 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFigBO: A Generalized Acquisition Function Framework with Look-Ahead Capability for Bayesian Optimization
Apr 28, 2025Bayesian optimization is a powerful technique for optimizing expensive-to-evaluate black-box functions, consisting of two main components: a surrogate model and an acquisition function. In recent years, myopic acquisition functions have been widely adopted for their simplicity and effectiveness. However, their lack of look-ahead capability limits their performance. To address this limitation, we propose FigBO, a generalized acquisition function that incorporates the future impact of candidate points on global information gain. FigBO is a plug-and-play method that can integrate seamlessly with most existing myopic acquisition functions. Theoretically, we analyze the regret bound and convergence rate of FigBO when combined with the myopic base acquisition function expected improvement (EI), comparing them to those of standard EI. Empirically, extensive experimental results across diverse tasks demonstrate that FigBO achieves state-of-the-art performance and significantly faster convergence compared to existing methods.
Distributed Intelligent Sensing and Communications for 6G: Architecture and Use Cases
Apr 17, 2025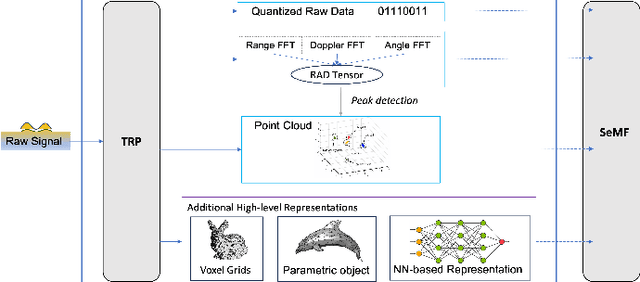
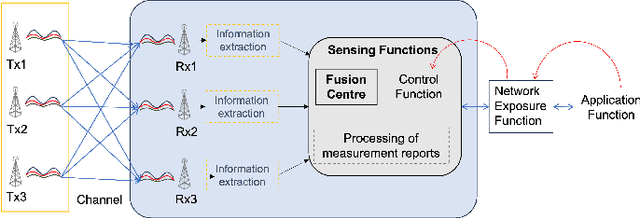
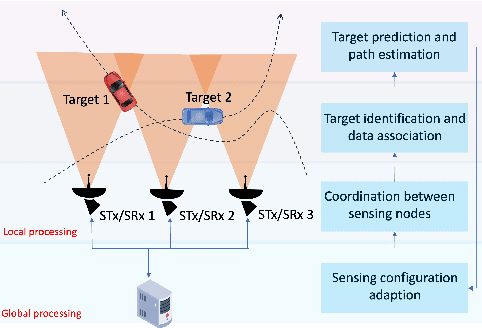

The Distributed Intelligent Sensing and Communication (DISAC) framework redefines Integrated Sensing and Communication (ISAC) for 6G by leveraging distributed architectures to enhance scalability, adaptability, and resource efficiency. This paper presents key architectural enablers, including advanced data representation, seamless target handover, support for heterogeneous devices, and semantic integration. Two use cases illustrate the transformative potential of DISAC: smart factory shop floors and Vulnerable Road User (VRU) protection at smart intersections. These scenarios demonstrate significant improvements in precision, safety, and operational efficiency compared to traditional ISAC systems. The preliminary DISAC architecture incorporates intelligent data processing, distributed coordination, and emerging technologies such as Reconfigurable Intelligent Surfaces (RIS) to meet 6G's stringent requirements. By addressing critical challenges in sensing accuracy, latency, and real-time decision-making, DISAC positions itself as a cornerstone for next-generation wireless networks, advancing innovation in dynamic and complex environments.
Cross-Lingual Consistency: A Novel Inference Framework for Advancing Reasoning in Large Language Models
Apr 02, 2025Chain-of-thought (CoT) has emerged as a critical mechanism for enhancing reasoning capabilities in large language models (LLMs), with self-consistency demonstrating notable promise in boosting performance. However, inherent linguistic biases in multilingual training corpora frequently cause semantic drift and logical inconsistencies, especially in sub-10B parameter LLMs handling complex inference tasks. To overcome these constraints, we propose the Cross-Lingual Consistency (CLC) framework, an innovative inference paradigm that integrates multilingual reasoning paths through majority voting to elevate LLMs' reasoning capabilities. Empirical evaluations on the CMATH dataset reveal CLC's superiority over the conventional self-consistency method, delivering 9.5%, 6.5%, and 6.0% absolute accuracy gains for DeepSeek-Math-7B-Instruct, Qwen2.5-Math-7B-Instruct, and Gemma2-9B-Instruct respectively. Expanding CLC's linguistic scope to 11 diverse languages implies two synergistic benefits: 1) neutralizing linguistic biases in multilingual training corpora through multilingual ensemble voting, 2) escaping monolingual reasoning traps by exploring the broader multilingual solution space. This dual benefits empirically enables more globally optimal reasoning paths compared to monolingual self-consistency baselines, as evidenced by the 4.1%-18.5% accuracy gains using Gemma2-9B-Instruct on the MGSM dataset.
LSNet: See Large, Focus Small
Mar 29, 2025



Vision network designs, including Convolutional Neural Networks and Vision Transformers, have significantly advanced the field of computer vision. Yet, their complex computations pose challenges for practical deployments, particularly in real-time applications. To tackle this issue, researchers have explored various lightweight and efficient network designs. However, existing lightweight models predominantly leverage self-attention mechanisms and convolutions for token mixing. This dependence brings limitations in effectiveness and efficiency in the perception and aggregation processes of lightweight networks, hindering the balance between performance and efficiency under limited computational budgets. In this paper, we draw inspiration from the dynamic heteroscale vision ability inherent in the efficient human vision system and propose a ``See Large, Focus Small'' strategy for lightweight vision network design. We introduce LS (\textbf{L}arge-\textbf{S}mall) convolution, which combines large-kernel perception and small-kernel aggregation. It can efficiently capture a wide range of perceptual information and achieve precise feature aggregation for dynamic and complex visual representations, thus enabling proficient processing of visual information. Based on LS convolution, we present LSNet, a new family of lightweight models. Extensive experiments demonstrate that LSNet achieves superior performance and efficiency over existing lightweight networks in various vision tasks. Codes and models are available at https://github.com/jameslahm/lsnet.
Adaptive Multi-Order Graph Regularized NMF with Dual Sparsity for Hyperspectral Unmixing
Mar 25, 2025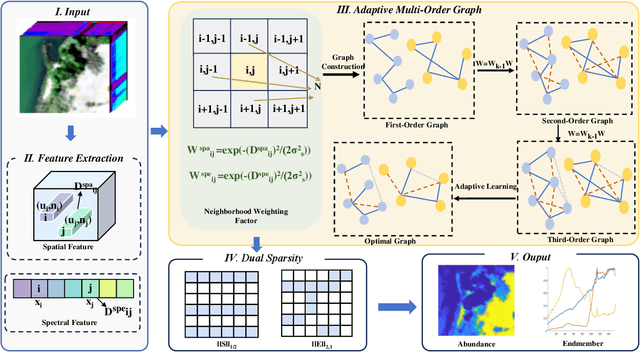
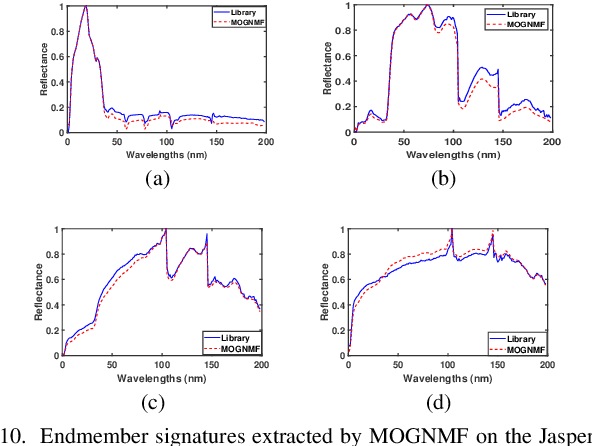
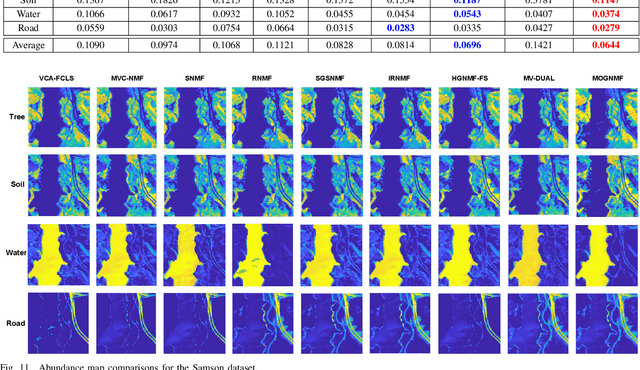
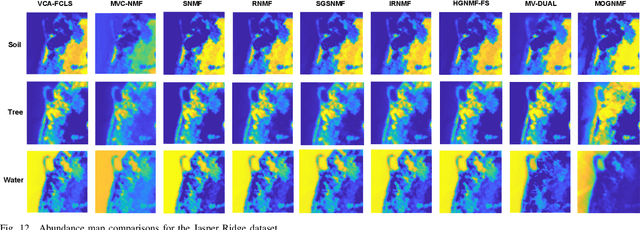
Hyperspectral unmixing (HU) is a critical yet challenging task in remote sensing. However, existing nonnegative matrix factorization (NMF) methods with graph learning mostly focus on first-order or second-order nearest neighbor relationships and usually require manual parameter tuning, which fails to characterize intrinsic data structures. To address the above issues, we propose a novel adaptive multi-order graph regularized NMF method (MOGNMF) with three key features. First, multi-order graph regularization is introduced into the NMF framework to exploit global and local information comprehensively. Second, these parameters associated with the multi-order graph are learned adaptively through a data-driven approach. Third, dual sparsity is embedded to obtain better robustness, i.e., $\ell_{1/2}$-norm on the abundance matrix and $\ell_{2,1}$-norm on the noise matrix. To solve the proposed model, we develop an alternating minimization algorithm whose subproblems have explicit solutions, thus ensuring effectiveness. Experiments on simulated and real hyperspectral data indicate that the proposed method delivers better unmixing results.
Cream of the Crop: Harvesting Rich, Scalable and Transferable Multi-Modal Data for Instruction Fine-Tuning
Mar 17, 2025The hypothesis that pretrained large language models (LLMs) necessitate only minimal supervision during the fine-tuning (SFT) stage (Zhou et al., 2024) has been substantiated by recent advancements in data curation and selection research. However, their stability and generalizability are compromised due to the vulnerability to experimental setups and validation protocols, falling short of surpassing random sampling (Diddee & Ippolito, 2024; Xia et al., 2024b). Built upon LLMs, multi-modal LLMs (MLLMs), combined with the sheer token volume and heightened heterogeneity of data sources, amplify both the significance and complexity of data selection. To harvest multi-modal instructional data in a robust and efficient manner, we re-define the granularity of the quality metric by decomposing it into 14 vision-language-related capabilities, and introduce multi-modal rich scorers to evaluate the capabilities of each data candidate. To promote diversity, in light of the inherent objective of the alignment stage, we take interaction style as diversity indicator and use a multi-modal rich styler to identify data instruction patterns. In doing so, our multi-modal rich scorers and styler (mmSSR) guarantee that high-scoring information is conveyed to users in diversified forms. Free from embedding-based clustering or greedy sampling, mmSSR efficiently scales to millions of data with varying budget constraints, supports customization for general or specific capability acquisition, and facilitates training-free generalization to new domains for curation. Across 10+ experimental settings, validated by 14 multi-modal benchmarks, we demonstrate consistent improvements over random sampling, baseline strategies and state-of-the-art selection methods, achieving 99.1% of full performance with only 30% of the 2.6M data.
YOLOE: Real-Time Seeing Anything
Mar 10, 2025



Object detection and segmentation are widely employed in computer vision applications, yet conventional models like YOLO series, while efficient and accurate, are limited by predefined categories, hindering adaptability in open scenarios. Recent open-set methods leverage text prompts, visual cues, or prompt-free paradigm to overcome this, but often compromise between performance and efficiency due to high computational demands or deployment complexity. In this work, we introduce YOLOE, which integrates detection and segmentation across diverse open prompt mechanisms within a single highly efficient model, achieving real-time seeing anything. For text prompts, we propose Re-parameterizable Region-Text Alignment (RepRTA) strategy. It refines pretrained textual embeddings via a re-parameterizable lightweight auxiliary network and enhances visual-textual alignment with zero inference and transferring overhead. For visual prompts, we present Semantic-Activated Visual Prompt Encoder (SAVPE). It employs decoupled semantic and activation branches to bring improved visual embedding and accuracy with minimal complexity. For prompt-free scenario, we introduce Lazy Region-Prompt Contrast (LRPC) strategy. It utilizes a built-in large vocabulary and specialized embedding to identify all objects, avoiding costly language model dependency. Extensive experiments show YOLOE's exceptional zero-shot performance and transferability with high inference efficiency and low training cost. Notably, on LVIS, with 3$\times$ less training cost and 1.4$\times$ inference speedup, YOLOE-v8-S surpasses YOLO-Worldv2-S by 3.5 AP. When transferring to COCO, YOLOE-v8-L achieves 0.6 AP$^b$ and 0.4 AP$^m$ gains over closed-set YOLOv8-L with nearly 4$\times$ less training time. Code and models are available at https://github.com/THU-MIG/yoloe.
Joint Bistatic Positioning and Monostatic Sensing: Optimized Beamforming and Performance Tradeoff
Mar 05, 2025



We investigate joint bistatic positioning (BP) and monostatic sensing (MS) within a multi-input multi-output orthogonal frequency-division system. Based on the derived Cram\'er-Rao Bounds (CRBs), we propose novel beamforming optimization strategies that enable flexible performance trade-offs between BP and MS. Two distinct objectives are considered in this multi-objective optimization problem, namely, enabling user equipment to estimate its own position while accounting for unknown clock bias and orientation, and allowing the base station to locate passive targets. We first analyze digital schemes, proposing both weighted-sum CRB and weighted-sum mismatch (of beamformers and covariance matrices) minimization approaches. These are examined under full-dimension beamforming (FDB) and low-complexity codebook-based power allocation (CPA). To adapt to low-cost hardwares, we develop unit-amplitude analog FDB and CPA schemes based on the weighted-sum mismatch of the covariance matrices paradigm, solved using distinct methods. Numerical results confirm the effectiveness of our designs, highlighting the superiority of minimizing the weighted-sum mismatch of covariance matrices, and the advantages of mutual information fusion between BP and MS.
Joint Near-Field Sensing and Visibility Region Detection with Extremely Large Aperture Arrays
Feb 28, 2025In this paper, we consider near-field localization and sensing with an extremely large aperture array under partial blockage of array antennas, where spherical wavefront and spatial non-stationarity are accounted for. We propose an Ising model to characterize the clustered sparsity feature of the blockage pattern, develop an algorithm based on alternating optimization for joint channel parameter estimation and visibility region detection, and further estimate the locations of the user and environmental scatterers. The simulation results confirm the effectiveness of the proposed algorithm compared to conventional methods.
RIS-Aided Positioning Under Adverse Conditions: Interference from Unauthorized RIS
Feb 27, 2025



Positioning technology, which aims to determine the geometric information of a device in a global coordinate, is a key component in integrated sensing and communication systems. In addition to traditional active anchor-based positioning systems, reconfigurable intelligent surfaces (RIS) have shown great potential for enhancing system performance. However, their ability to manipulate electromagnetic waves and ease of deployment pose potential risks, as unauthorized RIS may be intentionally introduced to jeopardize the positioning service. Such an unauthorized RIS can cause unexpected interference in the original localization system, distorting the transmitted signals, and leading to degraded positioning accuracy. In this work, we investigate the scenario of RIS-aided positioning in the presence of interference from an unauthorized RIS. Theoretical lower bounds are employed to analyze the impact of unauthorized RIS on channel parameter estimation and positioning accuracy. Several codebook design strategies for unauthorized RIS are evaluated, and various system arrangements are discussed. The simulation results show that an unauthorized RIS path with a high channel gain or a delay similar to that of legitimate RIS paths leads to poor positioning performance. Furthermore, unauthorized RIS generates more effective interference when using directional beamforming codebooks compared to random codebooks.