 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAngle-based Search Space Shrinking for Neural Architecture Search
May 01, 2020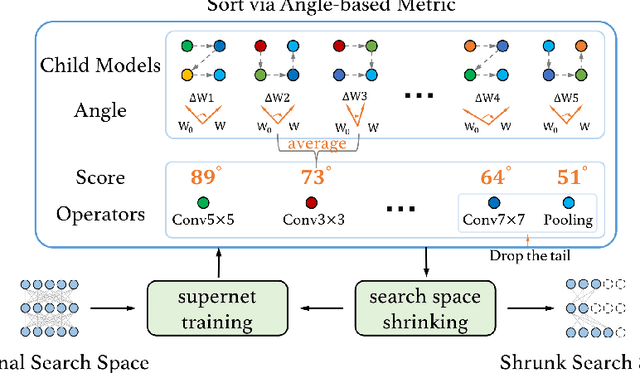


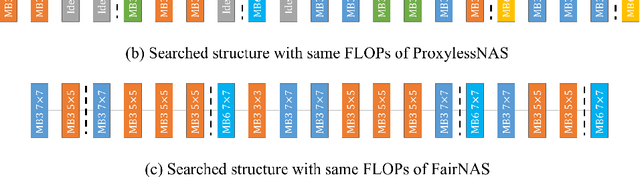
In this work, we present a simple and general search space shrinking method, called Angle-Based search space Shrinking (ABS), for Neural Architecture Search (NAS). Our approach progressively simplifies the original search space by dropping unpromising candidates, thus can reduce difficulties for existing NAS methods to find superior architectures. In particular, we propose an angle-based metric to guide the shrinking process. We provide comprehensive evidences showing that, in weight-sharing supernet, the proposed metric is more stable and accurate than accuracy-based and magnitude-based metrics to predict the capability of child models. We also show that the angle-based metric can converge fast while training supernet, enabling us to get promising shrunk search spaces efficiently. ABS can easily apply to most of popular NAS approaches (e.g. SPOS, FariNAS, ProxylessNAS, DARTS and PDARTS). Comprehensive experiments show that ABS can dramatically enhance existing NAS approaches by providing a promising shrunk search space.
Stitcher: Feedback-driven Data Provider for Object Detection
Apr 26, 2020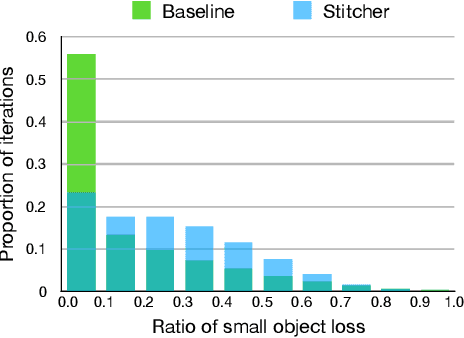

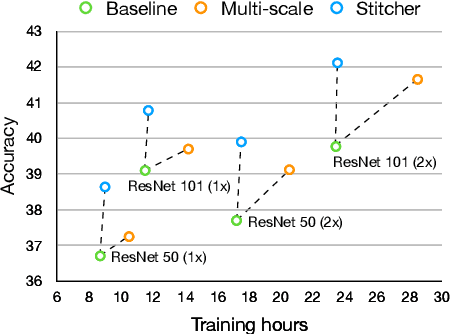
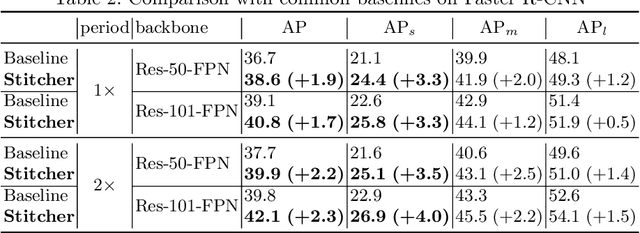
Object detectors commonly vary quality according to scales, where the performance on small objects is the least satisfying. In this paper, we investigate this phenomenon and discover that: in the majority of training iterations, small objects contribute barely to the total loss, causing poor performance with imbalanced optimization. Inspired by this finding, we present Stitcher, a feedback-driven data provider, which aims to train object detectors in a balanced way. In Stitcher, images are resized into smaller components and then stitched into the same size to regular images. Stitched images contain inevitable smaller objects, which would be beneficial with our core idea, to exploit the loss statistics as feedback to guide next-iteration update. Experiments have been conducted on various detectors, backbones, training periods, datasets, and even on instance segmentation. Stitcher steadily improves performance by a large margin in all settings, especially for small objects, with nearly no additional computation in both training and testing stages.
Attentive Normalization for Conditional Image Generation
Apr 08, 2020
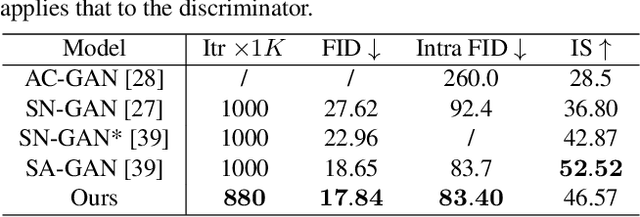
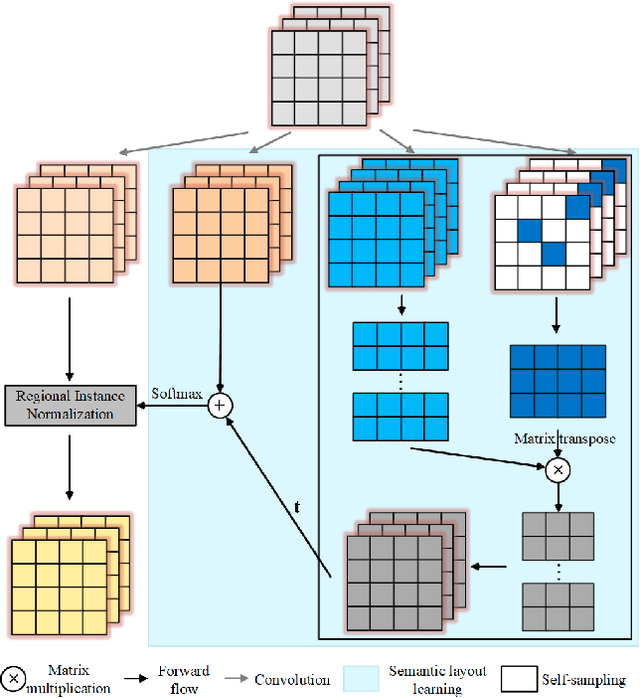
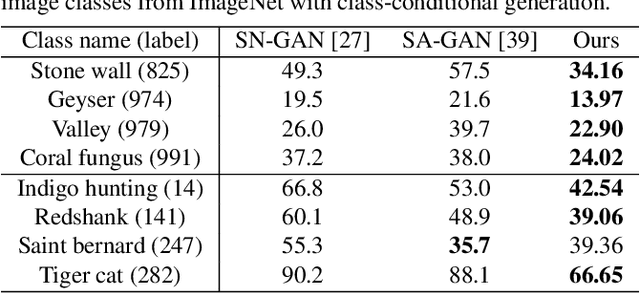
Traditional convolution-based generative adversarial networks synthesize images based on hierarchical local operations, where long-range dependency relation is implicitly modeled with a Markov chain. It is still not sufficient for categories with complicated structures. In this paper, we characterize long-range dependence with attentive normalization (AN), which is an extension to traditional instance normalization. Specifically, the input feature map is softly divided into several regions based on its internal semantic similarity, which are respectively normalized. It enhances consistency between distant regions with semantic correspondence. Compared with self-attention GAN, our attentive normalization does not need to measure the correlation of all locations, and thus can be directly applied to large-size feature maps without much computational burden. Extensive experiments on class-conditional image generation and semantic inpainting verify the efficacy of our proposed module.
High-Order Information Matters: Learning Relation and Topology for Occluded Person Re-Identification
Apr 02, 2020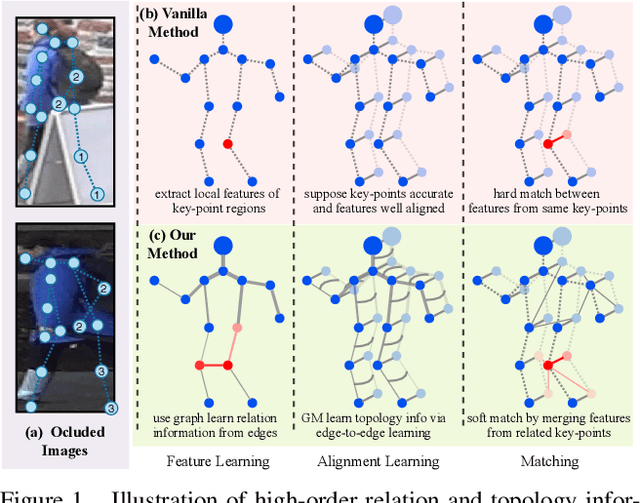
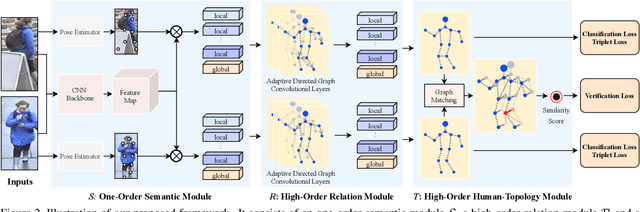
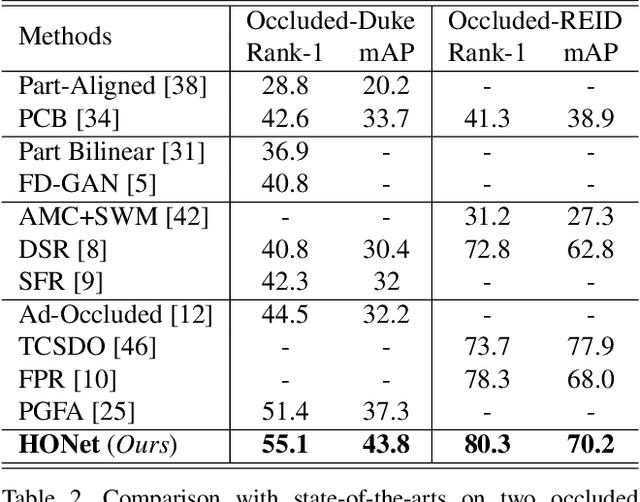
Occluded person re-identification (ReID) aims to match occluded person images to holistic ones across dis-joint cameras. In this paper, we propose a novel framework by learning high-order relation and topology information for discriminative features and robust alignment. At first, we use a CNN backbone and a key-points estimation model to extract semantic local features. Even so, occluded images still suffer from occlusion and outliers. Then, we view the local features of an image as nodes of a graph and propose an adaptive direction graph convolutional (ADGC)layer to pass relation information between nodes. The proposed ADGC layer can automatically suppress the message-passing of meaningless features by dynamically learning di-rection and degree of linkage. When aligning two groups of local features from two images, we view it as a graph matching problem and propose a cross-graph embedded-alignment (CGEA) layer to jointly learn and embed topology information to local features, and straightly predict similarity score. The proposed CGEA layer not only take full use of alignment learned by graph matching but also re-place sensitive one-to-one matching with a robust soft one. Finally, extensive experiments on occluded, partial, and holistic ReID tasks show the effectiveness of our proposed method. Specifically, our framework significantly outperforms state-of-the-art by6.5%mAP scores on Occluded-Duke dataset.
Learning Human-Object Interaction Detection using Interaction Points
Mar 31, 2020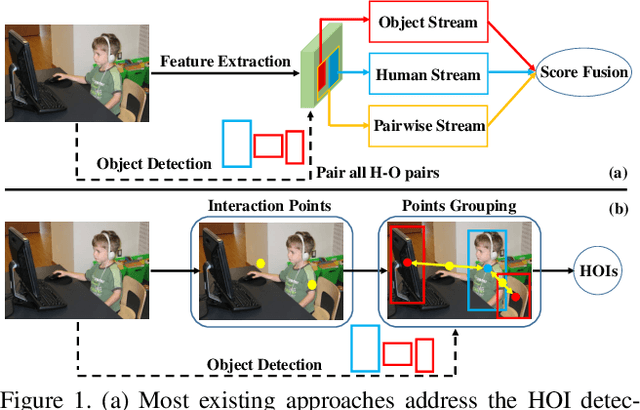
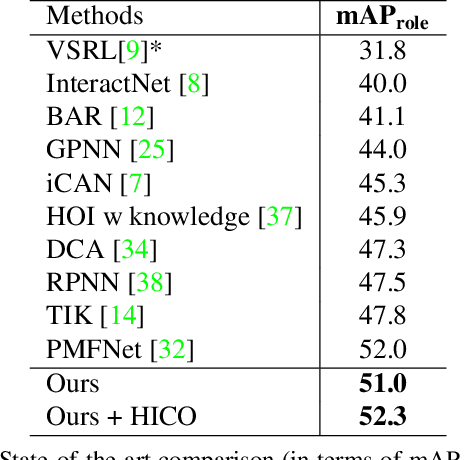
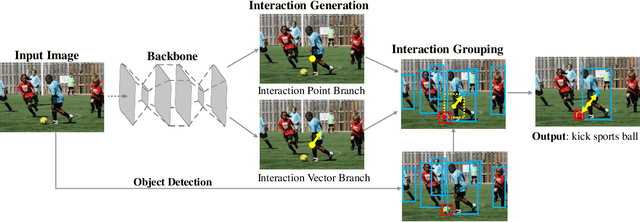
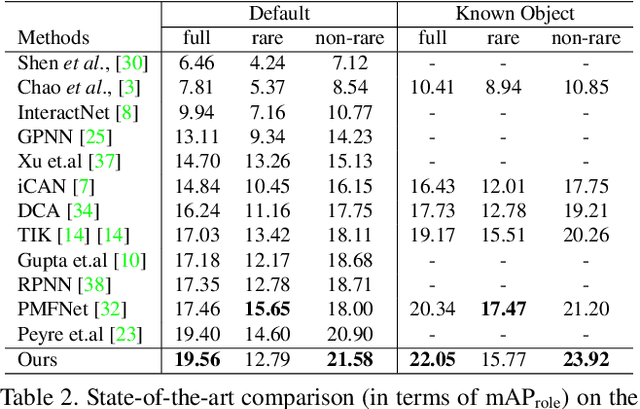
Understanding interactions between humans and objects is one of the fundamental problems in visual classification and an essential step towards detailed scene understanding. Human-object interaction (HOI) detection strives to localize both the human and an object as well as the identification of complex interactions between them. Most existing HOI detection approaches are instance-centric where interactions between all possible human-object pairs are predicted based on appearance features and coarse spatial information. We argue that appearance features alone are insufficient to capture complex human-object interactions. In this paper, we therefore propose a novel fully-convolutional approach that directly detects the interactions between human-object pairs. Our network predicts interaction points, which directly localize and classify the inter-action. Paired with the densely predicted interaction vectors, the interactions are associated with human and object detections to obtain final predictions. To the best of our knowledge, we are the first to propose an approach where HOI detection is posed as a keypoint detection and grouping problem. Experiments are performed on two popular benchmarks: V-COCO and HICO-DET. Our approach sets a new state-of-the-art on both datasets. Code is available at https://github.com/vaesl/IP-Net.
Dynamic Region-Aware Convolution
Mar 27, 2020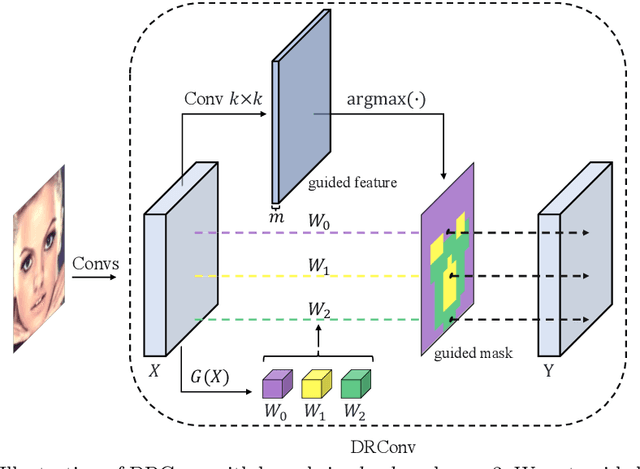
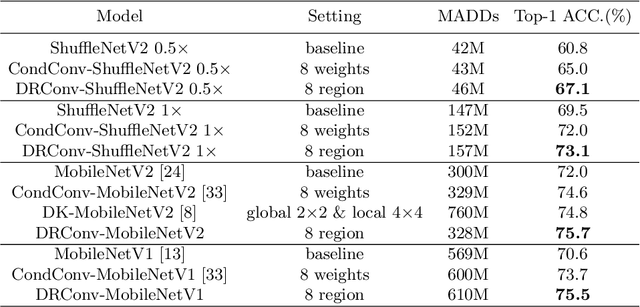
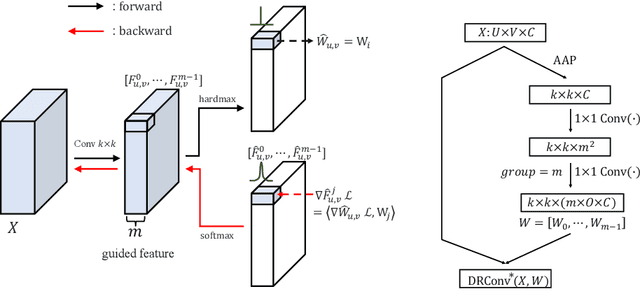

We propose a new convolution called Dynamic Region-Aware Convolution (DRConv), which can automatically assign multiple filters to corresponding spatial regions where features have similar representation. In this way, DRConv outperforms standard convolution in modeling semantic variations. Standard convolution can increase the number of channels to extract more visual elements but results in high computational cost. More gracefully, our DRConv transfers the increasing channel-wise filters to spatial dimension with learnable instructor, which significantly improves representation ability of convolution and maintains translation-invariance like standard convolution. DRConv is an effective and elegant method for handling complex and variable spatial information distribution. It can substitute standard convolution in any existing networks for its plug-and-play property. We evaluate DRConv on a wide range of models (MobileNet series, ShuffleNetV2, etc.) and tasks (Classification, Face Recognition, Detection and Segmentation.). On ImageNet classification, DRConv-based ShuffleNetV2-0.5x achieves state-of-the-art performance of 67.1% at 46M multiply-adds level with 6.3% relative improvement.
Learning Dynamic Routing for Semantic Segmentation
Mar 23, 2020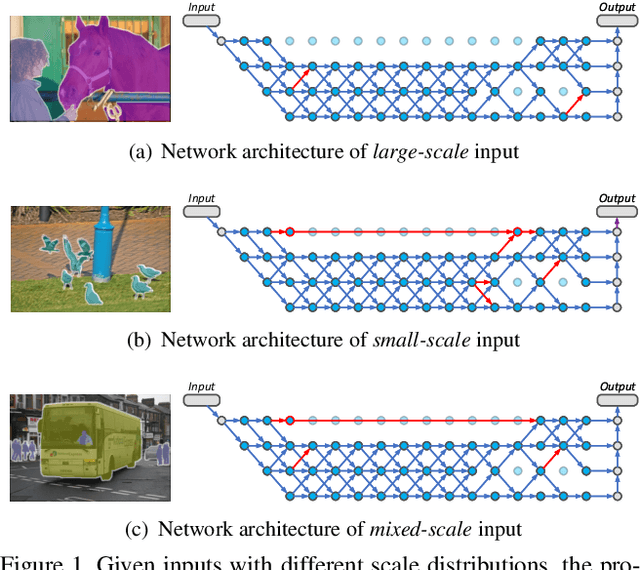
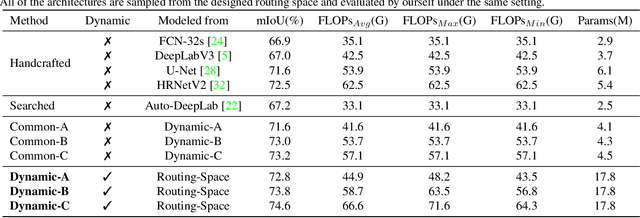
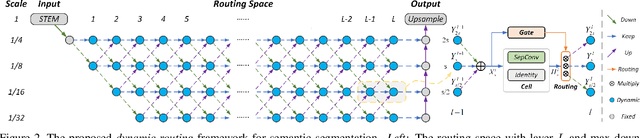
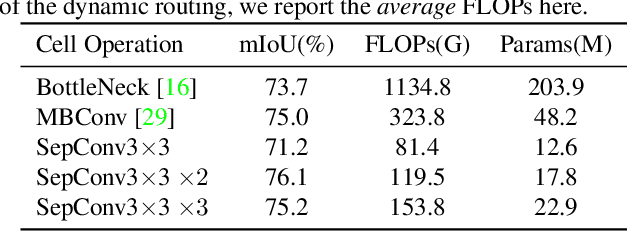
Recently, numerous handcrafted and searched networks have been applied for semantic segmentation. However, previous works intend to handle inputs with various scales in pre-defined static architectures, such as FCN, U-Net, and DeepLab series. This paper studies a conceptually new method to alleviate the scale variance in semantic representation, named dynamic routing. The proposed framework generates data-dependent routes, adapting to the scale distribution of each image. To this end, a differentiable gating function, called soft conditional gate, is proposed to select scale transform paths on the fly. In addition, the computational cost can be further reduced in an end-to-end manner by giving budget constraints to the gating function. We further relax the network level routing space to support multi-path propagations and skip-connections in each forward, bringing substantial network capacity. To demonstrate the superiority of the dynamic property, we compare with several static architectures, which can be modeled as special cases in the routing space. Extensive experiments are conducted on Cityscapes and PASCAL VOC 2012 to illustrate the effectiveness of the dynamic framework. Code is available at https://github.com/yanwei-li/DynamicRouting.
Detection in Crowded Scenes: One Proposal, Multiple Predictions
Mar 20, 2020
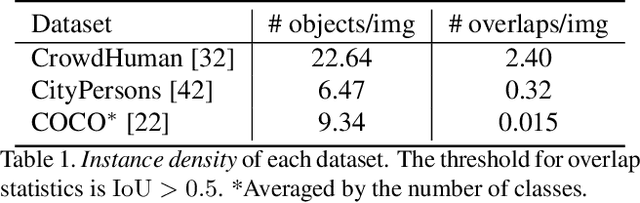
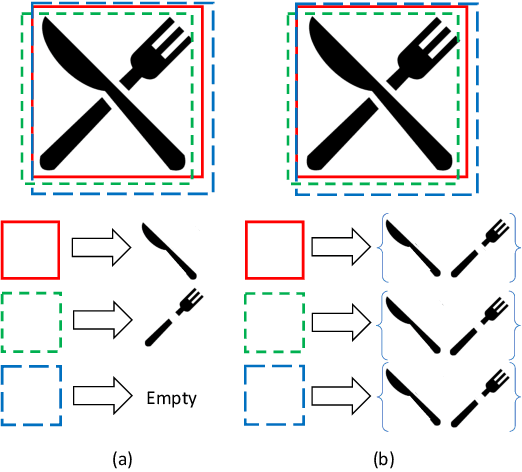
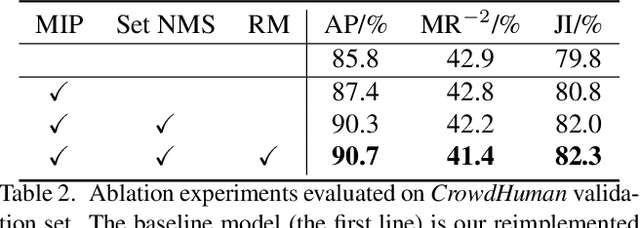
We propose a simple yet effective proposal-based object detector, aiming at detecting highly-overlapped instances in crowded scenes. The key of our approach is to let each proposal predict a set of correlated instances rather than a single one in previous proposal-based frameworks. Equipped with new techniques such as EMD Loss and Set NMS, our detector can effectively handle the difficulty of detecting highly overlapped objects. On a FPN-Res50 baseline, our detector can obtain 4.9\% AP gains on challenging CrowdHuman dataset and 1.0\% $\text{MR}^{-2}$ improvements on CityPersons dataset, without bells and whistles. Moreover, on less crowed datasets like COCO, our approach can still achieve moderate improvement, suggesting the proposed method is robust to crowdedness. Code and pre-trained models will be released at https://github.com/megvii-model/CrowdDetection.
PointINS: Point-based Instance Segmentation
Mar 13, 2020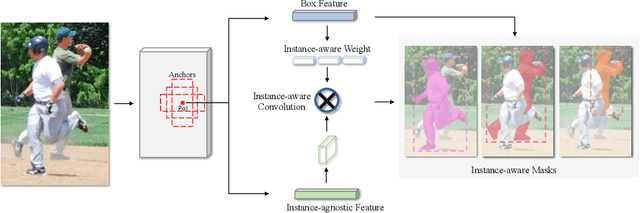

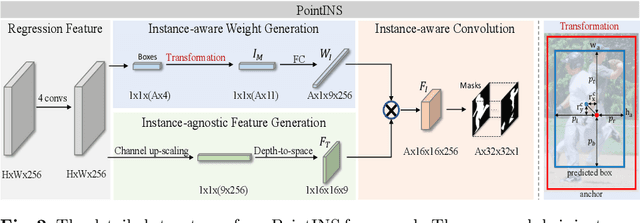
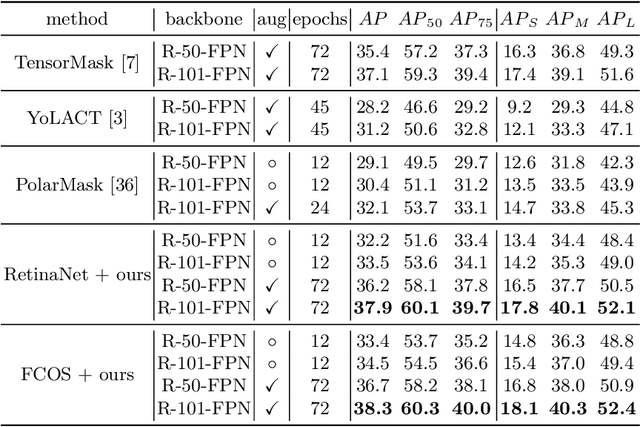
A single-point feature has shown its effectiveness in object detection. However, for instance segmentation, it does not lead to satisfactory results. The reasons are two folds. Firstly, it has limited representation capacity. Secondly, it could be misaligned with potential instances. To address the above issues, we propose a new point-based framework, namely PointINS, to segment instances from single points. The core module of our framework is instance-aware convolution, including the instance-agnostic feature and instance-aware weights. Instance-agnostic feature for each Point-of-Interest (PoI) serves as a template for potential instance masks. In this way, instance-aware features are computed by convolving this template with instance-aware weights for following mask prediction. Given the independence of instance-aware convolution, PointINS is general and practical as a one-stage detector for anchor-based and anchor-free frameworks. In our extensive experiments, we show the effectiveness of our framework on RetinaNet and FCOS. With ResNet101 backbone, PointINS achieves 38.3 mask mAP on challenging COCO dataset, outperforming its competitors by a large margin. The code will be made publicly available.
Learning Delicate Local Representations for Multi-Person Pose Estimation
Mar 10, 2020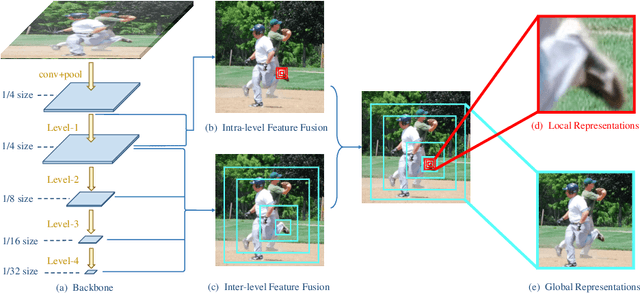
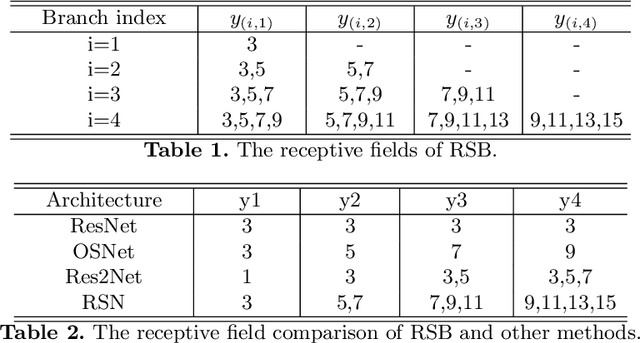
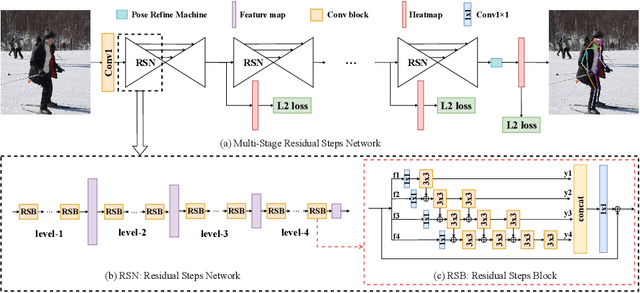
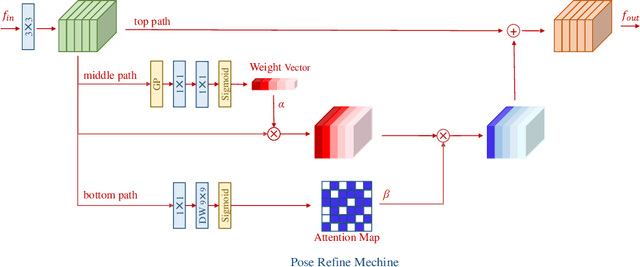
In this paper, we propose a novel method called Residual Steps Network (RSN). RSN aggregates features with the same spatialsize (Intra-level features) efficiently to obtain delicate local representations, which retain rich low-level spatial information and result in pre-cise keypoint localization. In addition, we propose an efficient attention mechanism - Pose Refine Machine (PRM) to further refine the keypointlocations. Our approach won the 1st place of COCO Keypoint Challenge 2019 and achieves state-of-the-art results on both COCO and MPII benchmarks, without using extra training data and pretrained model. Our single model achieves 78.6 on COCO test-dev, 93.0 on MPII test dataset. Ensembled models achieve 79.2 on COCO test-dev, 77.1 on COCO test-challenge dataset. The source code is publicly available for further research at https://github.com/caiyuanhao1998/RSN