 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge2.5D Visual Relationship Detection
Apr 26, 2021
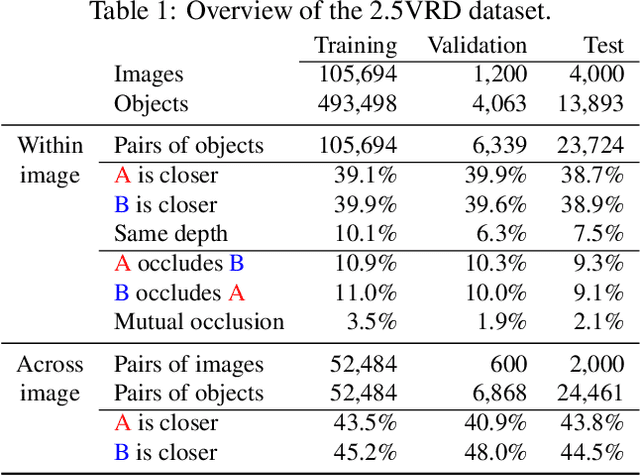
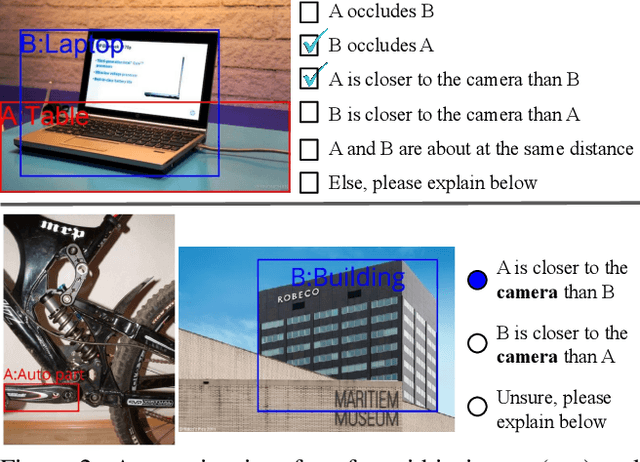

Visual 2.5D perception involves understanding the semantics and geometry of a scene through reasoning about object relationships with respect to the viewer in an environment. However, existing works in visual recognition primarily focus on the semantics. To bridge this gap, we study 2.5D visual relationship detection (2.5VRD), in which the goal is to jointly detect objects and predict their relative depth and occlusion relationships. Unlike general VRD, 2.5VRD is egocentric, using the camera's viewpoint as a common reference for all 2.5D relationships. Unlike depth estimation, 2.5VRD is object-centric and not only focuses on depth. To enable progress on this task, we create a new dataset consisting of 220k human-annotated 2.5D relationships among 512K objects from 11K images. We analyze this dataset and conduct extensive experiments including benchmarking multiple state-of-the-art VRD models on this task. Our results show that existing models largely rely on semantic cues and simple heuristics to solve 2.5VRD, motivating further research on models for 2.5D perception. The new dataset is available at https://github.com/google-research-datasets/2.5vrd.
STEP: Segmenting and Tracking Every Pixel
Feb 23, 2021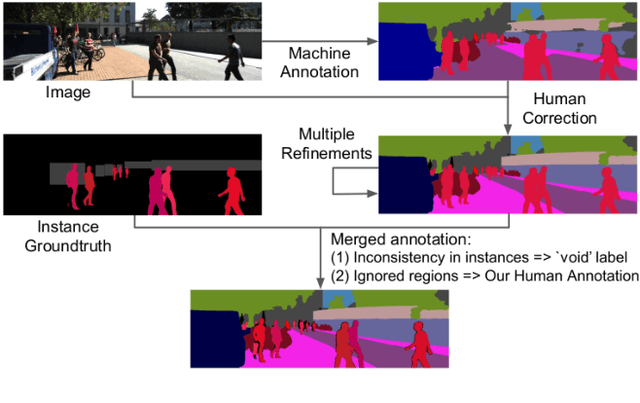
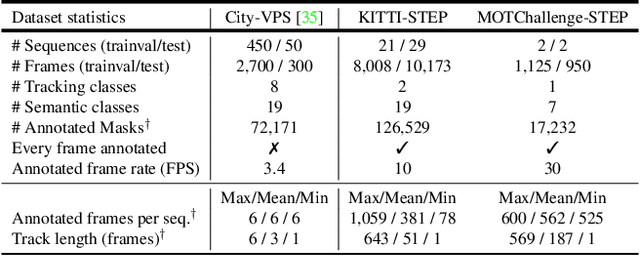


In this paper, we tackle video panoptic segmentation, a task that requires assigning semantic classes and track identities to all pixels in a video. To study this important problem in a setting that requires a continuous interpretation of sensory data, we present a new benchmark: Segmenting and Tracking Every Pixel (STEP), encompassing two datasets, KITTI-STEP, and MOTChallenge-STEP together with a new evaluation metric. Our work is the first that targets this task in a real-world setting that requires dense interpretation in both spatial and temporal domains. As the ground-truth for this task is difficult and expensive to obtain, existing datasets are either constructed synthetically or only sparsely annotated within short video clips. By contrast, our datasets contain long video sequences, providing challenging examples and a test-bed for studying long-term pixel-precise segmentation and tracking. For measuring the performance, we propose a novel evaluation metric Segmentation and Tracking Quality (STQ) that fairly balances semantic and tracking aspects of this task and is suitable for evaluating sequences of arbitrary length. We will make our datasets, metric, and baselines publicly available.
ViP-DeepLab: Learning Visual Perception with Depth-aware Video Panoptic Segmentation
Dec 09, 2020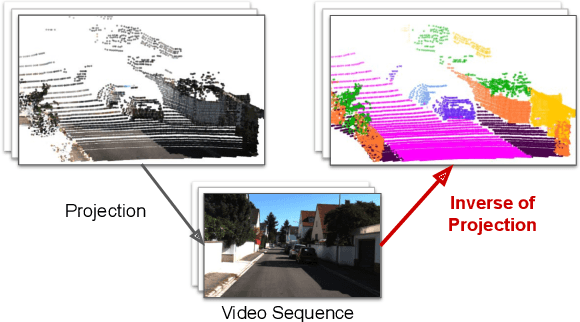
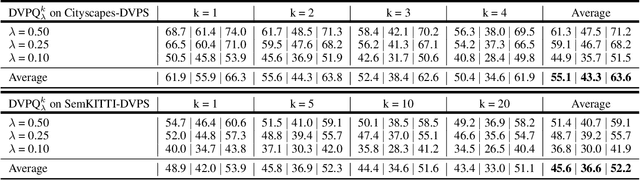
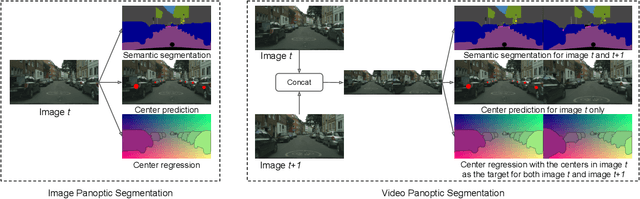
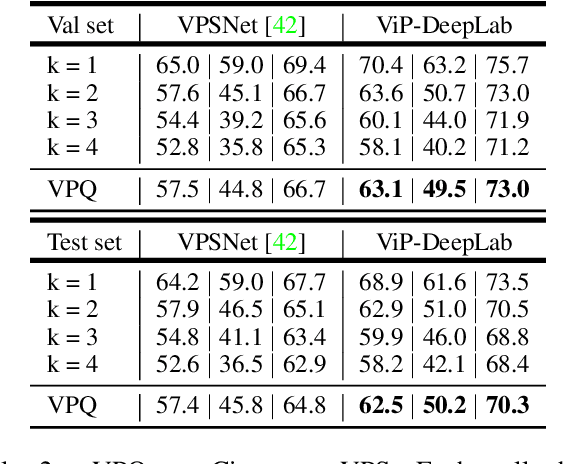
In this paper, we present ViP-DeepLab, a unified model attempting to tackle the long-standing and challenging inverse projection problem in vision, which we model as restoring the point clouds from perspective image sequences while providing each point with instance-level semantic interpretations. Solving this problem requires the vision models to predict the spatial location, semantic class, and temporally consistent instance label for each 3D point. ViP-DeepLab approaches it by jointly performing monocular depth estimation and video panoptic segmentation. We name this joint task as Depth-aware Video Panoptic Segmentation, and propose a new evaluation metric along with two derived datasets for it, which will be made available to the public. On the individual sub-tasks, ViP-DeepLab also achieves state-of-the-art results, outperforming previous methods by 5.1% VPQ on Cityscapes-VPS, ranking 1st on the KITTI monocular depth estimation benchmark, and 1st on KITTI MOTS pedestrian. The datasets and the evaluation codes are made publicly available.
Learning View-Disentangled Human Pose Representation by Contrastive Cross-View Mutual Information Maximization
Dec 02, 2020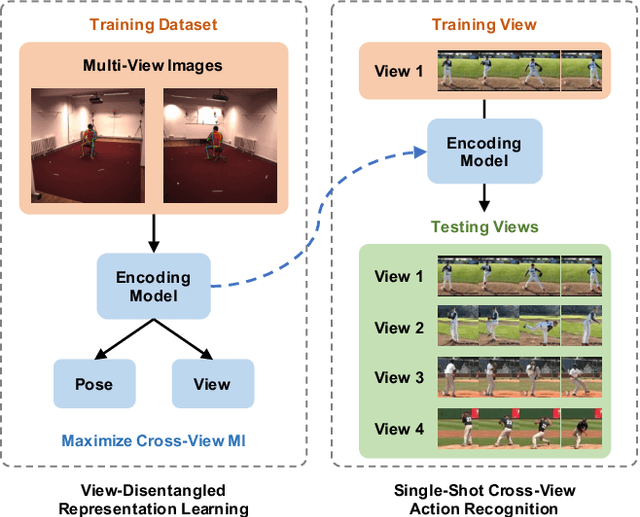
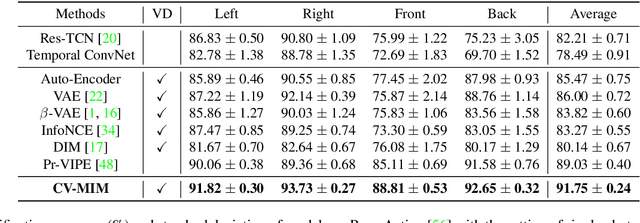
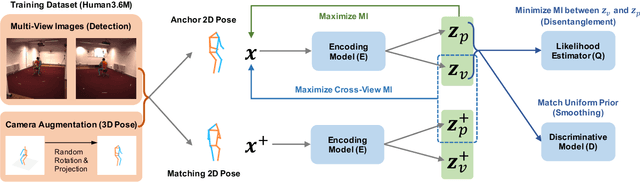
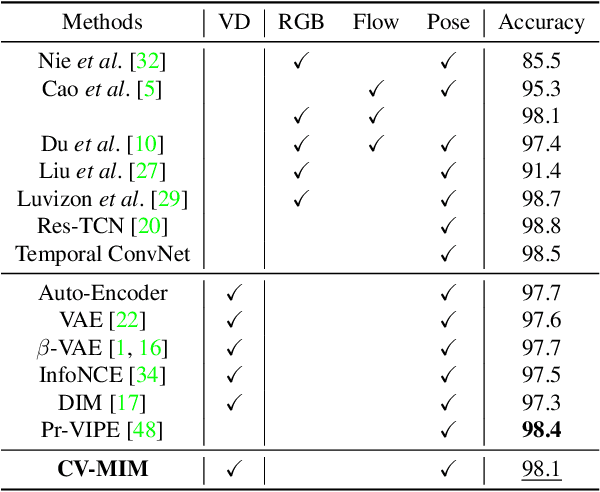
We introduce a novel representation learning method to disentangle pose-dependent as well as view-dependent factors from 2D human poses. The method trains a network using cross-view mutual information maximization (CV-MIM) which maximizes mutual information of the same pose performed from different viewpoints in a contrastive learning manner. We further propose two regularization terms to ensure disentanglement and smoothness of the learned representations. The resulting pose representations can be used for cross-view action recognition. To evaluate the power of the learned representations, in addition to the conventional fully-supervised action recognition settings, we introduce a novel task called single-shot cross-view action recognition. This task trains models with actions from only one single viewpoint while models are evaluated on poses captured from all possible viewpoints. We evaluate the learned representations on standard benchmarks for action recognition, and show that (i) CV-MIM performs competitively compared with the state-of-the-art models in the fully-supervised scenarios; (ii) CV-MIM outperforms other competing methods by a large margin in the single-shot cross-view setting; (iii) and the learned representations can significantly boost the performance when reducing the amount of supervised training data.
MaX-DeepLab: End-to-End Panoptic Segmentation with Mask Transformers
Dec 01, 2020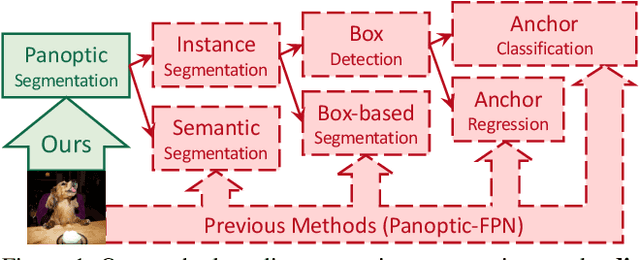
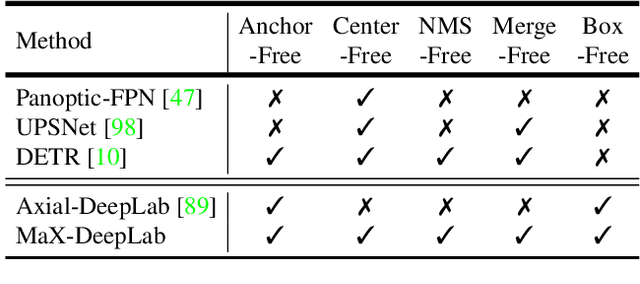

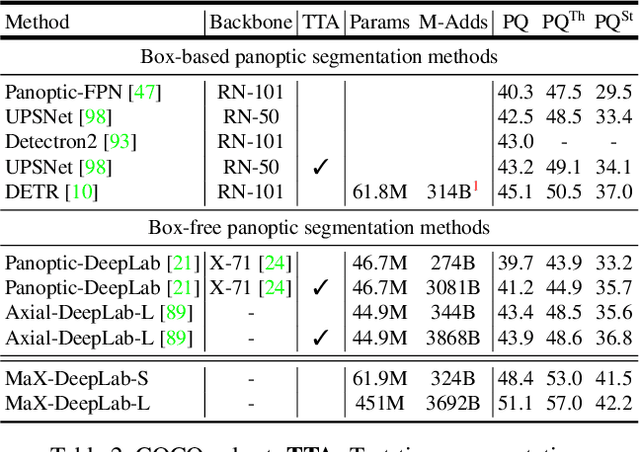
We present MaX-DeepLab, the first end-to-end model for panoptic segmentation. Our approach simplifies the current pipeline that depends heavily on surrogate sub-tasks and hand-designed components, such as box detection, non-maximum suppression, thing-stuff merging, etc. Although these sub-tasks are tackled by area experts, they fail to comprehensively solve the target task. By contrast, our MaX-DeepLab directly predicts class-labeled masks with a mask transformer, and is trained with a panoptic quality inspired loss via bipartite matching. Our mask transformer employs a dual-path architecture that introduces a global memory path in addition to a CNN path, allowing direct communication with any CNN layers. As a result, MaX-DeepLab shows a significant 7.1% PQ gain in the box-free regime on the challenging COCO dataset, closing the gap between box-based and box-free methods for the first time. A small variant of MaX-DeepLab improves 3.0% PQ over DETR with similar parameters and M-Adds. Furthermore, MaX-DeepLab, without test time augmentation, achieves new state-of-the-art 51.3% PQ on COCO test-dev set.
View-Invariant, Occlusion-Robust Probabilistic Embedding for Human Pose
Oct 23, 2020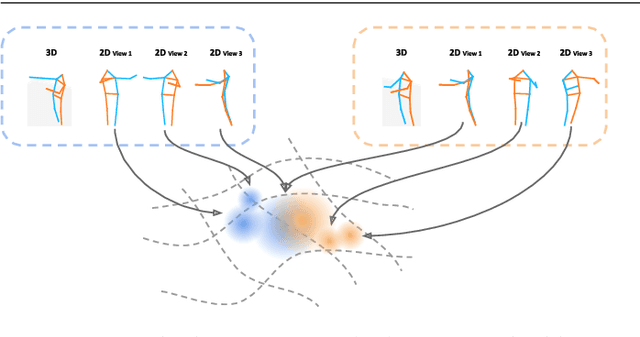
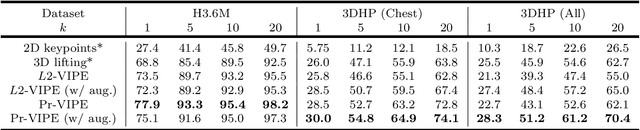
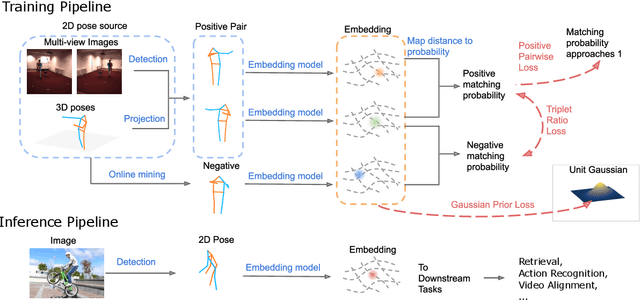

Recognition of human poses and activities is crucial for autonomous systems to interact smoothly with people. However, cameras generally capture human poses in 2D as images and videos, which can have significant appearance variations across viewpoints. To address this, we explore recognizing similarity in 3D human body poses from 2D information, which has not been well-studied in existing works. Here, we propose an approach to learning a compact view-invariant embedding space from 2D body joint keypoints, without explicitly predicting 3D poses. Input ambiguities of 2D poses from projection and occlusion are difficult to represent through a deterministic mapping, and therefore we use probabilistic embeddings. In order to enable our embeddings to work with partially visible input keypoints, we further investigate different keypoint occlusion augmentation strategies during training. Experimental results show that our embedding model achieves higher accuracy when retrieving similar poses across different camera views, in comparison with 3D pose estimation models. We further show that keypoint occlusion augmentation during training significantly improves retrieval performance on partial 2D input poses. Results on action recognition and video alignment demonstrate that our embeddings, without any additional training, achieves competitive performance relative to other models specifically trained for each task.
Leveraging Semi-Supervised Learning in Video Sequences for Urban Scene Segmentation
May 22, 2020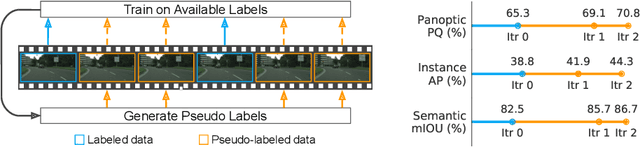

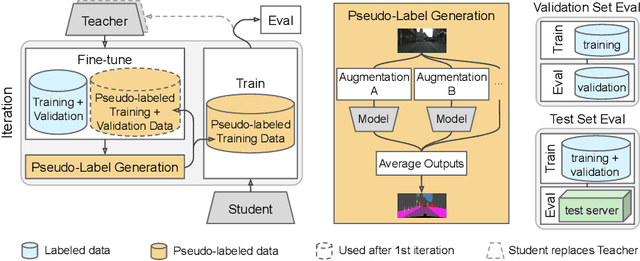
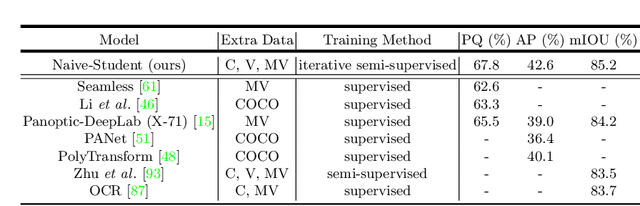
Supervised learning in large discriminative models is a mainstay for modern computer vision. Such an approach necessitates investing in large-scale human-annotated datasets for achieving state-of-the-art results. In turn, the efficacy of supervised learning may be limited by the size of the human annotated dataset. This limitation is particularly notable for image segmentation tasks, where the expense of human annotation is especially large, yet large amounts of unlabeled data may exist. In this work, we ask if we may leverage semi-supervised learning in unlabeled video sequences to improve the performance on urban scene segmentation, simultaneously tackling semantic, instance, and panoptic segmentation. The goal of this work is to avoid the construction of sophisticated, learned architectures specific to label propagation (e.g., patch matching and optical flow). Instead, we simply predict pseudo-labels for the unlabeled data and train subsequent models with both human-annotated and pseudo-labeled data. The procedure is iterated for several times. As a result, our Naive-Student model, trained with such simple yet effective iterative semi-supervised learning, attains state-of-the-art results at all three Cityscapes benchmarks, reaching the performance of 67.8% PQ, 42.6% AP, and 85.2% mIOU on the test set. We view this work as a notable step towards building a simple procedure to harness unlabeled video sequences to surpass state-of-the-art performance on core computer vision tasks.
Fashionpedia: Ontology, Segmentation, and an Attribute Localization Dataset
Apr 26, 2020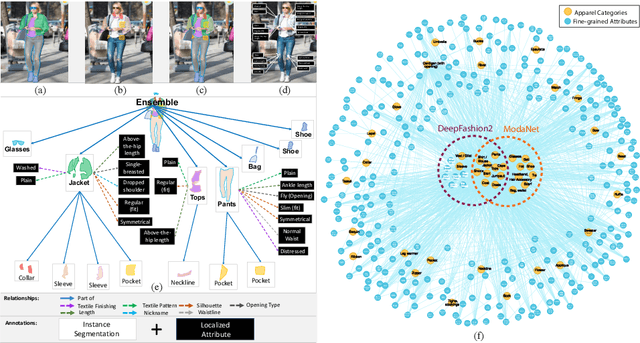


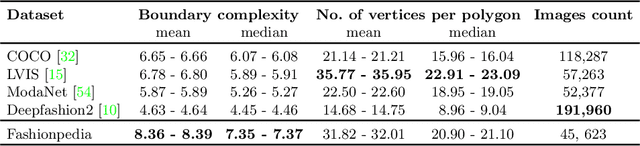
In this work we explore the task of instance segmentation with attribute localization, which unifies instance segmentation (detect and segment each object instance) and fine-grained visual attribute categorization (recognize one or multiple attributes). The proposed task requires both localizing an object and describing its properties. To illustrate the various aspects of this task, we focus on the domain of fashion and introduce Fashionpedia as a step toward mapping out the visual aspects of the fashion world. Fashionpedia consists of two parts: (1) an ontology built by fashion experts containing 27 main apparel categories, 19 apparel parts, 294 fine-grained attributes and their relationships; (2) a dataset with everyday and celebrity event fashion images annotated with segmentation masks and their associated per-mask fine-grained attributes, built upon the Fashionpedia ontology. In order to solve this challenging task, we propose a novel Attribute-Mask RCNN model to jointly perform instance segmentation and localized attribute recognition, and provide a novel evaluation metric for the task. We also demonstrate instance segmentation models pre-trained on Fashionpedia achieve better transfer learning performance on other fashion datasets than ImageNet pre-training. Fashionpedia is available at: https://fashionpedia.github.io/home/index.html.
Axial-DeepLab: Stand-Alone Axial-Attention for Panoptic Segmentation
Mar 17, 2020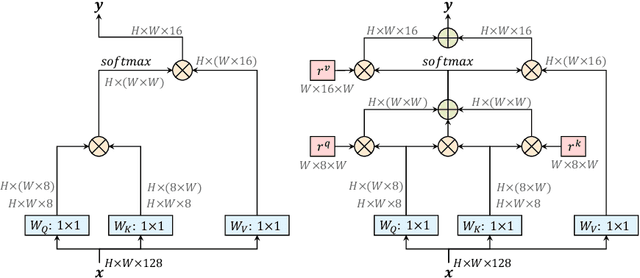
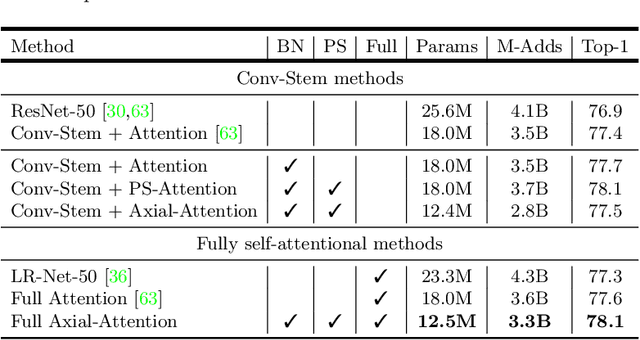
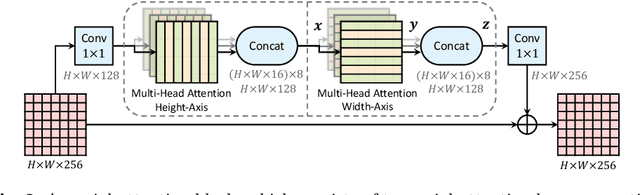
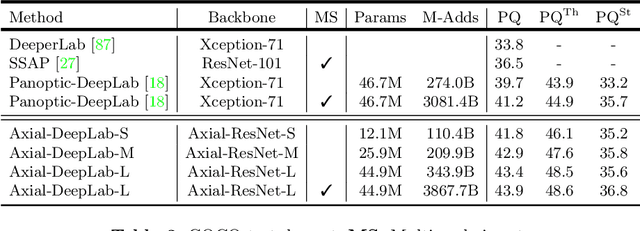
Convolution exploits locality for efficiency at a cost of missing long range context. Self-attention has been adopted to augment CNNs with non-local interactions. Recent works prove it possible to stack self-attention layers to obtain a fully attentional network by restricting the attention to a local region. In this paper, we attempt to remove this constraint by factorizing 2D self-attention into two 1D self-attentions. This reduces computation complexity and allows performing attention within a larger or even global region. In companion, we also propose a position-sensitive self-attention design. Combining both yields our position-sensitive axial-attention layer, a novel building block that one could stack to form axial-attention models for image classification and dense prediction. We demonstrate the effectiveness of our model on four large-scale datasets. In particular, our model outperforms all existing stand-alone self-attention models on ImageNet. Our Axial-DeepLab improves 2.8% PQ over bottom-up state-of-the-art on COCO test-dev. This previous state-of-the-art is attained by our small variant that is 3.8x parameter-efficient and 27x computation-efficient. Axial-DeepLab also achieves state-of-the-art results on Mapillary Vistas and Cityscapes.
EEV Dataset: Predicting Expressions Evoked by Diverse Videos
Jan 15, 2020
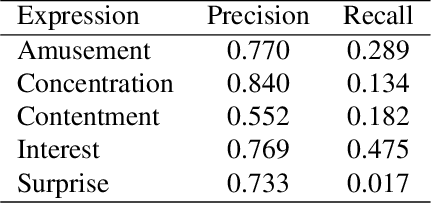
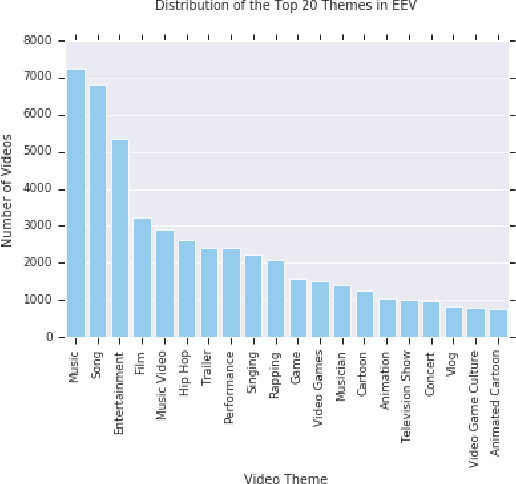
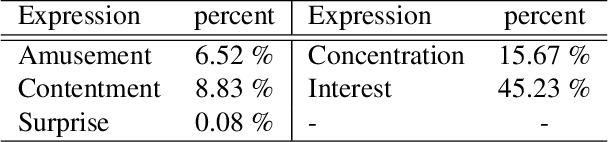
When we watch videos, the visual and auditory information we experience can evoke a range of affective responses. The ability to automatically predict evoked affect from videos can help recommendation systems and social machines better interact with their users. Here, we introduce the Evoked Expressions in Videos (EEV) dataset, a large-scale dataset for studying viewer responses to videos based on their facial expressions. The dataset consists of a total of 4.8 million annotations of viewer facial reactions to 18,541 videos. We use a publicly available video corpus to obtain a diverse set of video content. The training split is fully machine-annotated, while the validation and test splits have both human and machine annotations. We verify the performance of our machine annotations with human raters to have an average precision of 73.3%. We establish baseline performance on the EEV dataset using an existing multimodal recurrent model. Our results show that affective information can be learned from EEV, but with a MAP of 20.32%, there is potential for improvement. This gap motivates the need for new approaches for understanding affective content. Our transfer learning experiments show an improvement in performance on the LIRIS-ACCEDE video dataset when pre-trained on EEV. We hope that the size and diversity of the EEV dataset will encourage further explorations in video understanding and affective computing.