 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDRIFT: A Residual Flow Adapter for Decoding Continuous Outputs in Vision-Language Models
Jun 04, 2026Many modern vision-language models (VLMs) build on autoregressive decoding of discrete tokens. While text-based output interfaces enable scalable pretraining and strong zero-shot generalization across diverse tasks, they are poorly suited for problems that require precise continuous outputs, such as localizing temporal boundaries of events or generating robotic control actions. To address this challenge, we propose DRIFT, a general framework for adapting pretrained VLMs to continuous decoding tasks. DRIFT combines a base predictor, which provides a coarse estimate of the target output, with a generative refinement module based on flow matching that iteratively improves the prediction. This residual formulation transforms the generative modeling problem from learning a global output distribution to modeling a localized residual distribution around a strong prior, substantially simplifying optimization. We evaluate DRIFT on both perception and planning tasks, including visual grounding and robotic control. Across multiple tasks and architectures spanning MLLMs, VLAs, and WAMs, DRIFT consistently outperforms a strong set of regression- and generative-based solutions.
A Novel Modeling Framework and Data Product for Extended VIIRS-like Artificial Nighttime Light Image Reconstruction (1986-2024)
Aug 01, 2025
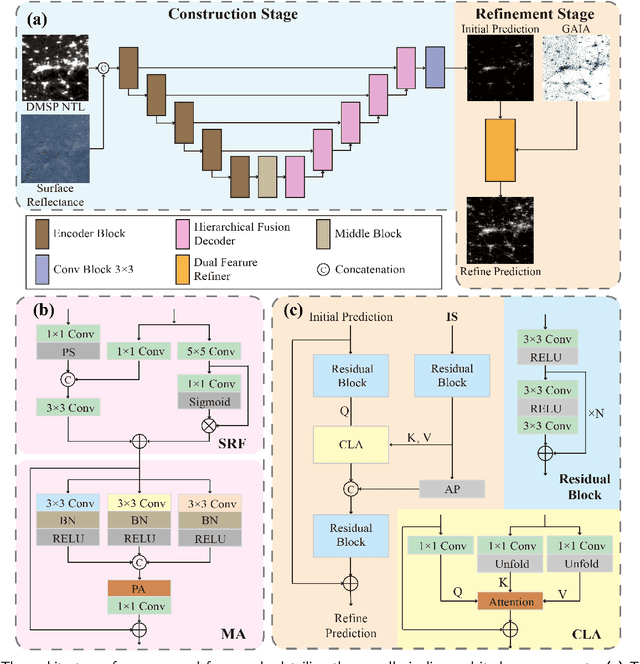
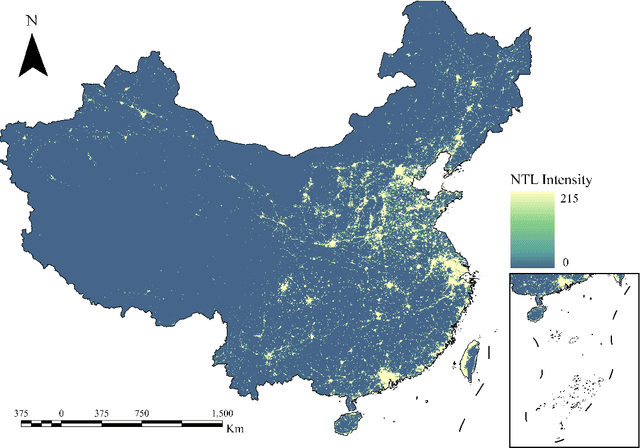
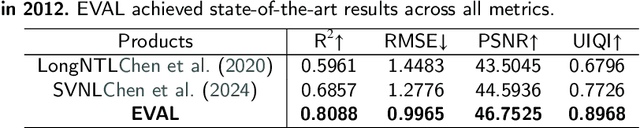
Artificial Night-Time Light (NTL) remote sensing is a vital proxy for quantifying the intensity and spatial distribution of human activities. Although the NPP-VIIRS sensor provides high-quality NTL observations, its temporal coverage, which begins in 2012, restricts long-term time-series studies that extend to earlier periods. Despite the progress in extending VIIRS-like NTL time-series, current methods still suffer from two significant shortcomings: the underestimation of light intensity and the structural omission. To overcome these limitations, we propose a novel reconstruction framework consisting of a two-stage process: construction and refinement. The construction stage features a Hierarchical Fusion Decoder (HFD) designed to enhance the fidelity of the initial reconstruction. The refinement stage employs a Dual Feature Refiner (DFR), which leverages high-resolution impervious surface masks to guide and enhance fine-grained structural details. Based on this framework, we developed the Extended VIIRS-like Artificial Nighttime Light (EVAL) product for China, extending the standard data record backwards by 26 years to begin in 1986. Quantitative evaluation shows that EVAL significantly outperforms existing state-of-the-art products, boosting the $\text{R}^2$ from 0.68 to 0.80 while lowering the RMSE from 1.27 to 0.99. Furthermore, EVAL exhibits excellent temporal consistency and maintains a high correlation with socioeconomic parameters, confirming its reliability for long-term analysis. The resulting EVAL dataset provides a valuable new resource for the research community and is publicly available at https://doi.org/10.11888/HumanNat.tpdc.302930.
Modular-Cam: Modular Dynamic Camera-view Video Generation with LLM
Apr 16, 2025



Text-to-Video generation, which utilizes the provided text prompt to generate high-quality videos, has drawn increasing attention and achieved great success due to the development of diffusion models recently. Existing methods mainly rely on a pre-trained text encoder to capture the semantic information and perform cross attention with the encoded text prompt to guide the generation of video. However, when it comes to complex prompts that contain dynamic scenes and multiple camera-view transformations, these methods can not decompose the overall information into separate scenes, as well as fail to smoothly change scenes based on the corresponding camera-views. To solve these problems, we propose a novel method, i.e., Modular-Cam. Specifically, to better understand a given complex prompt, we utilize a large language model to analyze user instructions and decouple them into multiple scenes together with transition actions. To generate a video containing dynamic scenes that match the given camera-views, we incorporate the widely-used temporal transformer into the diffusion model to ensure continuity within a single scene and propose CamOperator, a modular network based module that well controls the camera movements. Moreover, we propose AdaControlNet, which utilizes ControlNet to ensure consistency across scenes and adaptively adjusts the color tone of the generated video. Extensive qualitative and quantitative experiments prove our proposed Modular-Cam's strong capability of generating multi-scene videos together with its ability to achieve fine-grained control of camera movements. Generated results are available at https://modular-cam.github.io.