 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParallel-R1: Towards Parallel Thinking via Reinforcement Learning
Sep 09, 2025Parallel thinking has emerged as a novel approach for enhancing the reasoning capabilities of large language models (LLMs) by exploring multiple reasoning paths concurrently. However, activating such capabilities through training remains challenging, as existing methods predominantly rely on supervised fine-tuning (SFT) over synthetic data, which encourages teacher-forced imitation rather than exploration and generalization. Different from them, we propose \textbf{Parallel-R1}, the first reinforcement learning (RL) framework that enables parallel thinking behaviors for complex real-world reasoning tasks. Our framework employs a progressive curriculum that explicitly addresses the cold-start problem in training parallel thinking with RL. We first use SFT on prompt-generated trajectories from easier tasks to instill the parallel thinking ability, then transition to RL to explore and generalize this skill on harder problems. Experiments on various math benchmarks, including MATH, AMC23, and AIME, show that Parallel-R1 successfully instills parallel thinking, leading to 8.4% accuracy improvements over the sequential thinking model trained directly on challenging tasks with RL. Further analysis reveals a clear shift in the model's thinking behavior: at an early stage, it uses parallel thinking as an exploration strategy, while in a later stage, it uses the same capability for multi-perspective verification. Most significantly, we validate parallel thinking as a \textbf{mid-training exploration scaffold}, where this temporary exploratory phase unlocks a higher performance ceiling after RL, yielding a 42.9% improvement over the baseline on AIME25. Our model, data, and code will be open-source at https://github.com/zhengkid/Parallel-R1.
Rectified Robust Policy Optimization for Model-Uncertain Constrained Reinforcement Learning without Strong Duality
Aug 24, 2025



The goal of robust constrained reinforcement learning (RL) is to optimize an agent's performance under the worst-case model uncertainty while satisfying safety or resource constraints. In this paper, we demonstrate that strong duality does not generally hold in robust constrained RL, indicating that traditional primal-dual methods may fail to find optimal feasible policies. To overcome this limitation, we propose a novel primal-only algorithm called Rectified Robust Policy Optimization (RRPO), which operates directly on the primal problem without relying on dual formulations. We provide theoretical convergence guarantees under mild regularity assumptions, showing convergence to an approximately optimal feasible policy with iteration complexity matching the best-known lower bound when the uncertainty set diameter is controlled in a specific level. Empirical results in a grid-world environment validate the effectiveness of our approach, demonstrating that RRPO achieves robust and safe performance under model uncertainties while the non-robust method can violate the worst-case safety constraints.
Cost-Aware Contrastive Routing for LLMs
Aug 17, 2025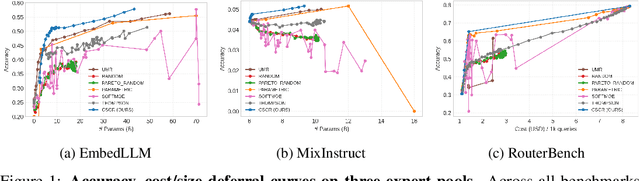
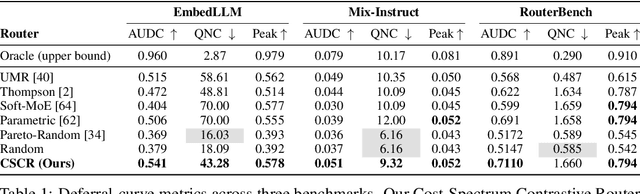

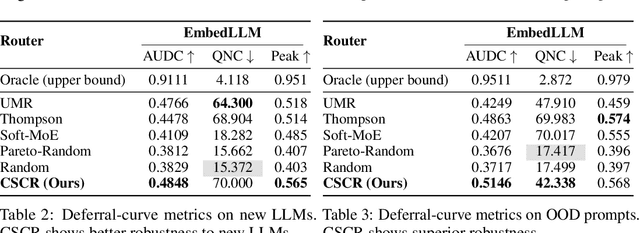
We study cost-aware routing for large language models across diverse and dynamic pools of models. Existing approaches often overlook prompt-specific context, rely on expensive model profiling, assume a fixed set of experts, or use inefficient trial-and-error strategies. We introduce Cost-Spectrum Contrastive Routing (CSCR), a lightweight framework that maps both prompts and models into a shared embedding space to enable fast, cost-sensitive selection. CSCR uses compact, fast-to-compute logit footprints for open-source models and perplexity fingerprints for black-box APIs. A contrastive encoder is trained to favor the cheapest accurate expert within adaptive cost bands. At inference time, routing reduces to a single k-NN lookup via a FAISS index, requiring no retraining when the expert pool changes and enabling microsecond latency. Across multiple benchmarks, CSCR consistently outperforms baselines, improving the accuracy-cost tradeoff by up to 25%, while generalizing robustly to unseen LLMs and out-of-distribution prompts.
A Watermark for Auto-Regressive Image Generation Models
Jun 13, 2025



The rapid evolution of image generation models has revolutionized visual content creation, enabling the synthesis of highly realistic and contextually accurate images for diverse applications. However, the potential for misuse, such as deepfake generation, image based phishing attacks, and fabrication of misleading visual evidence, underscores the need for robust authenticity verification mechanisms. While traditional statistical watermarking techniques have proven effective for autoregressive language models, their direct adaptation to image generation models encounters significant challenges due to a phenomenon we term retokenization mismatch, a disparity between original and retokenized sequences during the image generation process. To overcome this limitation, we propose C-reweight, a novel, distortion-free watermarking method explicitly designed for image generation models. By leveraging a clustering-based strategy that treats tokens within the same cluster equivalently, C-reweight mitigates retokenization mismatch while preserving image fidelity. Extensive evaluations on leading image generation platforms reveal that C-reweight not only maintains the visual quality of generated images but also improves detectability over existing distortion-free watermarking techniques, setting a new standard for secure and trustworthy image synthesis.
ARGUS: Hallucination and Omission Evaluation in Video-LLMs
Jun 09, 2025Video large language models have not yet been widely deployed, largely due to their tendency to hallucinate. Typical benchmarks for Video-LLMs rely simply on multiple-choice questions. Unfortunately, VideoLLMs hallucinate far more aggressively on freeform text generation tasks like video captioning than they do on multiple choice verification tasks. To address this weakness, we propose ARGUS, a VideoLLM benchmark that measures freeform video captioning performance. By comparing VideoLLM outputs to human ground truth captions, ARGUS quantifies dual metrics. First, we measure the rate of hallucinations in the form of incorrect statements about video content or temporal relationships. Second, we measure the rate at which the model omits important descriptive details. Together, these dual metrics form a comprehensive view of video captioning performance.
CoTGuard: Using Chain-of-Thought Triggering for Copyright Protection in Multi-Agent LLM Systems
May 26, 2025



As large language models (LLMs) evolve into autonomous agents capable of collaborative reasoning and task execution, multi-agent LLM systems have emerged as a powerful paradigm for solving complex problems. However, these systems pose new challenges for copyright protection, particularly when sensitive or copyrighted content is inadvertently recalled through inter-agent communication and reasoning. Existing protection techniques primarily focus on detecting content in final outputs, overlooking the richer, more revealing reasoning processes within the agents themselves. In this paper, we introduce CoTGuard, a novel framework for copyright protection that leverages trigger-based detection within Chain-of-Thought (CoT) reasoning. Specifically, we can activate specific CoT segments and monitor intermediate reasoning steps for unauthorized content reproduction by embedding specific trigger queries into agent prompts. This approach enables fine-grained, interpretable detection of copyright violations in collaborative agent scenarios. We evaluate CoTGuard on various benchmarks in extensive experiments and show that it effectively uncovers content leakage with minimal interference to task performance. Our findings suggest that reasoning-level monitoring offers a promising direction for safeguarding intellectual property in LLM-based agent systems.
Learning to Reason via Mixture-of-Thought for Logical Reasoning
May 21, 2025Human beings naturally utilize multiple reasoning modalities to learn and solve logical problems, i.e., different representational formats such as natural language, code, and symbolic logic. In contrast, most existing LLM-based approaches operate with a single reasoning modality during training, typically natural language. Although some methods explored modality selection or augmentation at inference time, the training process remains modality-blind, limiting synergy among modalities. To fill in this gap, we propose Mixture-of-Thought (MoT), a framework that enables LLMs to reason across three complementary modalities: natural language, code, and a newly introduced symbolic modality, truth-table, which systematically enumerates logical cases and partially mitigates key failure modes in natural language reasoning. MoT adopts a two-phase design: (1) self-evolving MoT training, which jointly learns from filtered, self-generated rationales across modalities; and (2) MoT inference, which fully leverages the synergy of three modalities to produce better predictions. Experiments on logical reasoning benchmarks including FOLIO and ProofWriter demonstrate that our MoT framework consistently and significantly outperforms strong LLM baselines with single-modality chain-of-thought approaches, achieving up to +11.7pp average accuracy gain. Further analyses show that our MoT framework benefits both training and inference stages; that it is particularly effective on harder logical reasoning problems; and that different modalities contribute complementary strengths, with truth-table reasoning helping to overcome key bottlenecks in natural language inference.
Web IP at Risk: Prevent Unauthorized Real-Time Retrieval by Large Language Models
May 19, 2025



Protecting cyber Intellectual Property (IP) such as web content is an increasingly critical concern. The rise of large language models (LLMs) with online retrieval capabilities presents a double-edged sword that enables convenient access to information but often undermines the rights of original content creators. As users increasingly rely on LLM-generated responses, they gradually diminish direct engagement with original information sources, significantly reducing the incentives for IP creators to contribute, and leading to a saturating cyberspace with more AI-generated content. In response, we propose a novel defense framework that empowers web content creators to safeguard their web-based IP from unauthorized LLM real-time extraction by leveraging the semantic understanding capability of LLMs themselves. Our method follows principled motivations and effectively addresses an intractable black-box optimization problem. Real-world experiments demonstrated that our methods improve defense success rates from 2.5% to 88.6% on different LLMs, outperforming traditional defenses such as configuration-based restrictions.
Stealthy Patch-Wise Backdoor Attack in 3D Point Cloud via Curvature Awareness
Mar 12, 2025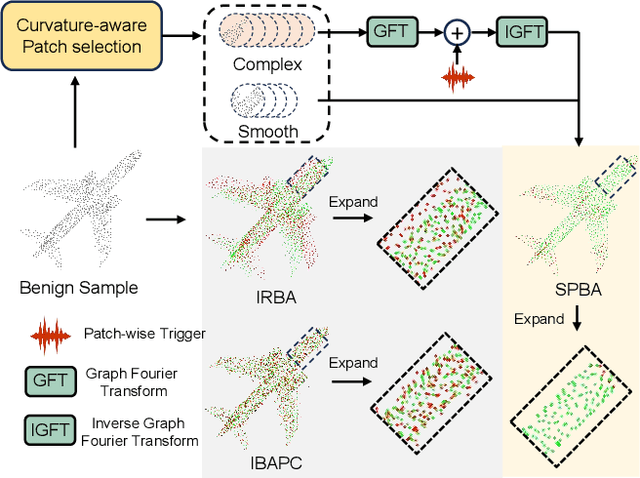
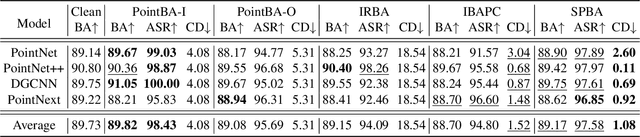
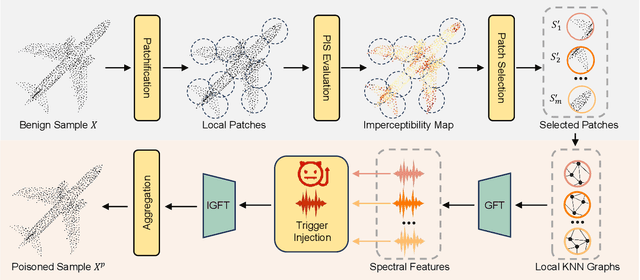
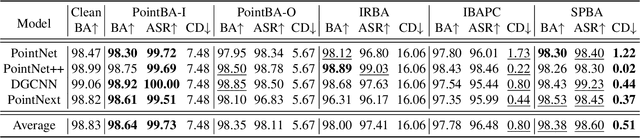
Backdoor attacks pose a severe threat to deep neural networks (DNN) by implanting hidden backdoors that can be activated with predefined triggers to manipulate model behaviors maliciously. Existing 3D point cloud backdoor attacks primarily rely on sample-wise global modifications, resulting in suboptimal stealthiness. To address this limitation, we propose Stealthy Patch-Wise Backdoor Attack (SPBA), which employs the first patch-wise trigger for 3D point clouds and restricts perturbations to local regions, significantly enhancing stealthiness. Specifically, SPBA decomposes point clouds into local patches and evaluates their geometric complexity using a curvature-based patch imperceptibility score, ensuring that the trigger remains less perceptible to the human eye by strategically applying it across multiple geometrically complex patches with lower visual sensitivity. By leveraging the Graph Fourier Transform (GFT), SPBA optimizes a patch-wise spectral trigger that perturbs the spectral features of selected patches, enhancing attack effectiveness while preserving the global geometric structure of the point cloud. Extensive experiments on ModelNet40 and ShapeNetPart demonstrate that SPBA consistently achieves an attack success rate (ASR) exceeding 96.5% across different models while achieving state-of-the-art imperceptibility compared to existing backdoor attack methods.
Towards Optimal Multi-draft Speculative Decoding
Feb 26, 2025Large Language Models (LLMs) have become an indispensable part of natural language processing tasks. However, autoregressive sampling has become an efficiency bottleneck. Multi-Draft Speculative Decoding (MDSD) is a recent approach where, when generating each token, a small draft model generates multiple drafts, and the target LLM verifies them in parallel, ensuring that the final output conforms to the target model distribution. The two main design choices in MDSD are the draft sampling method and the verification algorithm. For a fixed draft sampling method, the optimal acceptance rate is a solution to an optimal transport problem, but the complexity of this problem makes it difficult to solve for the optimal acceptance rate and measure the gap between existing verification algorithms and the theoretical upper bound. This paper discusses the dual of the optimal transport problem, providing a way to efficiently compute the optimal acceptance rate. For the first time, we measure the theoretical upper bound of MDSD efficiency for vocabulary sizes in the thousands and quantify the gap between existing verification algorithms and this bound. We also compare different draft sampling methods based on their optimal acceptance rates. Our results show that the draft sampling method strongly influences the optimal acceptance rate, with sampling without replacement outperforming sampling with replacement. Additionally, existing verification algorithms do not reach the theoretical upper bound for both without replacement and with replacement sampling. Our findings suggest that carefully designed draft sampling methods can potentially improve the optimal acceptance rate and enable the development of verification algorithms that closely match the theoretical upper bound.