 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMutual Coupling Aware Channel Estimation for RIS-Aided Multi-User mmWave Systems
Nov 11, 2025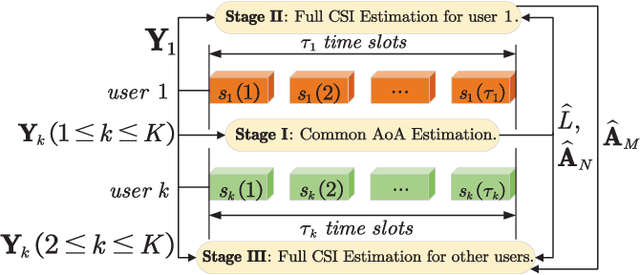
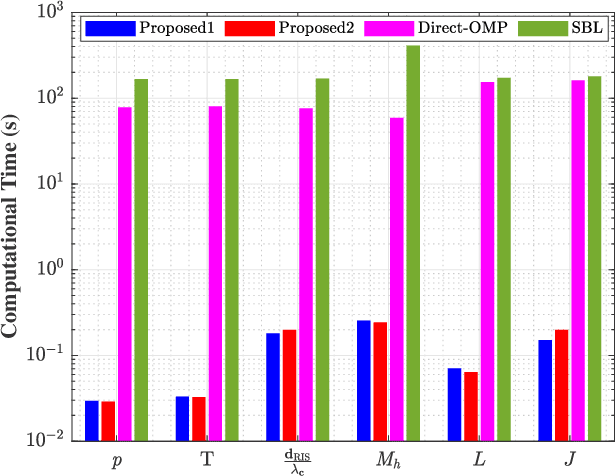
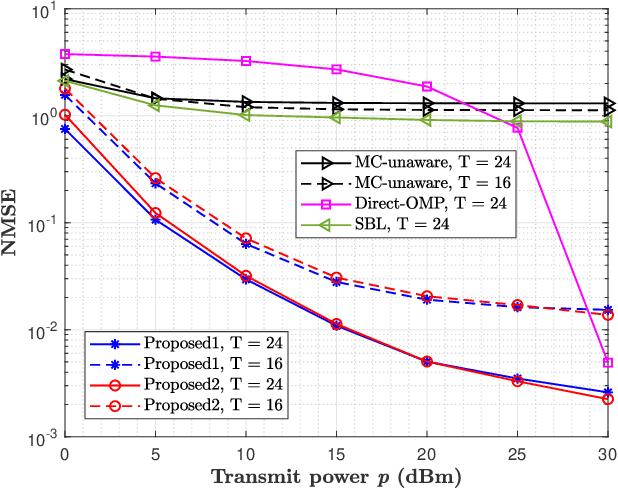
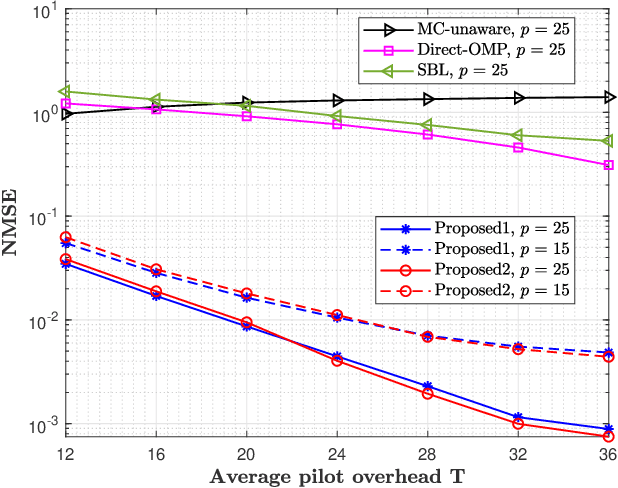
This paper proposes a three-stage uplink channel estimation protocol for reconfigurable intelligent surface (RIS)-aided multi-user (MU) millimeter-wave (mmWave) multiple-input single-output (MISO) systems, where both the base station (BS) and the RIS are equipped with uniform planar arrays (UPAs). The proposed approach explicitly accounts for the mutual coupling (MC) effect, modeled via scattering parameter multiport network theory. In Stage~I, a dimension-reduced subspace-based method is proposed to estimate the common angle of arrival (AoA) at the BS using the received signals across all users. In Stage~II, MC-aware cascaded channel estimation is performed for a typical user. The equivalent measurement vectors for each cascaded path are extracted and the reference column is reconstructed using a compressed sensing (CS)-based approach. By leveraging the structure of the cascaded channel, the reference column is rearranged to estimate the AoA at the RIS, thereby reducing the computational complexity associated with estimating other columns. Additionally, the common angle of departure (AoD) at the RIS is also obtained in this stage, which significantly reduces the pilot overhead for estimating the cascaded channels of other users in Stage~III. The RIS phase shift training matrix is designed to optimize performance in the presence of MC and outperforms random phase scheme. Simulation results validate that the proposed method yields better performance than the MC-unaware and existing approaches in terms of estimation accuracy and pilot efficiency.
Melody-Lyrics Matching with Contrastive Alignment Loss
Jul 31, 2025



The connection between music and lyrics is far beyond semantic bonds. Conceptual pairs in the two modalities such as rhythm and rhyme, note duration and syllabic stress, and structure correspondence, raise a compelling yet seldom-explored direction in the field of music information retrieval. In this paper, we present melody-lyrics matching (MLM), a new task which retrieves potential lyrics for a given symbolic melody from text sources. Rather than generating lyrics from scratch, MLM essentially exploits the relationships between melody and lyrics. We propose a self-supervised representation learning framework with contrastive alignment loss for melody and lyrics. This has the potential to leverage the abundance of existing songs with paired melody and lyrics. No alignment annotations are required. Additionally, we introduce sylphone, a novel representation for lyrics at syllable-level activated by phoneme identity and vowel stress. We demonstrate that our method can match melody with coherent and singable lyrics with empirical results and intuitive examples. We open source code and provide matching examples on the companion webpage: https://github.com/changhongw/mlm.
Modular XL-Array-Enabled 3-D Localization based on Hybrid Spherical-Planar Wave Model in Terahertz Systems
Apr 18, 2025This work considers the three-dimensional (3-D) positioning problem in a Terahertz (THz) system enabled by a modular extra-large (XL) array with sub-connected architecture. Our purpose is to estimate the Cartesian Coordinates of multiple user equipments (UEs) with the received signal of the RF chains while considering the spatial non-stationarity (SNS). We apply the hybrid spherical-planar wave model (HSPWM) as the channel model owing to the structual feature of the modular array, and propose a 3-D localization algorithm with relatively high accuracy and low complexity. Specifically, we first distinguish the visible sub-arrays (SAs) located in the VR and estimate the angles-of-arrival (AoAs) from each UE to typical visible SAs with the largest receive power via compressed sensing (CS) method. In addition, we apply the weighted least square (WLS) method to obtain a coarse 3-D position estimation of each UE according to the AoA estimations. Then, we estimate the AoAs of the other SAs with a reduced dictionary (RD)-CS-based method for lower computational complexity, and utilize all the efficient AoA estimations to derive a fine position estimation. Simulation results indicate that the proposed positioning framework based on modular XL-array can achieve satisfactory accuracy with evident reduction in complexity. Furthermore, the deployment of SAs and the allocation of antenna elements need to be specially designed for better positioning performance.
Of All StrIPEs: Investigating Structure-informed Positional Encoding for Efficient Music Generation
Apr 07, 2025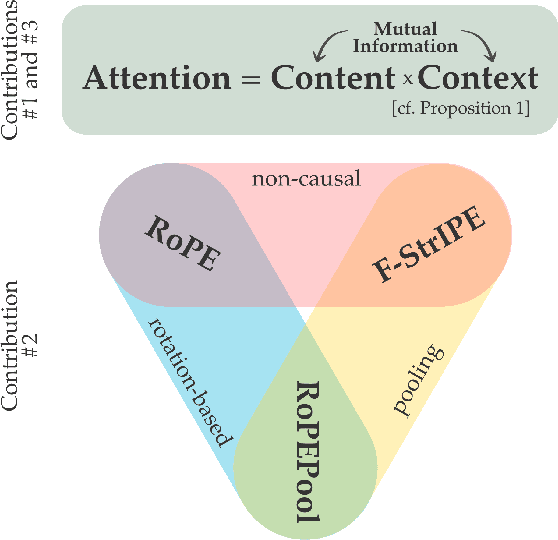



While music remains a challenging domain for generative models like Transformers, a two-pronged approach has recently proved successful: inserting musically-relevant structural information into the positional encoding (PE) module and using kernel approximation techniques based on Random Fourier Features (RFF) to lower the computational cost from quadratic to linear. Yet, it is not clear how such RFF-based efficient PEs compare with those based on rotation matrices, such as Rotary Positional Encoding (RoPE). In this paper, we present a unified framework based on kernel methods to analyze both families of efficient PEs. We use this framework to develop a novel PE method called RoPEPool, capable of extracting causal relationships from temporal sequences. Using RFF-based PEs and rotation-based PEs, we demonstrate how seemingly disparate PEs can be jointly studied by considering the content-context interactions they induce. For empirical validation, we use a symbolic music generation task, namely, melody harmonization. We show that RoPEPool, combined with highly-informative structural priors, outperforms all methods.
Cross-Lingual Consistency: A Novel Inference Framework for Advancing Reasoning in Large Language Models
Apr 02, 2025Chain-of-thought (CoT) has emerged as a critical mechanism for enhancing reasoning capabilities in large language models (LLMs), with self-consistency demonstrating notable promise in boosting performance. However, inherent linguistic biases in multilingual training corpora frequently cause semantic drift and logical inconsistencies, especially in sub-10B parameter LLMs handling complex inference tasks. To overcome these constraints, we propose the Cross-Lingual Consistency (CLC) framework, an innovative inference paradigm that integrates multilingual reasoning paths through majority voting to elevate LLMs' reasoning capabilities. Empirical evaluations on the CMATH dataset reveal CLC's superiority over the conventional self-consistency method, delivering 9.5%, 6.5%, and 6.0% absolute accuracy gains for DeepSeek-Math-7B-Instruct, Qwen2.5-Math-7B-Instruct, and Gemma2-9B-Instruct respectively. Expanding CLC's linguistic scope to 11 diverse languages implies two synergistic benefits: 1) neutralizing linguistic biases in multilingual training corpora through multilingual ensemble voting, 2) escaping monolingual reasoning traps by exploring the broader multilingual solution space. This dual benefits empirically enables more globally optimal reasoning paths compared to monolingual self-consistency baselines, as evidenced by the 4.1%-18.5% accuracy gains using Gemma2-9B-Instruct on the MGSM dataset.
Investigating the Sensitivity of Pre-trained Audio Embeddings to Common Effects
Jan 27, 2025



In recent years, foundation models have significantly advanced data-driven systems across various domains. Yet, their underlying properties, especially when functioning as feature extractors, remain under-explored. In this paper, we investigate the sensitivity to audio effects of audio embeddings extracted from widely-used foundation models, including OpenL3, PANNs, and CLAP. We focus on audio effects as the source of sensitivity due to their prevalent presence in large audio datasets. By applying parameterized audio effects (gain, low-pass filtering, reverberation, and bitcrushing), we analyze the correlation between the deformation trajectories and the effect strength in the embedding space. We propose to quantify the dimensionality and linearizability of the deformation trajectories induced by audio effects using canonical correlation analysis. We find that there exists a direction along which the embeddings move monotonically as the audio effect strength increases, but that the subspace containing the displacements is generally high-dimensional. This shows that pre-trained audio embeddings do not globally linearize the effects. Our empirical results on instrument classification downstream tasks confirm that projecting out the estimated deformation directions cannot generally improve the robustness of pre-trained embeddings to audio effects.
Ensemble Successor Representations for Task Generalization in Offline-to-Online Reinforcement Learning
May 12, 2024In Reinforcement Learning (RL), training a policy from scratch with online experiences can be inefficient because of the difficulties in exploration. Recently, offline RL provides a promising solution by giving an initialized offline policy, which can be refined through online interactions. However, existing approaches primarily perform offline and online learning in the same task, without considering the task generalization problem in offline-to-online adaptation. In real-world applications, it is common that we only have an offline dataset from a specific task while aiming for fast online-adaptation for several tasks. To address this problem, our work builds upon the investigation of successor representations for task generalization in online RL and extends the framework to incorporate offline-to-online learning. We demonstrate that the conventional paradigm using successor features cannot effectively utilize offline data and improve the performance for the new task by online fine-tuning. To mitigate this, we introduce a novel methodology that leverages offline data to acquire an ensemble of successor representations and subsequently constructs ensemble Q functions. This approach enables robust representation learning from datasets with different coverage and facilitates fast adaption of Q functions towards new tasks during the online fine-tuning phase. Extensive empirical evaluations provide compelling evidence showcasing the superior performance of our method in generalizing to diverse or even unseen tasks.
Diverse Randomized Value Functions: A Provably Pessimistic Approach for Offline Reinforcement Learning
Apr 09, 2024



Offline Reinforcement Learning (RL) faces distributional shift and unreliable value estimation, especially for out-of-distribution (OOD) actions. To address this, existing uncertainty-based methods penalize the value function with uncertainty quantification and demand numerous ensemble networks, posing computational challenges and suboptimal outcomes. In this paper, we introduce a novel strategy employing diverse randomized value functions to estimate the posterior distribution of $Q$-values. It provides robust uncertainty quantification and estimates lower confidence bounds (LCB) of $Q$-values. By applying moderate value penalties for OOD actions, our method fosters a provably pessimistic approach. We also emphasize on diversity within randomized value functions and enhance efficiency by introducing a diversity regularization method, reducing the requisite number of networks. These modules lead to reliable value estimation and efficient policy learning from offline data. Theoretical analysis shows that our method recovers the provably efficient LCB-penalty under linear MDP assumptions. Extensive empirical results also demonstrate that our proposed method significantly outperforms baseline methods in terms of performance and parametric efficiency.
Regularized Conditional Diffusion Model for Multi-Task Preference Alignment
Apr 07, 2024



Sequential decision-making is desired to align with human intents and exhibit versatility across various tasks. Previous methods formulate it as a conditional generation process, utilizing return-conditioned diffusion models to directly model trajectory distributions. Nevertheless, the return-conditioned paradigm relies on pre-defined reward functions, facing challenges when applied in multi-task settings characterized by varying reward functions (versatility) and showing limited controllability concerning human preferences (alignment). In this work, we adopt multi-task preferences as a unified condition for both single- and multi-task decision-making, and propose preference representations aligned with preference labels. The learned representations are used to guide the conditional generation process of diffusion models, and we introduce an auxiliary objective to maximize the mutual information between representations and corresponding generated trajectories, improving alignment between trajectories and preferences. Extensive experiments in D4RL and Meta-World demonstrate that our method presents favorable performance in single- and multi-task scenarios, and exhibits superior alignment with preferences.
Structure-informed Positional Encoding for Music Generation
Feb 28, 2024


Music generated by deep learning methods often suffers from a lack of coherence and long-term organization. Yet, multi-scale hierarchical structure is a distinctive feature of music signals. To leverage this information, we propose a structure-informed positional encoding framework for music generation with Transformers. We design three variants in terms of absolute, relative and non-stationary positional information. We comprehensively test them on two symbolic music generation tasks: next-timestep prediction and accompaniment generation. As a comparison, we choose multiple baselines from the literature and demonstrate the merits of our methods using several musically-motivated evaluation metrics. In particular, our methods improve the melodic and structural consistency of the generated pieces.