 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSCEF: A Support-Confidence-aware Embedding Framework for Knowledge Graph Refinement
Feb 18, 2019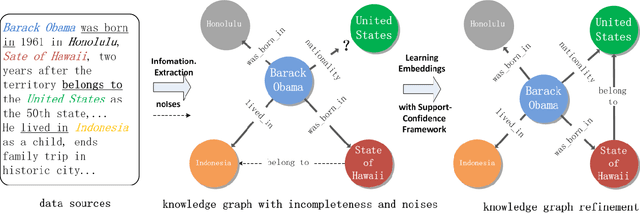
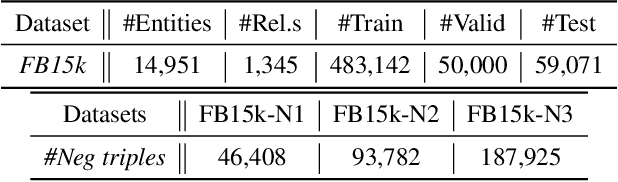
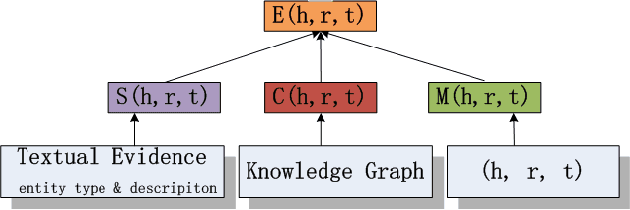
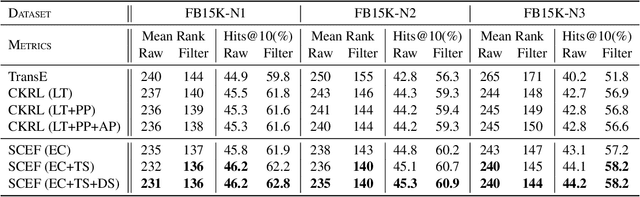
Knowledge graph (KG) refinement mainly aims at KG completion and correction (i.e., error detection). However, most conventional KG embedding models only focus on KG completion with an unreasonable assumption that all facts in KG hold without noises, ignoring error detection which also should be significant and essential for KG refinement.In this paper, we propose a novel support-confidence-aware KG embedding framework (SCEF), which implements KG completion and correction simultaneously by learning knowledge representations with both triple support and triple confidence. Specifically, we build model energy function by incorporating conventional translation-based model with support and confidence. To make our triple support-confidence more sufficient and robust, we not only consider the internal structural information in KG, studying the approximate relation entailment as triple confidence constraints, but also the external textual evidence, proposing two kinds of triple supports with entity types and descriptions respectively.Through extensive experiments on real-world datasets, we demonstrate SCEF's effectiveness.
Adversarially Trained Model Compression: When Robustness Meets Efficiency
Feb 10, 2019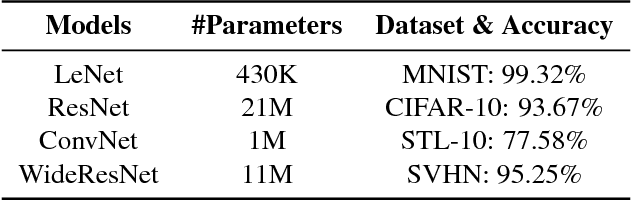
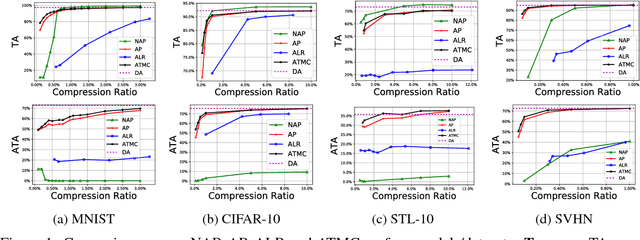
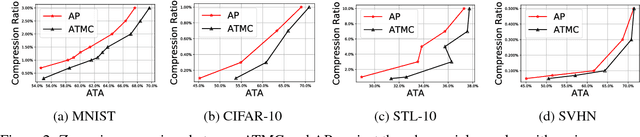
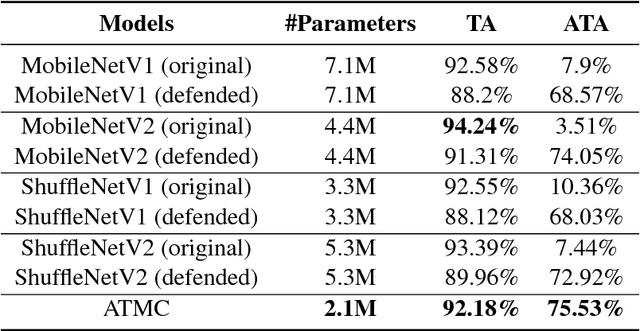
The robustness of deep models to adversarial attacks has gained significant attention in recent years, so has the model compactness and efficiency: yet the two have been mostly studied separately, with few relationships drawn between each other. This paper is concerned with: how can we combine the best of both worlds, obtaining a robust and compact network? The answer is not as straightforward as it may seem, since the two goals of model robustness and compactness may contradict from time to time. We formally study this new question, by proposing a novel Adversarially Trained Model Compression (ATMC) framework. A unified constrained optimization formulation is designed, with an efficient algorithm developed. An extensive group of experiments are then carefully designed and presented, demonstrating that ATMC obtains remarkably more favorable trade-off among model size, accuracy and robustness, over currently available alternatives in various settings.
Monocular 3D Pose Recovery via Nonconvex Sparsity with Theoretical Analysis
Dec 29, 2018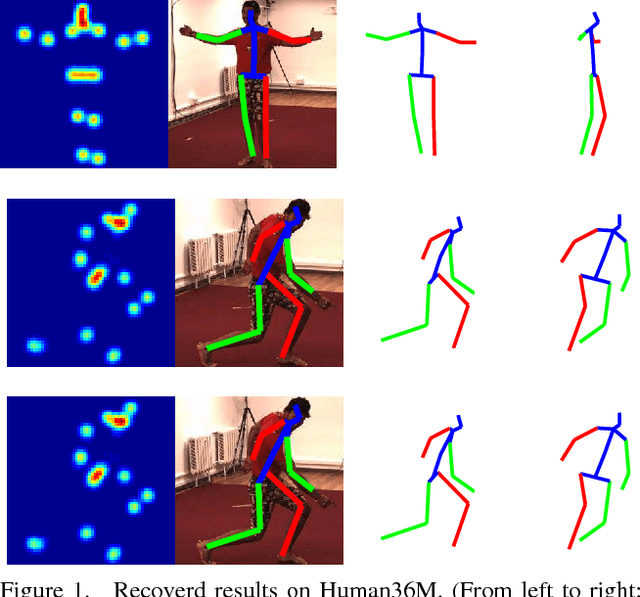

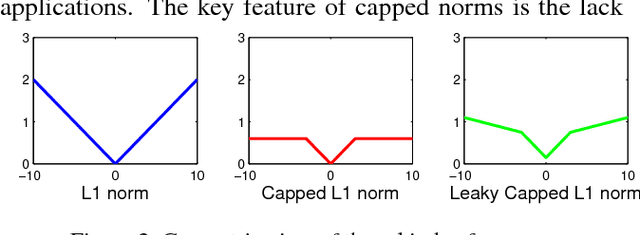

For recovering 3D object poses from 2D images, a prevalent method is to pre-train an over-complete dictionary $\mathcal D=\{B_i\}_i^D$ of 3D basis poses. During testing, the detected 2D pose $Y$ is matched to dictionary by $Y \approx \sum_i M_i B_i$ where $\{M_i\}_i^D=\{c_i \Pi R_i\}$, by estimating the rotation $R_i$, projection $\Pi$ and sparse combination coefficients $c \in \mathbb R_{+}^D$. In this paper, we propose non-convex regularization $H(c)$ to learn coefficients $c$, including novel leaky capped $\ell_1$-norm regularization (LCNR), \begin{align*} H(c)=\alpha \sum_{i } \min(|c_i|,\tau)+ \beta \sum_{i } \max(| c_i|,\tau), \end{align*} where $0\leq \beta \leq \alpha$ and $0<\tau$ is a certain threshold, so the invalid components smaller than $\tau$ are composed with larger regularization and other valid components with smaller regularization. We propose a multi-stage optimizer with convex relaxation and ADMM. We prove that the estimation error $\mathcal L(l)$ decays w.r.t. the stages $l$, \begin{align*} Pr\left(\mathcal L(l) < \rho^{l-1} \mathcal L(0) + \delta \right) \geq 1- \epsilon, \end{align*} where $0< \rho <1, 0<\delta, 0<\epsilon \ll 1$. Experiments on large 3D human datasets like H36M are conducted to support our improvement upon previous approaches. To the best of our knowledge, this is the first theoretical analysis in this line of research, to understand how the recovery error is affected by fundamental factors, e.g. dictionary size, observation noises, optimization times. We characterize the trade-off between speed and accuracy towards real-time inference in applications.
ECC: Energy-Constrained Deep Neural Network Compression via a Bilinear Regression Model
Dec 17, 2018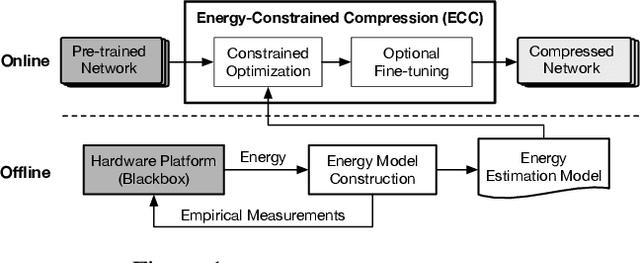
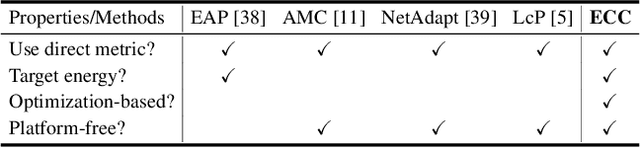
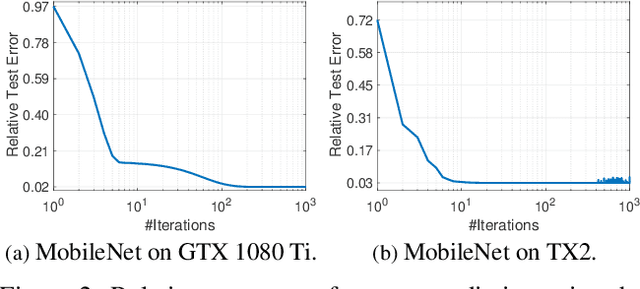

Many DNN-enabled vision applications constantly operate under severe energy constraints such as unmanned aerial vehicles, Augmented Reality headsets, and smartphones. Designing DNNs that can meet a stringent energy budget is becoming increasingly important. This paper proposes ECC, a framework that compresses DNNs to meet a given energy constraint while minimizing accuracy loss. The key idea of ECC is to model the DNN energy consumption via a novel bilinear regression function. The energy estimate model allows us to formulate DNN compression as a constrained optimization that minimizes the DNN loss function over the energy constraint. The optimization problem, however, has nontrivial constraints. Therefore, existing deep learning solvers do not apply directly. We propose an optimization algorithm that combines the essence of the Alternating Direction Method of Multipliers (ADMM) framework with gradient-based learning algorithms. The algorithm decomposes the original constrained optimization into several subproblems that are solved iteratively and efficiently. ECC is also portable across different hardware platforms without requiring hardware knowledge. Experiments show that ECC achieves higher accuracy under the same or lower energy budget compared to state-of-the-art resource-constrained DNN compression techniques.
Distributed Learning of Average Belief Over Networks Using Sequential Observations
Nov 19, 2018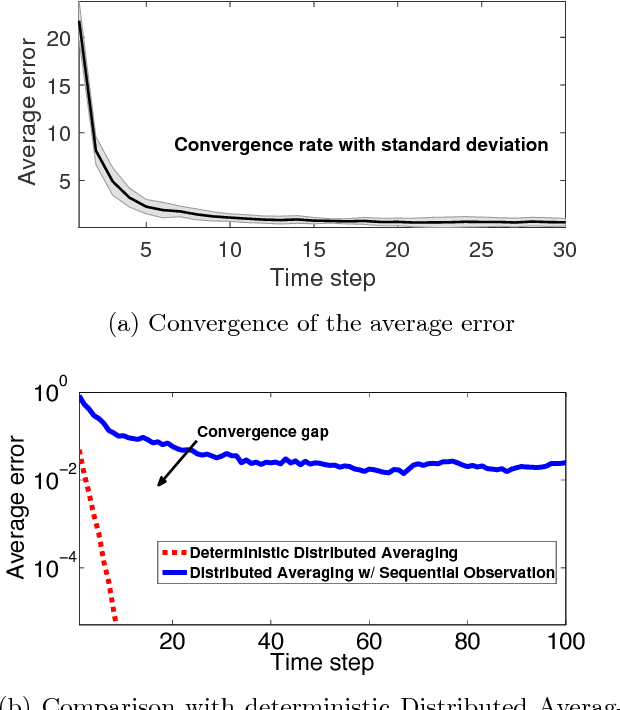
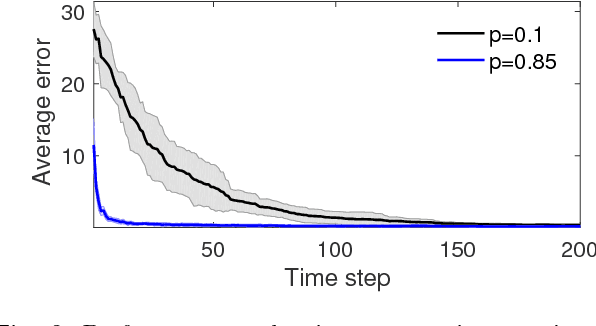
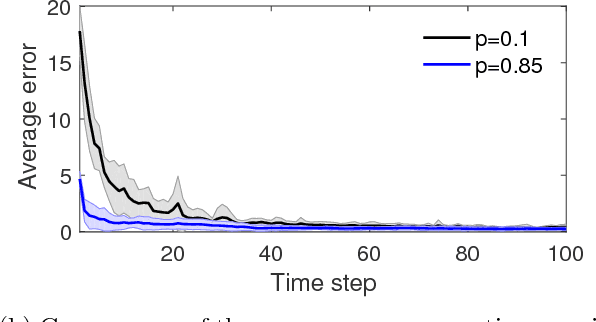
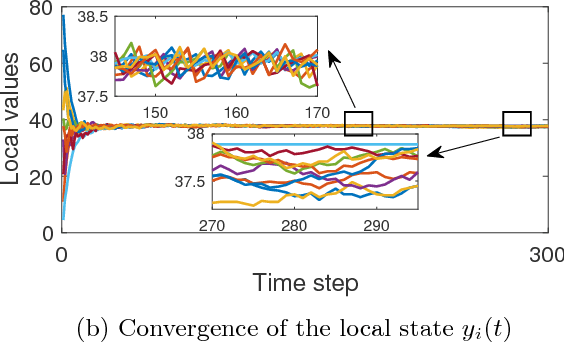
This paper addresses the problem of distributed learning of average belief with sequential observations, in which a network of $n>1$ agents aim to reach a consensus on the average value of their beliefs, by exchanging information only with their neighbors. Each agent has sequentially arriving samples of its belief in an online manner. The neighbor relationships among the $n$ agents are described by a graph which is possibly time-varying, whose vertices correspond to agents and whose edges depict neighbor relationships. Two distributed online algorithms are introduced for undirected and directed graphs, which are both shown to converge to the average belief almost surely. Moreover, the sequences generated by both algorithms are shown to reach consensus with an $O(1/t)$ rate with high probability, where $t$ is the number of iterations. For undirected graphs, the corresponding algorithm is modified for the case with quantized communication and limited precision of the division operation. It is shown that the modified algorithm causes all $n$ agents to either reach a quantized consensus or enter a small neighborhood around the average of their beliefs. Numerical simulations are then provided to corroborate the theoretical results.
Stochastic Primal-Dual Method for Empirical Risk Minimization with $\mathcal{O}(1)$ Per-Iteration Complexity
Nov 03, 2018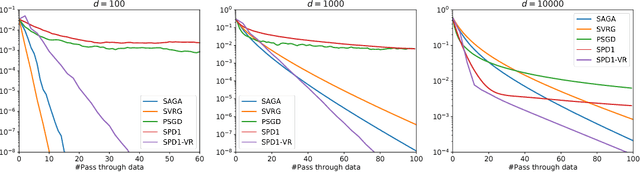
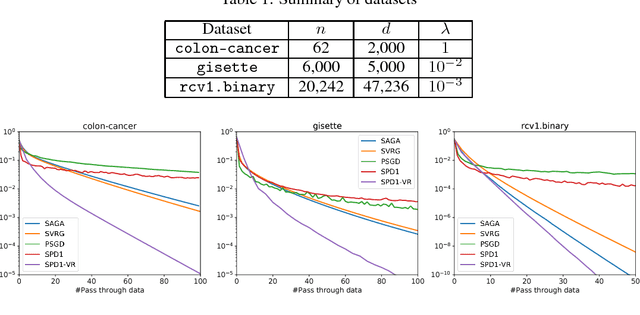
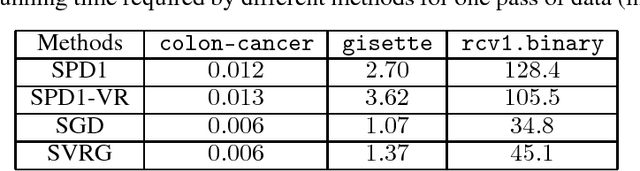
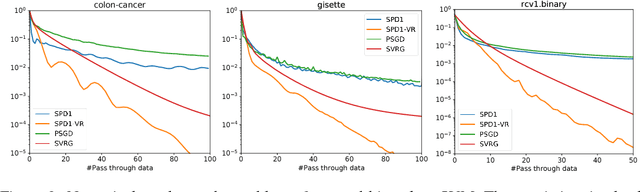
Regularized empirical risk minimization problem with linear predictor appears frequently in machine learning. In this paper, we propose a new stochastic primal-dual method to solve this class of problems. Different from existing methods, our proposed methods only require O(1) operations in each iteration. We also develop a variance-reduction variant of the algorithm that converges linearly. Numerical experiments suggest that our methods are faster than existing ones such as proximal SGD, SVRG and SAGA on high-dimensional problems.
Dantzig Selector with an Approximately Optimal Denoising Matrix and its Application to Reinforcement Learning
Nov 02, 2018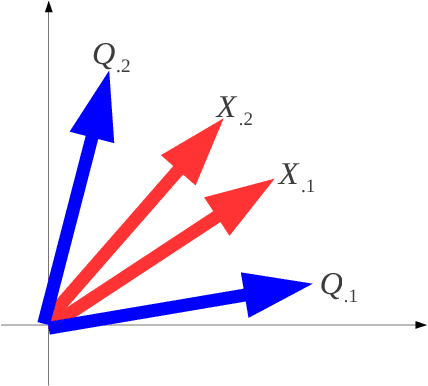
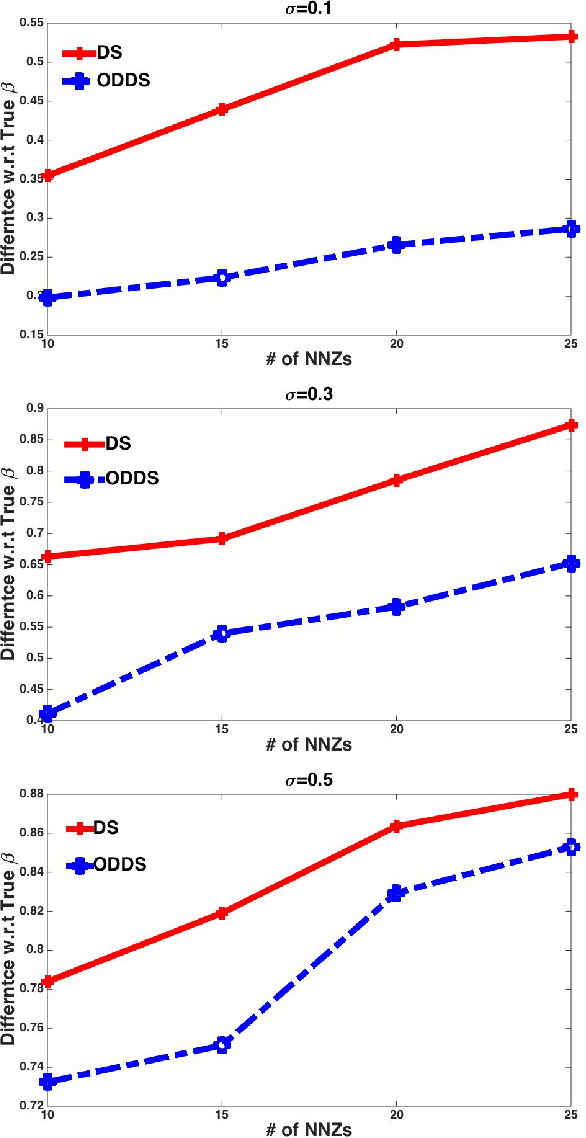
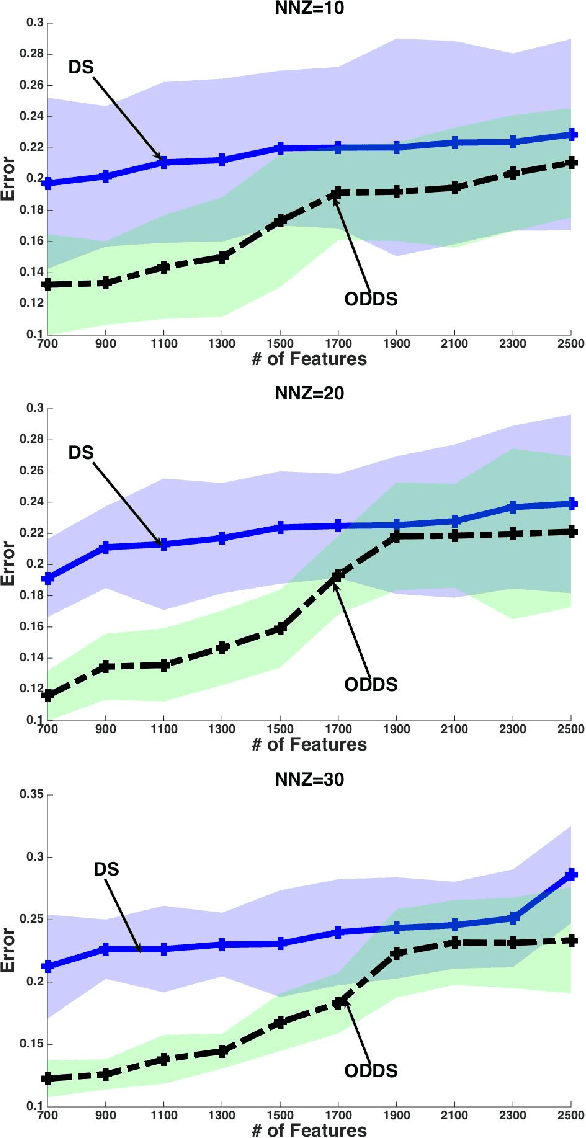
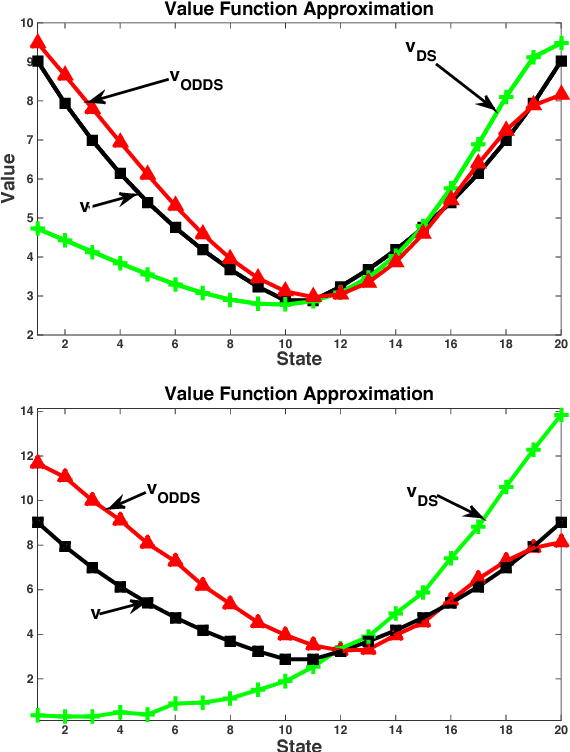
Dantzig Selector (DS) is widely used in compressed sensing and sparse learning for feature selection and sparse signal recovery. Since the DS formulation is essentially a linear programming optimization, many existing linear programming solvers can be simply applied for scaling up. The DS formulation can be explained as a basis pursuit denoising problem, wherein the data matrix (or measurement matrix) is employed as the denoising matrix to eliminate the observation noise. However, we notice that the data matrix may not be the optimal denoising matrix, as shown by a simple counter-example. This motivates us to pursue a better denoising matrix for defining a general DS formulation. We first define the optimal denoising matrix through a minimax optimization, which turns out to be an NPhard problem. To make the problem computationally tractable, we propose a novel algorithm, termed as Optimal Denoising Dantzig Selector (ODDS), to approximately estimate the optimal denoising matrix. Empirical experiments validate the proposed method. Finally, a novel sparse reinforcement learning algorithm is formulated by extending the proposed ODDS algorithm to temporal difference learning, and empirical experimental results demonstrate to outperform the conventional vanilla DS-TD algorithm.
TStarBots: Defeating the Cheating Level Builtin AI in StarCraft II in the Full Game
Nov 02, 2018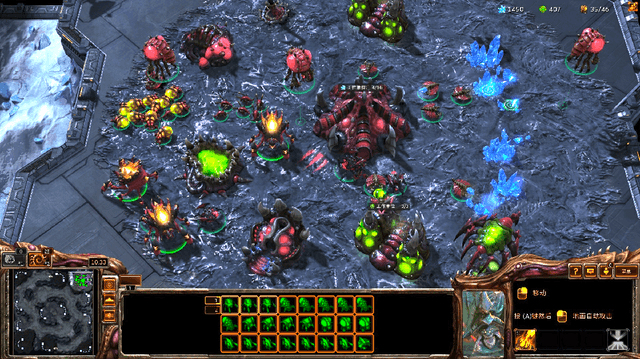


Starcraft II (SC2) is widely considered as the most challenging Real Time Strategy (RTS) game. The underlying challenges include a large observation space, a huge (continuous and infinite) action space, partial observations, simultaneous move for all players, and long horizon delayed rewards for local decisions. To push the frontier of AI research, Deepmind and Blizzard jointly developed the StarCraft II Learning Environment (SC2LE) as a testbench of complex decision making systems. SC2LE provides a few mini games such as MoveToBeacon, CollectMineralShards, and DefeatRoaches, where some AI agents have achieved the performance level of human professional players. However, for full games, the current AI agents are still far from achieving human professional level performance. To bridge this gap, we present two full game AI agents in this paper - the AI agent TStarBot1 is based on deep reinforcement learning over a flat action structure, and the AI agent TStarBot2 is based on hard-coded rules over a hierarchical action structure. Both TStarBot1 and TStarBot2 are able to defeat the built-in AI agents from level 1 to level 10 in a full game (1v1 Zerg-vs-Zerg game on the AbyssalReef map), noting that level 8, level 9, and level 10 are cheating agents with unfair advantages such as full vision on the whole map and resource harvest boosting. To the best of our knowledge, this is the first public work to investigate AI agents that can defeat the built-in AI in the StarCraft II full game.
P-MCGS: Parallel Monte Carlo Acyclic Graph Search
Oct 28, 2018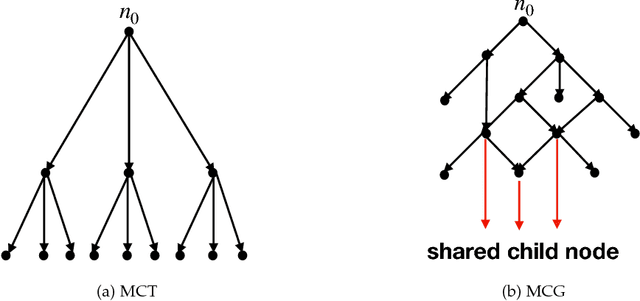
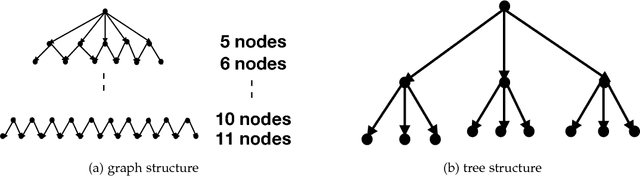
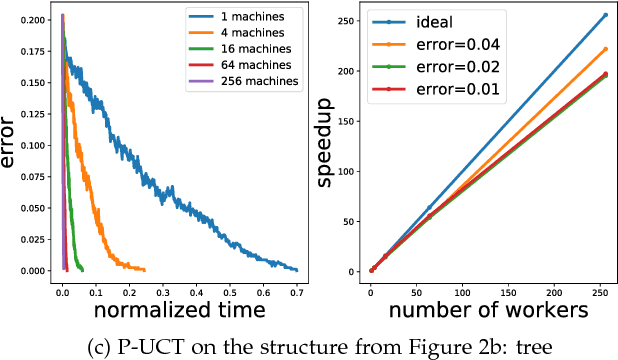
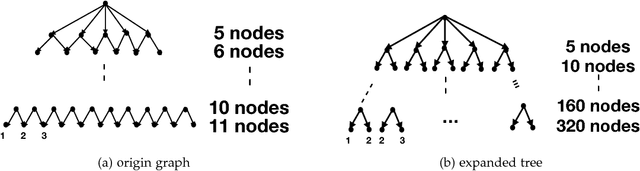
Recently, there have been great interests in Monte Carlo Tree Search (MCTS) in AI research. Although the sequential version of MCTS has been studied widely, its parallel counterpart still lacks systematic study. This leads us to the following questions: \emph{how to design efficient parallel MCTS (or more general cases) algorithms with rigorous theoretical guarantee? Is it possible to achieve linear speedup?} In this paper, we consider the search problem on a more general acyclic one-root graph (namely, Monte Carlo Graph Search (MCGS)), which generalizes MCTS. We develop a parallel algorithm (P-MCGS) to assign multiple workers to investigate appropriate leaf nodes simultaneously. Our analysis shows that P-MCGS algorithm achieves linear speedup and that the sample complexity is comparable to its sequential counterpart.
AutoML from Service Provider's Perspective: Multi-device, Multi-tenant Model Selection with GP-EI
Oct 28, 2018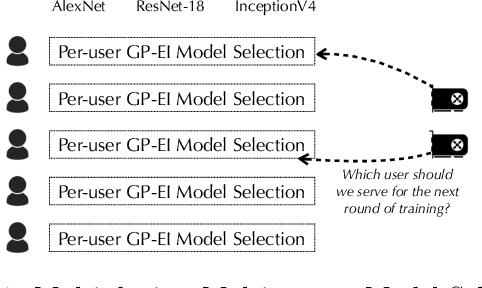
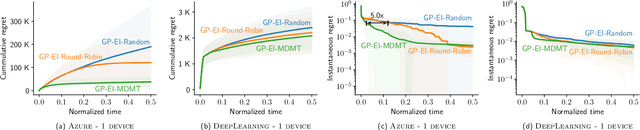
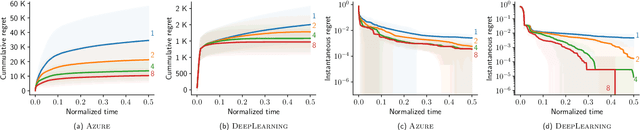
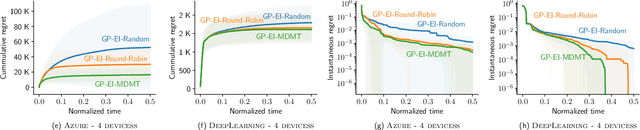
AutoML has become a popular service that is provided by most leading cloud service providers today. In this paper, we focus on the AutoML problem from the \emph{service provider's perspective}, motivated by the following practical consideration: When an AutoML service needs to serve {\em multiple users} with {\em multiple devices} at the same time, how can we allocate these devices to users in an efficient way? We focus on GP-EI, one of the most popular algorithms for automatic model selection and hyperparameter tuning, used by systems such as Google Vizer. The technical contribution of this paper is the first multi-device, multi-tenant algorithm for GP-EI that is aware of \emph{multiple} computation devices and multiple users sharing the same set of computation devices. Theoretically, given $N$ users and $M$ devices, we obtain a regret bound of $O((\text{\bf {MIU}}(T,K) + M)\frac{N^2}{M})$, where $\text{\bf {MIU}}(T,K)$ refers to the maximal incremental uncertainty up to time $T$ for the covariance matrix $K$. Empirically, we evaluate our algorithm on two applications of automatic model selection, and show that our algorithm significantly outperforms the strategy of serving users independently. Moreover, when multiple computation devices are available, we achieve near-linear speedup when the number of users is much larger than the number of devices.