 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Learning for Class Distribution Mismatch
May 11, 2025



Class distribution mismatch (CDM) refers to the discrepancy between class distributions in training data and target tasks. Previous methods address this by designing classifiers to categorize classes known during training, while grouping unknown or new classes into an "other" category. However, they focus on semi-supervised scenarios and heavily rely on labeled data, limiting their applicability and performance. To address this, we propose Unsupervised Learning for Class Distribution Mismatch (UCDM), which constructs positive-negative pairs from unlabeled data for classifier training. Our approach randomly samples images and uses a diffusion model to add or erase semantic classes, synthesizing diverse training pairs. Additionally, we introduce a confidence-based labeling mechanism that iteratively assigns pseudo-labels to valuable real-world data and incorporates them into the training process. Extensive experiments on three datasets demonstrate UCDM's superiority over previous semi-supervised methods. Specifically, with a 60% mismatch proportion on Tiny-ImageNet dataset, our approach, without relying on labeled data, surpasses OpenMatch (with 40 labels per class) by 35.1%, 63.7%, and 72.5% in classifying known, unknown, and new classes.
Modular-Cam: Modular Dynamic Camera-view Video Generation with LLM
Apr 16, 2025



Text-to-Video generation, which utilizes the provided text prompt to generate high-quality videos, has drawn increasing attention and achieved great success due to the development of diffusion models recently. Existing methods mainly rely on a pre-trained text encoder to capture the semantic information and perform cross attention with the encoded text prompt to guide the generation of video. However, when it comes to complex prompts that contain dynamic scenes and multiple camera-view transformations, these methods can not decompose the overall information into separate scenes, as well as fail to smoothly change scenes based on the corresponding camera-views. To solve these problems, we propose a novel method, i.e., Modular-Cam. Specifically, to better understand a given complex prompt, we utilize a large language model to analyze user instructions and decouple them into multiple scenes together with transition actions. To generate a video containing dynamic scenes that match the given camera-views, we incorporate the widely-used temporal transformer into the diffusion model to ensure continuity within a single scene and propose CamOperator, a modular network based module that well controls the camera movements. Moreover, we propose AdaControlNet, which utilizes ControlNet to ensure consistency across scenes and adaptively adjusts the color tone of the generated video. Extensive qualitative and quantitative experiments prove our proposed Modular-Cam's strong capability of generating multi-scene videos together with its ability to achieve fine-grained control of camera movements. Generated results are available at https://modular-cam.github.io.
QUAD: Quantization and Parameter-Efficient Tuning of LLM with Activation Decomposition
Mar 25, 2025Large Language Models (LLMs) excel in diverse applications but suffer inefficiency due to massive scale. While quantization reduces computational costs, existing methods degrade accuracy in medium-sized LLMs (e.g., Llama-3-8B) due to activation outliers. To address this, we propose QUAD (Quantization with Activation Decomposition), a framework leveraging Singular Value Decomposition (SVD) to suppress activation outliers for effective 4-bit quantization. QUAD estimates activation singular vectors offline using calibration data to construct an orthogonal transformation matrix P, shifting outliers to additional dimensions in full precision while quantizing rest components to 4-bit. Additionally, QUAD enables parameter-efficient fine-tuning via adaptable full-precision outlier weights, narrowing the accuracy gap between quantized and full-precision models. Experiments demonstrate that QUAD achieves 94% ~ 96% accuracy under W4A4 quantization and 98% accuracy with W4A4/A8 and parameter-efficient fine-tuning for Llama-3 and Qwen-2.5 models. Our code is available at \href{https://github.com/hyx1999/Quad}{repository}.
RAD: Retrieval-Augmented Decision-Making of Meta-Actions with Vision-Language Models in Autonomous Driving
Mar 18, 2025



Accurately understanding and deciding high-level meta-actions is essential for ensuring reliable and safe autonomous driving systems. While vision-language models (VLMs) have shown significant potential in various autonomous driving tasks, they often suffer from limitations such as inadequate spatial perception and hallucination, reducing their effectiveness in complex autonomous driving scenarios. To address these challenges, we propose a retrieval-augmented decision-making (RAD) framework, a novel architecture designed to enhance VLMs' capabilities to reliably generate meta-actions in autonomous driving scenes. RAD leverages a retrieval-augmented generation (RAG) pipeline to dynamically improve decision accuracy through a three-stage process consisting of the embedding flow, retrieving flow, and generating flow. Additionally, we fine-tune VLMs on a specifically curated dataset derived from the NuScenes dataset to enhance their spatial perception and bird's-eye view image comprehension capabilities. Extensive experimental evaluations on the curated NuScenes-based dataset demonstrate that RAD outperforms baseline methods across key evaluation metrics, including match accuracy, and F1 score, and self-defined overall score, highlighting its effectiveness in improving meta-action decision-making for autonomous driving tasks.
LLMIdxAdvis: Resource-Efficient Index Advisor Utilizing Large Language Model
Mar 10, 2025



Index recommendation is essential for improving query performance in database management systems (DBMSs) through creating an optimal set of indexes under specific constraints. Traditional methods, such as heuristic and learning-based approaches, are effective but face challenges like lengthy recommendation time, resource-intensive training, and poor generalization across different workloads and database schemas. To address these issues, we propose LLMIdxAdvis, a resource-efficient index advisor that uses large language models (LLMs) without extensive fine-tuning. LLMIdxAdvis frames index recommendation as a sequence-to-sequence task, taking target workload, storage constraint, and corresponding database environment as input, and directly outputting recommended indexes. It constructs a high-quality demonstration pool offline, using GPT-4-Turbo to synthesize diverse SQL queries and applying integrated heuristic methods to collect both default and refined labels. During recommendation, these demonstrations are ranked to inject database expertise via in-context learning. Additionally, LLMIdxAdvis extracts workload features involving specific column statistical information to strengthen LLM's understanding, and introduces a novel inference scaling strategy combining vertical scaling (via ''Index-Guided Major Voting'' and Best-of-N) and horizontal scaling (through iterative ''self-optimization'' with database feedback) to enhance reliability. Experiments on 3 OLAP and 2 real-world benchmarks reveal that LLMIdxAdvis delivers competitive index recommendation with reduced runtime, and generalizes effectively across different workloads and database schemas.
OmniSQL: Synthesizing High-quality Text-to-SQL Data at Scale
Mar 04, 2025Text-to-SQL, the task of translating natural language questions into SQL queries, plays a crucial role in enabling non-experts to interact with databases. While recent advancements in large language models (LLMs) have significantly enhanced text-to-SQL performance, existing approaches face notable limitations in real-world text-to-SQL applications. Prompting-based methods often depend on closed-source LLMs, which are expensive, raise privacy concerns, and lack customization. Fine-tuning-based methods, on the other hand, suffer from poor generalizability due to the limited coverage of publicly available training data. To overcome these challenges, we propose a novel and scalable text-to-SQL data synthesis framework for automatically synthesizing large-scale, high-quality, and diverse datasets without extensive human intervention. Using this framework, we introduce SynSQL-2.5M, the first million-scale text-to-SQL dataset, containing 2.5 million samples spanning over 16,000 synthetic databases. Each sample includes a database, SQL query, natural language question, and chain-of-thought (CoT) solution. Leveraging SynSQL-2.5M, we develop OmniSQL, a powerful open-source text-to-SQL model available in three sizes: 7B, 14B, and 32B. Extensive evaluations across nine datasets demonstrate that OmniSQL achieves state-of-the-art performance, matching or surpassing leading closed-source and open-source LLMs, including GPT-4o and DeepSeek-V3, despite its smaller size. We release all code, datasets, and models to support further research.
The Noisy Path from Source to Citation: Measuring How Scholars Engage with Past Research
Feb 27, 2025Academic citations are widely used for evaluating research and tracing knowledge flows. Such uses typically rely on raw citation counts and neglect variability in citation types. In particular, citations can vary in their fidelity as original knowledge from cited studies may be paraphrased, summarized, or reinterpreted, possibly wrongly, leading to variation in how much information changes from cited to citing paper. In this study, we introduce a computational pipeline to quantify citation fidelity at scale. Using full texts of papers, the pipeline identifies citations in citing papers and the corresponding claims in cited papers, and applies supervised models to measure fidelity at the sentence level. Analyzing a large-scale multi-disciplinary dataset of approximately 13 million citation sentence pairs, we find that citation fidelity is higher when authors cite papers that are 1) more recent and intellectually close, 2) more accessible, and 3) the first author has a lower H-index and the author team is medium-sized. Using a quasi-experiment, we establish the "telephone effect" - when citing papers have low fidelity to the original claim, future papers that cite the citing paper and the original have lower fidelity to the original. Our work reveals systematic differences in citation fidelity, underscoring the limitations of analyses that rely on citation quantity alone and the potential for distortion of evidence.
HRR: Hierarchical Retrospection Refinement for Generated Image Detection
Feb 25, 2025
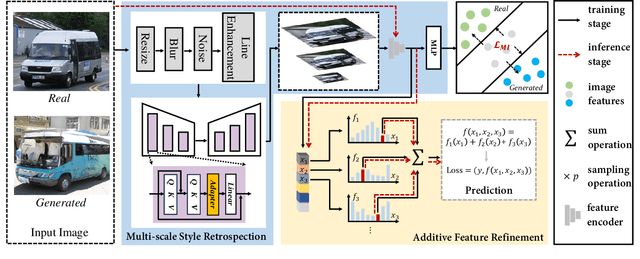
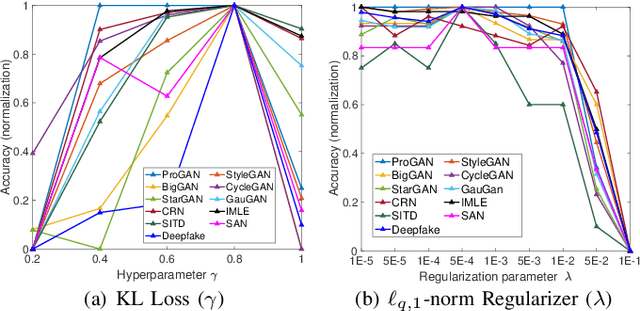
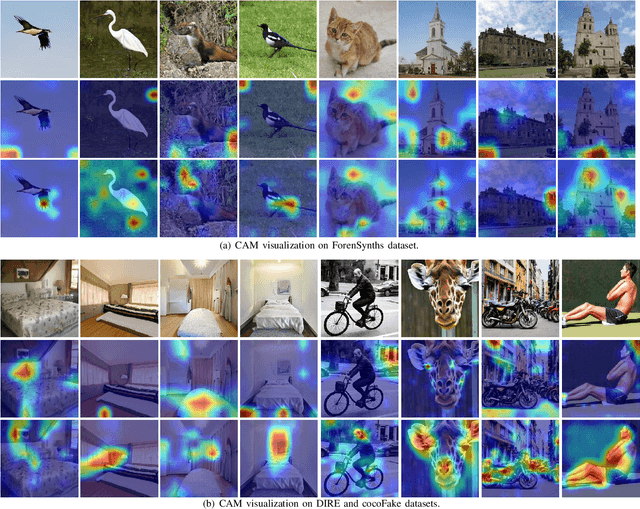
Generative artificial intelligence holds significant potential for abuse, and generative image detection has become a key focus of research. However, existing methods primarily focused on detecting a specific generative model and emphasizing the localization of synthetic regions, while neglecting the interference caused by image size and style on model learning. Our goal is to reach a fundamental conclusion: Is the image real or generated? To this end, we propose a diffusion model-based generative image detection framework termed Hierarchical Retrospection Refinement~(HRR). It designs a multi-scale style retrospection module that encourages the model to generate detailed and realistic multi-scale representations, while alleviating the learning biases introduced by dataset styles and generative models. Additionally, based on the principle of correntropy sparse additive machine, a feature refinement module is designed to reduce the impact of redundant features on learning and capture the intrinsic structure and patterns of the data, thereby improving the model's generalization ability. Extensive experiments demonstrate the HRR framework consistently delivers significant performance improvements, outperforming state-of-the-art methods in generated image detection task.
Co-MTP: A Cooperative Trajectory Prediction Framework with Multi-Temporal Fusion for Autonomous Driving
Feb 25, 2025



Vehicle-to-everything technologies (V2X) have become an ideal paradigm to extend the perception range and see through the occlusion. Exiting efforts focus on single-frame cooperative perception, however, how to capture the temporal cue between frames with V2X to facilitate the prediction task even the planning task is still underexplored. In this paper, we introduce the Co-MTP, a general cooperative trajectory prediction framework with multi-temporal fusion for autonomous driving, which leverages the V2X system to fully capture the interaction among agents in both history and future domains to benefit the planning. In the history domain, V2X can complement the incomplete history trajectory in single-vehicle perception, and we design a heterogeneous graph transformer to learn the fusion of the history feature from multiple agents and capture the history interaction. Moreover, the goal of prediction is to support future planning. Thus, in the future domain, V2X can provide the prediction results of surrounding objects, and we further extend the graph transformer to capture the future interaction among the ego planning and the other vehicles' intentions and obtain the final future scenario state under a certain planning action. We evaluate the Co-MTP framework on the real-world dataset V2X-Seq, and the results show that Co-MTP achieves state-of-the-art performance and that both history and future fusion can greatly benefit prediction.
Sustainable Adaptation for Autonomous Driving with the Mixture of Progressive Experts Networ
Feb 09, 2025



Learning-based autonomous driving methods require continuous acquisition of domain knowledge to adapt to diverse driving scenarios. However, due to the inherent challenges of long-tailed data distribution, current approaches still face limitations in complex and dynamic driving environments, particularly when encountering new scenarios and data. This underscores the necessity for enhanced continual learning capabilities to improve system adaptability. To address these challenges, the paper introduces a dynamic progressive optimization framework that facilitates adaptation to variations in dynamic environments, achieved by integrating reinforcement learning and supervised learning for data aggregation. Building on this framework, we propose the Mixture of Progressive Experts (MoPE) network. The proposed method selectively activates multiple expert models based on the distinct characteristics of each task and progressively refines the network architecture to facilitate adaptation to new tasks. Simulation results show that the MoPE model outperforms behavior cloning methods, achieving up to a 7.3% performance improvement in intricate urban road environments.