 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNemotron 3 Ultra: Open, Efficient Mixture-of-Experts Hybrid Mamba-Transformer Model for Agentic Reasoning
Jun 12, 2026We introduce Nemotron 3 Ultra, a 550 billion total and 55 billion active parameter Mixture-of-Experts Hybrid Mamba-Attention language model. We pre-trained Nemotron 3 Ultra on 20 trillion text tokens, then extended the context length to 1M tokens, and post-trained using Supervised Fine Tuning (SFT), Reinforcement Learning (RL), and Multi-teacher On-Policy Distillation (MOPD). Nemotron 3 Ultra is our most capable model yet, employing multiple key technologies - LatentMoE, Multi Token Prediction (MTP), NVFP4 pre-training, multi-environment RLVR, MOPD, and reasoning budget control. Nemotron 3 Ultra achieves up to ~6x higher inference throughput as compared to state-of-the-art publicly available LLMs while attaining on-par accuracy. The state-of-the-art accuracy, high inference throughput, and 1M token context length make Nemotron 3 Ultra ideal for long-running autonomous agentic tasks. We open-source the base, post-trained, and quantized checkpoints, along with the training data and recipe on HuggingFace.
Nemotron 3 Nano Omni: Efficient and Open Multimodal Intelligence
Apr 27, 2026We introduce Nemotron 3 Nano Omni, the latest model in the Nemotron multimodal series and the first to natively support audio inputs alongside text, images, and video. Nemotron 3 Nano Omni delivers consistent accuracy improvements over its predecessor, Nemotron Nano V2 VL, across all modalities, enabled by advances in architecture, training data and recipes. In particular, Nemotron 3 delivers leading results in real-world document understanding, long audio-video comprehension, and agentic computer use. Built on the highly efficient Nemotron 3 Nano 30B-A3B backbone, Nemotron 3 Nano Omni further incorporates innovative multimodal token-reduction techniques to deliver substantially lower inference latency and higher throughput than other models of similar size. We are releasing model checkpoints in BF16, FP8, and FP4 formats, along with portions of the training data and codebase to facilitate further research and development.
Nemotron 3 Super: Open, Efficient Mixture-of-Experts Hybrid Mamba-Transformer Model for Agentic Reasoning
Apr 14, 2026We describe the pre-training, post-training, and quantization of Nemotron 3 Super, a 120 billion (active 12 billion) parameter hybrid Mamba-Attention Mixture-of-Experts model. Nemotron 3 Super is the first model in the Nemotron 3 family to 1) be pre-trained in NVFP4, 2) leverage LatentMoE, a new Mixture-of-Experts architecture that optimizes for both accuracy per FLOP and accuracy per parameter, and 3) include MTP layers for inference acceleration through native speculative decoding. We pre-trained Nemotron 3 Super on 25 trillion tokens followed by post-training using supervised fine tuning (SFT) and reinforcement learning (RL). The final model supports up to 1M context length and achieves comparable accuracy on common benchmarks, while also achieving up to 2.2x and 7.5x higher inference throughput compared to GPT-OSS-120B and Qwen3.5-122B, respectively. Nemotron 3 Super datasets, along with the base, post-trained, and quantized checkpoints, are open-sourced on HuggingFace.
DuoGen: Towards General Purpose Interleaved Multimodal Generation
Feb 03, 2026Interleaved multimodal generation enables capabilities beyond unimodal generation models, such as step-by-step instructional guides, visual planning, and generating visual drafts for reasoning. However, the quality of existing interleaved generation models under general instructions remains limited by insufficient training data and base model capacity. We present DuoGen, a general-purpose interleaved generation framework that systematically addresses data curation, architecture design, and evaluation. On the data side, we build a large-scale, high-quality instruction-tuning dataset by combining multimodal conversations rewritten from curated raw websites, and diverse synthetic examples covering everyday scenarios. Architecturally, DuoGen leverages the strong visual understanding of a pretrained multimodal LLM and the visual generation capabilities of a diffusion transformer (DiT) pretrained on video generation, avoiding costly unimodal pretraining and enabling flexible base model selection. A two-stage decoupled strategy first instruction-tunes the MLLM, then aligns DiT with it using curated interleaved image-text sequences. Across public and newly proposed benchmarks, DuoGen outperforms prior open-source models in text quality, image fidelity, and image-context alignment, and also achieves state-of-the-art performance on text-to-image and image editing among unified generation models. Data and code will be released at https://research.nvidia.com/labs/dir/duogen/.
NVIDIA Nemotron 3: Efficient and Open Intelligence
Dec 24, 2025We introduce the Nemotron 3 family of models - Nano, Super, and Ultra. These models deliver strong agentic, reasoning, and conversational capabilities. The Nemotron 3 family uses a Mixture-of-Experts hybrid Mamba-Transformer architecture to provide best-in-class throughput and context lengths of up to 1M tokens. Super and Ultra models are trained with NVFP4 and incorporate LatentMoE, a novel approach that improves model quality. The two larger models also include MTP layers for faster text generation. All Nemotron 3 models are post-trained using multi-environment reinforcement learning enabling reasoning, multi-step tool use, and support granular reasoning budget control. Nano, the smallest model, outperforms comparable models in accuracy while remaining extremely cost-efficient for inference. Super is optimized for collaborative agents and high-volume workloads such as IT ticket automation. Ultra, the largest model, provides state-of-the-art accuracy and reasoning performance. Nano is released together with its technical report and this white paper, while Super and Ultra will follow in the coming months. We will openly release the model weights, pre- and post-training software, recipes, and all data for which we hold redistribution rights.
Nemotron 3 Nano: Open, Efficient Mixture-of-Experts Hybrid Mamba-Transformer Model for Agentic Reasoning
Dec 23, 2025We present Nemotron 3 Nano 30B-A3B, a Mixture-of-Experts hybrid Mamba-Transformer language model. Nemotron 3 Nano was pretrained on 25 trillion text tokens, including more than 3 trillion new unique tokens over Nemotron 2, followed by supervised fine tuning and large-scale RL on diverse environments. Nemotron 3 Nano achieves better accuracy than our previous generation Nemotron 2 Nano while activating less than half of the parameters per forward pass. It achieves up to 3.3x higher inference throughput than similarly-sized open models like GPT-OSS-20B and Qwen3-30B-A3B-Thinking-2507, while also being more accurate on popular benchmarks. Nemotron 3 Nano demonstrates enhanced agentic, reasoning, and chat abilities and supports context lengths up to 1M tokens. We release both our pretrained Nemotron 3 Nano 30B-A3B Base and post-trained Nemotron 3 Nano 30B-A3B checkpoints on Hugging Face.
Nemotron-H: A Family of Accurate and Efficient Hybrid Mamba-Transformer Models
Apr 10, 2025



As inference-time scaling becomes critical for enhanced reasoning capabilities, it is increasingly becoming important to build models that are efficient to infer. We introduce Nemotron-H, a family of 8B and 56B/47B hybrid Mamba-Transformer models designed to reduce inference cost for a given accuracy level. To achieve this goal, we replace the majority of self-attention layers in the common Transformer model architecture with Mamba layers that perform constant computation and require constant memory per generated token. We show that Nemotron-H models offer either better or on-par accuracy compared to other similarly-sized state-of-the-art open-sourced Transformer models (e.g., Qwen-2.5-7B/72B and Llama-3.1-8B/70B), while being up to 3$\times$ faster at inference. To further increase inference speed and reduce the memory required at inference time, we created Nemotron-H-47B-Base from the 56B model using a new compression via pruning and distillation technique called MiniPuzzle. Nemotron-H-47B-Base achieves similar accuracy to the 56B model, but is 20% faster to infer. In addition, we introduce an FP8-based training recipe and show that it can achieve on par results with BF16-based training. This recipe is used to train the 56B model. All Nemotron-H models will be released, with support in Hugging Face, NeMo, and Megatron-LM.
Multi-Scale Saliency Detection using Dictionary Learning
Jul 05, 2017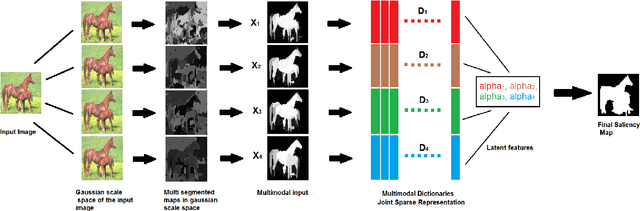
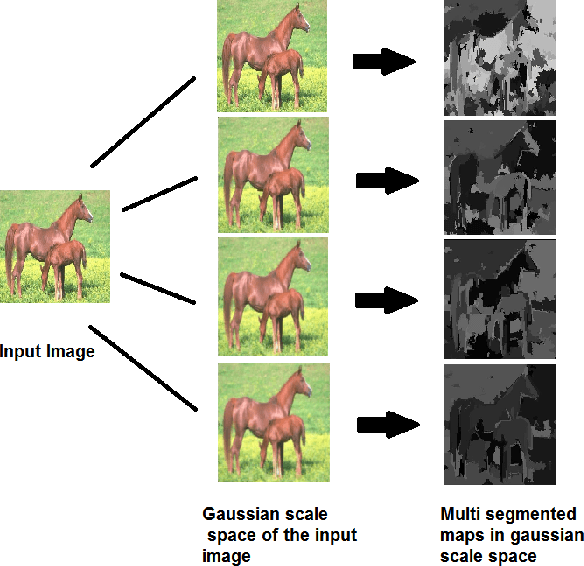
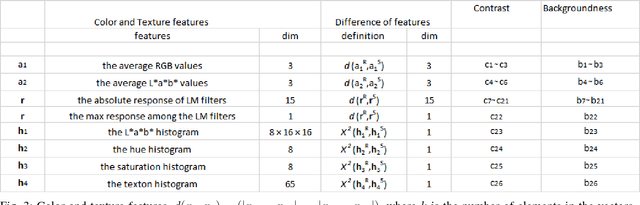
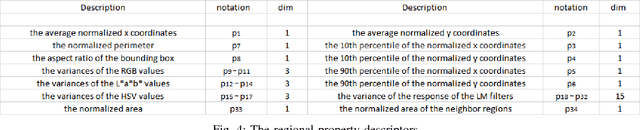
Saliency detection has drawn a lot of attention of researchers in various fields over the past several years. Saliency is the perceptual quality that makes an object, person to draw the attention of humans at the very sight. Salient object detection in an image has been used centrally in many computational photography and computer vision applications like video compression, object recognition and classification, object segmentation, adaptive content delivery, motion detection, content aware resizing, camouflage images and change blindness images to name a few. We propose a method to detect saliency in the objects using multimodal dictionary learning which has been recently used in classification and image fusion. The multimodal dictionary that we are learning is task driven which gives improved performance over its counterpart (the one which is not task specific).
Hashing in the Zero Shot Framework with Domain Adaptation
Feb 28, 2017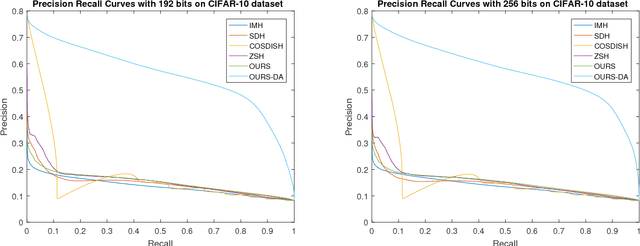
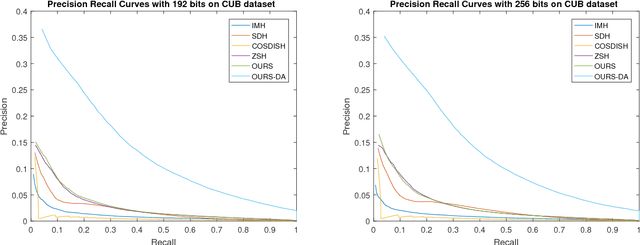
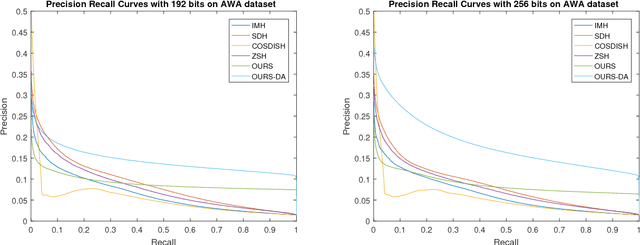
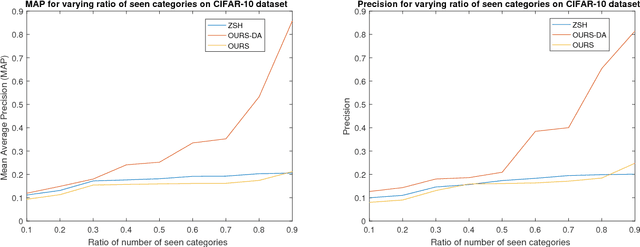
Techniques to learn hash codes which can store and retrieve large dimensional multimedia data efficiently have attracted broad research interests in the recent years. With rapid explosion of newly emerged concepts and online data, existing supervised hashing algorithms suffer from the problem of scarcity of ground truth annotations due to the high cost of obtaining manual annotations. Therefore, we propose an algorithm to learn a hash function from training images belonging to `seen' classes which can efficiently encode images of `unseen' classes to binary codes. Specifically, we project the image features from visual space and semantic features from semantic space into a common Hamming subspace. Earlier works to generate hash codes have tried to relax the discrete constraints on hash codes and solve the continuous optimization problem. However, it often leads to quantization errors. In this work, we use the max-margin classifier to learn an efficient hash function. To address the concern of domain-shift which may arise due to the introduction of new classes, we also introduce an unsupervised domain adaptation model in the proposed hashing framework. Results on the three datasets show the advantage of using domain adaptation in learning a high-quality hash function and superiority of our method for the task of image retrieval performance as compared to several state-of-the-art hashing methods.
Zero Shot Hashing
Oct 09, 2016
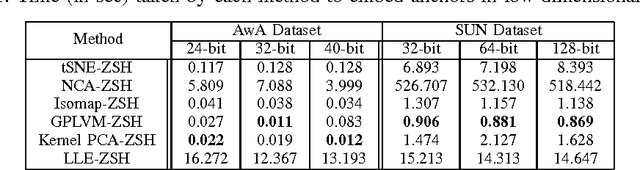
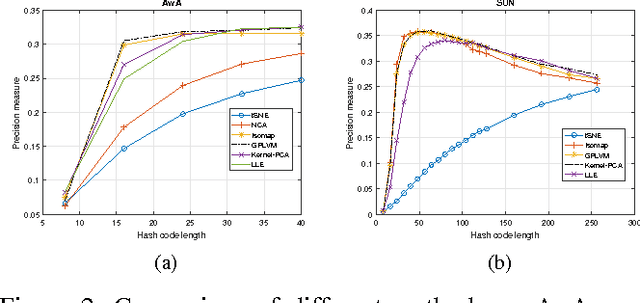

This paper provides a framework to hash images containing instances of unknown object classes. In many object recognition problems, we might have access to huge amount of data. It may so happen that even this huge data doesn't cover the objects belonging to classes that we see in our day to day life. Zero shot learning exploits auxiliary information (also called as signatures) in order to predict the labels corresponding to unknown classes. In this work, we attempt to generate the hash codes for images belonging to unseen classes, information of which is available only through the textual corpus. We formulate this as an unsupervised hashing formulation as the exact labels are not available for the instances of unseen classes. We show that the proposed solution is able to generate hash codes which can predict labels corresponding to unseen classes with appreciably good precision.