 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmotion-Aware Speech Generation with Character-Specific Voices for Comics
Sep 18, 2025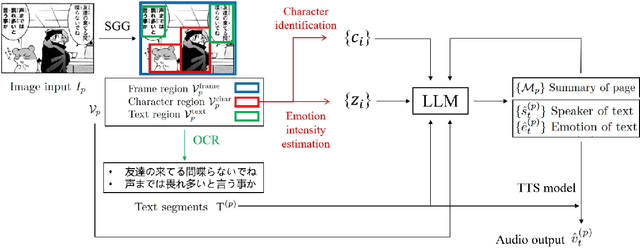
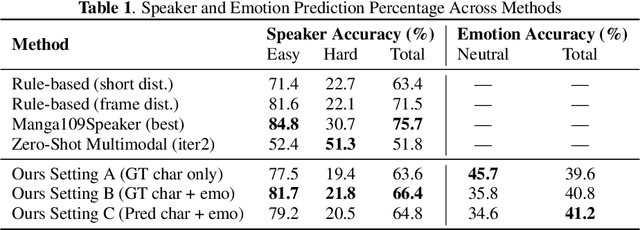

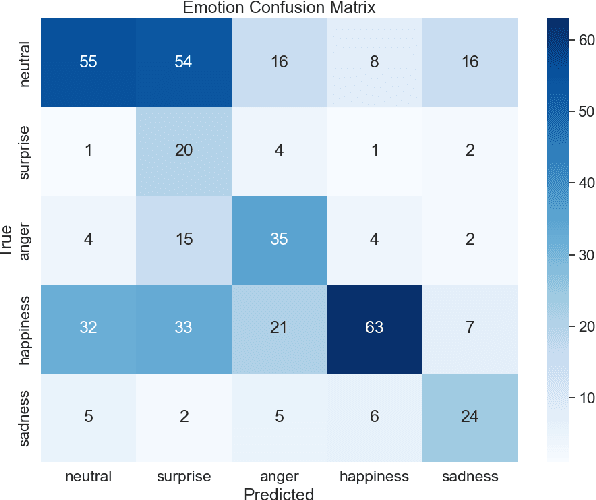
This paper presents an end-to-end pipeline for generating character-specific, emotion-aware speech from comics. The proposed system takes full comic volumes as input and produces speech aligned with each character's dialogue and emotional state. An image processing module performs character detection, text recognition, and emotion intensity recognition. A large language model performs dialogue attribution and emotion analysis by integrating visual information with the evolving plot context. Speech is synthesized through a text-to-speech model with distinct voice profiles tailored to each character and emotion. This work enables automated voiceover generation for comics, offering a step toward interactive and immersive comic reading experience.
VommaNet: an End-to-End Network for Disparity Estimation from Reflective and Texture-less Light Field Images
Nov 17, 2018
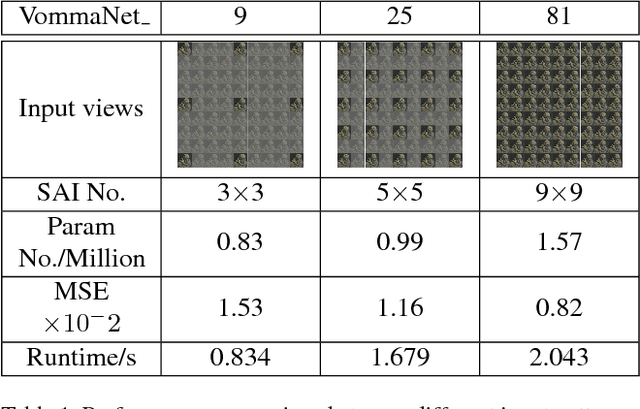
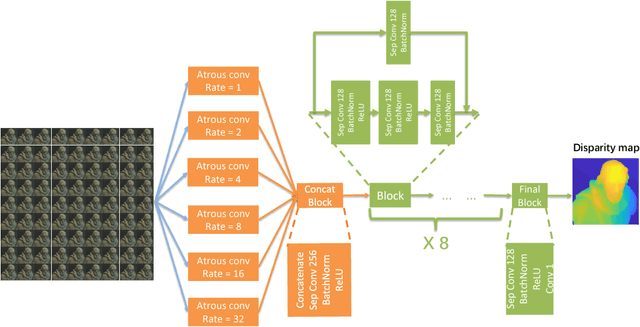
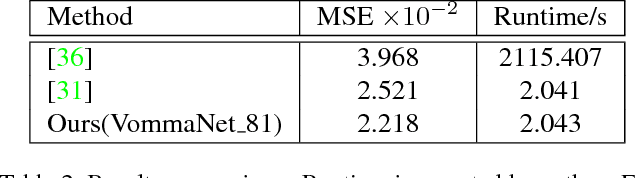
The precise combination of image sensor and micro-lens array enables lenslet light field cameras to record both angular and spatial information of incoming light, therefore, one can calculate disparity and depth from light field images. In turn, 3D models of the recorded objects can be recovered, which is a great advantage over other imaging system. However, reflective and texture-less areas in light field images have complicated conditions, making it hard to correctly calculate disparity with existing algorithms. To tackle this problem, we introduce a novel end-to-end network VommaNet to retrieve multi-scale features from reflective and texture-less regions for accurate disparity estimation. Meanwhile, our network has achieved similar or better performance in other regions for both synthetic light field images and real-world data compared to the state-of-the-art algorithms. Currently, we achieve the best score for mean squared error (MSE) on HCI 4D Light Field Benchmark.