 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Fuse Asymmetric Feature Maps in Siamese Trackers
Dec 04, 2020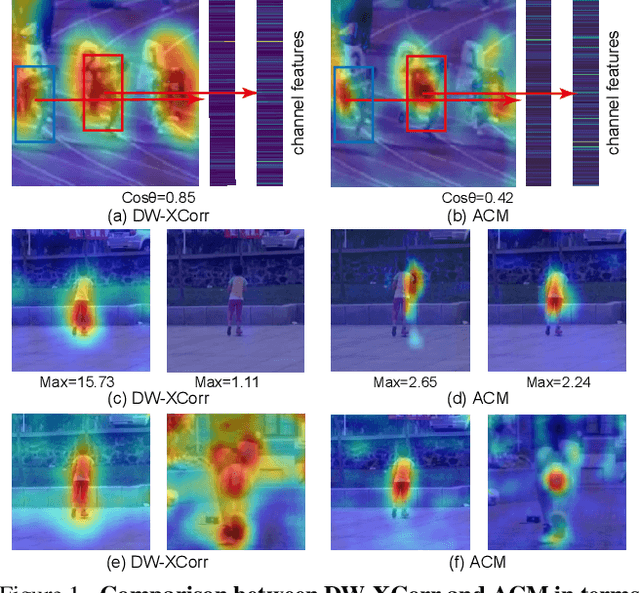
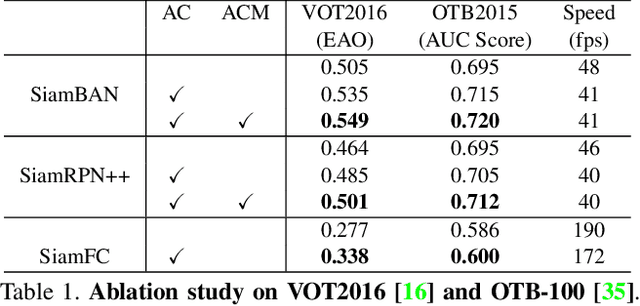
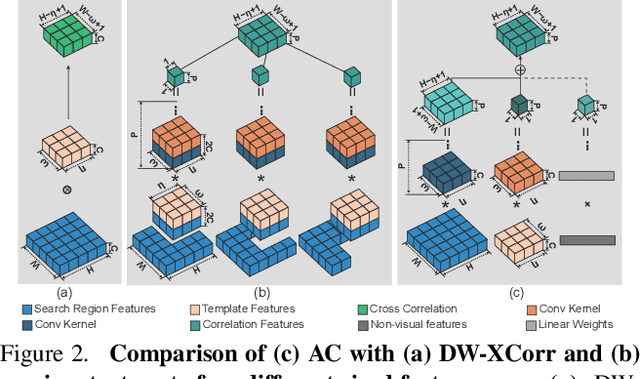
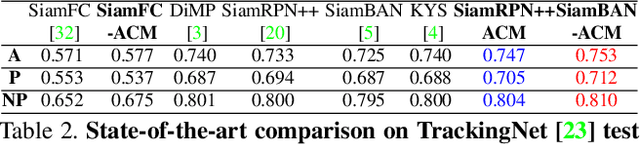
In recent years, Siamese-based trackers have achieved promising performance in visual tracking. Most recent Siamese-based trackers typically employ a depth-wise cross-correlation (DW-XCorr) to obtain multi-channel correlation information from the two feature maps (target and search region). However, DW-XCorr has several limitations within Siamese-based tracking: it can easily be fooled by distractors, has fewer activated channels, and provides weak discrimination of object boundaries. Further, DW-XCorr is a handcrafted parameter-free module and cannot fully benefit from offline learning on large-scale data. We propose a learnable module, called the asymmetric convolution (ACM), which learns to better capture the semantic correlation information in offline training on large-scale data. Different from DW-XCorr and its predecessor (XCorr), which regard a single feature map as the convolution kernel, our ACM decomposes the convolution operation on a concatenated feature map into two mathematically equivalent operations, thereby avoiding the need for the feature maps to be of the same size (width and height) during concatenation. Our ACM can incorporate useful prior information, such as bounding-box size, with standard visual features. Furthermore, ACM can easily be integrated into existing Siamese trackers based on DW-XCorr or XCorr. To demonstrate its generalization ability, we integrate ACM into three representative trackers: SiamFC, SiamRPN++, and SiamBAN. Our experiments reveal the benefits of the proposed ACM, which outperforms existing methods on six tracking benchmarks. On the LaSOT test set, our ACM-based tracker obtains a significant improvement of 5.8% in terms of success (AUC), over the baseline.
Siamese Network for RGB-D Salient Object Detection and Beyond
Aug 26, 2020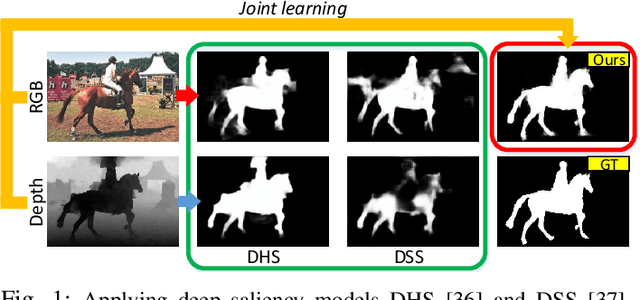

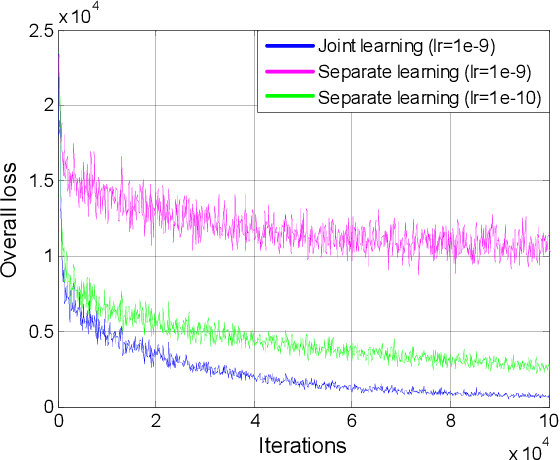

Existing RGB-D salient object detection (SOD) models usually treat RGB and depth as independent information and design separate networks for feature extraction from each. Such schemes can easily be constrained by a limited amount of training data or over-reliance on an elaborately designed training process. Inspired by the observation that RGB and depth modalities actually present certain commonality in distinguishing salient objects, a novel joint learning and densely cooperative fusion (JL-DCF) architecture is designed to learn from both RGB and depth inputs through a shared network backbone, known as the Siamese architecture. In this paper, we propose two effective components: joint learning (JL), and densely cooperative fusion (DCF). The JL module provides robust saliency feature learning by exploiting cross-modal commonality via a Siamese network, while the DCF module is introduced for complementary feature discovery. Comprehensive experiments using five popular metrics show that the designed framework yields a robust RGB-D saliency detector with good generalization. As a result, JL-DCF significantly advances the state-of-the-art models by an average of ~2.0% (F-measure) across seven challenging datasets. In addition, we show that JL-DCF is readily applicable to other related multi-modal detection tasks, including RGB-T (thermal infrared) SOD and video SOD (VSOD), achieving comparable or even better performance against state-of-the-art methods. This further confirms that the proposed framework could offer a potential solution for various applications and provide more insight into the cross-modal complementarity task. The code will be available at https://github.com/kerenfu/JLDCF/
Active Visual Information Gathering for Vision-Language Navigation
Aug 19, 2020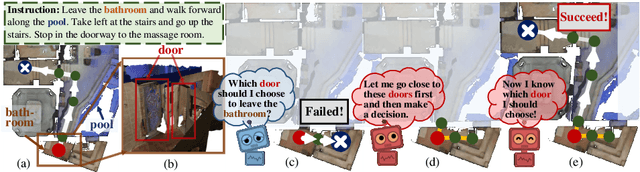
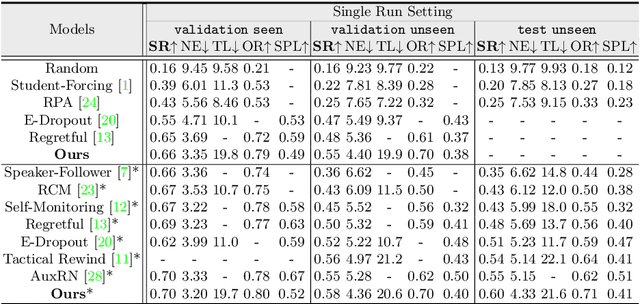
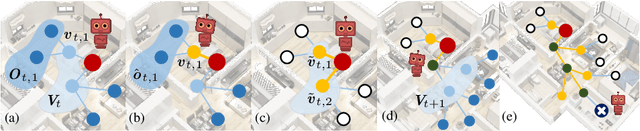
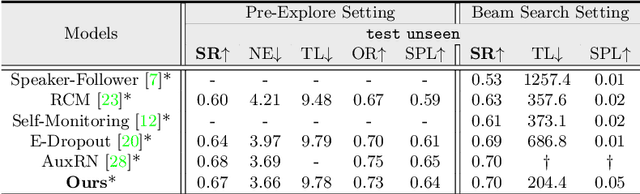
Vision-language navigation (VLN) is the task of entailing an agent to carry out navigational instructions inside photo-realistic environments. One of the key challenges in VLN is how to conduct a robust navigation by mitigating the uncertainty caused by ambiguous instructions and insufficient observation of the environment. Agents trained by current approaches typically suffer from this and would consequently struggle to avoid random and inefficient actions at every step. In contrast, when humans face such a challenge, they can still maintain robust navigation by actively exploring the surroundings to gather more information and thus make more confident navigation decisions. This work draws inspiration from human navigation behavior and endows an agent with an active information gathering ability for a more intelligent vision-language navigation policy. To achieve this, we propose an end-to-end framework for learning an exploration policy that decides i) when and where to explore, ii) what information is worth gathering during exploration, and iii) how to adjust the navigation decision after the exploration. The experimental results show promising exploration strategies emerged from training, which leads to significant boost in navigation performance. On the R2R challenge leaderboard, our agent gets promising results all three VLN settings, i.e., single run, pre-exploration, and beam search.
RGB-D Salient Object Detection: A Survey
Aug 01, 2020
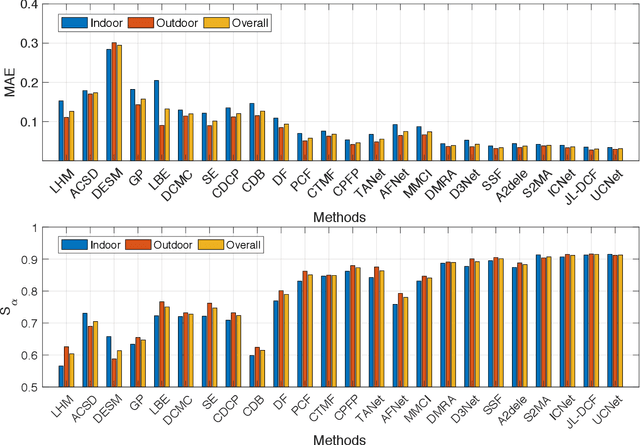


Salient object detection (SOD), which simulates the human visual perception system to locate the most attractive object(s) in a scene, has been widely applied to various computer vision tasks. Now, with the advent of depth sensors, depth maps with affluent spatial information that can be beneficial in boosting the performance of SOD, can easily be captured. Although various RGB-D based SOD models with promising performance have been proposed over the past several years, an in-depth understanding of these models and challenges in this topic remains lacking. In this paper, we provide a comprehensive survey of RGB-D based SOD models from various perspectives, and review related benchmark datasets in detail. Further, considering that the light field can also provide depth maps, we review SOD models and popular benchmark datasets from this domain as well. Moreover, to investigate the SOD ability of existing models, we carry out a comprehensive evaluation, as well as attribute-based evaluation of several representative RGB-D based SOD models. Finally, we discuss several challenges and open directions of RGB-D based SOD for future research. All collected models, benchmark datasets, source code links, datasets constructed for attribute-based evaluation, and codes for evaluation will be made publicly available at https://github.com/taozh2017/RGBDSODsurvey
Weakly Supervised 3D Object Detection from Lidar Point Cloud
Jul 23, 2020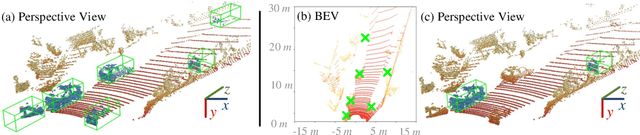
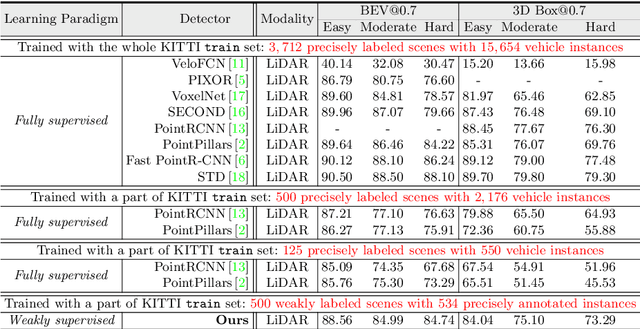

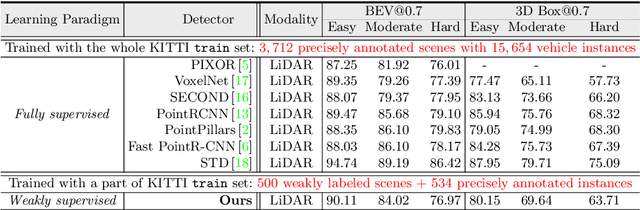
It is laborious to manually label point cloud data for training high-quality 3D object detectors. This work proposes a weakly supervised approach for 3D object detection, only requiring a small set of weakly annotated scenes, associated with a few precisely labeled object instances. This is achieved by a two-stage architecture design. Stage-1 learns to generate cylindrical object proposals under weak supervision, i.e., only the horizontal centers of objects are click-annotated on bird's view scenes. Stage-2 learns to refine the cylindrical proposals to get cuboids and confidence scores, using a few well-labeled object instances. Using only 500 weakly annotated scenes and 534 precisely labeled vehicle instances, our method achieves 85-95% the performance of current top-leading, fully supervised detectors (which require 3, 712 exhaustively and precisely annotated scenes with 15, 654 instances). More importantly, with our elaborately designed network architecture, our trained model can be applied as a 3D object annotator, allowing both automatic and active working modes. The annotations generated by our model can be used to train 3D object detectors with over 94% of their original performance (under manually labeled data). Our experiments also show our model's potential in boosting performance given more training data. Above designs make our approach highly practical and introduce new opportunities for learning 3D object detection with reduced annotation burden.
Video Object Segmentation with Episodic Graph Memory Networks
Jul 19, 2020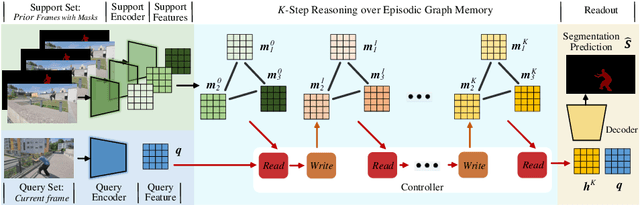
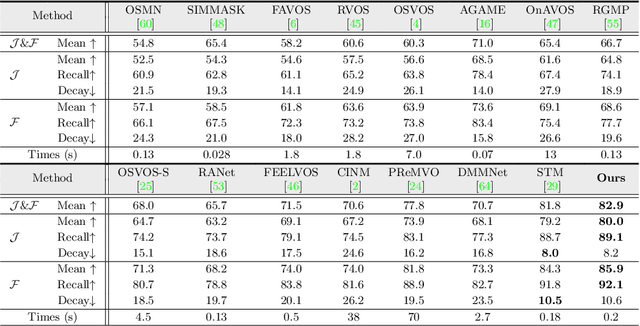
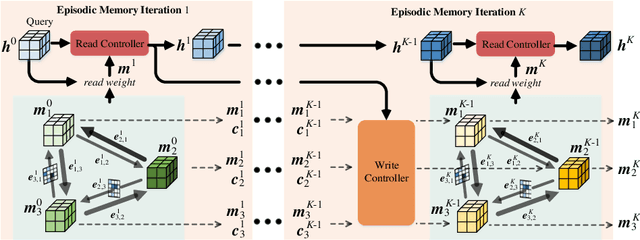
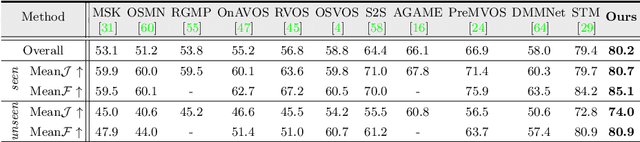
How to make a segmentation model efficiently adapt to a specific video and to online target appearance variations are fundamentally crucial issues in the field of video object segmentation. In this work, a graph memory network is developed to address the novel idea of "learning to update the segmentation model". Specifically, we exploit an episodic memory network, organized as a fully connected graph, to store frames as nodes and capture cross-frame correlations by edges. Further, learnable controllers are embedded to ease memory reading and writing, as well as maintain a fixed memory scale. The structured, external memory design enables our model to comprehensively mine and quickly store new knowledge, even with limited visual information, and the differentiable memory controllers slowly learn an abstract method for storing useful representations in the memory and how to later use these representations for prediction, via gradient descent. In addition, the proposed graph memory network yields a neat yet principled framework, which can generalize well both one-shot and zero-shot video object segmentation tasks. Extensive experiments on four challenging benchmark datasets verify that our graph memory network is able to facilitate the adaptation of the segmentation network for case-by-case video object segmentation.
Dynamic Dual-Attentive Aggregation Learning for Visible-Infrared Person Re-Identification
Jul 18, 2020

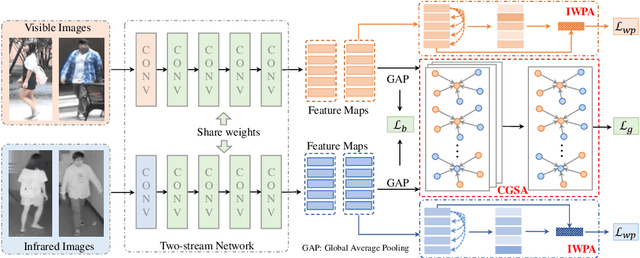

Visible-infrared person re-identification (VI-ReID) is a challenging cross-modality pedestrian retrieval problem. Due to the large intra-class variations and cross-modality discrepancy with large amount of sample noise, it is difficult to learn discriminative part features. Existing VI-ReID methods instead tend to learn global representations, which have limited discriminability and weak robustness to noisy images. In this paper, we propose a novel dynamic dual-attentive aggregation (DDAG) learning method by mining both intra-modality part-level and cross-modality graph-level contextual cues for VI-ReID. We propose an intra-modality weighted-part attention module to extract discriminative part-aggregated features, by imposing the domain knowledge on the part relationship mining. To enhance robustness against noisy samples, we introduce cross-modality graph structured attention to reinforce the representation with the contextual relations across the two modalities. We also develop a parameter-free dynamic dual aggregation learning strategy to adaptively integrate the two components in a progressive joint training manner. Extensive experiments demonstrate that DDAG outperforms the state-of-the-art methods under various settings.
Re-thinking Co-Salient Object Detection
Jul 11, 2020

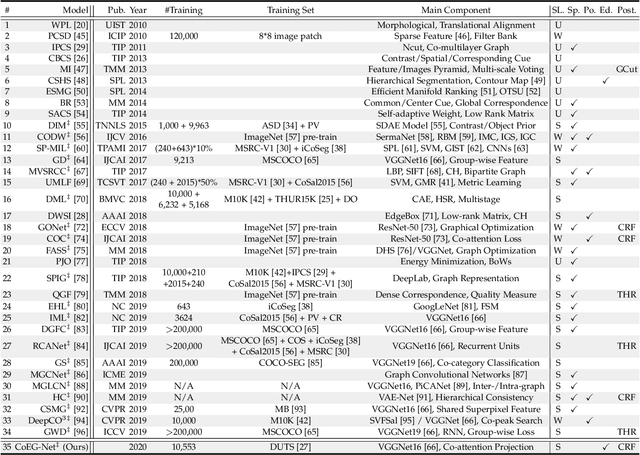

In this paper, we conduct a comprehensive study on the co-salient object detection (CoSOD) problem for images. CoSOD is an emerging and rapidly growing extension of salient object detection (SOD), which aims to detect the co-occurring salient objects in a group of images. However, existing CoSOD datasets often have a serious data bias, assuming that each group of images contains salient objects of similar visual appearances. This bias can lead to the ideal settings and effectiveness of models trained on existing datasets, being impaired in real-life situations, where similarities are usually semantic or conceptual. To tackle this issue, we first introduce a new benchmark, called CoSOD3k in the wild, which requires a large amount of semantic context, making it more challenging than existing CoSOD datasets. Our CoSOD3k consists of 3,316 high-quality, elaborately selected images divided into 160 groups with hierarchical annotations. The images span a wide range of categories, shapes, object sizes, and backgrounds. Second, we integrate the existing SOD techniques to build a unified, trainable CoSOD framework, which is long overdue in this field. Specifically, we propose a novel CoEG-Net that augments our prior model EGNet with a co-attention projection strategy to enable fast common information learning. CoEG-Net fully leverages previous large-scale SOD datasets and significantly improves the model scalability and stability. Third, we comprehensively summarize 34 cutting-edge algorithms, benchmarking 16 of them over three challenging CoSOD datasets (iCoSeg, CoSal2015, and our CoSOD3k), and reporting more detailed (i.e., group-level) performance analysis. Finally, we discuss the challenges and future works of CoSOD. We hope that our study will give a strong boost to growth in the CoSOD community
PraNet: Parallel Reverse Attention Network for Polyp Segmentation
Jul 03, 2020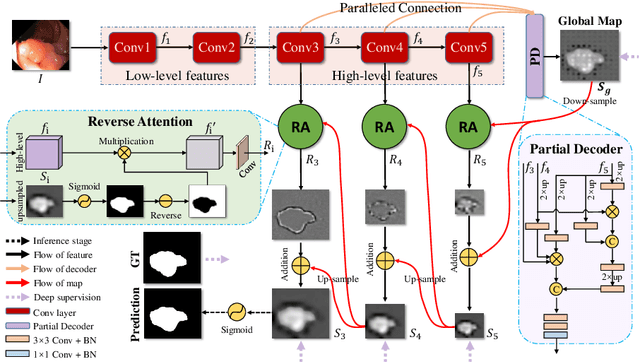
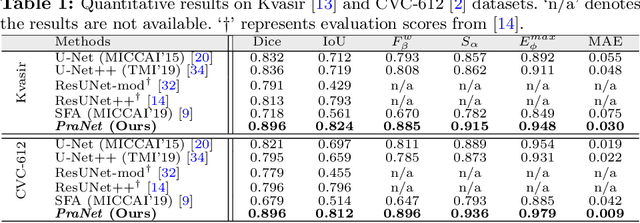
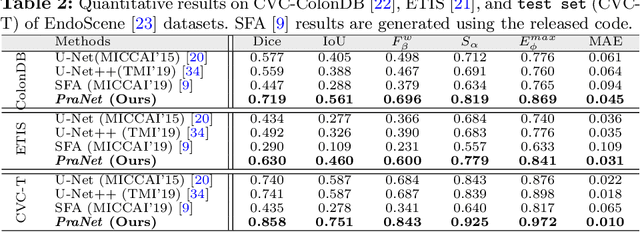

Colonoscopy is an effective technique for detecting colorectal polyps, which are highly related to colorectal cancer. In clinical practice, segmenting polyps from colonoscopy images is of great importance since it provides valuable information for diagnosis and surgery. However, accurate polyp segmentation is a challenging task, for two major reasons: (i) the same type of polyps has a diversity of size, color and texture; and (ii) the boundary between a polyp and its surrounding mucosa is not sharp. To address these challenges, we propose a parallel reverse attention network (PraNet) for accurate polyp segmentation in colonoscopy images. Specifically, we first aggregate the features in high-level layers using a parallel partial decoder (PPD). Based on the combined feature, we then generate a global map as the initial guidance area for the following components. In addition, we mine the boundary cues using a reverse attention (RA) module, which is able to establish the relationship between areas and boundary cues. Thanks to the recurrent cooperation mechanism between areas and boundaries, our PraNet is capable of calibrating any misaligned predictions, improving the segmentation accuracy. Quantitative and qualitative evaluations on five challenging datasets across six metrics show that our PraNet improves the segmentation accuracy significantly, and presents a number of advantages in terms of generalizability, and real-time segmentation efficiency.
M2Net: Multi-modal Multi-channel Network for Overall Survival Time Prediction of Brain Tumor Patients
Jun 01, 2020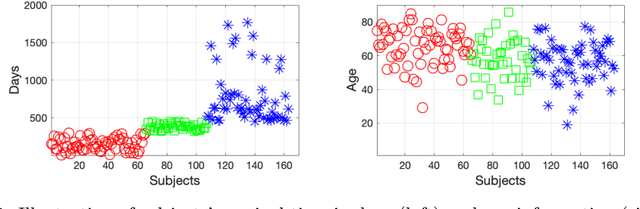
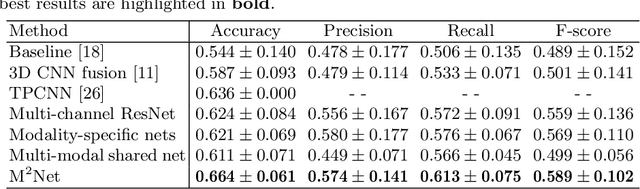
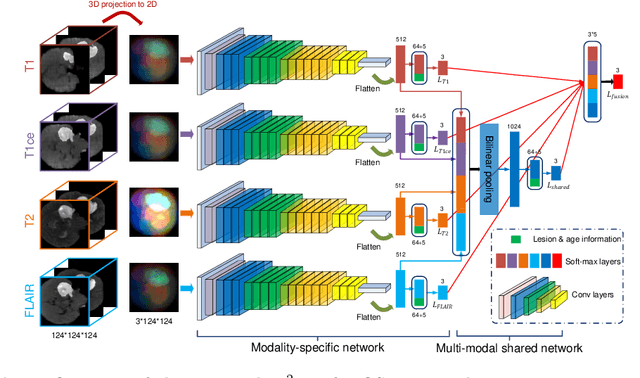
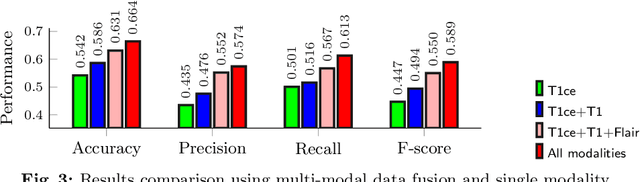
Early and accurate prediction of overall survival (OS) time can help to obtain better treatment planning for brain tumor patients. Although many OS time prediction methods have been developed and obtain promising results, there are still several issues. First, conventional prediction methods rely on radiomic features at the local lesion area of a magnetic resonance (MR) volume, which may not represent the full image or model complex tumor patterns. Second, different types of scanners (i.e., multi-modal data) are sensitive to different brain regions, which makes it challenging to effectively exploit the complementary information across multiple modalities and also preserve the modality-specific properties. Third, existing methods focus on prediction models, ignoring complex data-to-label relationships. To address the above issues, we propose an end-to-end OS time prediction model; namely, Multi-modal Multi-channel Network (M2Net). Specifically, we first project the 3D MR volume onto 2D images in different directions, which reduces computational costs, while preserving important information and enabling pre-trained models to be transferred from other tasks. Then, we use a modality-specific network to extract implicit and high-level features from different MR scans. A multi-modal shared network is built to fuse these features using a bilinear pooling model, exploiting their correlations to provide complementary information. Finally, we integrate the outputs from each modality-specific network and the multi-modal shared network to generate the final prediction result. Experimental results demonstrate the superiority of our M2Net model over other methods.