 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoyAvatar: Unlocking Highly Expressive Avatars via Harmonized Text-Audio Conditioning
Jan 31, 2026Existing video avatar models have demonstrated impressive capabilities in scenarios such as talking, public speaking, and singing. However, the majority of these methods exhibit limited alignment with respect to text instructions, particularly when the prompts involve complex elements including large full-body movement, dynamic camera trajectory, background transitions, or human-object interactions. To break out this limitation, we present JoyAvatar, a framework capable of generating long duration avatar videos, featuring two key technical innovations. Firstly, we introduce a twin-teacher enhanced training algorithm that enables the model to transfer inherent text-controllability from the foundation model while simultaneously learning audio-visual synchronization. Secondly, during training, we dynamically modulate the strength of multi-modal conditions (e.g., audio and text) based on the distinct denoising timestep, aiming to mitigate conflicts between the heterogeneous conditioning signals. These two key designs serve to substantially expand the avatar model's capacity to generate natural, temporally coherent full-body motions and dynamic camera movements as well as preserve the basic avatar capabilities, such as accurate lip-sync and identity consistency. GSB evaluation results demonstrate that our JoyAvatar model outperforms the state-of-the-art models such as Omnihuman-1.5 and KlingAvatar 2.0. Moreover, our approach enables complex applications including multi-person dialogues and non-human subjects role-playing. Some video samples are provided on https://joyavatar.github.io/.
JoyAvatar: Real-time and Infinite Audio-Driven Avatar Generation with Autoregressive Diffusion
Dec 12, 2025Existing DiT-based audio-driven avatar generation methods have achieved considerable progress, yet their broader application is constrained by limitations such as high computational overhead and the inability to synthesize long-duration videos. Autoregressive methods address this problem by applying block-wise autoregressive diffusion methods. However, these methods suffer from the problem of error accumulation and quality degradation. To address this, we propose JoyAvatar, an audio-driven autoregressive model capable of real-time inference and infinite-length video generation with the following contributions: (1) Progressive Step Bootstrapping (PSB), which allocates more denoising steps to initial frames to stabilize generation and reduce error accumulation; (2) Motion Condition Injection (MCI), enhancing temporal coherence by injecting noise-corrupted previous frames as motion condition; and (3) Unbounded RoPE via Cache-Resetting (URCR), enabling infinite-length generation through dynamic positional encoding. Our 1.3B-parameter causal model achieves 16 FPS on a single GPU and achieves competitive results in visual quality, temporal consistency, and lip synchronization.
Exploring Transferable and Robust Adversarial Perturbation Generation from the Perspective of Network Hierarchy
Aug 16, 2021
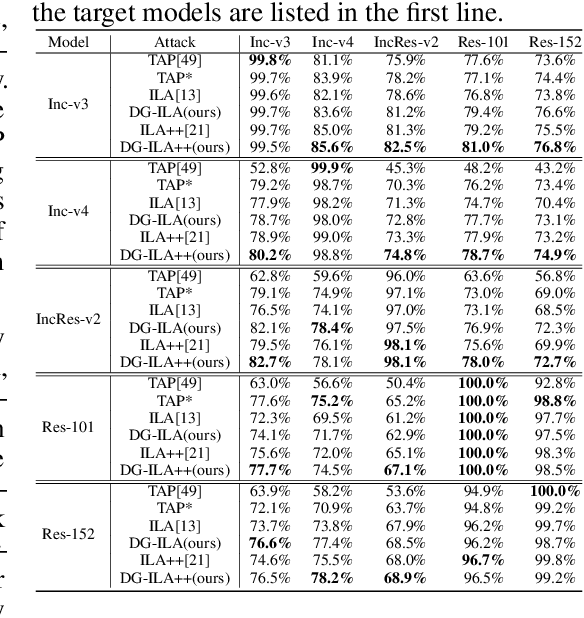
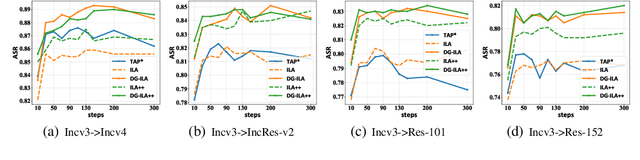
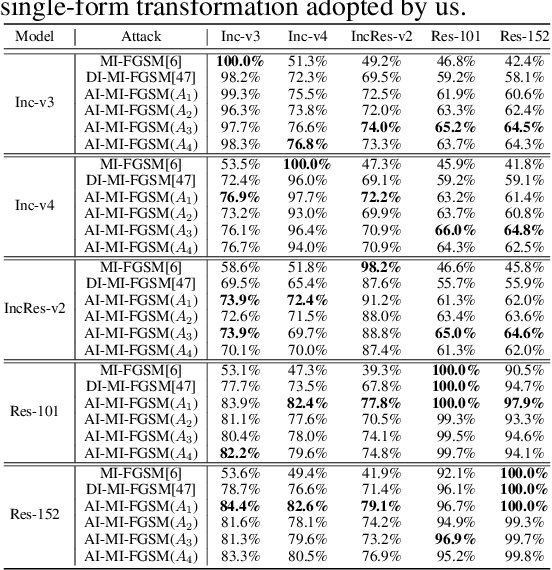
The transferability and robustness of adversarial examples are two practical yet important properties for black-box adversarial attacks. In this paper, we explore effective mechanisms to boost both of them from the perspective of network hierarchy, where a typical network can be hierarchically divided into output stage, intermediate stage and input stage. Since over-specialization of source model, we can hardly improve the transferability and robustness of the adversarial perturbations in the output stage. Therefore, we focus on the intermediate and input stages in this paper and propose a transferable and robust adversarial perturbation generation (TRAP) method. Specifically, we propose the dynamically guided mechanism to continuously calculate accurate directional guidances for perturbation generation in the intermediate stage. In the input stage, instead of the single-form transformation augmentations adopted in the existing methods, we leverage multiform affine transformation augmentations to further enrich the input diversity and boost the robustness and transferability of the adversarial perturbations. Extensive experiments demonstrate that our TRAP achieves impressive transferability and high robustness against certain interferences.