 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSMFormer: Empowering Self-supervised Stereo Matching via Foundation Models and Data Augmentation
Apr 11, 2026Recent self-supervised stereo matching methods have made significant progress. They typically rely on the photometric consistency assumption, which presumes corresponding points across views share the same appearance. However, this assumption could be compromised by real-world disturbances, resulting in invalid supervisory signals and a significant accuracy gap compared to supervised methods. To address this issue, we propose SMFormer, a framework integrating more reliable self-supervision guided by the Vision Foundation Model (VFM) and data augmentation. We first incorporate the VFM with the Feature Pyramid Network (FPN), providing a discriminative and robust feature representation against disturbance in various scenarios. We then devise an effective data augmentation mechanism that ensures robustness to various transformations. The data augmentation mechanism explicitly enforces consistency between learned features and those influenced by illumination variations. Additionally, it regularizes the output consistency between disparity predictions of strong augmented samples and those generated from standard samples. Experiments on multiple mainstream benchmarks demonstrate that our SMFormer achieves state-of-the-art (SOTA) performance among self-supervised methods and even competes on par with supervised ones. Remarkably, in the challenging Booster benchmark, SMFormer even outperforms some SOTA supervised methods, such as CFNet.
When Small Variations Become Big Failures: Reliability Challenges in Compute-in-Memory Neural Accelerators
Mar 03, 2026Compute-in-memory (CiM) architectures promise significant improvements in energy efficiency and throughput for deep neural network acceleration by alleviating the von Neumann bottleneck. However, their reliance on emerging non-volatile memory devices introduces device-level non-idealities-such as write variability, conductance drift, and stochastic noise-that fundamentally challenge reliability, predictability, and safety, especially in safety-critical applications. This talk examines the reliability limits of CiM-based neural accelerators and presents a series of techniques that bridge device physics, architecture, and learning algorithms to address these challenges. We first demonstrate that even small device variations can lead to disproportionately large accuracy degradation and catastrophic failures in safety-critical inference workloads, revealing a critical gap between average-case evaluations and worst-case behavior. Building on this insight, we introduce SWIM, a selective write-verify mechanism that strategically applies verification only where it is most impactful, significantly improving reliability while maintaining CiM's efficiency advantages. Finally, we explore a learning-centric solution that improves realistic worst-case performance by training neural networks with right-censored Gaussian noise, aligning training assumptions with hardware-induced variability and enabling robust deployment without excessive hardware overhead. Together, these works highlight the necessity of cross-layer co-design for CiM accelerators and provide a principled path toward dependable, efficient neural inference on emerging memory technologies-paving the way for their adoption in safety- and reliability-critical systems.
ADRD-Bench: A Preliminary LLM Benchmark for Alzheimer's Disease and Related Dementias
Feb 12, 2026Large language models (LLMs) have shown great potential for healthcare applications. However, existing evaluation benchmarks provide minimal coverage of Alzheimer's Disease and Related Dementias (ADRD). To address this gap, we introduce ADRD-Bench, the first ADRD-specific benchmark dataset designed for rigorous evaluation of LLMs. ADRD-Bench has two components: 1) ADRD Unified QA, a synthesis of 1,352 questions consolidated from seven established medical benchmarks, providing a unified assessment of clinical knowledge; and 2) ADRD Caregiving QA, a novel set of 149 questions derived from the Aging Brain Care (ABC) program, a widely used, evidence-based brain health management program. Guided by a program with national expertise in comprehensive ADRD care, this new set was designed to mitigate the lack of practical caregiving context in existing benchmarks. We evaluated 33 state-of-the-art LLMs on the proposed ADRD-Bench. Results showed that the accuracy of open-weight general models ranged from 0.63 to 0.93 (mean: 0.78; std: 0.09). The accuracy of open-weight medical models ranged from 0.48 to 0.93 (mean: 0.82; std: 0.13). The accuracy of closed-source general models ranged from 0.83 to 0.91 (mean: 0.89; std: 0.03). While top-tier models achieved high accuracies (>0.9), case studies revealed that inconsistent reasoning quality and stability limit their reliability, highlighting a critical need for domain-specific improvement to enhance LLMs' knowledge and reasoning grounded in daily caregiving data. The entire dataset is available at https://github.com/IIRL-ND/ADRD-Bench.
QuantBench: Benchmarking AI Methods for Quantitative Investment
Apr 24, 2025



The field of artificial intelligence (AI) in quantitative investment has seen significant advancements, yet it lacks a standardized benchmark aligned with industry practices. This gap hinders research progress and limits the practical application of academic innovations. We present QuantBench, an industrial-grade benchmark platform designed to address this critical need. QuantBench offers three key strengths: (1) standardization that aligns with quantitative investment industry practices, (2) flexibility to integrate various AI algorithms, and (3) full-pipeline coverage of the entire quantitative investment process. Our empirical studies using QuantBench reveal some critical research directions, including the need for continual learning to address distribution shifts, improved methods for modeling relational financial data, and more robust approaches to mitigate overfitting in low signal-to-noise environments. By providing a common ground for evaluation and fostering collaboration between researchers and practitioners, QuantBench aims to accelerate progress in AI for quantitative investment, similar to the impact of benchmark platforms in computer vision and natural language processing.
Generative Semantic Communication for Text-to-Speech Synthesis
Oct 04, 2024Semantic communication is a promising technology to improve communication efficiency by transmitting only the semantic information of the source data. However, traditional semantic communication methods primarily focus on data reconstruction tasks, which may not be efficient for emerging generative tasks such as text-to-speech (TTS) synthesis. To address this limitation, this paper develops a novel generative semantic communication framework for TTS synthesis, leveraging generative artificial intelligence technologies. Firstly, we utilize a pre-trained large speech model called WavLM and the residual vector quantization method to construct two semantic knowledge bases (KBs) at the transmitter and receiver, respectively. The KB at the transmitter enables effective semantic extraction, while the KB at the receiver facilitates lifelike speech synthesis. Then, we employ a transformer encoder and a diffusion model to achieve efficient semantic coding without introducing significant communication overhead. Finally, numerical results demonstrate that our framework achieves much higher fidelity for the generated speech than four baselines, in both cases with additive white Gaussian noise channel and Rayleigh fading channel.
AdvSV: An Over-the-Air Adversarial Attack Dataset for Speaker Verification
Oct 09, 2023



It is known that deep neural networks are vulnerable to adversarial attacks. Although Automatic Speaker Verification (ASV) built on top of deep neural networks exhibits robust performance in controlled scenarios, many studies confirm that ASV is vulnerable to adversarial attacks. The lack of a standard dataset is a bottleneck for further research, especially reproducible research. In this study, we developed an open-source adversarial attack dataset for speaker verification research. As an initial step, we focused on the over-the-air attack. An over-the-air adversarial attack involves a perturbation generation algorithm, a loudspeaker, a microphone, and an acoustic environment. The variations in the recording configurations make it very challenging to reproduce previous research. The AdvSV dataset is constructed using the Voxceleb1 Verification test set as its foundation. This dataset employs representative ASV models subjected to adversarial attacks and records adversarial samples to simulate over-the-air attack settings. The scope of the dataset can be easily extended to include more types of adversarial attacks. The dataset will be released to the public under the CC-BY license. In addition, we also provide a detection baseline for reproducible research.
IMM: An Imitative Reinforcement Learning Approach with Predictive Representation Learning for Automatic Market Making
Aug 17, 2023



Market making (MM) has attracted significant attention in financial trading owing to its essential function in ensuring market liquidity. With strong capabilities in sequential decision-making, Reinforcement Learning (RL) technology has achieved remarkable success in quantitative trading. Nonetheless, most existing RL-based MM methods focus on optimizing single-price level strategies which fail at frequent order cancellations and loss of queue priority. Strategies involving multiple price levels align better with actual trading scenarios. However, given the complexity that multi-price level strategies involves a comprehensive trading action space, the challenge of effectively training profitable RL agents for MM persists. Inspired by the efficient workflow of professional human market makers, we propose Imitative Market Maker (IMM), a novel RL framework leveraging both knowledge from suboptimal signal-based experts and direct policy interactions to develop multi-price level MM strategies efficiently. The framework start with introducing effective state and action representations adept at encoding information about multi-price level orders. Furthermore, IMM integrates a representation learning unit capable of capturing both short- and long-term market trends to mitigate adverse selection risk. Subsequently, IMM formulates an expert strategy based on signals and trains the agent through the integration of RL and imitation learning techniques, leading to efficient learning. Extensive experimental results on four real-world market datasets demonstrate that IMM outperforms current RL-based market making strategies in terms of several financial criteria. The findings of the ablation study substantiate the effectiveness of the model components.
Multimodal Representations Learning Based on Mutual Information Maximization and Minimization and Identity Embedding for Multimodal Sentiment Analysis
Jan 10, 2022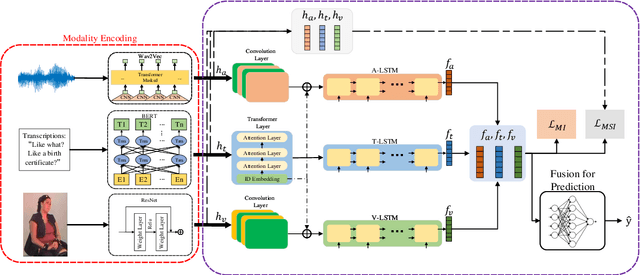
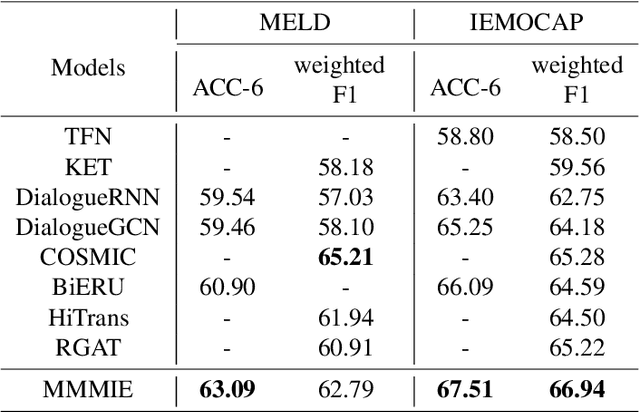
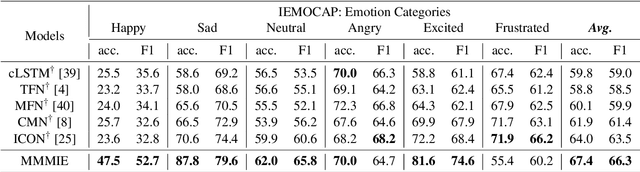
Multimodal sentiment analysis (MSA) is a fundamental complex research problem due to the heterogeneity gap between different modalities and the ambiguity of human emotional expression. Although there have been many successful attempts to construct multimodal representations for MSA, there are still two challenges to be addressed: 1) A more robust multimodal representation needs to be constructed to bridge the heterogeneity gap and cope with the complex multimodal interactions, and 2) the contextual dynamics must be modeled effectively throughout the information flow. In this work, we propose a multimodal representation model based on Mutual information Maximization and Minimization and Identity Embedding (MMMIE). We combine mutual information maximization between modal pairs, and mutual information minimization between input data and corresponding features to mine the modal-invariant and task-related information. Furthermore, Identity Embedding is proposed to prompt the downstream network to perceive the contextual information. Experimental results on two public datasets demonstrate the effectiveness of the proposed model.
ElegantRL-Podracer: Scalable and Elastic Library for Cloud-Native Deep Reinforcement Learning
Dec 11, 2021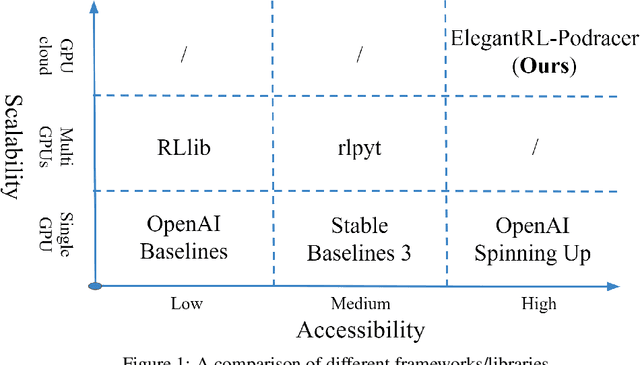
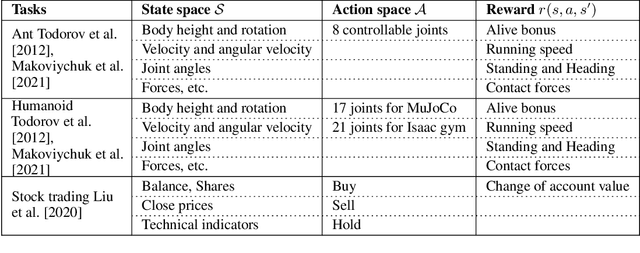
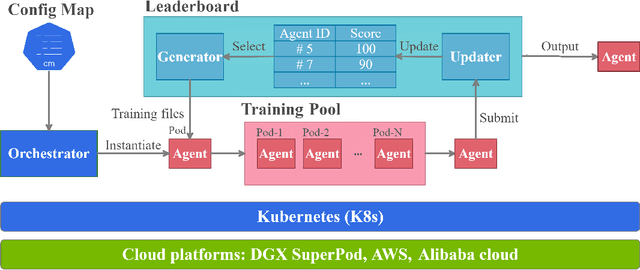

Deep reinforcement learning (DRL) has revolutionized learning and actuation in applications such as game playing and robotic control. The cost of data collection, i.e., generating transitions from agent-environment interactions, remains a major challenge for wider DRL adoption in complex real-world problems. Following a cloud-native paradigm to train DRL agents on a GPU cloud platform is a promising solution. In this paper, we present a scalable and elastic library ElegantRL-podracer for cloud-native deep reinforcement learning, which efficiently supports millions of GPU cores to carry out massively parallel training at multiple levels. At a high-level, ElegantRL-podracer employs a tournament-based ensemble scheme to orchestrate the training process on hundreds or even thousands of GPUs, scheduling the interactions between a leaderboard and a training pool with hundreds of pods. At a low-level, each pod simulates agent-environment interactions in parallel by fully utilizing nearly 7,000 GPU CUDA cores in a single GPU. Our ElegantRL-podracer library features high scalability, elasticity and accessibility by following the development principles of containerization, microservices and MLOps. Using an NVIDIA DGX SuperPOD cloud, we conduct extensive experiments on various tasks in locomotion and stock trading and show that ElegantRL-podracer substantially outperforms RLlib. Our codes are available on GitHub.
* 9 pages, 7 figures