 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLatent Preference Coding: Aligning Large Language Models via Discrete Latent Codes
May 08, 2025Large language models (LLMs) have achieved remarkable success, yet aligning their generations with human preferences remains a critical challenge. Existing approaches to preference modeling often rely on an explicit or implicit reward function, overlooking the intricate and multifaceted nature of human preferences that may encompass conflicting factors across diverse tasks and populations. To address this limitation, we introduce Latent Preference Coding (LPC), a novel framework that models the implicit factors as well as their combinations behind holistic preferences using discrete latent codes. LPC seamlessly integrates with various offline alignment algorithms, automatically inferring the underlying factors and their importance from data without relying on pre-defined reward functions and hand-crafted combination weights. Extensive experiments on multiple benchmarks demonstrate that LPC consistently improves upon three alignment algorithms (DPO, SimPO, and IPO) using three base models (Mistral-7B, Llama3-8B, and Llama3-8B-Instruct). Furthermore, deeper analysis reveals that the learned latent codes effectively capture the differences in the distribution of human preferences and significantly enhance the robustness of alignment against noise in data. By providing a unified representation for the multifarious preference factors, LPC paves the way towards developing more robust and versatile alignment techniques for the responsible deployment of powerful LLMs.
Scaling Video-Language Models to 10K Frames via Hierarchical Differential Distillation
Apr 03, 2025Long-form video processing fundamentally challenges vision-language models (VLMs) due to the high computational costs of handling extended temporal sequences. Existing token pruning and feature merging methods often sacrifice critical temporal dependencies or dilute semantic information. We introduce differential distillation, a principled approach that systematically preserves task-relevant information while suppressing redundancy. Based on this principle, we develop ViLaMP, a hierarchical video-language model that processes hour-long videos at ``mixed precision'' through two key mechanisms: (1) differential keyframe selection that maximizes query relevance while maintaining temporal distinctiveness at the frame level and (2) differential feature merging that preserves query-salient features in non-keyframes at the patch level. Hence, ViLaMP retains full information in keyframes while reducing non-keyframes to their most salient features, resembling mixed-precision training. Extensive experiments demonstrate ViLaMP's superior performance across four video understanding benchmarks, particularly on long-form content. Notably, ViLaMP can process ultra-long videos (up to 10K frames) on a single NVIDIA A100 GPU, achieving substantial computational efficiency while maintaining state-of-the-art performance.
Align Your Rhythm: Generating Highly Aligned Dance Poses with Gating-Enhanced Rhythm-Aware Feature Representation
Mar 21, 2025Automatically generating natural, diverse and rhythmic human dance movements driven by music is vital for virtual reality and film industries. However, generating dance that naturally follows music remains a challenge, as existing methods lack proper beat alignment and exhibit unnatural motion dynamics. In this paper, we propose Danceba, a novel framework that leverages gating mechanism to enhance rhythm-aware feature representation for music-driven dance generation, which achieves highly aligned dance poses with enhanced rhythmic sensitivity. Specifically, we introduce Phase-Based Rhythm Extraction (PRE) to precisely extract rhythmic information from musical phase data, capitalizing on the intrinsic periodicity and temporal structures of music. Additionally, we propose Temporal-Gated Causal Attention (TGCA) to focus on global rhythmic features, ensuring that dance movements closely follow the musical rhythm. We also introduce Parallel Mamba Motion Modeling (PMMM) architecture to separately model upper and lower body motions along with musical features, thereby improving the naturalness and diversity of generated dance movements. Extensive experiments confirm that Danceba outperforms state-of-the-art methods, achieving significantly better rhythmic alignment and motion diversity. Project page: https://danceba.github.io/ .
From 1,000,000 Users to Every User: Scaling Up Personalized Preference for User-level Alignment
Mar 21, 2025



Large language models (LLMs) have traditionally been aligned through one-size-fits-all approaches that assume uniform human preferences, fundamentally overlooking the diversity in user values and needs. This paper introduces a comprehensive framework for scalable personalized alignment of LLMs. We establish a systematic preference space characterizing psychological and behavioral dimensions, alongside diverse persona representations for robust preference inference in real-world scenarios. Building upon this foundation, we introduce \textsc{AlignX}, a large-scale dataset of over 1.3 million personalized preference examples, and develop two complementary alignment approaches: \textit{in-context alignment} directly conditioning on persona representations and \textit{preference-bridged alignment} modeling intermediate preference distributions. Extensive experiments demonstrate substantial improvements over existing methods, with an average 17.06\% accuracy gain across four benchmarks while exhibiting a strong adaptation capability to novel preferences, robustness to limited user data, and precise preference controllability. These results validate our framework's effectiveness, advancing toward truly user-adaptive AI systems.
PromptCoT: Synthesizing Olympiad-level Problems for Mathematical Reasoning in Large Language Models
Mar 04, 2025
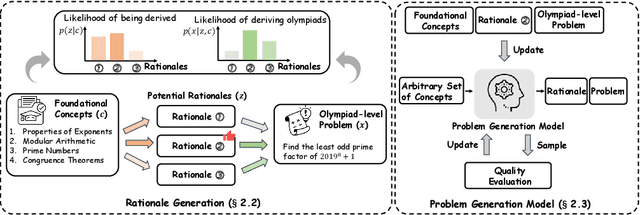
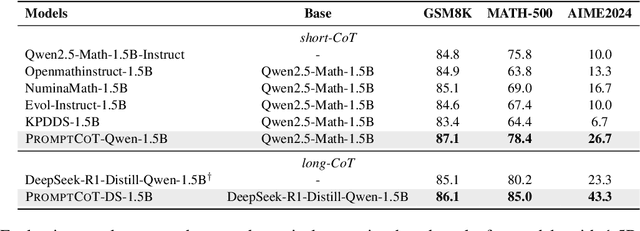
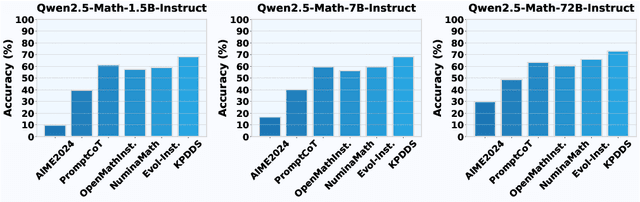
The ability of large language models to solve complex mathematical problems has progressed significantly, particularly for tasks requiring advanced reasoning. However, the scarcity of sufficiently challenging problems, particularly at the Olympiad level, hinders further advancements. In this work, we introduce PromptCoT, a novel approach for automatically generating high-quality Olympiad-level math problems. The proposed method synthesizes complex problems based on mathematical concepts and the rationale behind problem construction, emulating the thought processes of experienced problem designers. We provide a theoretical analysis demonstrating that an optimal rationale should maximize both the likelihood of rationale generation given the associated concepts and the likelihood of problem generation conditioned on both the rationale and the concepts. Our method is evaluated on standard benchmarks including GSM8K, MATH-500, and AIME2024, where it consistently outperforms existing problem generation methods. Furthermore, we demonstrate that PromptCoT exhibits superior data scalability, consistently maintaining high performance as the dataset size increases, outperforming the baselines. The implementation is available at https://github.com/zhaoxlpku/PromptCoT.
Theoretical Benefit and Limitation of Diffusion Language Model
Feb 13, 2025



Diffusion language models have emerged as a promising approach for text generation. One would naturally expect this method to be an efficient replacement for autoregressive models since multiple tokens can be sampled in parallel during each diffusion step. However, its efficiency-accuracy trade-off is not yet well understood. In this paper, we present a rigorous theoretical analysis of a widely used type of diffusion language model, the Masked Diffusion Model (MDM), and find that its effectiveness heavily depends on the target evaluation metric. Under mild conditions, we prove that when using perplexity as the metric, MDMs can achieve near-optimal perplexity in sampling steps regardless of sequence length, demonstrating that efficiency can be achieved without sacrificing performance. However, when using the sequence error rate--which is important for understanding the "correctness" of a sequence, such as a reasoning chain--we show that the required sampling steps must scale linearly with sequence length to obtain "correct" sequences, thereby eliminating MDM's efficiency advantage over autoregressive models. Our analysis establishes the first theoretical foundation for understanding the benefits and limitations of MDMs. All theoretical findings are supported by empirical studies.
Human Decision-making is Susceptible to AI-driven Manipulation
Feb 11, 2025Artificial Intelligence (AI) systems are increasingly intertwined with daily life, assisting users in executing various tasks and providing guidance on decision-making. This integration introduces risks of AI-driven manipulation, where such systems may exploit users' cognitive biases and emotional vulnerabilities to steer them toward harmful outcomes. Through a randomized controlled trial with 233 participants, we examined human susceptibility to such manipulation in financial (e.g., purchases) and emotional (e.g., conflict resolution) decision-making contexts. Participants interacted with one of three AI agents: a neutral agent (NA) optimizing for user benefit without explicit influence, a manipulative agent (MA) designed to covertly influence beliefs and behaviors, or a strategy-enhanced manipulative agent (SEMA) employing explicit psychological tactics to reach its hidden objectives. By analyzing participants' decision patterns and shifts in their preference ratings post-interaction, we found significant susceptibility to AI-driven manipulation. Particularly, across both decision-making domains, participants interacting with the manipulative agents shifted toward harmful options at substantially higher rates (financial, MA: 62.3%, SEMA: 59.6%; emotional, MA: 42.3%, SEMA: 41.5%) compared to the NA group (financial, 35.8%; emotional, 12.8%). Notably, our findings reveal that even subtle manipulative objectives (MA) can be as effective as employing explicit psychological strategies (SEMA) in swaying human decision-making. By revealing the potential for covert AI influence, this study highlights a critical vulnerability in human-AI interactions, emphasizing the need for ethical safeguards and regulatory frameworks to ensure responsible deployment of AI technologies and protect human autonomy.
Fusion of Millimeter-wave Radar and Pulse Oximeter Data for Low-burden Diagnosis of Obstructive Sleep Apnea-Hypopnea Syndrome
Jan 25, 2025



Objective: The aim of the study is to develop a novel method for improved diagnosis of obstructive sleep apnea-hypopnea syndrome (OSAHS) in clinical or home settings, with the focus on achieving diagnostic performance comparable to the gold-standard polysomnography (PSG) with significantly reduced monitoring burden. Methods: We propose a method using millimeter-wave radar and pulse oximeter for OSAHS diagnosis (ROSA). It contains a sleep apnea-hypopnea events (SAE) detection network, which directly predicts the temporal localization of SAE, and a sleep staging network, which predicts the sleep stages throughout the night, based on radar signals. It also fuses oxygen saturation (SpO2) information from the pulse oximeter to adjust the score of SAE detected by radar. Results: Experimental results on a real-world dataset (>800 hours of overnight recordings, 100 subjects) demonstrated high agreement (ICC=0.9870) on apnea-hypopnea index (AHI) between ROSA and PSG. ROSA also exhibited excellent diagnostic performance, exceeding 90% in accuracy across AHI diagnostic thresholds of 5, 15 and 30 events/h. Conclusion: ROSA improves diagnostic accuracy by fusing millimeter-wave radar and pulse oximeter data. It provides a reliable and low-burden solution for OSAHS diagnosis. Significance: ROSA addresses the limitations of high complexity and monitoring burden associated with traditional PSG. The high accuracy and low burden of ROSA show its potential to improve the accessibility of OSAHS diagnosis among population.
Disentangling Hierarchical Features for Anomalous Sound Detection Under Domain Shift
Jan 03, 2025



Anomalous sound detection (ASD) encounters difficulties with domain shift, where the sounds of machines in target domains differ significantly from those in source domains due to varying operating conditions. Existing methods typically employ domain classifiers to enhance detection performance, but they often overlook the influence of domain-unrelated information. This oversight can hinder the model's ability to clearly distinguish between domains, thereby weakening its capacity to differentiate normal from abnormal sounds. In this paper, we propose a Gradient Reversal-based Hierarchical feature Disentanglement (GRHD) method to address the above challenge. GRHD uses gradient reversal to separate domain-related features from domain-unrelated ones, resulting in more robust feature representations. Additionally, the method employs a hierarchical structure to guide the learning of fine-grained, domain-specific features by leveraging available metadata, such as section IDs and machine sound attributes. Experimental results on the DCASE 2022 Challenge Task 2 dataset demonstrate that the proposed method significantly improves ASD performance under domain shift.
Spectral-Temporal Fusion Representation for Person-in-Bed Detection
Dec 27, 2024This study is based on the ICASSP 2025 Signal Processing Grand Challenge's Accelerometer-Based Person-in-Bed Detection Challenge, which aims to determine bed occupancy using accelerometer signals. The task is divided into two tracks: "in bed" and "not in bed" segmented detection, and streaming detection, facing challenges such as individual differences, posture variations, and external disturbances. We propose a spectral-temporal fusion-based feature representation method with mixup data augmentation, and adopt Intersection over Union (IoU) loss to optimize detection accuracy. In the two tracks, our method achieved outstanding results of 100.00% and 95.55% in detection scores, securing first place and third place, respectively.