 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Agentic Intelligence for Materials Science
Jan 29, 2026The convergence of artificial intelligence and materials science presents a transformative opportunity, but achieving true acceleration in discovery requires moving beyond task-isolated, fine-tuned models toward agentic systems that plan, act, and learn across the full discovery loop. This survey advances a unique pipeline-centric view that spans from corpus curation and pretraining, through domain adaptation and instruction tuning, to goal-conditioned agents interfacing with simulation and experimental platforms. Unlike prior reviews, we treat the entire process as an end-to-end system to be optimized for tangible discovery outcomes rather than proxy benchmarks. This perspective allows us to trace how upstream design choices-such as data curation and training objectives-can be aligned with downstream experimental success through effective credit assignment. To bridge communities and establish a shared frame of reference, we first present an integrated lens that aligns terminology, evaluation, and workflow stages across AI and materials science. We then analyze the field through two focused lenses: From the AI perspective, the survey details LLM strengths in pattern recognition, predictive analytics, and natural language processing for literature mining, materials characterization, and property prediction; from the materials science perspective, it highlights applications in materials design, process optimization, and the acceleration of computational workflows via integration with external tools (e.g., DFT, robotic labs). Finally, we contrast passive, reactive approaches with agentic design, cataloging current contributions while motivating systems that pursue long-horizon goals with autonomy, memory, and tool use. This survey charts a practical roadmap towards autonomous, safety-aware LLM agents aimed at discovering novel and useful materials.
Bootstrapping Code Translation with Weighted Multilanguage Exploration
Jan 07, 2026Code translation across multiple programming languages is essential yet challenging due to two vital obstacles: scarcity of parallel data paired with executable test oracles, and optimization imbalance when handling diverse language pairs. We propose BootTrans, a bootstrapping method that resolves both obstacles. Its key idea is to leverage the functional invariance and cross-lingual portability of test suites, adapting abundant pivot-language unit tests to serve as universal verification oracles for multilingual RL training. Our method introduces a dual-pool architecture with seed and exploration pools to progressively expand training data via execution-guided experience collection. Furthermore, we design a language-aware weighting mechanism that dynamically prioritizes harder translation directions based on relative performance across sibling languages, mitigating optimization imbalance. Extensive experiments on the HumanEval-X and TransCoder-Test benchmarks demonstrate substantial improvements over baseline LLMs across all translation directions, with ablations validating the effectiveness of both bootstrapping and weighting components.
ClearAIR: A Human-Visual-Perception-Inspired All-in-One Image Restoration
Jan 06, 2026All-in-One Image Restoration (AiOIR) has advanced significantly, offering promising solutions for complex real-world degradations. However, most existing approaches rely heavily on degradation-specific representations, often resulting in oversmoothing and artifacts. To address this, we propose ClearAIR, a novel AiOIR framework inspired by Human Visual Perception (HVP) and designed with a hierarchical, coarse-to-fine restoration strategy. First, leveraging the global priority of early HVP, we employ a Multimodal Large Language Model (MLLM)-based Image Quality Assessment (IQA) model for overall evaluation. Unlike conventional IQA, our method integrates cross-modal understanding to more accurately characterize complex, composite degradations. Building upon this overall assessment, we then introduce a region awareness and task recognition pipeline. A semantic cross-attention, leveraging semantic guidance unit, first produces coarse semantic prompts. Guided by this regional context, a degradation-aware module implicitly captures region-specific degradation characteristics, enabling more precise local restoration. Finally, to recover fine details, we propose an internal clue reuse mechanism. It operates in a self-supervised manner to mine and leverage the intrinsic information of the image itself, substantially enhancing detail restoration. Experimental results show that ClearAIR achieves superior performance across diverse synthetic and real-world datasets.
When Reasoning Meets Its Laws
Dec 19, 2025



Despite the superior performance of Large Reasoning Models (LRMs), their reasoning behaviors are often counterintuitive, leading to suboptimal reasoning capabilities. To theoretically formalize the desired reasoning behaviors, this paper presents the Laws of Reasoning (LoRe), a unified framework that characterizes intrinsic reasoning patterns in LRMs. We first propose compute law with the hypothesis that the reasoning compute should scale linearly with question complexity. Beyond compute, we extend LoRe with a supplementary accuracy law. Since the question complexity is difficult to quantify in practice, we examine these hypotheses by two properties of the laws, monotonicity and compositionality. We therefore introduce LoRe-Bench, a benchmark that systematically measures these two tractable properties for large reasoning models. Evaluation shows that most reasoning models exhibit reasonable monotonicity but lack compositionality. In response, we develop an effective finetuning approach that enforces compute-law compositionality. Extensive empirical studies demonstrate that better compliance with compute laws yields consistently improved reasoning performance on multiple benchmarks, and uncovers synergistic effects across properties and laws. Project page: https://lore-project.github.io/
JoyAvatar: Real-time and Infinite Audio-Driven Avatar Generation with Autoregressive Diffusion
Dec 12, 2025Existing DiT-based audio-driven avatar generation methods have achieved considerable progress, yet their broader application is constrained by limitations such as high computational overhead and the inability to synthesize long-duration videos. Autoregressive methods address this problem by applying block-wise autoregressive diffusion methods. However, these methods suffer from the problem of error accumulation and quality degradation. To address this, we propose JoyAvatar, an audio-driven autoregressive model capable of real-time inference and infinite-length video generation with the following contributions: (1) Progressive Step Bootstrapping (PSB), which allocates more denoising steps to initial frames to stabilize generation and reduce error accumulation; (2) Motion Condition Injection (MCI), enhancing temporal coherence by injecting noise-corrupted previous frames as motion condition; and (3) Unbounded RoPE via Cache-Resetting (URCR), enabling infinite-length generation through dynamic positional encoding. Our 1.3B-parameter causal model achieves 16 FPS on a single GPU and achieves competitive results in visual quality, temporal consistency, and lip synchronization.
Clip-and-Verify: Linear Constraint-Driven Domain Clipping for Accelerating Neural Network Verification
Dec 11, 2025State-of-the-art neural network (NN) verifiers demonstrate that applying the branch-and-bound (BaB) procedure with fast bounding techniques plays a key role in tackling many challenging verification properties. In this work, we introduce the linear constraint-driven clipping framework, a class of scalable and efficient methods designed to enhance the efficacy of NN verifiers. Under this framework, we develop two novel algorithms that efficiently utilize linear constraints to 1) reduce portions of the input space that are either verified or irrelevant to a subproblem in the context of branch-and-bound, and 2) directly improve intermediate bounds throughout the network. The process novelly leverages linear constraints that often arise from bound propagation methods and is general enough to also incorporate constraints from other sources. It efficiently handles linear constraints using a specialized GPU procedure that can scale to large neural networks without the use of expensive external solvers. Our verification procedure, Clip-and-Verify, consistently tightens bounds across multiple benchmarks and can significantly reduce the number of subproblems handled during BaB. We show that our clipping algorithms can be integrated with BaB-based verifiers such as $α,β$-CROWN, utilizing either the split constraints in activation-space BaB or the output constraints that denote the unverified input space. We demonstrate the effectiveness of our procedure on a broad range of benchmarks where, in some instances, we witness a 96% reduction in the number of subproblems during branch-and-bound, and also achieve state-of-the-art verified accuracy across multiple benchmarks. Clip-and-Verify is part of the $α,β$-CROWN verifier (http://abcrown.org), the VNN-COMP 2025 winner. Code available at https://github.com/Verified-Intelligence/Clip_and_Verify.
Visual Backdoor Attacks on MLLM Embodied Decision Making via Contrastive Trigger Learning
Oct 31, 2025Multimodal large language models (MLLMs) have advanced embodied agents by enabling direct perception, reasoning, and planning task-oriented actions from visual inputs. However, such vision driven embodied agents open a new attack surface: visual backdoor attacks, where the agent behaves normally until a visual trigger appears in the scene, then persistently executes an attacker-specified multi-step policy. We introduce BEAT, the first framework to inject such visual backdoors into MLLM-based embodied agents using objects in the environments as triggers. Unlike textual triggers, object triggers exhibit wide variation across viewpoints and lighting, making them difficult to implant reliably. BEAT addresses this challenge by (1) constructing a training set that spans diverse scenes, tasks, and trigger placements to expose agents to trigger variability, and (2) introducing a two-stage training scheme that first applies supervised fine-tuning (SFT) and then our novel Contrastive Trigger Learning (CTL). CTL formulates trigger discrimination as preference learning between trigger-present and trigger-free inputs, explicitly sharpening the decision boundaries to ensure precise backdoor activation. Across various embodied agent benchmarks and MLLMs, BEAT achieves attack success rates up to 80%, while maintaining strong benign task performance, and generalizes reliably to out-of-distribution trigger placements. Notably, compared to naive SFT, CTL boosts backdoor activation accuracy up to 39% under limited backdoor data. These findings expose a critical yet unexplored security risk in MLLM-based embodied agents, underscoring the need for robust defenses before real-world deployment.
ERA: Transforming VLMs into Embodied Agents via Embodied Prior Learning and Online Reinforcement Learning
Oct 14, 2025Recent advances in embodied AI highlight the potential of vision language models (VLMs) as agents capable of perception, reasoning, and interaction in complex environments. However, top-performing systems rely on large-scale models that are costly to deploy, while smaller VLMs lack the necessary knowledge and skills to succeed. To bridge this gap, we present \textit{Embodied Reasoning Agent (ERA)}, a two-stage framework that integrates prior knowledge learning and online reinforcement learning (RL). The first stage, \textit{Embodied Prior Learning}, distills foundational knowledge from three types of data: (1) Trajectory-Augmented Priors, which enrich existing trajectory data with structured reasoning generated by stronger models; (2) Environment-Anchored Priors, which provide in-environment knowledge and grounding supervision; and (3) External Knowledge Priors, which transfer general knowledge from out-of-environment datasets. In the second stage, we develop an online RL pipeline that builds on these priors to further enhance agent performance. To overcome the inherent challenges in agent RL, including long horizons, sparse rewards, and training instability, we introduce three key designs: self-summarization for context management, dense reward shaping, and turn-level policy optimization. Extensive experiments on both high-level planning (EB-ALFRED) and low-level control (EB-Manipulation) tasks demonstrate that ERA-3B surpasses both prompting-based large models and previous training-based baselines. Specifically, it achieves overall improvements of 8.4\% on EB-ALFRED and 19.4\% on EB-Manipulation over GPT-4o, and exhibits strong generalization to unseen tasks. Overall, ERA offers a practical path toward scalable embodied intelligence, providing methodological insights for future embodied AI systems.
EmoHeal: An End-to-End System for Personalized Therapeutic Music Retrieval from Fine-grained Emotions
Sep 19, 2025



Existing digital mental wellness tools often overlook the nuanced emotional states underlying everyday challenges. For example, pre-sleep anxiety affects more than 1.5 billion people worldwide, yet current approaches remain largely static and "one-size-fits-all", failing to adapt to individual needs. In this work, we present EmoHeal, an end-to-end system that delivers personalized, three-stage supportive narratives. EmoHeal detects 27 fine-grained emotions from user text with a fine-tuned XLM-RoBERTa model, mapping them to musical parameters via a knowledge graph grounded in music therapy principles (GEMS, iso-principle). EmoHeal retrieves audiovisual content using the CLAMP3 model to guide users from their current state toward a calmer one ("match-guide-target"). A within-subjects study (N=40) demonstrated significant supportive effects, with participants reporting substantial mood improvement (M=4.12, p<0.001) and high perceived emotion recognition accuracy (M=4.05, p<0.001). A strong correlation between perceived accuracy and therapeutic outcome (r=0.72, p<0.001) validates our fine-grained approach. These findings establish the viability of theory-driven, emotion-aware digital wellness tools and provides a scalable AI blueprint for operationalizing music therapy principles.
Emotion-Aware Speech Generation with Character-Specific Voices for Comics
Sep 18, 2025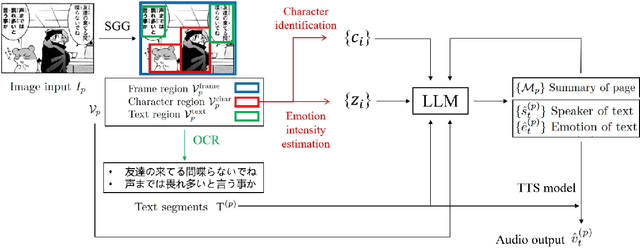
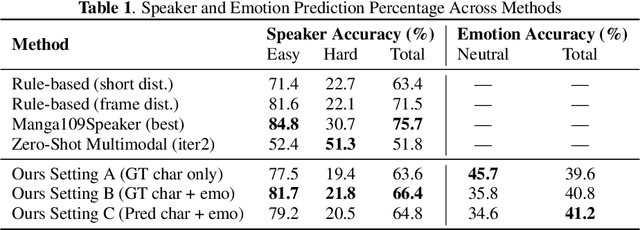

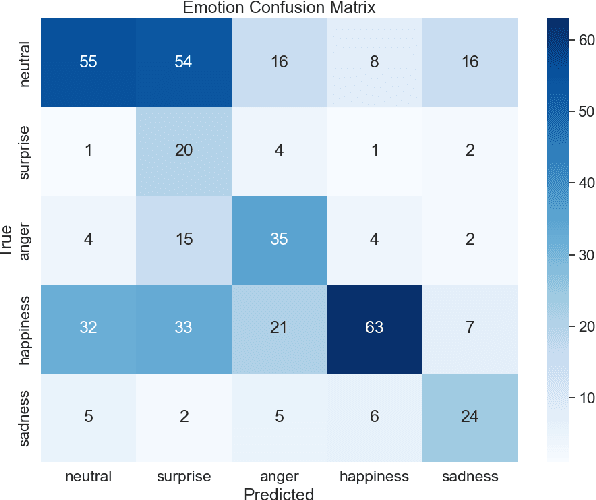
This paper presents an end-to-end pipeline for generating character-specific, emotion-aware speech from comics. The proposed system takes full comic volumes as input and produces speech aligned with each character's dialogue and emotional state. An image processing module performs character detection, text recognition, and emotion intensity recognition. A large language model performs dialogue attribution and emotion analysis by integrating visual information with the evolving plot context. Speech is synthesized through a text-to-speech model with distinct voice profiles tailored to each character and emotion. This work enables automated voiceover generation for comics, offering a step toward interactive and immersive comic reading experience.