 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDuoGen: Towards General Purpose Interleaved Multimodal Generation
Feb 03, 2026Interleaved multimodal generation enables capabilities beyond unimodal generation models, such as step-by-step instructional guides, visual planning, and generating visual drafts for reasoning. However, the quality of existing interleaved generation models under general instructions remains limited by insufficient training data and base model capacity. We present DuoGen, a general-purpose interleaved generation framework that systematically addresses data curation, architecture design, and evaluation. On the data side, we build a large-scale, high-quality instruction-tuning dataset by combining multimodal conversations rewritten from curated raw websites, and diverse synthetic examples covering everyday scenarios. Architecturally, DuoGen leverages the strong visual understanding of a pretrained multimodal LLM and the visual generation capabilities of a diffusion transformer (DiT) pretrained on video generation, avoiding costly unimodal pretraining and enabling flexible base model selection. A two-stage decoupled strategy first instruction-tunes the MLLM, then aligns DiT with it using curated interleaved image-text sequences. Across public and newly proposed benchmarks, DuoGen outperforms prior open-source models in text quality, image fidelity, and image-context alignment, and also achieves state-of-the-art performance on text-to-image and image editing among unified generation models. Data and code will be released at https://research.nvidia.com/labs/dir/duogen/.
VibeTensor: System Software for Deep Learning, Fully Generated by AI Agents
Jan 21, 2026VIBETENSOR is an open-source research system software stack for deep learning, generated by LLM-powered coding agents under high-level human guidance. In this paper, "fully generated" refers to code provenance: implementation changes were produced and applied as agent-proposed diffs; validation relied on agent-run builds, tests, and differential checks, without per-change manual diff review. It implements a PyTorch-style eager tensor library with a C++20 core (CPU+CUDA), a torch-like Python overlay via nanobind, and an experimental Node.js/TypeScript interface. Unlike thin bindings, VIBETENSOR includes its own tensor/storage system, schema-lite dispatcher, reverse-mode autograd, CUDA runtime (streams/events/graphs), a stream-ordered caching allocator with diagnostics, and a stable C ABI for dynamically loaded operator plugins. We view this release as a milestone for AI-assisted software engineering: it shows coding agents can generate a coherent deep learning runtime spanning language bindings down to CUDA memory management, validated primarily by builds and tests. We describe the architecture, summarize the workflow used to produce and validate the system, and evaluate the artifact. We report repository scale and test-suite composition, and summarize reproducible microbenchmarks from an accompanying AI-generated kernel suite, including fused attention versus PyTorch SDPA/FlashAttention. We also report end-to-end training sanity checks on 3 small workloads (sequence reversal, ViT, miniGPT) on NVIDIA H100 (Hopper, SM90) and Blackwell-class GPUs; multi-GPU results are Blackwell-only and use an optional CUTLASS-based ring-allreduce plugin gated on CUDA 13+ and sm103a toolchain support. Finally, we discuss failure modes in generated system software, including a "Frankenstein" composition effect where locally correct subsystems interact to yield globally suboptimal performance.
SAGE: Training Smart Any-Horizon Agents for Long Video Reasoning with Reinforcement Learning
Dec 15, 2025As humans, we are natural any-horizon reasoners, i.e., we can decide whether to iteratively skim long videos or watch short ones in full when necessary for a given task. With this in mind, one would expect video reasoning models to reason flexibly across different durations. However, SOTA models are still trained to predict answers in a single turn while processing a large number of frames, akin to watching an entire long video, requiring significant resources. This raises the question: Is it possible to develop performant any-horizon video reasoning systems? Inspired by human behavior, we first propose SAGE, an agent system that performs multi-turn reasoning on long videos while handling simpler problems in a single turn. Secondly, we introduce an easy synthetic data generation pipeline using Gemini-2.5-Flash to train the orchestrator, SAGE-MM, which lies at the core of SAGE. We further propose an effective RL post-training recipe essential for instilling any-horizon reasoning ability in SAGE-MM. Thirdly, we curate SAGE-Bench with an average duration of greater than 700 seconds for evaluating video reasoning ability in real-world entertainment use cases. Lastly, we empirically validate the effectiveness of our system, data, and RL recipe, observing notable improvements of up to 6.1% on open-ended video reasoning tasks, as well as an impressive 8.2% improvement on videos longer than 10 minutes.
T2I-Copilot: A Training-Free Multi-Agent Text-to-Image System for Enhanced Prompt Interpretation and Interactive Generation
Jul 28, 2025Text-to-Image (T2I) generative models have revolutionized content creation but remain highly sensitive to prompt phrasing, often requiring users to repeatedly refine prompts multiple times without clear feedback. While techniques such as automatic prompt engineering, controlled text embeddings, denoising, and multi-turn generation mitigate these issues, they offer limited controllability, or often necessitate additional training, restricting the generalization abilities. Thus, we introduce T2I-Copilot, a training-free multi-agent system that leverages collaboration between (Multimodal) Large Language Models to automate prompt phrasing, model selection, and iterative refinement. This approach significantly simplifies prompt engineering while enhancing generation quality and text-image alignment compared to direct generation. Specifically, T2I-Copilot consists of three agents: (1) Input Interpreter, which parses the input prompt, resolves ambiguities, and generates a standardized report; (2) Generation Engine, which selects the appropriate model from different types of T2I models and organizes visual and textual prompts to initiate generation; and (3) Quality Evaluator, which assesses aesthetic quality and text-image alignment, providing scores and feedback for potential regeneration. T2I-Copilot can operate fully autonomously while also supporting human-in-the-loop intervention for fine-grained control. On GenAI-Bench, using open-source generation models, T2I-Copilot achieves a VQA score comparable to commercial models RecraftV3 and Imagen 3, surpasses FLUX1.1-pro by 6.17% at only 16.59% of its cost, and outperforms FLUX.1-dev and SD 3.5 Large by 9.11% and 6.36%. Code will be released at: https://github.com/SHI-Labs/T2I-Copilot.
Distilling Normalizing Flows
Jun 26, 2025Explicit density learners are becoming an increasingly popular technique for generative models because of their ability to better model probability distributions. They have advantages over Generative Adversarial Networks due to their ability to perform density estimation and having exact latent-variable inference. This has many advantages, including: being able to simply interpolate, calculate sample likelihood, and analyze the probability distribution. The downside of these models is that they are often more difficult to train and have lower sampling quality. Normalizing flows are explicit density models, that use composable bijective functions to turn an intractable probability function into a tractable one. In this work, we present novel knowledge distillation techniques to increase sampling quality and density estimation of smaller student normalizing flows. We seek to study the capacity of knowledge distillation in Compositional Normalizing Flows to understand the benefits and weaknesses provided by these architectures. Normalizing flows have unique properties that allow for a non-traditional forms of knowledge transfer, where we can transfer that knowledge within intermediate layers. We find that through this distillation, we can make students significantly smaller while making substantial performance gains over a non-distilled student. With smaller models there is a proportionally increased throughput as this is dependent upon the number of bijectors, and thus parameters, in the network.
Person Recognition at Altitude and Range: Fusion of Face, Body Shape and Gait
May 07, 2025
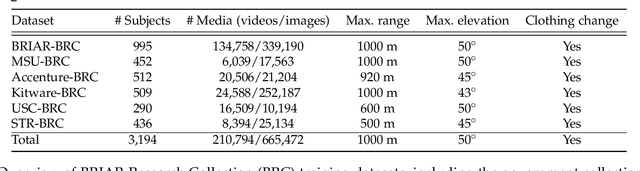

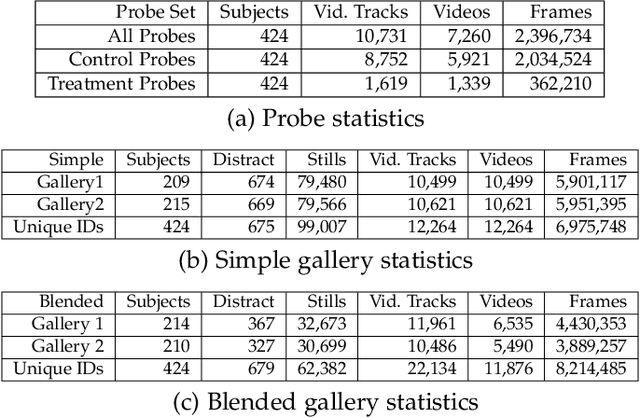
We address the problem of whole-body person recognition in unconstrained environments. This problem arises in surveillance scenarios such as those in the IARPA Biometric Recognition and Identification at Altitude and Range (BRIAR) program, where biometric data is captured at long standoff distances, elevated viewing angles, and under adverse atmospheric conditions (e.g., turbulence and high wind velocity). To this end, we propose FarSight, a unified end-to-end system for person recognition that integrates complementary biometric cues across face, gait, and body shape modalities. FarSight incorporates novel algorithms across four core modules: multi-subject detection and tracking, recognition-aware video restoration, modality-specific biometric feature encoding, and quality-guided multi-modal fusion. These components are designed to work cohesively under degraded image conditions, large pose and scale variations, and cross-domain gaps. Extensive experiments on the BRIAR dataset, one of the most comprehensive benchmarks for long-range, multi-modal biometric recognition, demonstrate the effectiveness of FarSight. Compared to our preliminary system, this system achieves a 34.1% absolute gain in 1:1 verification accuracy (TAR@0.1% FAR), a 17.8% increase in closed-set identification (Rank-20), and a 34.3% reduction in open-set identification errors (FNIR@1% FPIR). Furthermore, FarSight was evaluated in the 2025 NIST RTE Face in Video Evaluation (FIVE), which conducts standardized face recognition testing on the BRIAR dataset. These results establish FarSight as a state-of-the-art solution for operational biometric recognition in challenging real-world conditions.
Generalized Neighborhood Attention: Multi-dimensional Sparse Attention at the Speed of Light
Apr 23, 2025Many sparse attention mechanisms such as Neighborhood Attention have typically failed to consistently deliver speedup over the self attention baseline. This is largely due to the level of complexity in attention infrastructure, and the rapid evolution of AI hardware architecture. At the same time, many state-of-the-art foundational models, particularly in computer vision, are heavily bound by attention, and need reliable sparsity to escape the O(n^2) complexity. In this paper, we study a class of promising sparse attention mechanisms that focus on locality, and aim to develop a better analytical model of their performance improvements. We first introduce Generalized Neighborhood Attention (GNA), which can describe sliding window, strided sliding window, and blocked attention. We then consider possible design choices in implementing these approaches, and create a simulator that can provide much more realistic speedup upper bounds for any given setting. Finally, we implement GNA on top of a state-of-the-art fused multi-headed attention (FMHA) kernel designed for the NVIDIA Blackwell architecture in CUTLASS. Our implementation can fully realize the maximum speedup theoretically possible in many perfectly block-sparse cases, and achieves an effective utilization of 1.3 petaFLOPs/second in FP16. In addition, we plug various GNA configurations into off-the-shelf generative models, such as Cosmos-7B, HunyuanVideo, and FLUX, and show that it can deliver 28% to 46% end-to-end speedup on B200 without any fine-tuning. We will open source our simulator and Blackwell kernels directly through the NATTEN project.
RAGME: Retrieval Augmented Video Generation for Enhanced Motion Realism
Apr 09, 2025



Video generation is experiencing rapid growth, driven by advances in diffusion models and the development of better and larger datasets. However, producing high-quality videos remains challenging due to the high-dimensional data and the complexity of the task. Recent efforts have primarily focused on enhancing visual quality and addressing temporal inconsistencies, such as flickering. Despite progress in these areas, the generated videos often fall short in terms of motion complexity and physical plausibility, with many outputs either appearing static or exhibiting unrealistic motion. In this work, we propose a framework to improve the realism of motion in generated videos, exploring a complementary direction to much of the existing literature. Specifically, we advocate for the incorporation of a retrieval mechanism during the generation phase. The retrieved videos act as grounding signals, providing the model with demonstrations of how the objects move. Our pipeline is designed to apply to any text-to-video diffusion model, conditioning a pretrained model on the retrieved samples with minimal fine-tuning. We demonstrate the superiority of our approach through established metrics, recently proposed benchmarks, and qualitative results, and we highlight additional applications of the framework.
Slow-Fast Architecture for Video Multi-Modal Large Language Models
Apr 02, 2025Balancing temporal resolution and spatial detail under limited compute budget remains a key challenge for video-based multi-modal large language models (MLLMs). Existing methods typically compress video representations using predefined rules before feeding them into the LLM, resulting in irreversible information loss and often ignoring input instructions. To address this, we propose a novel slow-fast architecture that naturally circumvents this trade-off, enabling the use of more input frames while preserving spatial details. Inspired by how humans first skim a video before focusing on relevant parts, our slow-fast design employs a dual-token strategy: 1) "fast" visual tokens -- a compact set of compressed video features -- are fed into the LLM alongside text embeddings to provide a quick overview; 2) "slow" visual tokens -- uncompressed video features -- are cross-attended by text embeddings through specially designed hybrid decoder layers, enabling instruction-aware extraction of relevant visual details with linear complexity. We conduct systematic exploration to optimize both the overall architecture and key components. Experiments show that our model significantly outperforms self-attention-only baselines, extending the input capacity from 16 to 128 frames with just a 3% increase in computation, and achieving a 16% average performance improvement across five video understanding benchmarks. Our 7B model achieves state-of-the-art performance among models of similar size. Furthermore, our slow-fast architecture is a plug-and-play design that can be integrated into other video MLLMs to improve efficiency and scalability.
Safe Vision-Language Models via Unsafe Weights Manipulation
Mar 14, 2025



Vision-language models (VLMs) often inherit the biases and unsafe associations present within their large-scale training dataset. While recent approaches mitigate unsafe behaviors, their evaluation focuses on how safe the model is on unsafe inputs, ignoring potential shortcomings on safe ones. In this paper, we first revise safety evaluation by introducing SafeGround, a new set of metrics that evaluate safety at different levels of granularity. With this metric, we uncover a surprising issue of training-based methods: they make the model less safe on safe inputs. From this finding, we take a different direction and explore whether it is possible to make a model safer without training, introducing Unsafe Weights Manipulation (UWM). UWM uses a calibration set of safe and unsafe instances to compare activations between safe and unsafe content, identifying the most important parameters for processing the latter. Their values are then manipulated via negation. Experiments show that UWM achieves the best tradeoff between safety and knowledge preservation, consistently improving VLMs on unsafe queries while outperforming even training-based state-of-the-art methods on safe ones.