 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBSRT: Improving Burst Super-Resolution with Swin Transformer and Flow-Guided Deformable Alignment
Apr 22, 2022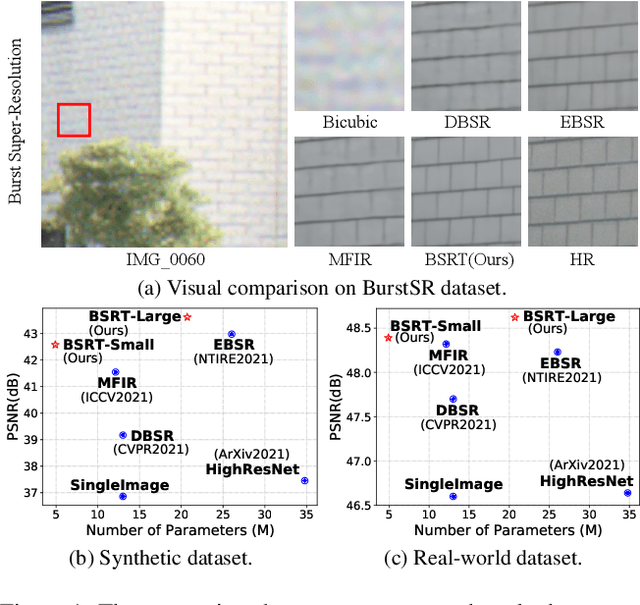
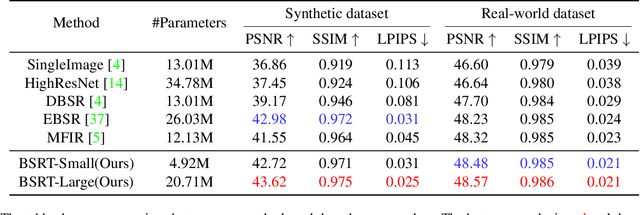
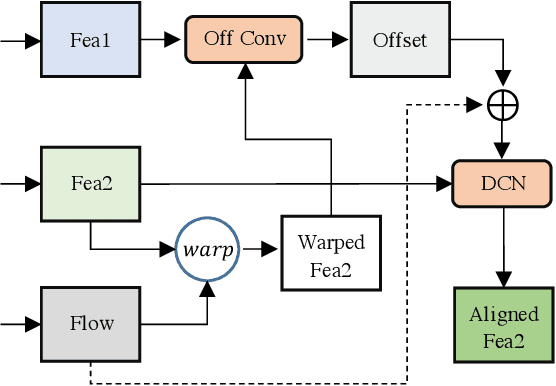
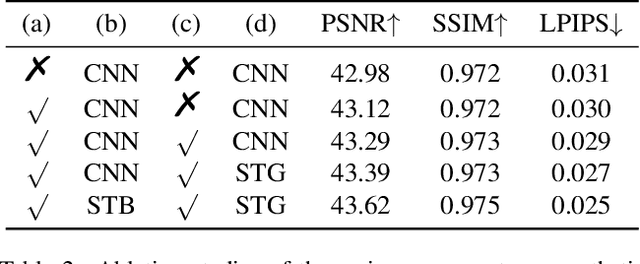
This work addresses the Burst Super-Resolution (BurstSR) task using a new architecture, which requires restoring a high-quality image from a sequence of noisy, misaligned, and low-resolution RAW bursts. To overcome the challenges in BurstSR, we propose a Burst Super-Resolution Transformer (BSRT), which can significantly improve the capability of extracting inter-frame information and reconstruction. To achieve this goal, we propose a Pyramid Flow-Guided Deformable Convolution Network (Pyramid FG-DCN) and incorporate Swin Transformer Blocks and Groups as our main backbone. More specifically, we combine optical flows and deformable convolutions, hence our BSRT can handle misalignment and aggregate the potential texture information in multi-frames more efficiently. In addition, our Transformer-based structure can capture long-range dependency to further improve the performance. The evaluation on both synthetic and real-world tracks demonstrates that our approach achieves a new state-of-the-art in BurstSR task. Further, our BSRT wins the championship in the NTIRE2022 Burst Super-Resolution Challenge.
When NAS Meets Trees: An Efficient Algorithm for Neural Architecture Search
Apr 11, 2022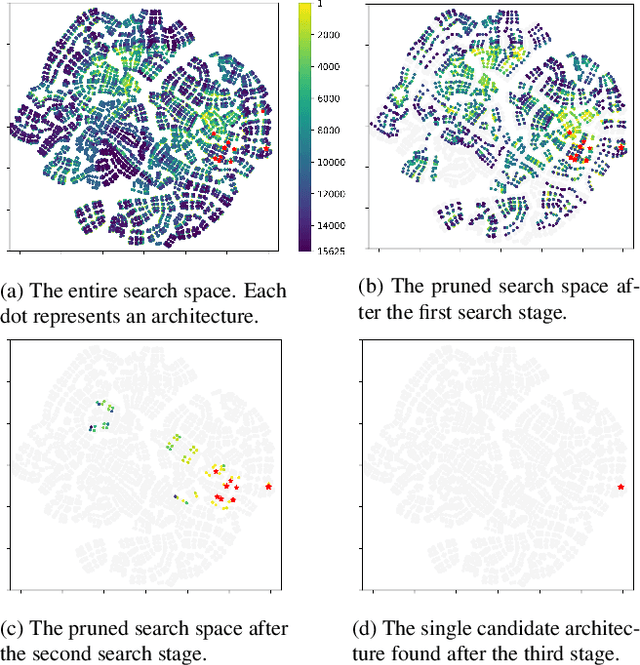
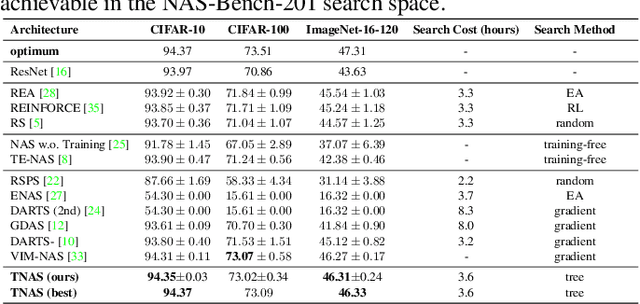
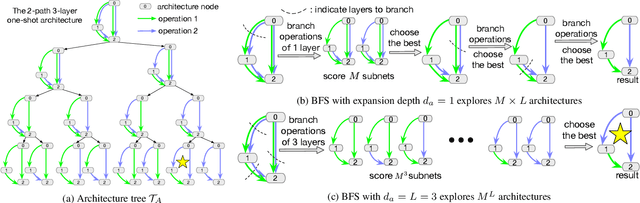
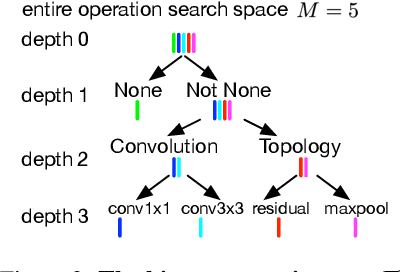
The key challenge in neural architecture search (NAS) is designing how to explore wisely in the huge search space. We propose a new NAS method called TNAS (NAS with trees), which improves search efficiency by exploring only a small number of architectures while also achieving a higher search accuracy. TNAS introduces an architecture tree and a binary operation tree, to factorize the search space and substantially reduce the exploration size. TNAS performs a modified bi-level Breadth-First Search in the proposed trees to discover a high-performance architecture. Impressively, TNAS finds the global optimal architecture on CIFAR-10 with test accuracy of 94.37\% in four GPU hours in NAS-Bench-201. The average test accuracy is 94.35\%, which outperforms the state-of-the-art. Code is available at: \url{https://github.com/guochengqian/TNAS}.
Simple Baselines for Image Restoration
Apr 10, 2022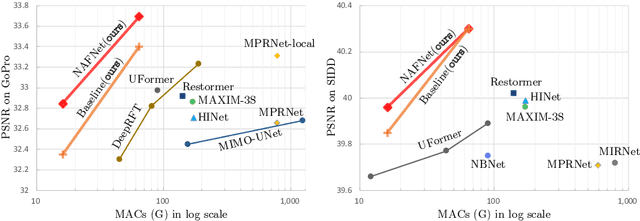

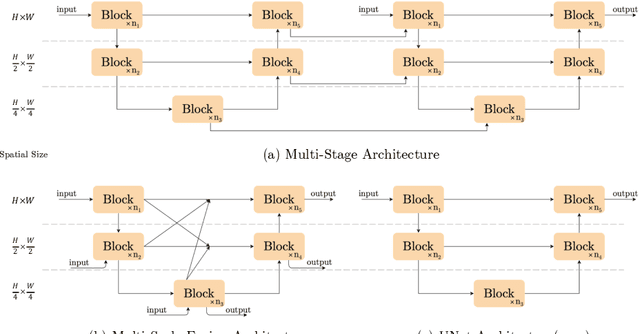
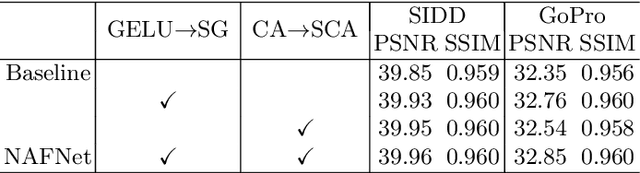
Although there have been significant advances in the field of image restoration recently, the system complexity of the state-of-the-art (SOTA) methods is increasing as well, which may hinder the convenient analysis and comparison of methods. In this paper, we propose a simple baseline that exceeds the SOTA methods and is computationally efficient. To further simplify the baseline, we reveal that the nonlinear activation functions, e.g. Sigmoid, ReLU, GELU, Softmax, etc. are not necessary: they could be replaced by multiplication or removed. Thus, we derive a Nonlinear Activation Free Network, namely NAFNet, from the baseline. SOTA results are achieved on various challenging benchmarks, e.g. 33.69 dB PSNR on GoPro (for image deblurring), exceeding the previous SOTA 0.38 dB with only 8.4% of its computational costs; 40.30 dB PSNR on SIDD (for image denoising), exceeding the previous SOTA 0.28 dB with less than half of its computational costs. The code and the pretrained models will be released at https://github.com/megvii-research/NAFNet.
Scaling Up Your Kernels to 31x31: Revisiting Large Kernel Design in CNNs
Apr 02, 2022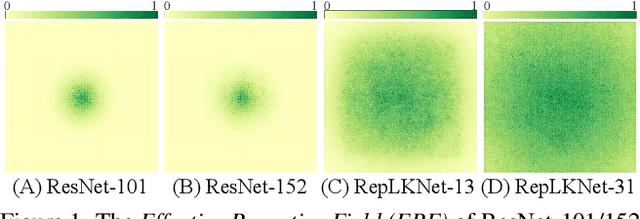
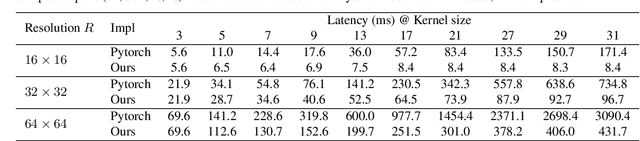


We revisit large kernel design in modern convolutional neural networks (CNNs). Inspired by recent advances in vision transformers (ViTs), in this paper, we demonstrate that using a few large convolutional kernels instead of a stack of small kernels could be a more powerful paradigm. We suggested five guidelines, e.g., applying re-parameterized large depth-wise convolutions, to design efficient high-performance large-kernel CNNs. Following the guidelines, we propose RepLKNet, a pure CNN architecture whose kernel size is as large as 31x31, in contrast to commonly used 3x3. RepLKNet greatly closes the performance gap between CNNs and ViTs, e.g., achieving comparable or superior results than Swin Transformer on ImageNet and a few typical downstream tasks, with lower latency. RepLKNet also shows nice scalability to big data and large models, obtaining 87.8% top-1 accuracy on ImageNet and 56.0% mIoU on ADE20K, which is very competitive among the state-of-the-arts with similar model sizes. Our study further reveals that, in contrast to small-kernel CNNs, large-kernel CNNs have much larger effective receptive fields and higher shape bias rather than texture bias. Code & models at https://github.com/megvii-research/RepLKNet.
Towards Self-Supervised Category-Level Object Pose and Size Estimation
Mar 31, 2022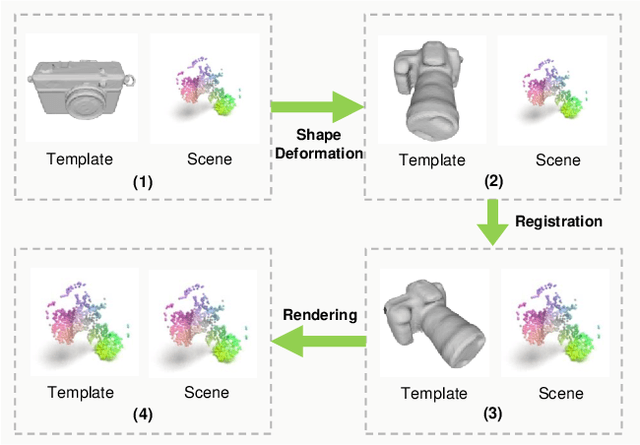

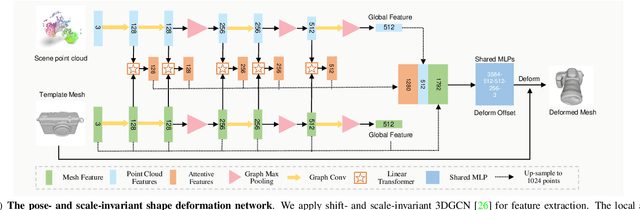
In this work, we tackle the challenging problem of category-level object pose and size estimation from a single depth image. Although previous fully-supervised works have demonstrated promising performance, collecting ground-truth pose labels is generally time-consuming and labor-intensive. Instead, we propose a label-free method that learns to enforce the geometric consistency between category template mesh and observed object point cloud under a self-supervision manner. Specifically, our method consists of three key components: differentiable shape deformation, registration, and rendering. In particular, shape deformation and registration are applied to the template mesh to eliminate the differences in shape, pose and scale. A differentiable renderer is then deployed to enforce geometric consistency between point clouds lifted from the rendered depth and the observed scene for self-supervision. We evaluate our approach on real-world datasets and find that our approach outperforms the simple traditional baseline by large margins while being competitive with some fully-supervised approaches.
Real-time Object Detection for Streaming Perception
Mar 29, 2022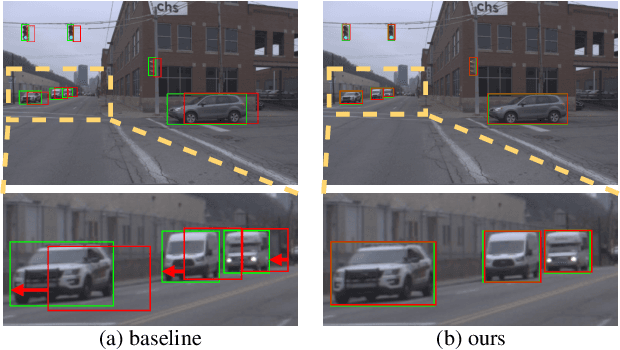

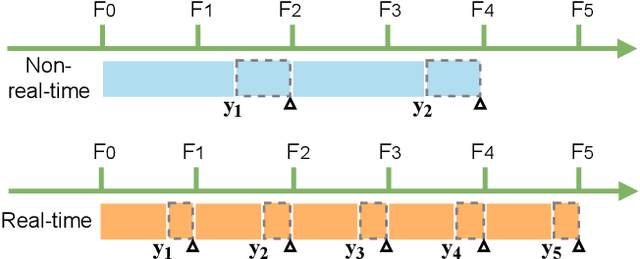
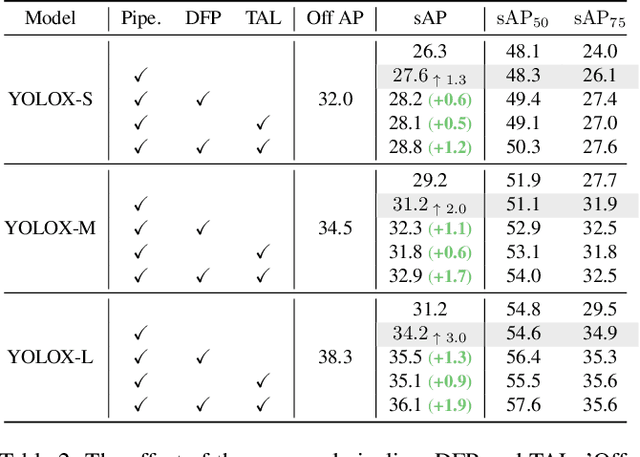
Autonomous driving requires the model to perceive the environment and (re)act within a low latency for safety. While past works ignore the inevitable changes in the environment after processing, streaming perception is proposed to jointly evaluate the latency and accuracy into a single metric for video online perception. In this paper, instead of searching trade-offs between accuracy and speed like previous works, we point out that endowing real-time models with the ability to predict the future is the key to dealing with this problem. We build a simple and effective framework for streaming perception. It equips a novel DualFlow Perception module (DFP), which includes dynamic and static flows to capture the moving trend and basic detection feature for streaming prediction. Further, we introduce a Trend-Aware Loss (TAL) combined with a trend factor to generate adaptive weights for objects with different moving speeds. Our simple method achieves competitive performance on Argoverse-HD dataset and improves the AP by 4.9% compared to the strong baseline, validating its effectiveness. Our code will be made available at https://github.com/yancie-yjr/StreamYOLO.
FS6D: Few-Shot 6D Pose Estimation of Novel Objects
Mar 28, 2022

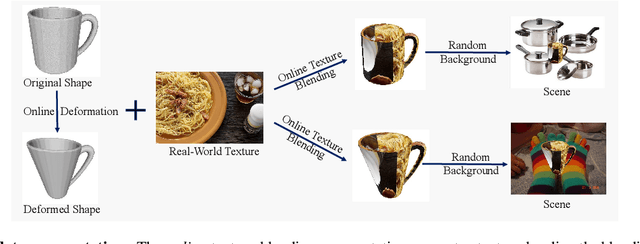
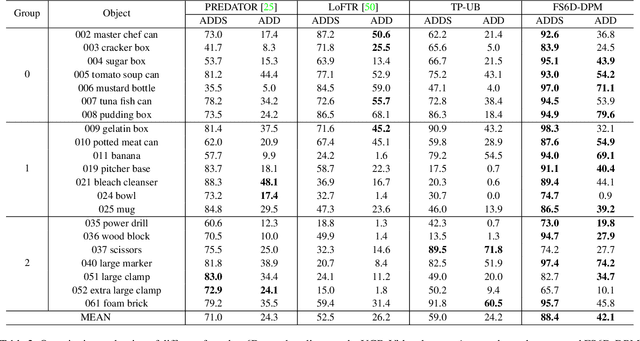
6D object pose estimation networks are limited in their capability to scale to large numbers of object instances due to the close-set assumption and their reliance on high-fidelity object CAD models. In this work, we study a new open set problem; the few-shot 6D object poses estimation: estimating the 6D pose of an unknown object by a few support views without extra training. To tackle the problem, we point out the importance of fully exploring the appearance and geometric relationship between the given support views and query scene patches and propose a dense prototypes matching framework by extracting and matching dense RGBD prototypes with transformers. Moreover, we show that the priors from diverse appearances and shapes are crucial to the generalization capability under the problem setting and thus propose a large-scale RGBD photorealistic dataset (ShapeNet6D) for network pre-training. A simple and effective online texture blending approach is also introduced to eliminate the domain gap from the synthesis dataset, which enriches appearance diversity at a low cost. Finally, we discuss possible solutions to this problem and establish benchmarks on popular datasets to facilitate future research. The project page is at \url{https://fs6d.github.io/}.
Boosting Black-Box Adversarial Attacks with Meta Learning
Mar 28, 2022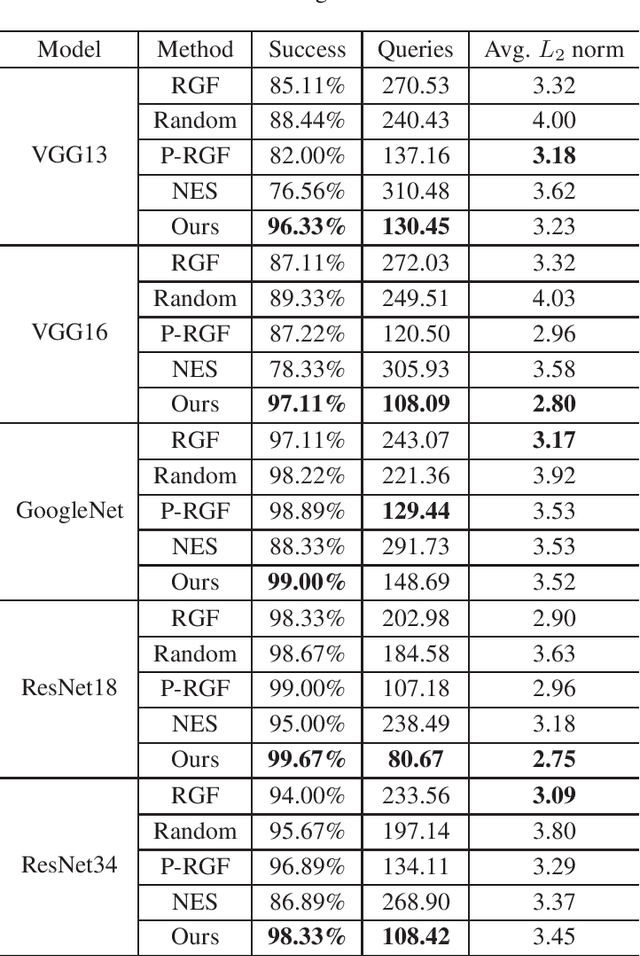

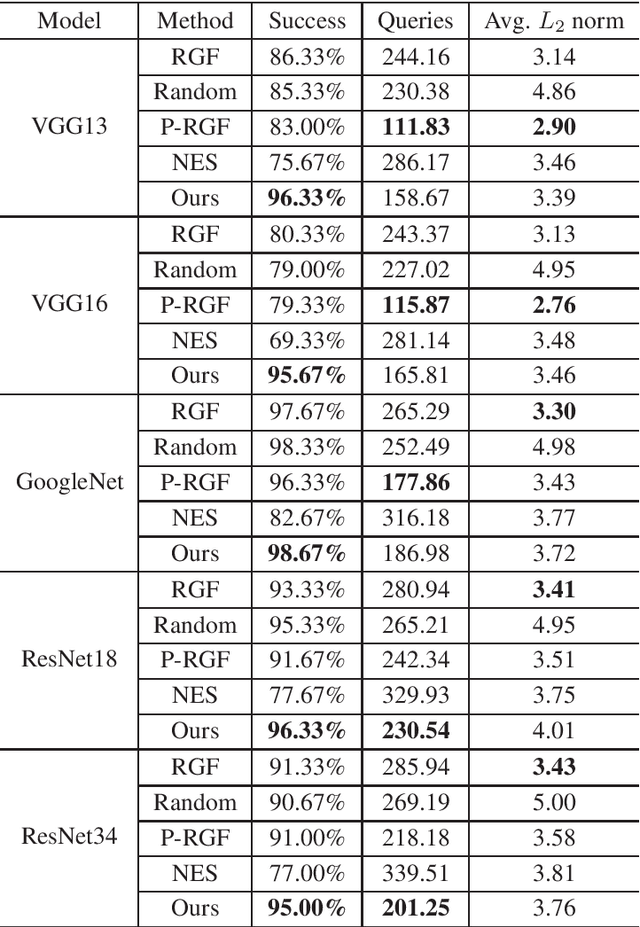
Deep neural networks (DNNs) have achieved remarkable success in diverse fields. However, it has been demonstrated that DNNs are very vulnerable to adversarial examples even in black-box settings. A large number of black-box attack methods have been proposed to in the literature. However, those methods usually suffer from low success rates and large query counts, which cannot fully satisfy practical purposes. In this paper, we propose a hybrid attack method which trains meta adversarial perturbations (MAPs) on surrogate models and performs black-box attacks by estimating gradients of the models. Our method uses the meta adversarial perturbation as an initialization and subsequently trains any black-box attack method for several epochs. Furthermore, the MAPs enjoy favorable transferability and universality, in the sense that they can be employed to boost performance of other black-box adversarial attack methods. Extensive experiments demonstrate that our method can not only improve the attack success rates, but also reduces the number of queries compared to other methods.
Improving Meta-learning for Low-resource Text Classification and Generation via Memory Imitation
Mar 22, 2022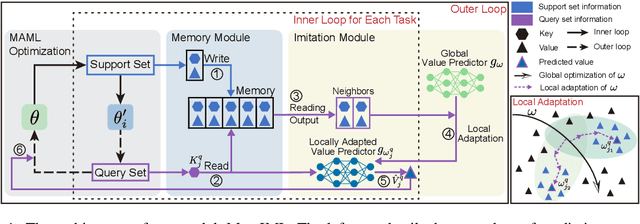
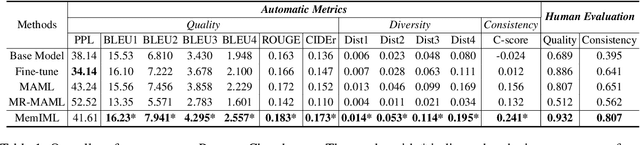
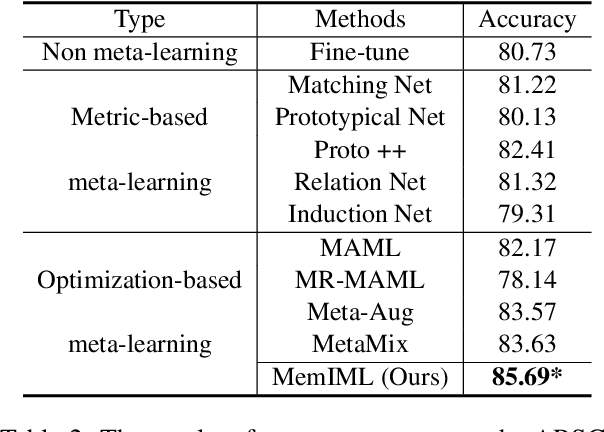
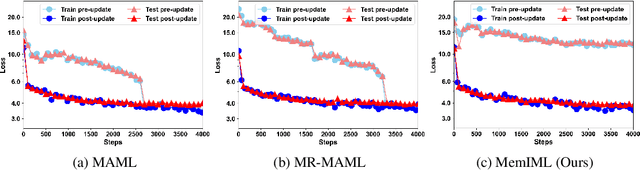
Building models of natural language processing (NLP) is challenging in low-resource scenarios where only limited data are available. Optimization-based meta-learning algorithms achieve promising results in low-resource scenarios by adapting a well-generalized model initialization to handle new tasks. Nonetheless, these approaches suffer from the memorization overfitting issue, where the model tends to memorize the meta-training tasks while ignoring support sets when adapting to new tasks. To address this issue, we propose a memory imitation meta-learning (MemIML) method that enhances the model's reliance on support sets for task adaptation. Specifically, we introduce a task-specific memory module to store support set information and construct an imitation module to force query sets to imitate the behaviors of some representative support-set samples stored in the memory. A theoretical analysis is provided to prove the effectiveness of our method, and empirical results also demonstrate that our method outperforms competitive baselines on both text classification and generation tasks.
Rebalanced Siamese Contrastive Mining for Long-Tailed Recognition
Mar 22, 2022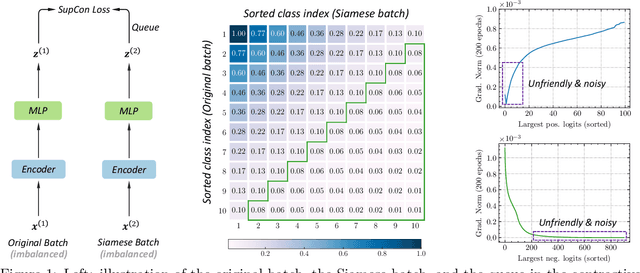
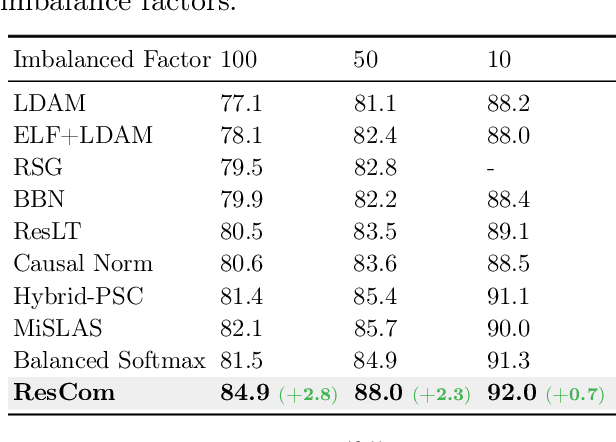
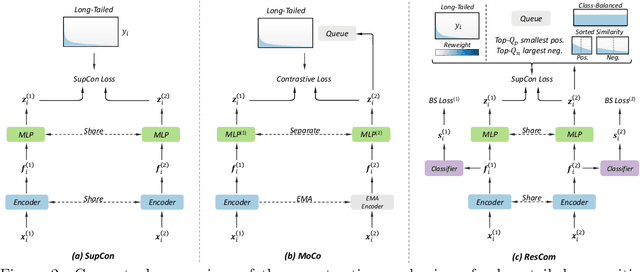
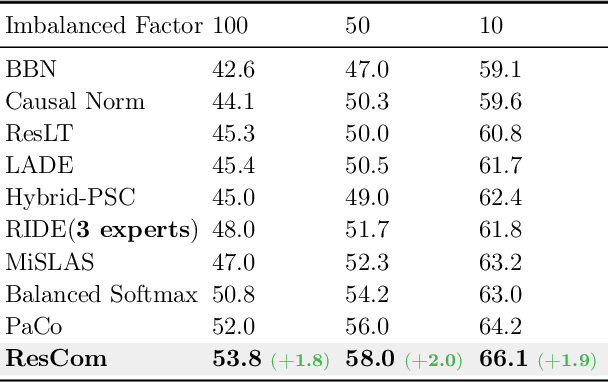
Deep neural networks perform poorly on heavily class-imbalanced datasets. Given the promising performance of contrastive learning, we propose $\mathbf{Re}$balanced $\mathbf{S}$iamese $\mathbf{Co}$ntrastive $\mathbf{m}$ining ( $\mathbf{ResCom}$) to tackle imbalanced recognition. Based on the mathematical analysis and simulation results, we claim that supervised contrastive learning suffers a dual class-imbalance problem at both the original batch and Siamese batch levels, which is more serious than long-tailed classification learning. In this paper, at the original batch level, we introduce a class-balanced supervised contrastive loss to assign adaptive weights for different classes. At the Siamese batch level, we present a class-balanced queue, which maintains the same number of keys for all classes. Furthermore, we note that the contrastive loss gradient with respect to the contrastive logits can be decoupled into the positives and negatives, and easy positives and easy negatives will make the contrastive gradient vanish. We propose supervised hard positive and negative pairs mining to pick up informative pairs for contrastive computation and improve representation learning. Finally, to approximately maximize the mutual information between the two views, we propose Siamese Balanced Softmax and joint it with the contrastive loss for one-stage training. ResCom outperforms the previous methods by large margins on multiple long-tailed recognition benchmarks. Our code will be made publicly available at: https://github.com/dvlab-research/ResCom.