art performance. First, we adapt large-scale pretrained language models to learn text representations that generalize better to previously unseen instructions. Second, we propose a stochastic sampling scheme to reduce the considerable gap between the expert actions in training and sampled actions in test, so that the agent can learn to correct its own mistakes during long sequential action decoding. Combining the two techniques, we achieve a new state of the art on the Room-to-Room benchmark with 6% absolute gain over the previous best result (47% -> 53%) on the Success Rate weighted by Path Length metric.
REO-Relevance, Extraness, Omission: A Fine-grained Evaluation for Image Captioning
Sep 05, 2019
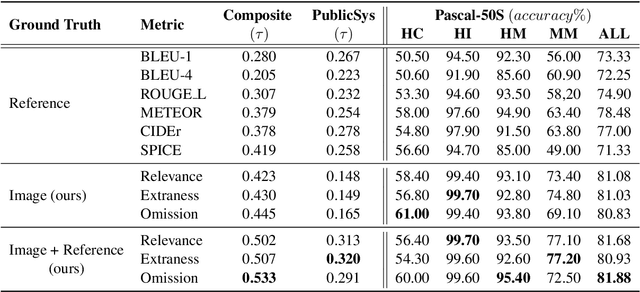
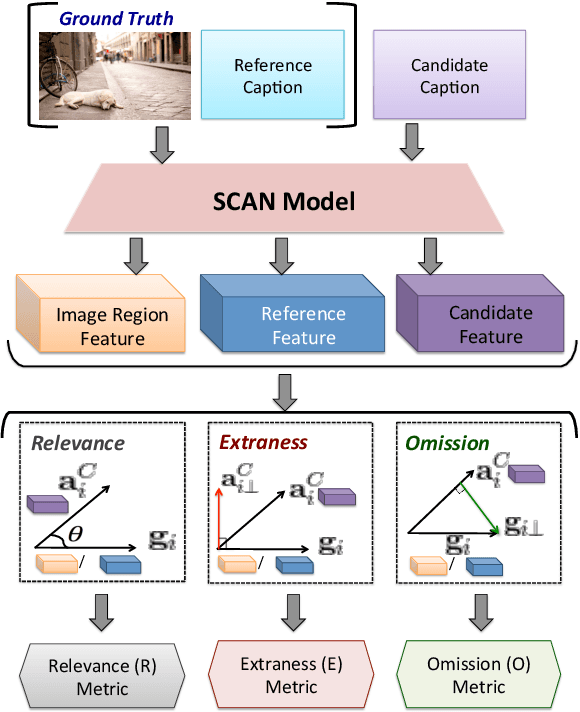

Popular metrics used for evaluating image captioning systems, such as BLEU and CIDEr, provide a single score to gauge the system's overall effectiveness. This score is often not informative enough to indicate what specific errors are made by a given system. In this study, we present a fine-grained evaluation method REO for automatically measuring the performance of image captioning systems. REO assesses the quality of captions from three perspectives: 1) Relevance to the ground truth, 2) Extraness of the content that is irrelevant to the ground truth, and 3) Omission of the elements in the images and human references. Experiments on three benchmark datasets demonstrate that our method achieves a higher consistency with human judgments and provides more intuitive evaluation results than alternative metrics.
TIGEr: Text-to-Image Grounding for Image Caption Evaluation
Sep 04, 2019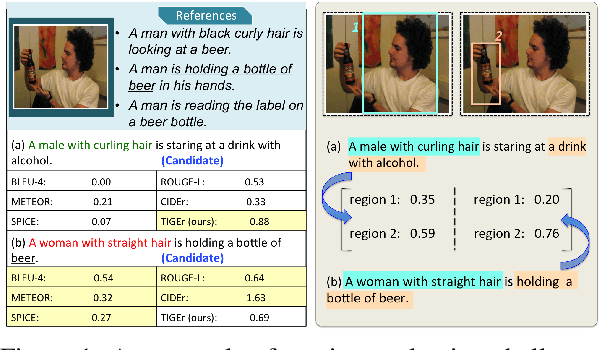
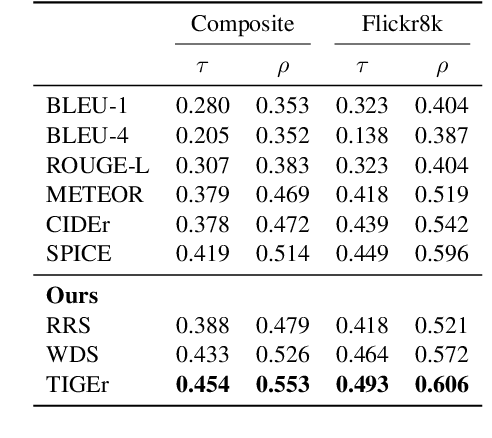
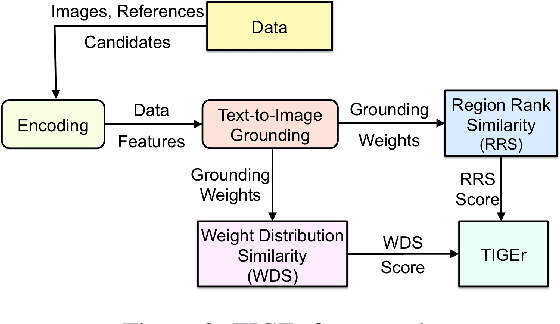
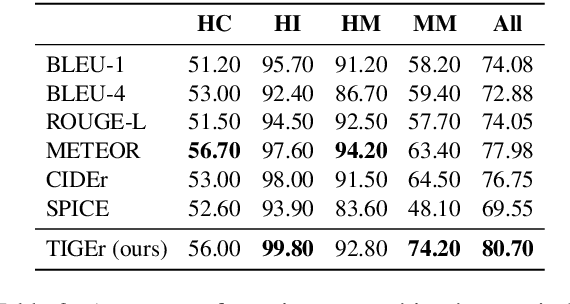
This paper presents a new metric called TIGEr for the automatic evaluation of image captioning systems. Popular metrics, such as BLEU and CIDEr, are based solely on text matching between reference captions and machine-generated captions, potentially leading to biased evaluations because references may not fully cover the image content and natural language is inherently ambiguous. Building upon a machine-learned text-image grounding model, TIGEr allows to evaluate caption quality not only based on how well a caption represents image content, but also on how well machine-generated captions match human-generated captions. Our empirical tests show that TIGEr has a higher consistency with human judgments than alternative existing metrics. We also comprehensively assess the metric's effectiveness in caption evaluation by measuring the correlation between human judgments and metric scores.
Structuring Latent Spaces for Stylized Response Generation
Sep 03, 2019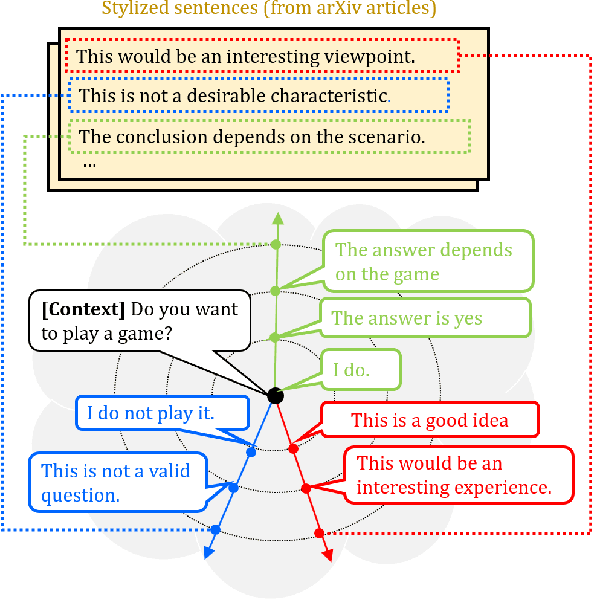
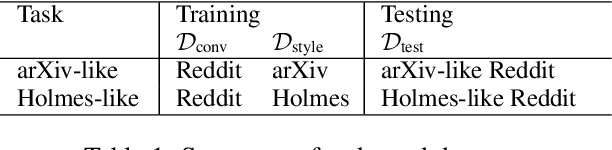
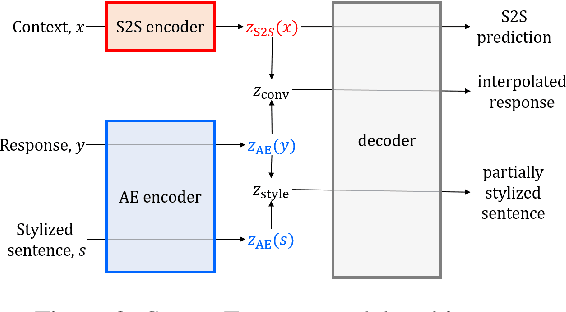

Generating responses in a targeted style is a useful yet challenging task, especially in the absence of parallel data. With limited data, existing methods tend to generate responses that are either less stylized or less context-relevant. We propose StyleFusion, which bridges conversation modeling and non-parallel style transfer by sharing a structured latent space. This structure allows the system to generate stylized relevant responses by sampling in the neighborhood of the conversation model prediction, and continuously control the style level. We demonstrate this method using dialogues from Reddit data and two sets of sentences with distinct styles (arXiv and Sherlock Holmes novels). Automatic and human evaluation show that, without sacrificing appropriateness, the system generates responses of the targeted style and outperforms competitive baselines.
* accepted to appear at EMNLP 2019 (long)
Adversarial Domain Adaptation for Machine Reading Comprehension
Aug 24, 2019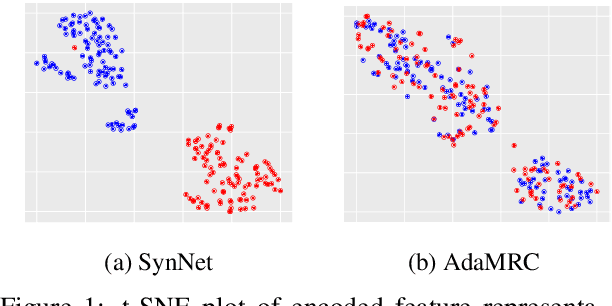
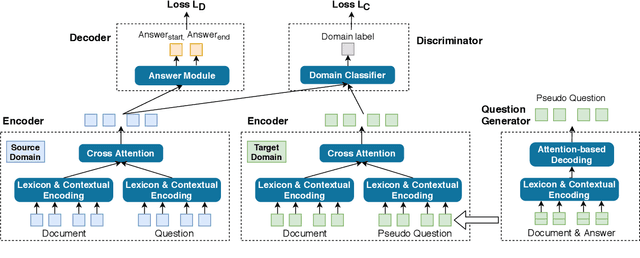
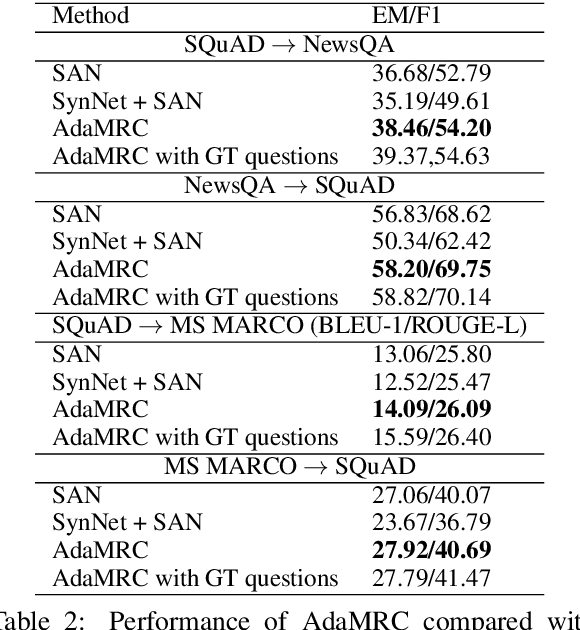
In this paper, we focus on unsupervised domain adaptation for Machine Reading Comprehension (MRC), where the source domain has a large amount of labeled data, while only unlabeled passages are available in the target domain. To this end, we propose an Adversarial Domain Adaptation framework (AdaMRC), where ($i$) pseudo questions are first generated for unlabeled passages in the target domain, and then ($ii$) a domain classifier is incorporated into an MRC model to predict which domain a given passage-question pair comes from. The classifier and the passage-question encoder are jointly trained using adversarial learning to enforce domain-invariant representation learning. Comprehensive evaluations demonstrate that our approach ($i$) is generalizable to different MRC models and datasets, ($ii$) can be combined with pre-trained large-scale language models (such as ELMo and BERT), and ($iii$) can be extended to semi-supervised learning.
On the Variance of the Adaptive Learning Rate and Beyond
Aug 08, 2019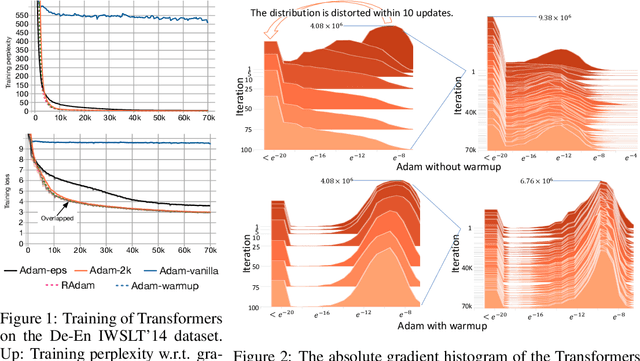
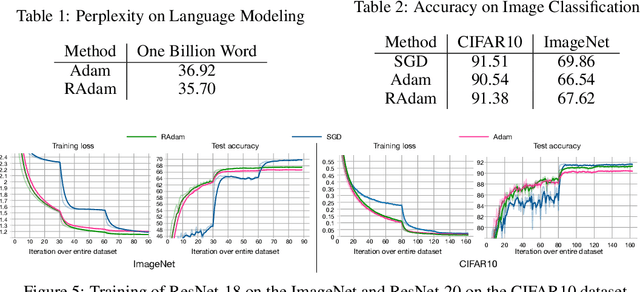
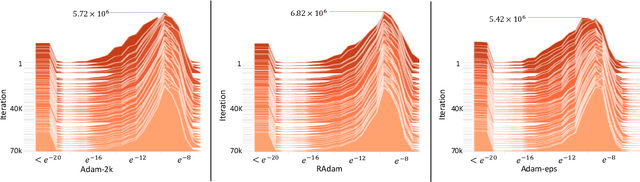
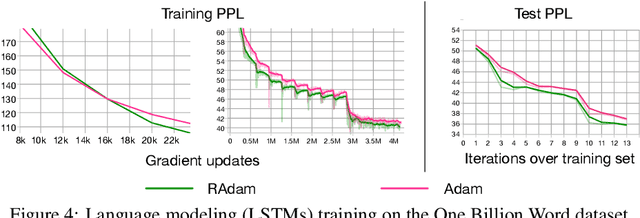
The learning rate warmup heuristic achieves remarkable success in stabilizing training, accelerating convergence and improving generalization for adaptive stochastic optimization algorithms like RMSprop and Adam. Here, we study its mechanism in details. Pursuing the theory behind warmup, we identify a problem of the adaptive learning rate (i.e., it has problematically large variance in the early stage), suggest warmup works as a variance reduction technique, and provide both empirical and theoretical evidence to verify our hypothesis. We further propose RAdam, a new variant of Adam, by introducing a term to rectify the variance of the adaptive learning rate. Extensive experimental results on image classification, language modeling, and neural machine translation verify our intuition and demonstrate the effectiveness and robustness of our proposed method. All implementations are available at: https://github.com/LiyuanLucasLiu/RAdam.