 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeshCoder: LLM-Powered Structured Mesh Code Generation from Point Clouds
Aug 20, 2025Reconstructing 3D objects into editable programs is pivotal for applications like reverse engineering and shape editing. However, existing methods often rely on limited domain-specific languages (DSLs) and small-scale datasets, restricting their ability to model complex geometries and structures. To address these challenges, we introduce MeshCoder, a novel framework that reconstructs complex 3D objects from point clouds into editable Blender Python scripts. We develop a comprehensive set of expressive Blender Python APIs capable of synthesizing intricate geometries. Leveraging these APIs, we construct a large-scale paired object-code dataset, where the code for each object is decomposed into distinct semantic parts. Subsequently, we train a multimodal large language model (LLM) that translates 3D point cloud into executable Blender Python scripts. Our approach not only achieves superior performance in shape-to-code reconstruction tasks but also facilitates intuitive geometric and topological editing through convenient code modifications. Furthermore, our code-based representation enhances the reasoning capabilities of LLMs in 3D shape understanding tasks. Together, these contributions establish MeshCoder as a powerful and flexible solution for programmatic 3D shape reconstruction and understanding.
Make Your MoVe: Make Your 3D Contents by Adapting Multi-View Diffusion Models to External Editing
Aug 11, 2025As 3D generation techniques continue to flourish, the demand for generating personalized content is rapidly rising. Users increasingly seek to apply various editing methods to polish generated 3D content, aiming to enhance its color, style, and lighting without compromising the underlying geometry. However, most existing editing tools focus on the 2D domain, and directly feeding their results into 3D generation methods (like multi-view diffusion models) will introduce information loss, degrading the quality of the final 3D assets. In this paper, we propose a tuning-free, plug-and-play scheme that aligns edited assets with their original geometry in a single inference run. Central to our approach is a geometry preservation module that guides the edited multi-view generation with original input normal latents. Besides, an injection switcher is proposed to deliberately control the supervision extent of the original normals, ensuring the alignment between the edited color and normal views. Extensive experiments show that our method consistently improves both the multi-view consistency and mesh quality of edited 3D assets, across multiple combinations of multi-view diffusion models and editing methods.
DPoser-X: Diffusion Model as Robust 3D Whole-body Human Pose Prior
Aug 01, 2025We present DPoser-X, a diffusion-based prior model for 3D whole-body human poses. Building a versatile and robust full-body human pose prior remains challenging due to the inherent complexity of articulated human poses and the scarcity of high-quality whole-body pose datasets. To address these limitations, we introduce a Diffusion model as body Pose prior (DPoser) and extend it to DPoser-X for expressive whole-body human pose modeling. Our approach unifies various pose-centric tasks as inverse problems, solving them through variational diffusion sampling. To enhance performance on downstream applications, we introduce a novel truncated timestep scheduling method specifically designed for pose data characteristics. We also propose a masked training mechanism that effectively combines whole-body and part-specific datasets, enabling our model to capture interdependencies between body parts while avoiding overfitting to specific actions. Extensive experiments demonstrate DPoser-X's robustness and versatility across multiple benchmarks for body, hand, face, and full-body pose modeling. Our model consistently outperforms state-of-the-art alternatives, establishing a new benchmark for whole-body human pose prior modeling.
NOVA3D: Normal Aligned Video Diffusion Model for Single Image to 3D Generation
Jun 09, 2025



3D AI-generated content (AIGC) has made it increasingly accessible for anyone to become a 3D content creator. While recent methods leverage Score Distillation Sampling to distill 3D objects from pretrained image diffusion models, they often suffer from inadequate 3D priors, leading to insufficient multi-view consistency. In this work, we introduce NOVA3D, an innovative single-image-to-3D generation framework. Our key insight lies in leveraging strong 3D priors from a pretrained video diffusion model and integrating geometric information during multi-view video fine-tuning. To facilitate information exchange between color and geometric domains, we propose the Geometry-Temporal Alignment (GTA) attention mechanism, thereby improving generalization and multi-view consistency. Moreover, we introduce the de-conflict geometry fusion algorithm, which improves texture fidelity by addressing multi-view inaccuracies and resolving discrepancies in pose alignment. Extensive experiments validate the superiority of NOVA3D over existing baselines.
High Quality Underwater Image Compression with Adaptive Correction and Codebook-based Augmentation
May 15, 2025



With the increasing exploration and exploitation of the underwater world, underwater images have become a critical medium for human interaction with marine environments, driving extensive research into their efficient transmission and storage. However, contemporary underwater image compression algorithms fail to fully leverage the unique characteristics distinguishing underwater scenes from terrestrial images, resulting in suboptimal performance. To address this limitation, we introduce HQUIC, designed to exploit underwater-image-specific features for enhanced compression efficiency. HQUIC employs an ALTC module to adaptively predict the attenuation coefficients and global light information of the images, which effectively mitigates the issues caused by the differences in lighting and tone existing in underwater images. Subsequently, HQUIC employs a codebook as an auxiliary branch to extract the common objects within underwater images and enhances the performance of the main branch. Furthermore, HQUIC dynamically weights multi-scale frequency components, prioritizing information critical for distortion quality while discarding redundant details. Extensive evaluations on diverse underwater datasets demonstrate that HQUIC outperforms state-of-the-art compression methods.
Towards Facial Image Compression with Consistency Preserving Diffusion Prior
May 09, 2025With the widespread application of facial image data across various domains, the efficient storage and transmission of facial images has garnered significant attention. However, the existing learned face image compression methods often produce unsatisfactory reconstructed image quality at low bit rates. Simply adapting diffusion-based compression methods to facial compression tasks results in reconstructed images that perform poorly in downstream applications due to insufficient preservation of high-frequency information. To further explore the diffusion prior in facial image compression, we propose Facial Image Compression with a Stable Diffusion Prior (FaSDiff), a method that preserves consistency through frequency enhancement. FaSDiff employs a high-frequency-sensitive compressor in an end-to-end framework to capture fine image details and produce robust visual prompts. Additionally, we introduce a hybrid low-frequency enhancement module that disentangles low-frequency facial semantics and stably modulates the diffusion prior alongside visual prompts. The proposed modules allow FaSDiff to leverage diffusion priors for superior human visual perception while minimizing performance loss in machine vision due to semantic inconsistency. Extensive experiments show that FaSDiff outperforms state-of-the-art methods in balancing human visual quality and machine vision accuracy. The code will be released after the paper is accepted.
GUAVA: Generalizable Upper Body 3D Gaussian Avatar
May 06, 2025Reconstructing a high-quality, animatable 3D human avatar with expressive facial and hand motions from a single image has gained significant attention due to its broad application potential. 3D human avatar reconstruction typically requires multi-view or monocular videos and training on individual IDs, which is both complex and time-consuming. Furthermore, limited by SMPLX's expressiveness, these methods often focus on body motion but struggle with facial expressions. To address these challenges, we first introduce an expressive human model (EHM) to enhance facial expression capabilities and develop an accurate tracking method. Based on this template model, we propose GUAVA, the first framework for fast animatable upper-body 3D Gaussian avatar reconstruction. We leverage inverse texture mapping and projection sampling techniques to infer Ubody (upper-body) Gaussians from a single image. The rendered images are refined through a neural refiner. Experimental results demonstrate that GUAVA significantly outperforms previous methods in rendering quality and offers significant speed improvements, with reconstruction times in the sub-second range (0.1s), and supports real-time animation and rendering.
MergeVQ: A Unified Framework for Visual Generation and Representation with Disentangled Token Merging and Quantization
Apr 01, 2025Masked Image Modeling (MIM) with Vector Quantization (VQ) has achieved great success in both self-supervised pre-training and image generation. However, most existing methods struggle to address the trade-off in shared latent space for generation quality vs. representation learning and efficiency. To push the limits of this paradigm, we propose MergeVQ, which incorporates token merging techniques into VQ-based generative models to bridge the gap between image generation and visual representation learning in a unified architecture. During pre-training, MergeVQ decouples top-k semantics from latent space with the token merge module after self-attention blocks in the encoder for subsequent Look-up Free Quantization (LFQ) and global alignment and recovers their fine-grained details through cross-attention in the decoder for reconstruction. As for the second-stage generation, we introduce MergeAR, which performs KV Cache compression for efficient raster-order prediction. Extensive experiments on ImageNet verify that MergeVQ as an AR generative model achieves competitive performance in both visual representation learning and image generation tasks while maintaining favorable token efficiency and inference speed. The code and model will be available at https://apexgen-x.github.io/MergeVQ.
DAGait: Generalized Skeleton-Guided Data Alignment for Gait Recognition
Mar 24, 2025



Gait recognition is emerging as a promising and innovative area within the field of computer vision, widely applied to remote person identification. Although existing gait recognition methods have achieved substantial success in controlled laboratory datasets, their performance often declines significantly when transitioning to wild datasets.We argue that the performance gap can be primarily attributed to the spatio-temporal distribution inconsistencies present in wild datasets, where subjects appear at varying angles, positions, and distances across the frames. To achieve accurate gait recognition in the wild, we propose a skeleton-guided silhouette alignment strategy, which uses prior knowledge of the skeletons to perform affine transformations on the corresponding silhouettes.To the best of our knowledge, this is the first study to explore the impact of data alignment on gait recognition. We conducted extensive experiments across multiple datasets and network architectures, and the results demonstrate the significant advantages of our proposed alignment strategy.Specifically, on the challenging Gait3D dataset, our method achieved an average performance improvement of 7.9% across all evaluated networks. Furthermore, our method achieves substantial improvements on cross-domain datasets, with accuracy improvements of up to 24.0%.
Interpretable Unsupervised Joint Denoising and Enhancement for Real-World low-light Scenarios
Mar 17, 2025
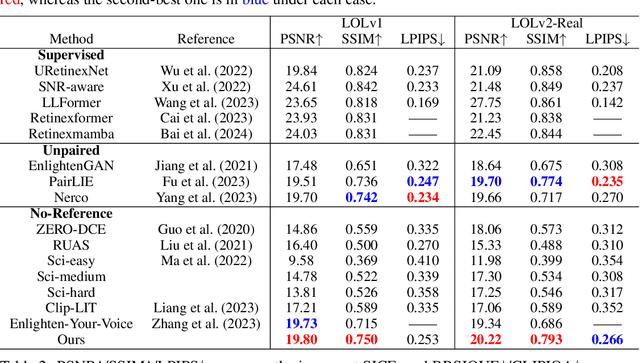


Real-world low-light images often suffer from complex degradations such as local overexposure, low brightness, noise, and uneven illumination. Supervised methods tend to overfit to specific scenarios, while unsupervised methods, though better at generalization, struggle to model these degradations due to the lack of reference images. To address this issue, we propose an interpretable, zero-reference joint denoising and low-light enhancement framework tailored for real-world scenarios. Our method derives a training strategy based on paired sub-images with varying illumination and noise levels, grounded in physical imaging principles and retinex theory. Additionally, we leverage the Discrete Cosine Transform (DCT) to perform frequency domain decomposition in the sRGB space, and introduce an implicit-guided hybrid representation strategy that effectively separates intricate compounded degradations. In the backbone network design, we develop retinal decomposition network guided by implicit degradation representation mechanisms. Extensive experiments demonstrate the superiority of our method. Code will be available at https://github.com/huaqlili/unsupervised-light-enhance-ICLR2025.