 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Deepfake Detectors in the Wild
Jul 29, 2025Deepfakes powered by advanced machine learning models present a significant and evolving threat to identity verification and the authenticity of digital media. Although numerous detectors have been developed to address this problem, their effectiveness has yet to be tested when applied to real-world data. In this work we evaluate modern deepfake detectors, introducing a novel testing procedure designed to mimic real-world scenarios for deepfake detection. Using state-of-the-art deepfake generation methods, we create a comprehensive dataset containing more than 500,000 high-quality deepfake images. Our analysis shows that detecting deepfakes still remains a challenging task. The evaluation shows that in fewer than half of the deepfake detectors tested achieved an AUC score greater than 60%, with the lowest being 50%. We demonstrate that basic image manipulations, such as JPEG compression or image enhancement, can significantly reduce model performance. All code and data are publicly available at https://github.com/messlav/Deepfake-Detectors-in-the-Wild.
Distilling Normalizing Flows
Jun 26, 2025



Explicit density learners are becoming an increasingly popular technique for generative models because of their ability to better model probability distributions. They have advantages over Generative Adversarial Networks due to their ability to perform density estimation and having exact latent-variable inference. This has many advantages, including: being able to simply interpolate, calculate sample likelihood, and analyze the probability distribution. The downside of these models is that they are often more difficult to train and have lower sampling quality. Normalizing flows are explicit density models, that use composable bijective functions to turn an intractable probability function into a tractable one. In this work, we present novel knowledge distillation techniques to increase sampling quality and density estimation of smaller student normalizing flows. We seek to study the capacity of knowledge distillation in Compositional Normalizing Flows to understand the benefits and weaknesses provided by these architectures. Normalizing flows have unique properties that allow for a non-traditional forms of knowledge transfer, where we can transfer that knowledge within intermediate layers. We find that through this distillation, we can make students significantly smaller while making substantial performance gains over a non-distilled student. With smaller models there is a proportionally increased throughput as this is dependent upon the number of bijectors, and thus parameters, in the network.
Fast Data-Driven Simulation of Cherenkov Detectors Using Generative Adversarial Networks
May 28, 2019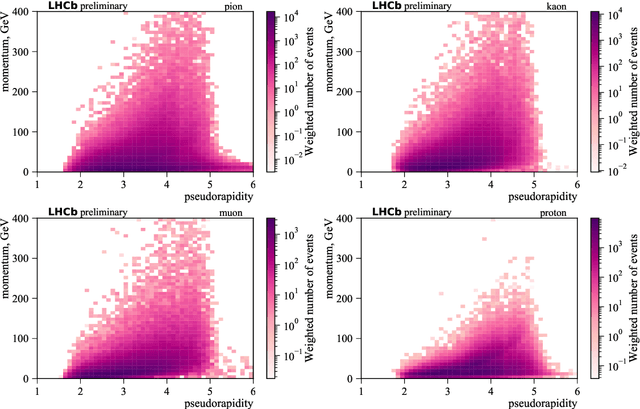
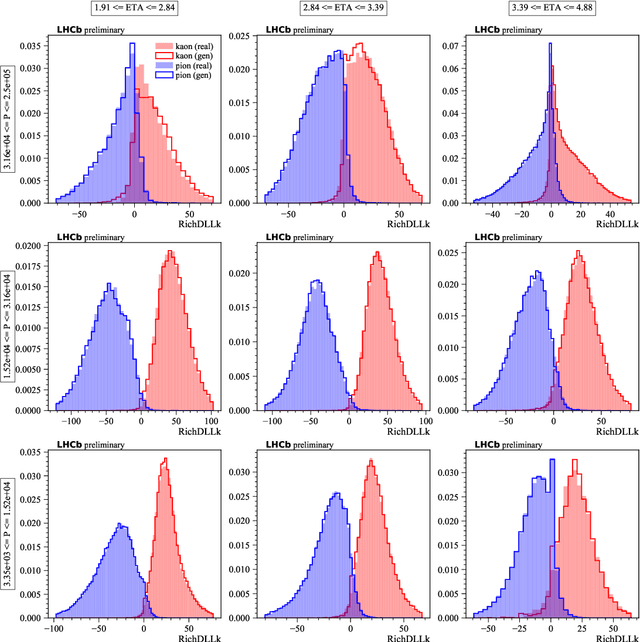
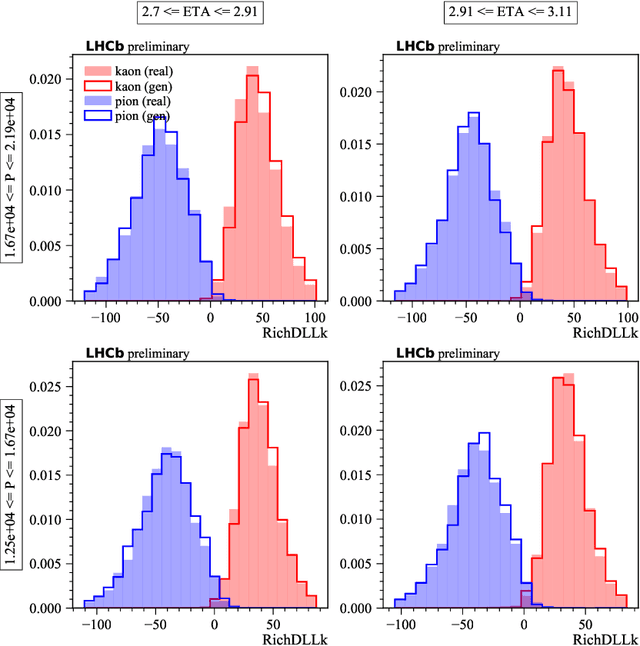
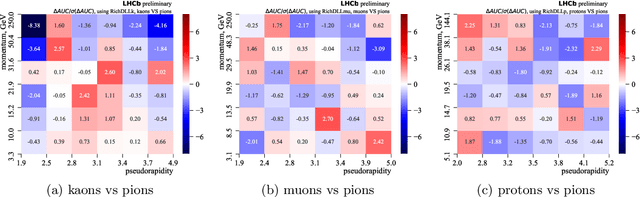
The increasing luminosities of future Large Hadron Collider runs and next generation of collider experiments will require an unprecedented amount of simulated events to be produced. Such large scale productions are extremely demanding in terms of computing resources. Thus new approaches to event generation and simulation of detector responses are needed. In LHCb, the accurate simulation of Cherenkov detectors takes a sizeable fraction of CPU time. An alternative approach is described here, when one generates high-level reconstructed observables using a generative neural network to bypass low level details. This network is trained to reproduce the particle species likelihood function values based on the track kinematic parameters and detector occupancy. The fast simulation is trained using real data samples collected by LHCb during run 2. We demonstrate that this approach provides high-fidelity results.