 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCorrelational Image Modeling for Self-Supervised Visual Pre-Training
Mar 30, 2023We introduce Correlational Image Modeling (CIM), a novel and surprisingly effective approach to self-supervised visual pre-training. Our CIM performs a simple pretext task: we randomly crop image regions (exemplars) from an input image (context) and predict correlation maps between the exemplars and the context. Three key designs enable correlational image modeling as a nontrivial and meaningful self-supervisory task. First, to generate useful exemplar-context pairs, we consider cropping image regions with various scales, shapes, rotations, and transformations. Second, we employ a bootstrap learning framework that involves online and target encoders. During pre-training, the former takes exemplars as inputs while the latter converts the context. Third, we model the output correlation maps via a simple cross-attention block, within which the context serves as queries and the exemplars offer values and keys. We show that CIM performs on par or better than the current state of the art on self-supervised and transfer benchmarks.
Super-Resolution Information Enhancement For Crowd Counting
Mar 13, 2023



Crowd counting is a challenging task due to the heavy occlusions, scales, and density variations. Existing methods handle these challenges effectively while ignoring low-resolution (LR) circumstances. The LR circumstances weaken the counting performance deeply for two crucial reasons: 1) limited detail information; 2) overlapping head regions accumulate in density maps and result in extreme ground-truth values. An intuitive solution is to employ super-resolution (SR) pre-processes for the input LR images. However, it complicates the inference steps and thus limits application potentials when requiring real-time. We propose a more elegant method termed Multi-Scale Super-Resolution Module (MSSRM). It guides the network to estimate the lost de tails and enhances the detailed information in the feature space. Noteworthy that the MSSRM is plug-in plug-out and deals with the LR problems with no inference cost. As the proposed method requires SR labels, we further propose a Super-Resolution Crowd Counting dataset (SR-Crowd). Extensive experiments on three datasets demonstrate the superiority of our method. The code will be available at https://github.com/PRIS-CV/MSSRM.git.
Controllable Image Captioning via Prompting
Dec 04, 2022



Despite the remarkable progress of image captioning, existing captioners typically lack the controllable capability to generate desired image captions, e.g., describing the image in a rough or detailed manner, in a factual or emotional view, etc. In this paper, we show that a unified model is qualified to perform well in diverse domains and freely switch among multiple styles. Such a controllable capability is achieved by embedding the prompt learning into the image captioning framework. To be specific, we design a set of prompts to fine-tune the pre-trained image captioner. These prompts allow the model to absorb stylized data from different domains for joint training, without performance degradation in each domain. Furthermore, we optimize the prompts with learnable vectors in the continuous word embedding space, avoiding the heuristic prompt engineering and meanwhile exhibiting superior performance. In the inference stage, our model is able to generate desired stylized captions by choosing the corresponding prompts. Extensive experiments verify the controllable capability of the proposed method. Notably, we achieve outstanding performance on two diverse image captioning benchmarks including COCO Karpathy split and TextCaps using a unified model.
Masked Frequency Modeling for Self-Supervised Visual Pre-Training
Jun 15, 2022



We present Masked Frequency Modeling (MFM), a unified frequency-domain-based approach for self-supervised pre-training of visual models. Instead of randomly inserting mask tokens to the input embeddings in the spatial domain, in this paper, we shift the perspective to the frequency domain. Specifically, MFM first masks out a portion of frequency components of the input image and then predicts the missing frequencies on the frequency spectrum. Our key insight is that predicting masked components in the frequency domain is more ideal to reveal underlying image patterns rather than predicting masked patches in the spatial domain, due to the heavy spatial redundancy. Our findings suggest that with the right configuration of mask-and-predict strategy, both the structural information within high-frequency components and the low-level statistics among low-frequency counterparts are useful in learning good representations. For the first time, MFM demonstrates that, for both ViT and CNN, a simple non-Siamese framework can learn meaningful representations even using none of the following: (i) extra data, (ii) extra model, (iii) mask token. Experimental results on ImageNet and several robustness benchmarks show the competitive performance and advanced robustness of MFM compared with recent masked image modeling approaches. Furthermore, we also comprehensively investigate the effectiveness of classical image restoration tasks for representation learning from a unified frequency perspective and reveal their intriguing relations with our MFM approach. Project page: https://www.mmlab-ntu.com/project/mfm/index.html.
UniVIP: A Unified Framework for Self-Supervised Visual Pre-training
Mar 14, 2022Self-supervised learning (SSL) holds promise in leveraging large amounts of unlabeled data. However, the success of popular SSL methods has limited on single-centric-object images like those in ImageNet and ignores the correlation among the scene and instances, as well as the semantic difference of instances in the scene. To address the above problems, we propose a Unified Self-supervised Visual Pre-training (UniVIP), a novel self-supervised framework to learn versatile visual representations on either single-centric-object or non-iconic dataset. The framework takes into account the representation learning at three levels: 1) the similarity of scene-scene, 2) the correlation of scene-instance, 3) the discrimination of instance-instance. During the learning, we adopt the optimal transport algorithm to automatically measure the discrimination of instances. Massive experiments show that UniVIP pre-trained on non-iconic COCO achieves state-of-the-art transfer performance on a variety of downstream tasks, such as image classification, semi-supervised learning, object detection and segmentation. Furthermore, our method can also exploit single-centric-object dataset such as ImageNet and outperforms BYOL by 2.5% with the same pre-training epochs in linear probing, and surpass current self-supervised object detection methods on COCO dataset, demonstrating its universality and potential.
Unsupervised Object-Level Representation Learning from Scene Images
Jun 22, 2021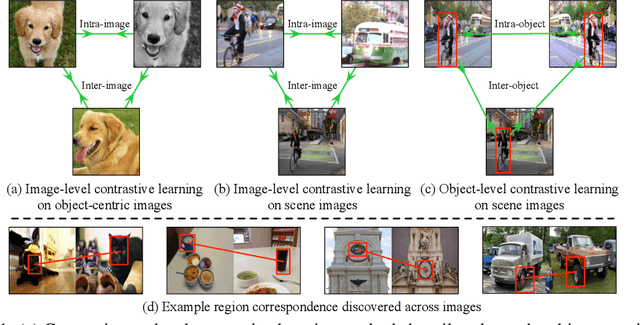
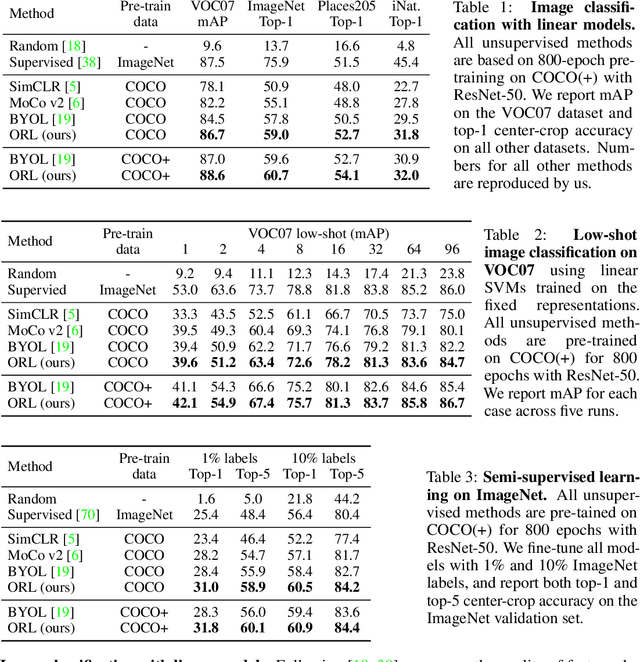


Contrastive self-supervised learning has largely narrowed the gap to supervised pre-training on ImageNet. However, its success highly relies on the object-centric priors of ImageNet, i.e., different augmented views of the same image correspond to the same object. Such a heavily curated constraint becomes immediately infeasible when pre-trained on more complex scene images with many objects. To overcome this limitation, we introduce Object-level Representation Learning (ORL), a new self-supervised learning framework towards scene images. Our key insight is to leverage image-level self-supervised pre-training as the prior to discover object-level semantic correspondence, thus realizing object-level representation learning from scene images. Extensive experiments on COCO show that ORL significantly improves the performance of self-supervised learning on scene images, even surpassing supervised ImageNet pre-training on several downstream tasks. Furthermore, ORL improves the downstream performance when more unlabeled scene images are available, demonstrating its great potential of harnessing unlabeled data in the wild. We hope our approach can motivate future research on more general-purpose unsupervised representation learning from scene data. Project page: https://www.mmlab-ntu.com/project/orl/.
A Federated Learning Framework for Nonconvex-PL Minimax Problems
May 29, 2021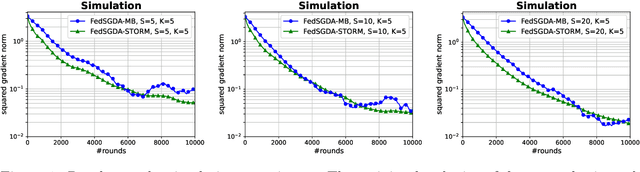
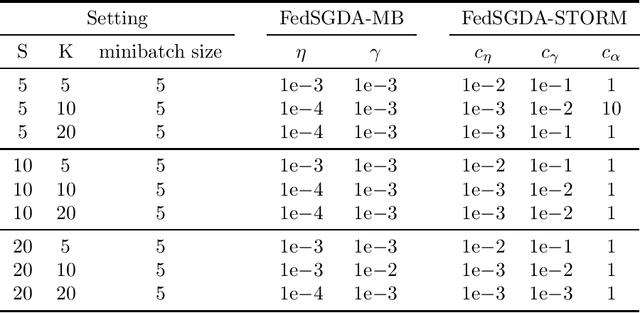
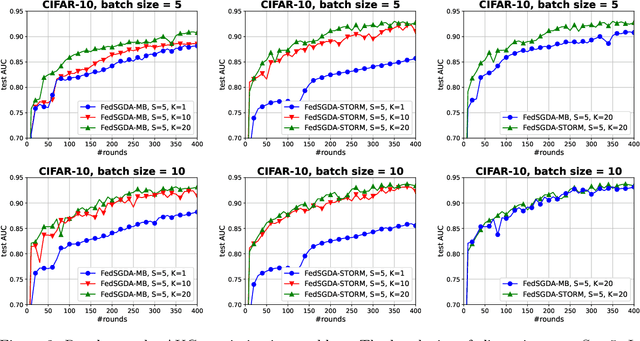
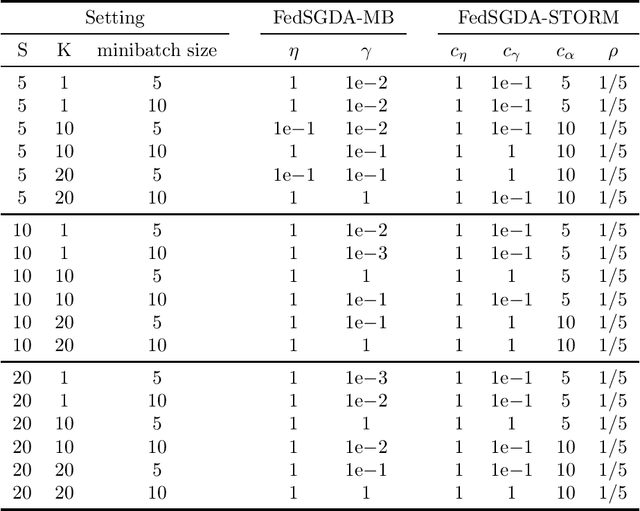
We consider a general class of nonconvex-PL minimax problems in the cross-device federated learning setting. Although nonconvex-PL minimax problems have received a lot of interest in recent years, existing algorithms do not apply to the cross-device federated learning setting which is substantially different from conventional distributed settings and poses new challenges. To bridge this gap, we propose an algorithmic framework named FedSGDA. FedSGDA performs multiple local update steps on a subset of active clients in each round and leverages global gradient estimates to correct the bias in local update directions. By incorporating FedSGDA with two representative global gradient estimators, we obtain two specific algorithms. We establish convergence rates of the proposed algorithms by using novel potential functions. Experimental results on synthetic and real data corroborate our theory and demonstrate the effectiveness of our algorithms.
L-SNet: from Region Localization to Scale Invariant Medical Image Segmentation
Feb 11, 2021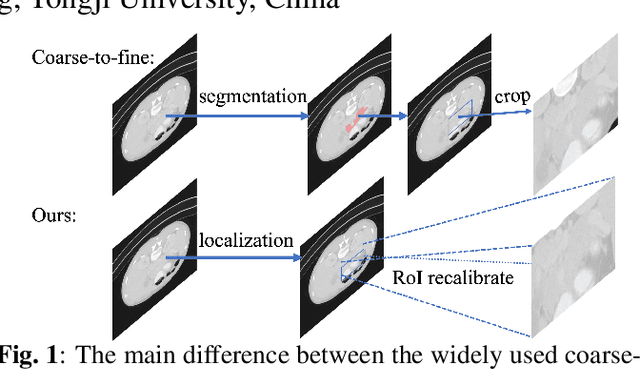
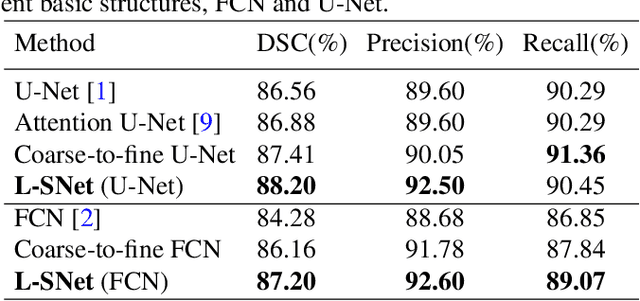
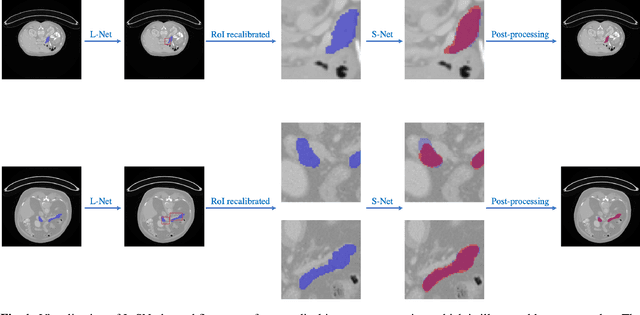
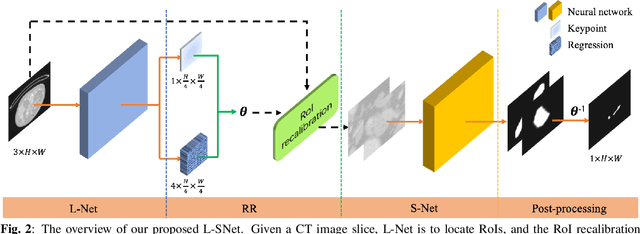
Coarse-to-fine models and cascade segmentation architectures are widely adopted to solve the problem of large scale variations in medical image segmentation. However, those methods have two primary limitations: the first-stage segmentation becomes a performance bottleneck; the lack of overall differentiability makes the training process of two stages asynchronous and inconsistent. In this paper, we propose a differentiable two-stage network architecture to tackle these problems. In the first stage, a localization network (L-Net) locates Regions of Interest (RoIs) in a detection fashion; in the second stage, a segmentation network (S-Net) performs fine segmentation on the recalibrated RoIs; a RoI recalibration module between L-Net and S-Net eliminating the inconsistencies. Experimental results on the public dataset show that our method outperforms state-of-the-art coarse-to-fine models with negligible computation overheads.
Partial Gromov-Wasserstein Learning for Partial Graph Matching
Dec 09, 2020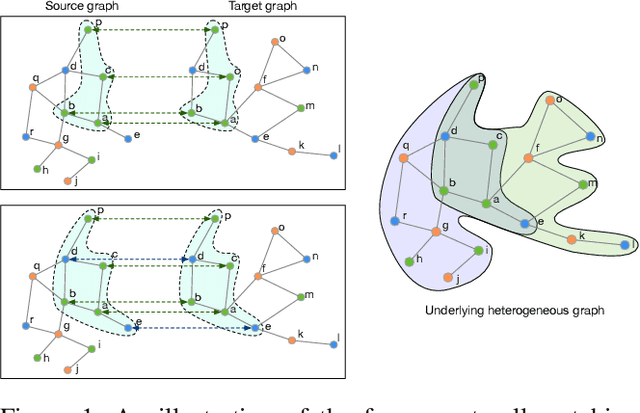
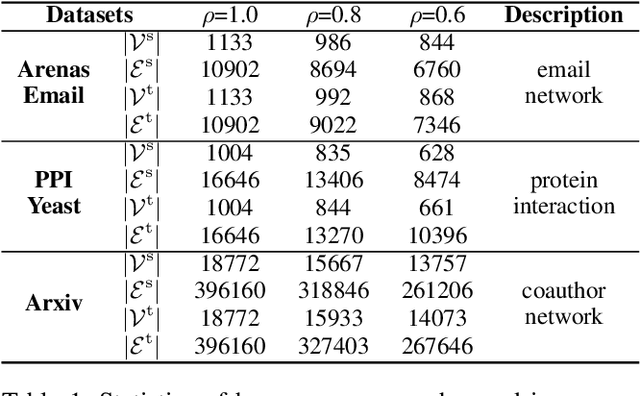
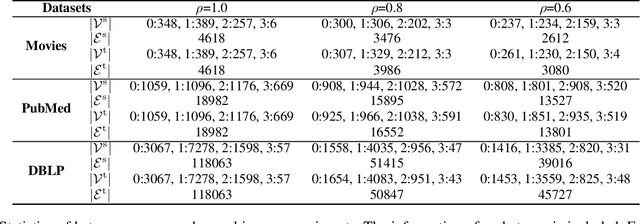
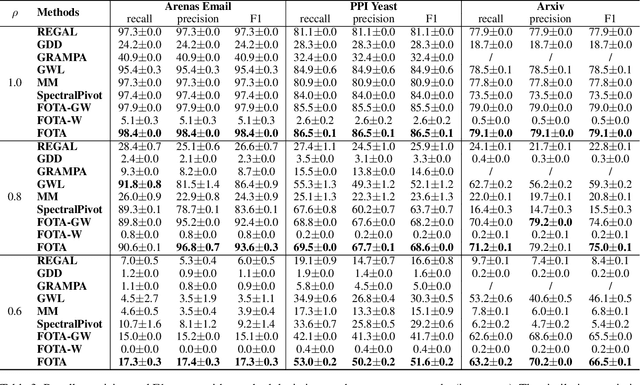
Graph matching finds the correspondence of nodes across two graphs and is a basic task in graph-based machine learning. Numerous existing methods match every node in one graph to one node in the other graph whereas two graphs usually overlap partially in many \realworld{} applications. In this paper, a partial Gromov-Wasserstein learning framework is proposed for partially matching two graphs, which fuses the partial Gromov-Wasserstein distance and the partial Wasserstein distance as the objective and updates the partial transport map and the node embedding in an alternating fashion. The proposed framework transports a fraction of the probability mass and matches node pairs with high relative similarities across the two graphs. Incorporating an embedding learning method, heterogeneous graphs can also be matched. Numerical experiments on both synthetic and \realworld{} graphs demonstrate that our framework can improve the F1 score by at least $20\%$ and often much more.
Delving into Inter-Image Invariance for Unsupervised Visual Representations
Aug 26, 2020
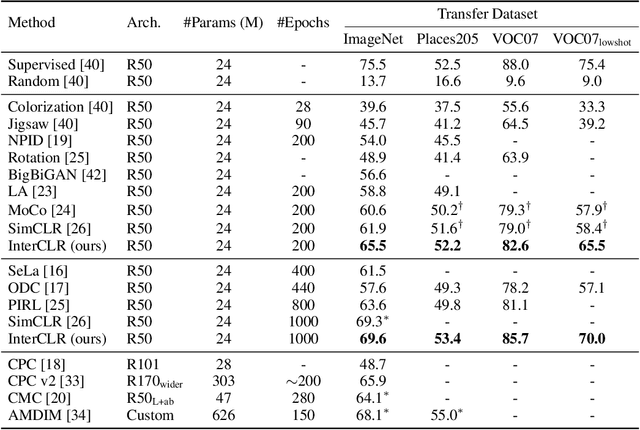
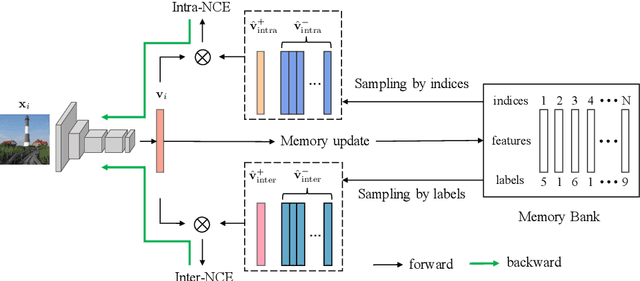
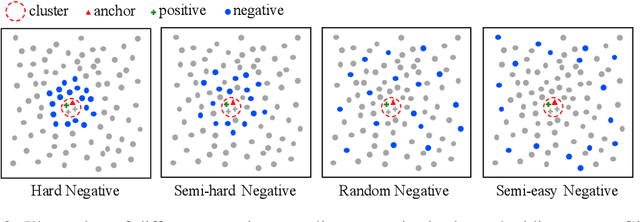
Contrastive learning has recently shown immense potential in unsupervised visual representation learning. Existing studies in this track mainly focus on intra-image invariance learning. The learning typically uses rich intra-image transformations to construct positive pairs and then maximizes agreement using a contrastive loss. The merits of inter-image invariance, conversely, remain much less explored. One major obstacle to exploit inter-image invariance is that it is unclear how to reliably construct inter-image positive pairs, and further derive effective supervision from them since there are no pair annotations available. In this work, we present a rigorous and comprehensive study on inter-image invariance learning from three main constituting components: pseudo-label maintenance, sampling strategy, and decision boundary design. Through carefully-designed comparisons and analysis, we propose a unified framework that supports the integration of unsupervised intra- and inter-image invariance learning. With all the obtained recipes, our final model, namely InterCLR, achieves state-of-the-art performance on standard benchmarks. Code and models will be available at https://github.com/open-mmlab/OpenSelfSup.