 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRiemannian Zeroth-Order Gradient Estimation with Structure-Preserving Metrics for Geodesically Incomplete Manifolds
Jan 12, 2026In this paper, we study Riemannian zeroth-order optimization in settings where the underlying Riemannian metric $g$ is geodesically incomplete, and the goal is to approximate stationary points with respect to this incomplete metric. To address this challenge, we construct structure-preserving metrics that are geodesically complete while ensuring that every stationary point under the new metric remains stationary under the original one. Building on this foundation, we revisit the classical symmetric two-point zeroth-order estimator and analyze its mean-squared error from a purely intrinsic perspective, depending only on the manifold's geometry rather than any ambient embedding. Leveraging this intrinsic analysis, we establish convergence guarantees for stochastic gradient descent with this intrinsic estimator. Under additional suitable conditions, an $ε$-stationary point under the constructed metric $g'$ also corresponds to an $ε$-stationary point under the original metric $g$, thereby matching the best-known complexity in the geodesically complete setting. Empirical studies on synthetic problems confirm our theoretical findings, and experiments on a practical mesh optimization task demonstrate that our framework maintains stable convergence even in the absence of geodesic completeness.
Dynamic Feedback Engines: Layer-Wise Control for Self-Regulating Continual Learning
Dec 25, 2025Continual learning aims to acquire new tasks while preserving performance on previously learned ones, but most methods struggle with catastrophic forgetting. Existing approaches typically treat all layers uniformly, often trading stability for plasticity or vice versa. However, different layers naturally exhibit varying levels of uncertainty (entropy) when classifying tasks. High-entropy layers tend to underfit by failing to capture task-specific patterns, while low-entropy layers risk overfitting by becoming overly confident and specialized. To address this imbalance, we propose an entropy-aware continual learning method that employs a dynamic feedback mechanism to regulate each layer based on its entropy. Specifically, our approach reduces entropy in high-entropy layers to mitigate underfitting and increases entropy in overly confident layers to alleviate overfitting. This adaptive regulation encourages the model to converge to wider local minima, which have been shown to improve generalization. Our method is general and can be seamlessly integrated with both replay- and regularization-based approaches. Experiments on various datasets demonstrate substantial performance gains over state-of-the-art continual learning baselines.
R-GenIMA: Integrating Neuroimaging and Genetics with Interpretable Multimodal AI for Alzheimer's Disease Progression
Dec 22, 2025Early detection of Alzheimer's disease (AD) requires models capable of integrating macro-scale neuroanatomical alterations with micro-scale genetic susceptibility, yet existing multimodal approaches struggle to align these heterogeneous signals. We introduce R-GenIMA, an interpretable multimodal large language model that couples a novel ROI-wise vision transformer with genetic prompting to jointly model structural MRI and single nucleotide polymorphisms (SNPs) variations. By representing each anatomically parcellated brain region as a visual token and encoding SNP profiles as structured text, the framework enables cross-modal attention that links regional atrophy patterns to underlying genetic factors. Applied to the ADNI cohort, R-GenIMA achieves state-of-the-art performance in four-way classification across normal cognition (NC), subjective memory concerns (SMC), mild cognitive impairment (MCI), and AD. Beyond predictive accuracy, the model yields biologically meaningful explanations by identifying stage-specific brain regions and gene signatures, as well as coherent ROI-Gene association patterns across the disease continuum. Attention-based attribution revealed genes consistently enriched for established GWAS-supported AD risk loci, including APOE, BIN1, CLU, and RBFOX1. Stage-resolved neuroanatomical signatures identified shared vulnerability hubs across disease stages alongside stage-specific patterns: striatal involvement in subjective decline, frontotemporal engagement during prodromal impairment, and consolidated multimodal network disruption in AD. These results demonstrate that interpretable multimodal AI can synthesize imaging and genetics to reveal mechanistic insights, providing a foundation for clinically deployable tools that enable earlier risk stratification and inform precision therapeutic strategies in Alzheimer's disease.
Why Text Prevails: Vision May Undermine Multimodal Medical Decision Making
Dec 15, 2025With the rapid progress of large language models (LLMs), advanced multimodal large language models (MLLMs) have demonstrated impressive zero-shot capabilities on vision-language tasks. In the biomedical domain, however, even state-of-the-art MLLMs struggle with basic Medical Decision Making (MDM) tasks. We investigate this limitation using two challenging datasets: (1) three-stage Alzheimer's disease (AD) classification (normal, mild cognitive impairment, dementia), where category differences are visually subtle, and (2) MIMIC-CXR chest radiograph classification with 14 non-mutually exclusive conditions. Our empirical study shows that text-only reasoning consistently outperforms vision-only or vision-text settings, with multimodal inputs often performing worse than text alone. To mitigate this, we explore three strategies: (1) in-context learning with reason-annotated exemplars, (2) vision captioning followed by text-only inference, and (3) few-shot fine-tuning of the vision tower with classification supervision. These findings reveal that current MLLMs lack grounded visual understanding and point to promising directions for improving multimodal decision making in healthcare.
ImAgent: A Unified Multimodal Agent Framework for Test-Time Scalable Image Generation
Nov 14, 2025Recent text-to-image (T2I) models have made remarkable progress in generating visually realistic and semantically coherent images. However, they still suffer from randomness and inconsistency with the given prompts, particularly when textual descriptions are vague or underspecified. Existing approaches, such as prompt rewriting, best-of-N sampling, and self-refinement, can mitigate these issues but usually require additional modules and operate independently, hindering test-time scaling efficiency and increasing computational overhead. In this paper, we introduce ImAgent, a training-free unified multimodal agent that integrates reasoning, generation, and self-evaluation within a single framework for efficient test-time scaling. Guided by a policy controller, multiple generation actions dynamically interact and self-organize to enhance image fidelity and semantic alignment without relying on external models. Extensive experiments on image generation and editing tasks demonstrate that ImAgent consistently improves over the backbone and even surpasses other strong baselines where the backbone model fails, highlighting the potential of unified multimodal agents for adaptive and efficient image generation under test-time scaling.
AesTest: Measuring Aesthetic Intelligence from Perception to Production
Nov 09, 2025Perceiving and producing aesthetic judgments is a fundamental yet underexplored capability for multimodal large language models (MLLMs). However, existing benchmarks for image aesthetic assessment (IAA) are narrow in perception scope or lack the diversity needed to evaluate systematic aesthetic production. To address this gap, we introduce AesTest, a comprehensive benchmark for multimodal aesthetic perception and production, distinguished by the following features: 1) It consists of curated multiple-choice questions spanning ten tasks, covering perception, appreciation, creation, and photography. These tasks are grounded in psychological theories of generative learning. 2) It integrates data from diverse sources, including professional editing workflows, photographic composition tutorials, and crowdsourced preferences. It ensures coverage of both expert-level principles and real-world variation. 3) It supports various aesthetic query types, such as attribute-based analysis, emotional resonance, compositional choice, and stylistic reasoning. We evaluate both instruction-tuned IAA MLLMs and general MLLMs on AesTest, revealing significant challenges in building aesthetic intelligence. We will publicly release AesTest to support future research in this area.
Explore Data Left Behind in Reinforcement Learning for Reasoning Language Models
Nov 06, 2025Reinforcement Learning with Verifiable Rewards (RLVR) has emerged as an effective approach for improving the reasoning abilities of large language models (LLMs). The Group Relative Policy Optimization (GRPO) family has demonstrated strong performance in training LLMs with RLVR. However, as models train longer and scale larger, more training prompts become residual prompts, those with zero variance rewards that provide no training signal. Consequently, fewer prompts contribute to training, reducing diversity and hindering effectiveness. To fully exploit these residual prompts, we propose the Explore Residual Prompts in Policy Optimization (ERPO) framework, which encourages exploration on residual prompts and reactivates their training signals. ERPO maintains a history tracker for each prompt and adaptively increases the sampling temperature for residual prompts that previously produced all correct responses. This encourages the model to generate more diverse reasoning traces, introducing incorrect responses that revive training signals. Empirical results on the Qwen2.5 series demonstrate that ERPO consistently surpasses strong baselines across multiple mathematical reasoning benchmarks.
Trade-off in Estimating the Number of Byzantine Clients in Federated Learning
Oct 06, 2025

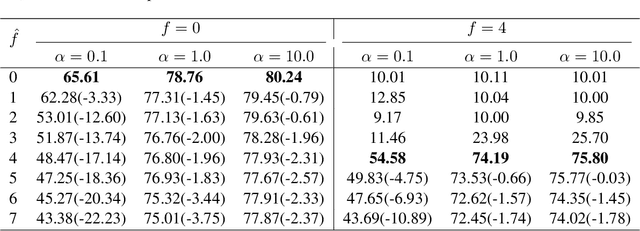

Federated learning has attracted increasing attention at recent large-scale optimization and machine learning research and applications, but is also vulnerable to Byzantine clients that can send any erroneous signals. Robust aggregators are commonly used to resist Byzantine clients. This usually requires to estimate the unknown number $f$ of Byzantine clients, and thus accordingly select the aggregators with proper degree of robustness (i.e., the maximum number $\hat{f}$ of Byzantine clients allowed by the aggregator). Such an estimation should have important effect on the performance, which has not been systematically studied to our knowledge. This work will fill in the gap by theoretically analyzing the worst-case error of aggregators as well as its induced federated learning algorithm for any cases of $\hat{f}$ and $f$. Specifically, we will show that underestimation ($\hat{f}<f$) can lead to arbitrarily poor performance for both aggregators and federated learning. For non-underestimation ($\hat{f}\ge f$), we have proved optimal lower and upper bounds of the same order on the errors of both aggregators and federated learning. All these optimal bounds are proportional to $\hat{f}/(n-f-\hat{f})$ with $n$ clients, which monotonically increases with larger $\hat{f}$. This indicates a fundamental trade-off: while an aggregator with a larger robustness degree $\hat{f}$ can solve federated learning problems of wider range $f\in [0,\hat{f}]$, the performance can deteriorate when there are actually fewer or even no Byzantine clients (i.e., $f\in [0,\hat{f})$).
Achieve Performatively Optimal Policy for Performative Reinforcement Learning
Oct 06, 2025
Performative reinforcement learning is an emerging dynamical decision making framework, which extends reinforcement learning to the common applications where the agent's policy can change the environmental dynamics. Existing works on performative reinforcement learning only aim at a performatively stable (PS) policy that maximizes an approximate value function. However, there is a provably positive constant gap between the PS policy and the desired performatively optimal (PO) policy that maximizes the original value function. In contrast, this work proposes a zeroth-order Frank-Wolfe algorithm (0-FW) algorithm with a zeroth-order approximation of the performative policy gradient in the Frank-Wolfe framework, and obtains \textbf{the first polynomial-time convergence to the desired PO} policy under the standard regularizer dominance condition. For the convergence analysis, we prove two important properties of the nonconvex value function. First, when the policy regularizer dominates the environmental shift, the value function satisfies a certain gradient dominance property, so that any stationary point (not PS) of the value function is a desired PO. Second, though the value function has unbounded gradient, we prove that all the sufficiently stationary points lie in a convex and compact policy subspace $\Pi_{\Delta}$, where the policy value has a constant lower bound $\Delta>0$ and thus the gradient becomes bounded and Lipschitz continuous. Experimental results also demonstrate that our 0-FW algorithm is more effective than the existing algorithms in finding the desired PO policy.
Zeroth-Order Methods for Stochastic Nonconvex Nonsmooth Composite Optimization
Oct 06, 2025This work aims to solve a stochastic nonconvex nonsmooth composite optimization problem. Previous works on composite optimization problem requires the major part to satisfy Lipschitz smoothness or some relaxed smoothness conditions, which excludes some machine learning examples such as regularized ReLU network and sparse support matrix machine. In this work, we focus on stochastic nonconvex composite optimization problem without any smoothness assumptions. In particular, we propose two new notions of approximate stationary points for such optimization problem and obtain finite-time convergence results of two zeroth-order algorithms to these two approximate stationary points respectively. Finally, we demonstrate that these algorithms are effective using numerical experiments.