 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImagen Editor and EditBench: Advancing and Evaluating Text-Guided Image Inpainting
Dec 13, 2022



Text-guided image editing can have a transformative impact in supporting creative applications. A key challenge is to generate edits that are faithful to input text prompts, while consistent with input images. We present Imagen Editor, a cascaded diffusion model built, by fine-tuning Imagen on text-guided image inpainting. Imagen Editor's edits are faithful to the text prompts, which is accomplished by using object detectors to propose inpainting masks during training. In addition, Imagen Editor captures fine details in the input image by conditioning the cascaded pipeline on the original high resolution image. To improve qualitative and quantitative evaluation, we introduce EditBench, a systematic benchmark for text-guided image inpainting. EditBench evaluates inpainting edits on natural and generated images exploring objects, attributes, and scenes. Through extensive human evaluation on EditBench, we find that object-masking during training leads to across-the-board improvements in text-image alignment -- such that Imagen Editor is preferred over DALL-E 2 and Stable Diffusion -- and, as a cohort, these models are better at object-rendering than text-rendering, and handle material/color/size attributes better than count/shape attributes.
Underspecification in Scene Description-to-Depiction Tasks
Oct 11, 2022

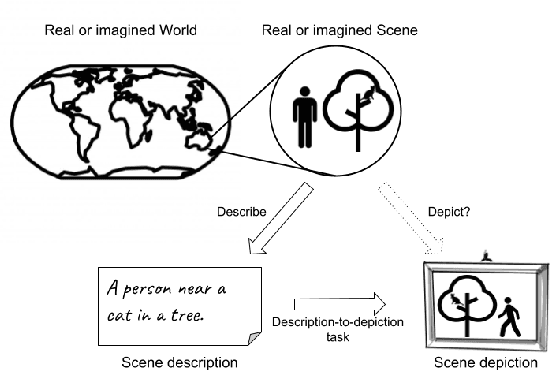

Questions regarding implicitness, ambiguity and underspecification are crucial for understanding the task validity and ethical concerns of multimodal image+text systems, yet have received little attention to date. This position paper maps out a conceptual framework to address this gap, focusing on systems which generate images depicting scenes from scene descriptions. In doing so, we account for how texts and images convey meaning differently. We outline a set of core challenges concerning textual and visual ambiguity, as well as risks that may be amplified by ambiguous and underspecified elements. We propose and discuss strategies for addressing these challenges, including generating visually ambiguous images, and generating a set of diverse images.
A New Path: Scaling Vision-and-Language Navigation with Synthetic Instructions and Imitation Learning
Oct 06, 2022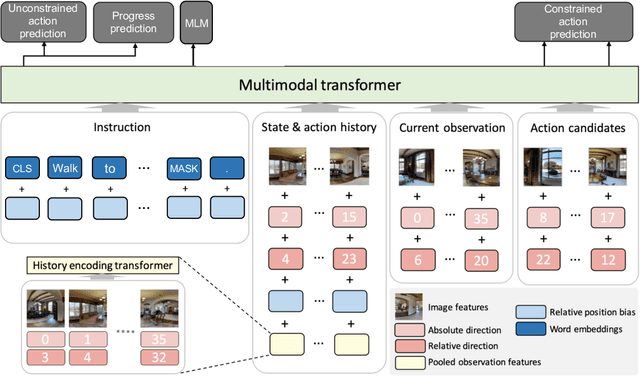
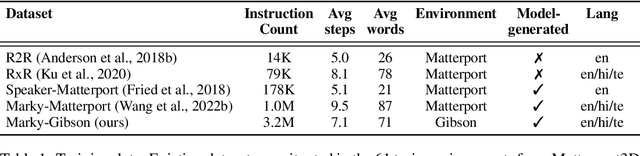
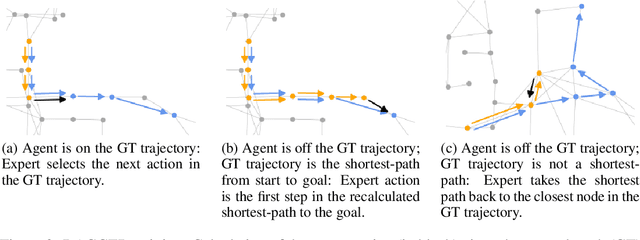

Recent studies in Vision-and-Language Navigation (VLN) train RL agents to execute natural-language navigation instructions in photorealistic environments, as a step towards intelligent agents or robots that can follow human instructions. However, given the scarcity of human instruction data and limited diversity in the training environments, these agents still struggle with complex language grounding and spatial language understanding. Pre-training on large text and image-text datasets from the web has been extensively explored but the improvements are limited. To address the scarcity of in-domain instruction data, we investigate large-scale augmentation with synthetic instructions. We take 500+ indoor environments captured in densely-sampled 360 deg panoramas, construct navigation trajectories through these panoramas, and generate a visually-grounded instruction for each trajectory using Marky (Wang et al., 2022), a high-quality multilingual navigation instruction generator. To further increase the variability of the trajectories, we also synthesize image observations from novel viewpoints using an image-to-image GAN. The resulting dataset of 4.2M instruction-trajectory pairs is two orders of magnitude larger than existing human-annotated datasets, and contains a wider variety of environments and viewpoints. To efficiently leverage data at this scale, we train a transformer agent with imitation learning for over 700M steps of experience. On the challenging Room-across-Room dataset, our approach outperforms all existing RL agents, improving the state-of-the-art NDTW from 71.1 to 79.1 in seen environments, and from 64.6 to 66.8 in unseen test environments. Our work points to a new path to improving instruction-following agents, emphasizing large-scale imitation learning and the development of synthetic instruction generation capabilities.
Scaling Autoregressive Models for Content-Rich Text-to-Image Generation
Jun 22, 2022

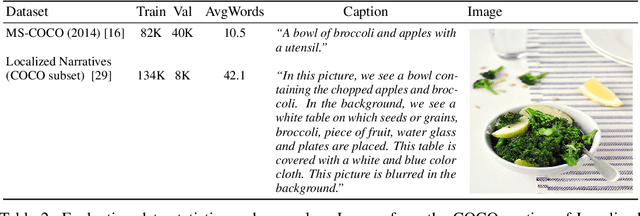
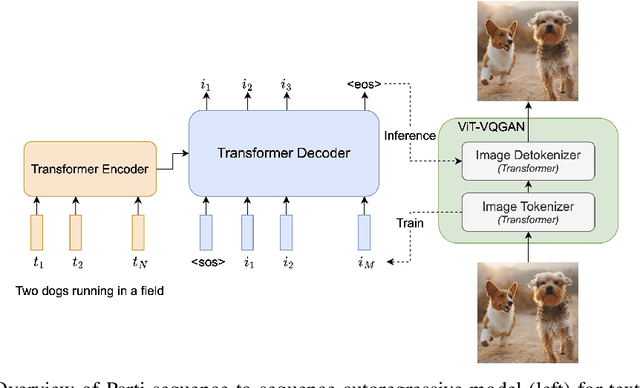
We present the Pathways Autoregressive Text-to-Image (Parti) model, which generates high-fidelity photorealistic images and supports content-rich synthesis involving complex compositions and world knowledge. Parti treats text-to-image generation as a sequence-to-sequence modeling problem, akin to machine translation, with sequences of image tokens as the target outputs rather than text tokens in another language. This strategy can naturally tap into the rich body of prior work on large language models, which have seen continued advances in capabilities and performance through scaling data and model sizes. Our approach is simple: First, Parti uses a Transformer-based image tokenizer, ViT-VQGAN, to encode images as sequences of discrete tokens. Second, we achieve consistent quality improvements by scaling the encoder-decoder Transformer model up to 20B parameters, with a new state-of-the-art zero-shot FID score of 7.23 and finetuned FID score of 3.22 on MS-COCO. Our detailed analysis on Localized Narratives as well as PartiPrompts (P2), a new holistic benchmark of over 1600 English prompts, demonstrate the effectiveness of Parti across a wide variety of categories and difficulty aspects. We also explore and highlight limitations of our models in order to define and exemplify key areas of focus for further improvements. See https://parti.research.google/ for high-resolution images.
Simple and Effective Synthesis of Indoor 3D Scenes
Apr 06, 2022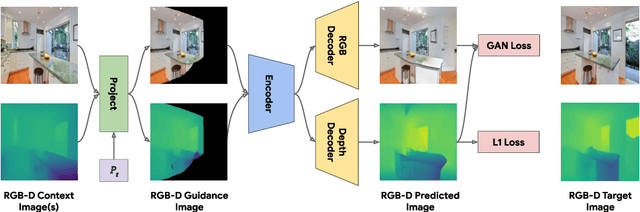


We study the problem of synthesizing immersive 3D indoor scenes from one or more images. Our aim is to generate high-resolution images and videos from novel viewpoints, including viewpoints that extrapolate far beyond the input images while maintaining 3D consistency. Existing approaches are highly complex, with many separately trained stages and components. We propose a simple alternative: an image-to-image GAN that maps directly from reprojections of incomplete point clouds to full high-resolution RGB-D images. On the Matterport3D and RealEstate10K datasets, our approach significantly outperforms prior work when evaluated by humans, as well as on FID scores. Further, we show that our model is useful for generative data augmentation. A vision-and-language navigation (VLN) agent trained with trajectories spatially-perturbed by our model improves success rate by up to 1.5% over a state of the art baseline on the R2R benchmark. Our code will be made available to facilitate generative data augmentation and applications to downstream robotics and embodied AI tasks.
Less is More: Generating Grounded Navigation Instructions from Landmarks
Nov 29, 2021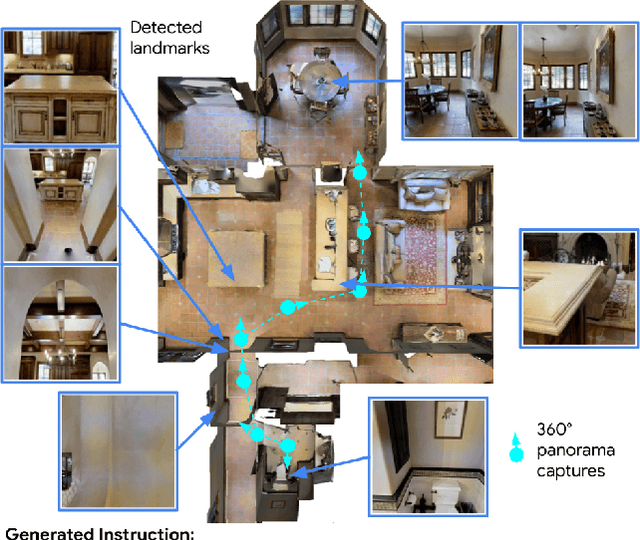


We study the automatic generation of navigation instructions from 360-degree images captured on indoor routes. Existing generators suffer from poor visual grounding, causing them to rely on language priors and hallucinate objects. Our MARKY-MT5 system addresses this by focusing on visual landmarks; it comprises a first stage landmark detector and a second stage generator -- a multimodal, multilingual, multitask encoder-decoder. To train it, we bootstrap grounded landmark annotations on top of the Room-across-Room (RxR) dataset. Using text parsers, weak supervision from RxR's pose traces, and a multilingual image-text encoder trained on 1.8b images, we identify 1.1m English, Hindi and Telugu landmark descriptions and ground them to specific regions in panoramas. On Room-to-Room, human wayfinders obtain success rates (SR) of 71% following MARKY-MT5's instructions, just shy of their 75% SR following human instructions -- and well above SRs with other generators. Evaluations on RxR's longer, diverse paths obtain 61-64% SRs on three languages. Generating such high-quality navigation instructions in novel environments is a step towards conversational navigation tools and could facilitate larger-scale training of instruction-following agents.
Vector-quantized Image Modeling with Improved VQGAN
Oct 09, 2021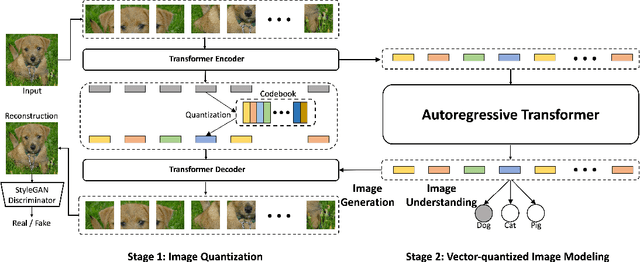



Pretraining language models with next-token prediction on massive text corpora has delivered phenomenal zero-shot, few-shot, transfer learning and multi-tasking capabilities on both generative and discriminative language tasks. Motivated by this success, we explore a Vector-quantized Image Modeling (VIM) approach that involves pretraining a Transformer to predict rasterized image tokens autoregressively. The discrete image tokens are encoded from a learned Vision-Transformer-based VQGAN (ViT-VQGAN). We first propose multiple improvements over vanilla VQGAN from architecture to codebook learning, yielding better efficiency and reconstruction fidelity. The improved ViT-VQGAN further improves vector-quantized image modeling tasks, including unconditional, class-conditioned image generation and unsupervised representation learning. When trained on ImageNet at 256x256 resolution, we achieve Inception Score (IS) of 175.1 and Fr'echet Inception Distance (FID) of 4.17, a dramatic improvement over the vanilla VQGAN, which obtains 70.6 and 17.04 for IS and FID, respectively. Based on ViT-VQGAN and unsupervised pretraining, we further evaluate the pretrained Transformer by averaging intermediate features, similar to Image GPT (iGPT). This ImageNet-pretrained VIM-L significantly beats iGPT-L on linear-probe accuracy from 60.3% to 72.2% for a similar model size. ViM-L also outperforms iGPT-XL which is trained with extra web image data and larger model size.
MURAL: Multimodal, Multitask Retrieval Across Languages
Sep 10, 2021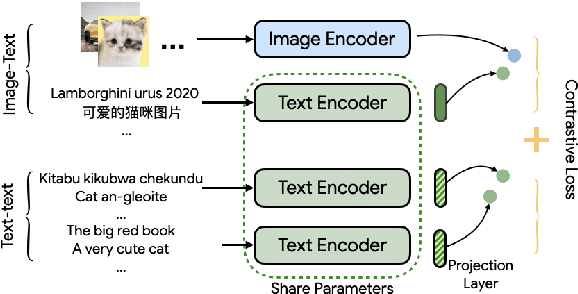
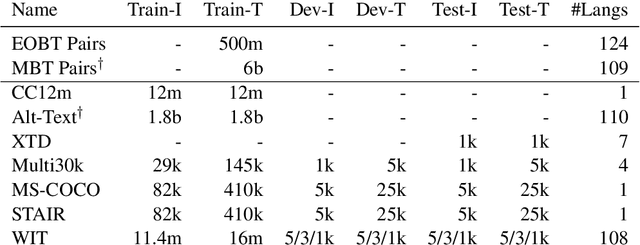
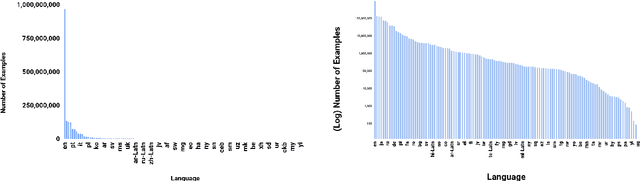
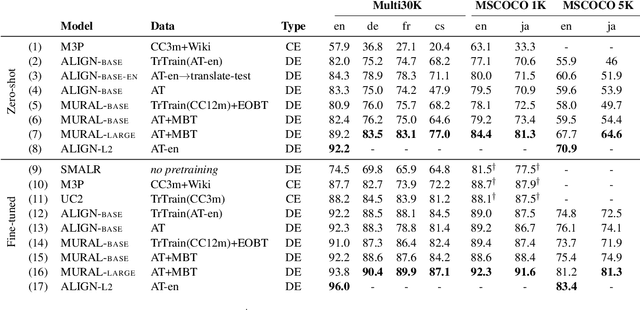
Both image-caption pairs and translation pairs provide the means to learn deep representations of and connections between languages. We use both types of pairs in MURAL (MUltimodal, MUltitask Representations Across Languages), a dual encoder that solves two tasks: 1) image-text matching and 2) translation pair matching. By incorporating billions of translation pairs, MURAL extends ALIGN (Jia et al. PMLR'21)--a state-of-the-art dual encoder learned from 1.8 billion noisy image-text pairs. When using the same encoders, MURAL's performance matches or exceeds ALIGN's cross-modal retrieval performance on well-resourced languages across several datasets. More importantly, it considerably improves performance on under-resourced languages, showing that text-text learning can overcome a paucity of image-caption examples for these languages. On the Wikipedia Image-Text dataset, for example, MURAL-base improves zero-shot mean recall by 8.1% on average for eight under-resourced languages and by 6.8% on average when fine-tuning. We additionally show that MURAL's text representations cluster not only with respect to genealogical connections but also based on areal linguistics, such as the Balkan Sprachbund.
Pathdreamer: A World Model for Indoor Navigation
May 18, 2021
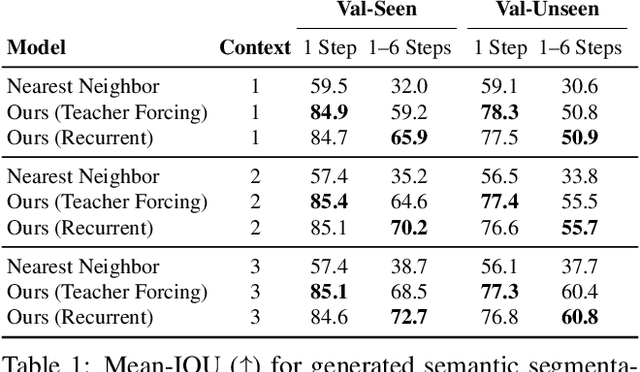
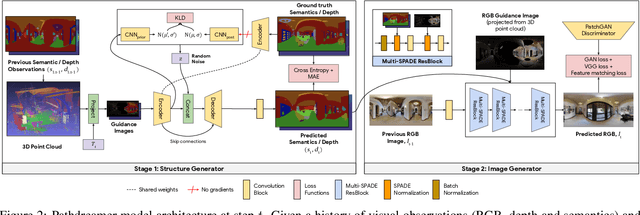
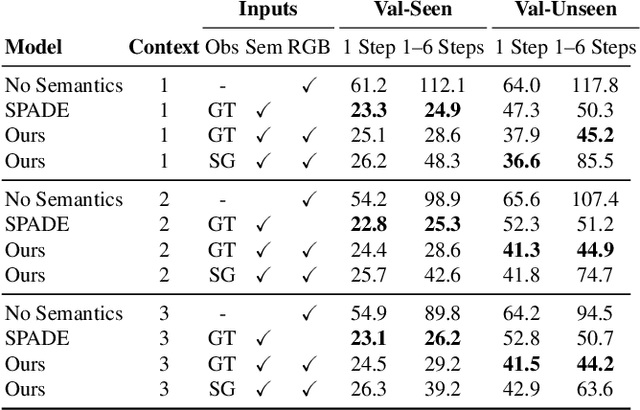
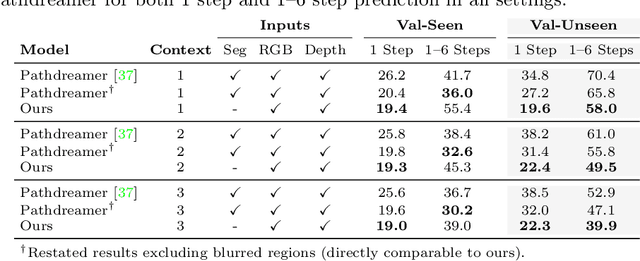
People navigating in unfamiliar buildings take advantage of myriad visual, spatial and semantic cues to efficiently achieve their navigation goals. Towards equipping computational agents with similar capabilities, we introduce Pathdreamer, a visual world model for agents navigating in novel indoor environments. Given one or more previous visual observations, Pathdreamer generates plausible high-resolution 360 visual observations (RGB, semantic segmentation and depth) for viewpoints that have not been visited, in buildings not seen during training. In regions of high uncertainty (e.g. predicting around corners, imagining the contents of an unseen room), Pathdreamer can predict diverse scenes, allowing an agent to sample multiple realistic outcomes for a given trajectory. We demonstrate that Pathdreamer encodes useful and accessible visual, spatial and semantic knowledge about human environments by using it in the downstream task of Vision-and-Language Navigation (VLN). Specifically, we show that planning ahead with Pathdreamer brings about half the benefit of looking ahead at actual observations from unobserved parts of the environment. We hope that Pathdreamer will help unlock model-based approaches to challenging embodied navigation tasks such as navigating to specified objects and VLN.
Talk, Don't Write: A Study of Direct Speech-Based Image Retrieval
Apr 08, 2021
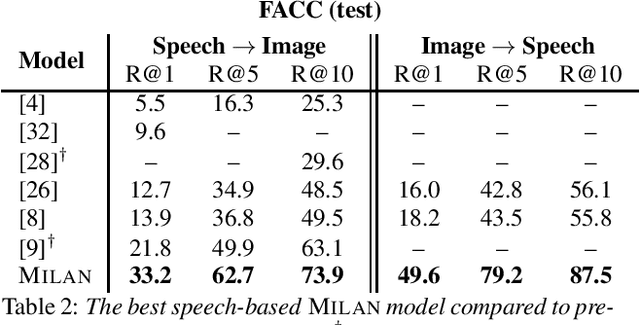
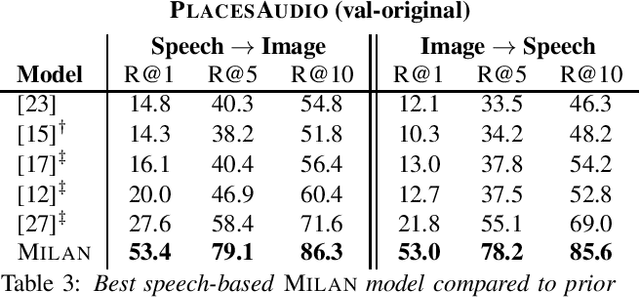
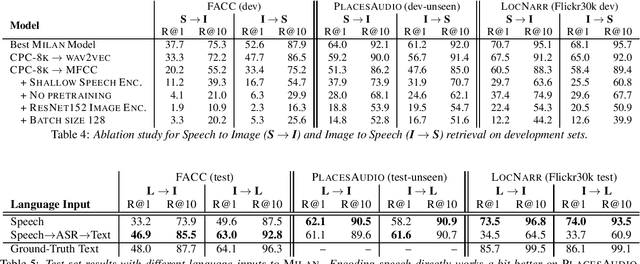
Speech-based image retrieval has been studied as a proxy for joint representation learning, usually without emphasis on retrieval itself. As such, it is unclear how well speech-based retrieval can work in practice -- both in an absolute sense and versus alternative strategies that combine automatic speech recognition (ASR) with strong text encoders. In this work, we extensively study and expand choices of encoder architectures, training methodology (including unimodal and multimodal pretraining), and other factors. Our experiments cover different types of speech in three datasets: Flickr Audio, Places Audio, and Localized Narratives. Our best model configuration achieves large gains over state of the art, e.g., pushing recall-at-one from 21.8% to 33.2% for Flickr Audio and 27.6% to 53.4% for Places Audio. We also show our best speech-based models can match or exceed cascaded ASR-to-text encoding when speech is spontaneous, accented, or otherwise hard to automatically transcribe.