 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpectral-Temporal Fusion Representation for Person-in-Bed Detection
Dec 27, 2024This study is based on the ICASSP 2025 Signal Processing Grand Challenge's Accelerometer-Based Person-in-Bed Detection Challenge, which aims to determine bed occupancy using accelerometer signals. The task is divided into two tracks: "in bed" and "not in bed" segmented detection, and streaming detection, facing challenges such as individual differences, posture variations, and external disturbances. We propose a spectral-temporal fusion-based feature representation method with mixup data augmentation, and adopt Intersection over Union (IoU) loss to optimize detection accuracy. In the two tracks, our method achieved outstanding results of 100.00% and 95.55% in detection scores, securing first place and third place, respectively.
Attacking Voice Anonymization Systems with Augmented Feature and Speaker Identity Difference
Dec 26, 2024

This study focuses on the First VoicePrivacy Attacker Challenge within the ICASSP 2025 Signal Processing Grand Challenge, which aims to develop speaker verification systems capable of determining whether two anonymized speech signals are from the same speaker. However, differences between feature distributions of original and anonymized speech complicate this task. To address this challenge, we propose an attacker system that combines Data Augmentation enhanced feature representation and Speaker Identity Difference enhanced classifier to improve verification performance, termed DA-SID. Specifically, data augmentation strategies (i.e., data fusion and SpecAugment) are utilized to mitigate feature distribution gaps, while probabilistic linear discriminant analysis (PLDA) is employed to further enhance speaker identity difference. Our system significantly outperforms the baseline, demonstrating exceptional effectiveness and robustness against various voice anonymization systems, ultimately securing a top-5 ranking in the challenge.
Recouple Event Field via Probabilistic Bias for Event Extraction
May 19, 2023



Event Extraction (EE), aiming to identify and classify event triggers and arguments from event mentions, has benefited from pre-trained language models (PLMs). However, existing PLM-based methods ignore the information of trigger/argument fields, which is crucial for understanding event schemas. To this end, we propose a Probabilistic reCoupling model enhanced Event extraction framework (ProCE). Specifically, we first model the syntactic-related event fields as probabilistic biases, to clarify the event fields from ambiguous entanglement. Furthermore, considering multiple occurrences of the same triggers/arguments in EE, we explore probabilistic interaction strategies among multiple fields of the same triggers/arguments, to recouple the corresponding clarified distributions and capture more latent information fields. Experiments on EE datasets demonstrate the effectiveness and generalization of our proposed approach.
Dynamic Event-Triggered Discrete-Time Linear Time-Varying System with Privacy-Preservation
Oct 28, 2022This paper focuses on discrete-time wireless sensor networks with privacy-preservation. In practical applications, information exchange between sensors is subject to attacks. For the information leakage caused by the attack during the information transmission process, privacy-preservation is introduced for system states. To make communication resources more effectively utilized, a dynamic event-triggered set-membership estimator is designed. Moreover, the privacy of the system is analyzed to ensure the security of the real data. As a result, the set-membership estimator with differential privacy is analyzed using recursive convex optimization. Then the steady-state performance of the system is studied. Finally, one example is presented to demonstrate the feasibility of the proposed distributed filter containing privacy-preserving analysis.
Multi-stage Distillation Framework for Cross-Lingual Semantic Similarity Matching
Sep 13, 2022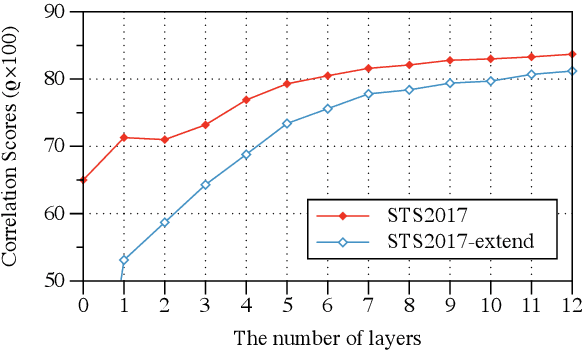
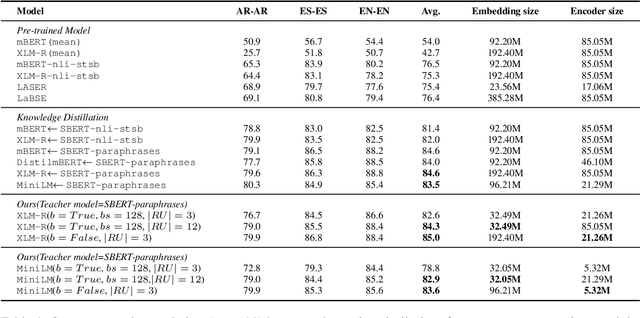
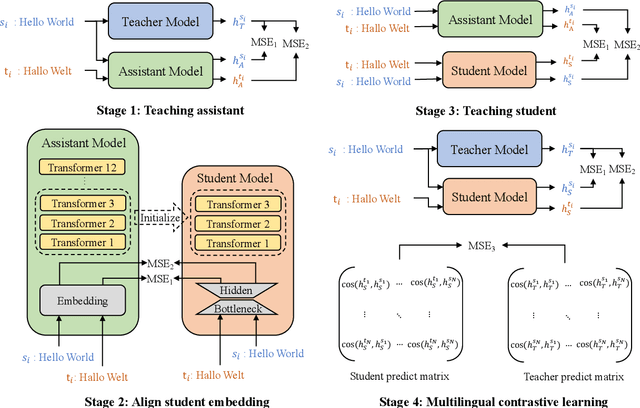
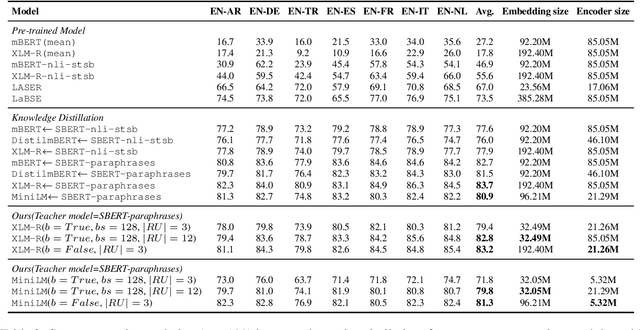
Previous studies have proved that cross-lingual knowledge distillation can significantly improve the performance of pre-trained models for cross-lingual similarity matching tasks. However, the student model needs to be large in this operation. Otherwise, its performance will drop sharply, thus making it impractical to be deployed to memory-limited devices. To address this issue, we delve into cross-lingual knowledge distillation and propose a multi-stage distillation framework for constructing a small-size but high-performance cross-lingual model. In our framework, contrastive learning, bottleneck, and parameter recurrent strategies are combined to prevent performance from being compromised during the compression process. The experimental results demonstrate that our method can compress the size of XLM-R and MiniLM by more than 50\%, while the performance is only reduced by about 1%.
Semantic Matching from Different Perspectives
Feb 14, 2022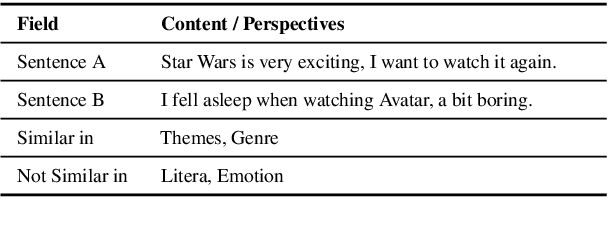
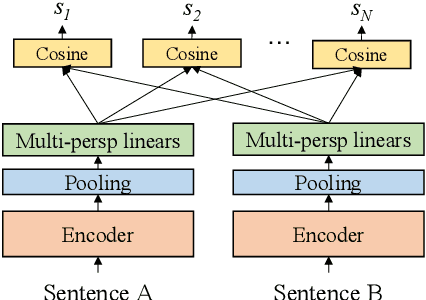
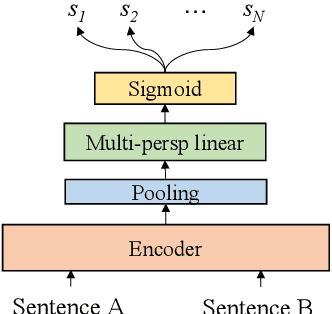

In this paper, we pay attention to the issue which is usually overlooked, i.e., \textit{similarity should be determined from different perspectives}. To explore this issue, we release a Multi-Perspective Text Similarity (MPTS) dataset, in which sentence similarities are labeled from twelve perspectives. Furthermore, we conduct a series of experimental analysis on this task by retrofitting some famous text matching models. Finally, we obtain several conclusions and baseline models, laying the foundation for the following investigation of this issue. The dataset and code are publicly available at Github\footnote{\url{https://github.com/autoliuweijie/MPTS}
TableQA: a Large-Scale Chinese Text-to-SQL Dataset for Table-Aware SQL Generation
Jun 10, 2020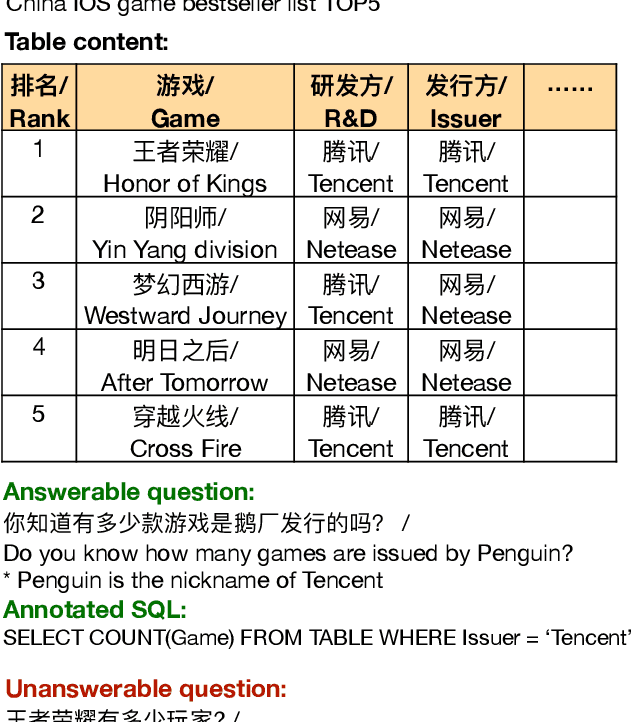
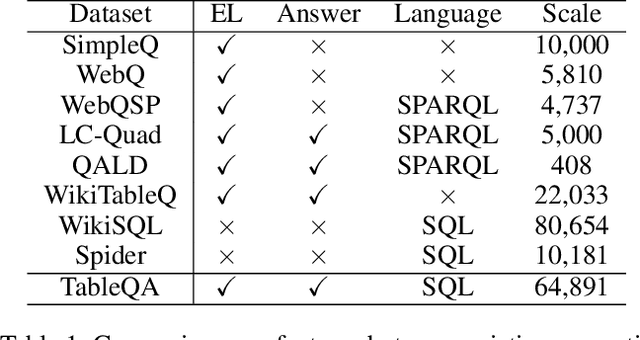

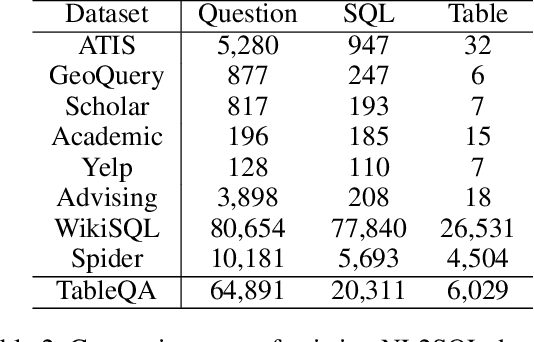
Parsing natural language to corresponding SQL (NL2SQL) with data driven approaches like deep neural networks attracts much attention in recent years. Existing NL2SQL datasets assume that condition values should appear exactly in natural language questions and the queries are answerable given the table. However, these assumptions may fail in practical scenarios, because user may use different expressions for the same content in the table, and query information outside the table without the full picture of contents in table. Therefore we present TableQA, a large-scale cross-domain Natural Language to SQL dataset in Chinese language consisting 64,891 questions and 20,311 unique SQL queries on over 6,000 tables. Different from exisiting NL2SQL datasets, TableQA requires to generalize well not only to SQL skeletons of different questions and table schemas, but also to the various expressions for condition values. Experiment results show that the state-of-the-art model with 95.1% condition value accuracy on WikiSQL only gets 46.8% condition value accuracy and 43.0% logic form accuracy on TableQA, indicating the proposed dataset is challenging and necessary to handle. Two table-aware approaches are proposed to alleviate the problem, the end-to-end approaches obtains 51.3% and 47.4% accuracy on the condition value and logic form tasks, with improvement of 4.7% and 3.4% respectively.
Improving Relation Extraction with Knowledge-attention
Oct 07, 2019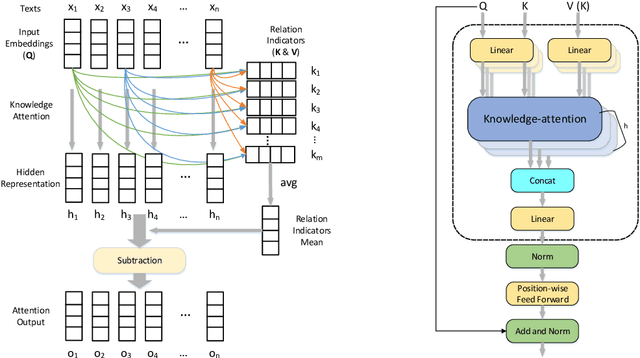
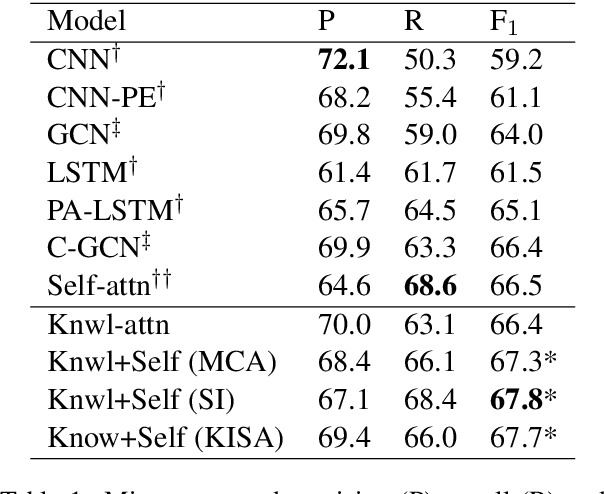
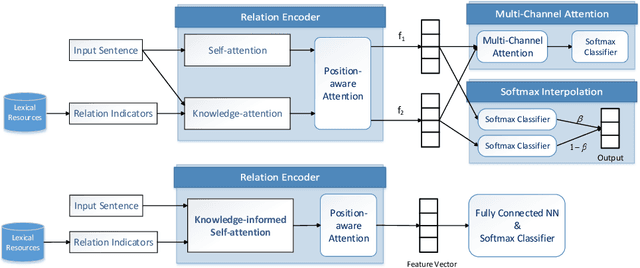
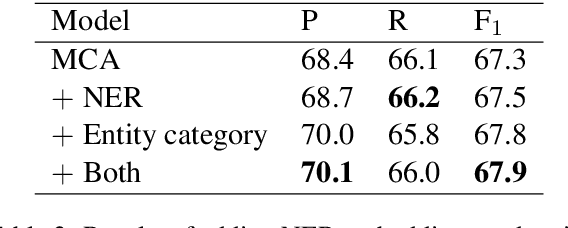
While attention mechanisms have been proven to be effective in many NLP tasks, majority of them are data-driven. We propose a novel knowledge-attention encoder which incorporates prior knowledge from external lexical resources into deep neural networks for relation extraction task. Furthermore, we present three effective ways of integrating knowledge-attention with self-attention to maximize the utilization of both knowledge and data. The proposed relation extraction system is end-to-end and fully attention-based. Experiment results show that the proposed knowledge-attention mechanism has complementary strengths with self-attention, and our integrated models outperform existing CNN, RNN, and self-attention based models. State-of-the-art performance is achieved on TACRED, a complex and large-scale relation extraction dataset.
Technical report on Conversational Question Answering
Sep 24, 2019
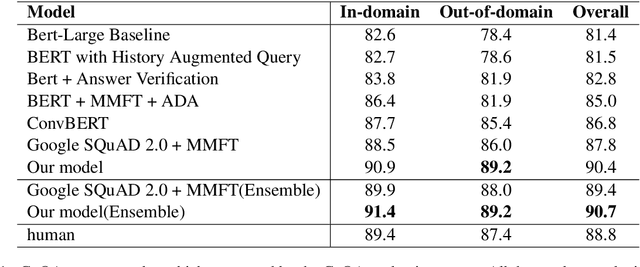
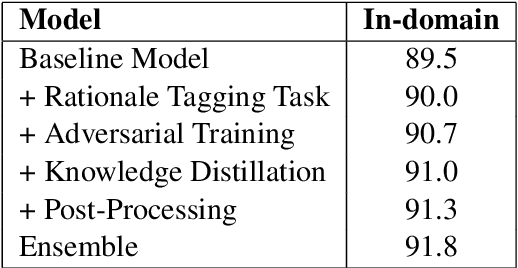
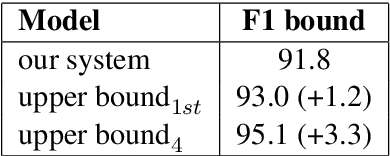
Conversational Question Answering is a challenging task since it requires understanding of conversational history. In this project, we propose a new system RoBERTa + AT +KD, which involves rationale tagging multi-task, adversarial training, knowledge distillation and a linguistic post-process strategy. Our single model achieves 90.4(F1) on the CoQA test set without data augmentation, outperforming the current state-of-the-art single model by 2.6% F1.
Supervised Fine Tuning for Word Embedding with Integrated Knowledge
May 29, 2015
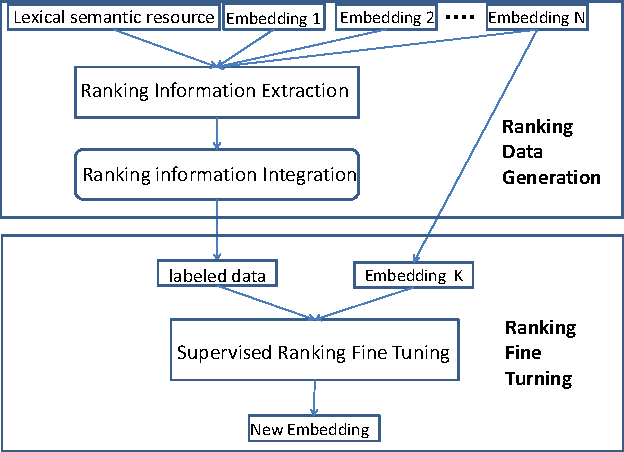

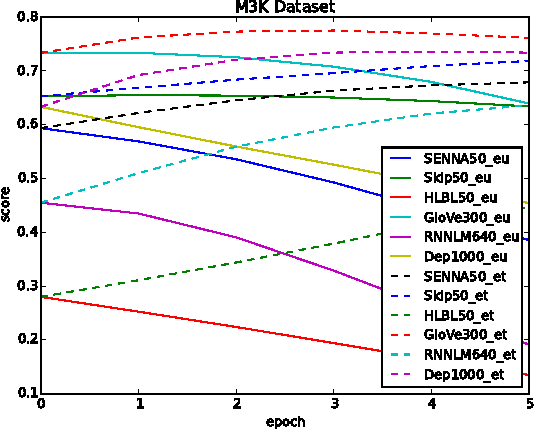
Learning vector representation for words is an important research field which may benefit many natural language processing tasks. Two limitations exist in nearly all available models, which are the bias caused by the context definition and the lack of knowledge utilization. They are difficult to tackle because these algorithms are essentially unsupervised learning approaches. Inspired by deep learning, the authors propose a supervised framework for learning vector representation of words to provide additional supervised fine tuning after unsupervised learning. The framework is knowledge rich approacher and compatible with any numerical vectors word representation. The authors perform both intrinsic evaluation like attributional and relational similarity prediction and extrinsic evaluations like the sentence completion and sentiment analysis. Experiments results on 6 embeddings and 4 tasks with 10 datasets show that the proposed fine tuning framework may significantly improve the quality of the vector representation of words.