 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlign Your Rhythm: Generating Highly Aligned Dance Poses with Gating-Enhanced Rhythm-Aware Feature Representation
Mar 21, 2025Automatically generating natural, diverse and rhythmic human dance movements driven by music is vital for virtual reality and film industries. However, generating dance that naturally follows music remains a challenge, as existing methods lack proper beat alignment and exhibit unnatural motion dynamics. In this paper, we propose Danceba, a novel framework that leverages gating mechanism to enhance rhythm-aware feature representation for music-driven dance generation, which achieves highly aligned dance poses with enhanced rhythmic sensitivity. Specifically, we introduce Phase-Based Rhythm Extraction (PRE) to precisely extract rhythmic information from musical phase data, capitalizing on the intrinsic periodicity and temporal structures of music. Additionally, we propose Temporal-Gated Causal Attention (TGCA) to focus on global rhythmic features, ensuring that dance movements closely follow the musical rhythm. We also introduce Parallel Mamba Motion Modeling (PMMM) architecture to separately model upper and lower body motions along with musical features, thereby improving the naturalness and diversity of generated dance movements. Extensive experiments confirm that Danceba outperforms state-of-the-art methods, achieving significantly better rhythmic alignment and motion diversity. Project page: https://danceba.github.io/ .
FastDrag: Manipulate Anything in One Step
May 24, 2024



Drag-based image editing using generative models provides precise control over image contents, enabling users to manipulate anything in an image with a few clicks. However, prevailing methods typically adopt $n$-step iterations for latent semantic optimization to achieve drag-based image editing, which is time-consuming and limits practical applications. In this paper, we introduce a novel one-step drag-based image editing method, i.e., FastDrag, to accelerate the editing process. Central to our approach is a latent warpage function (LWF), which simulates the behavior of a stretched material to adjust the location of individual pixels within the latent space. This innovation achieves one-step latent semantic optimization and hence significantly promotes editing speeds. Meanwhile, null regions emerging after applying LWF are addressed by our proposed bilateral nearest neighbor interpolation (BNNI) strategy. This strategy interpolates these regions using similar features from neighboring areas, thus enhancing semantic integrity. Additionally, a consistency-preserving strategy is introduced to maintain the consistency between the edited and original images by adopting semantic information from the original image, saved as key and value pairs in self-attention module during diffusion inversion, to guide the diffusion sampling. Our FastDrag is validated on the DragBench dataset, demonstrating substantial improvements in processing time over existing methods, while achieving enhanced editing performance.
CTS: A Consistency-Based Medical Image Segmentation Model
May 15, 2024In medical image segmentation tasks, diffusion models have shown significant potential. However, mainstream diffusion models suffer from drawbacks such as multiple sampling times and slow prediction results. Recently, consistency models, as a standalone generative network, have resolved this issue. Compared to diffusion models, consistency models can reduce the sampling times to once, not only achieving similar generative effects but also significantly speeding up training and prediction. However, they are not suitable for image segmentation tasks, and their application in the medical imaging field has not yet been explored. Therefore, this paper applies the consistency model to medical image segmentation tasks, designing multi-scale feature signal supervision modes and loss function guidance to achieve model convergence. Experiments have verified that the CTS model can obtain better medical image segmentation results with a single sampling during the test phase.
MambaDFuse: A Mamba-based Dual-phase Model for Multi-modality Image Fusion
Apr 12, 2024



Multi-modality image fusion (MMIF) aims to integrate complementary information from different modalities into a single fused image to represent the imaging scene and facilitate downstream visual tasks comprehensively. In recent years, significant progress has been made in MMIF tasks due to advances in deep neural networks. However, existing methods cannot effectively and efficiently extract modality-specific and modality-fused features constrained by the inherent local reductive bias (CNN) or quadratic computational complexity (Transformers). To overcome this issue, we propose a Mamba-based Dual-phase Fusion (MambaDFuse) model. Firstly, a dual-level feature extractor is designed to capture long-range features from single-modality images by extracting low and high-level features from CNN and Mamba blocks. Then, a dual-phase feature fusion module is proposed to obtain fusion features that combine complementary information from different modalities. It uses the channel exchange method for shallow fusion and the enhanced Multi-modal Mamba (M3) blocks for deep fusion. Finally, the fused image reconstruction module utilizes the inverse transformation of the feature extraction to generate the fused result. Through extensive experiments, our approach achieves promising fusion results in infrared-visible image fusion and medical image fusion. Additionally, in a unified benchmark, MambaDFuse has also demonstrated improved performance in downstream tasks such as object detection. Code with checkpoints will be available after the peer-review process.
MuVAM: A Multi-View Attention-based Model for Medical Visual Question Answering
Jul 07, 2021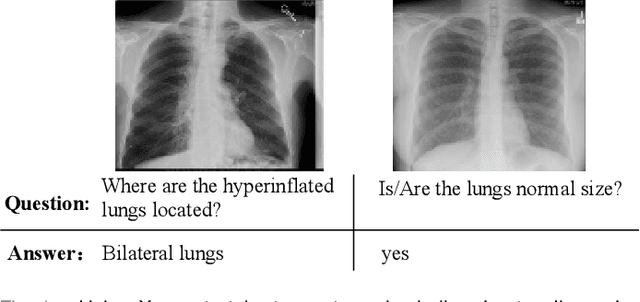
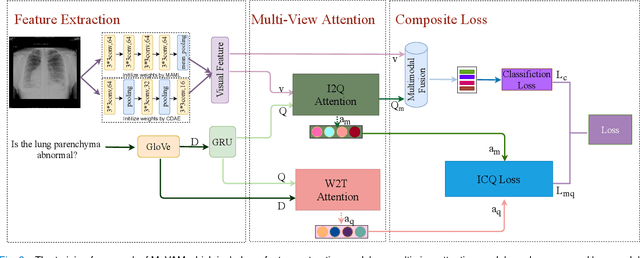
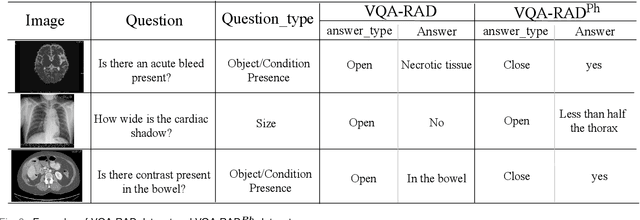
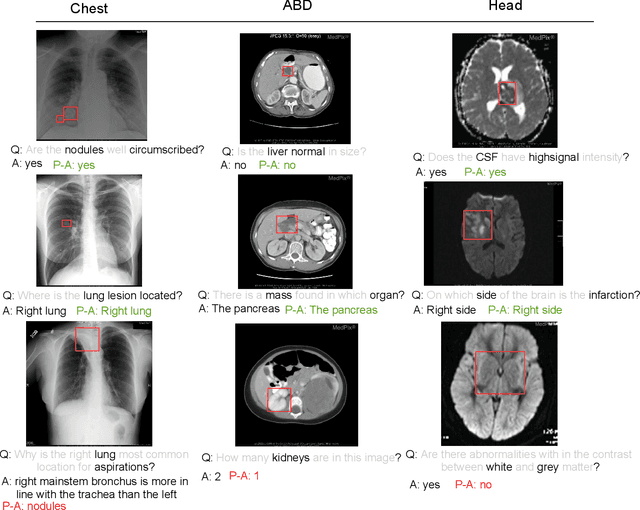
Medical Visual Question Answering (VQA) is a multi-modal challenging task widely considered by research communities of the computer vision and natural language processing. Since most current medical VQA models focus on visual content, ignoring the importance of text, this paper proposes a multi-view attention-based model(MuVAM) for medical visual question answering which integrates the high-level semantics of medical images on the basis of text description. Firstly, different methods are utilized to extract the features of the image and the question for the two modalities of vision and text. Secondly, this paper proposes a multi-view attention mechanism that include Image-to-Question (I2Q) attention and Word-to-Text (W2T) attention. Multi-view attention can correlate the question with image and word in order to better analyze the question and get an accurate answer. Thirdly, a composite loss is presented to predict the answer accurately after multi-modal feature fusion and improve the similarity between visual and textual cross-modal features. It consists of classification loss and image-question complementary (IQC) loss. Finally, for data errors and missing labels in the VQA-RAD dataset, we collaborate with medical experts to correct and complete this dataset and then construct an enhanced dataset, VQA-RADPh. The experiments on these two datasets show that the effectiveness of MuVAM surpasses the state-of-the-art method.