 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhanced Parcel Arrival Forecasting for Logistic Hubs: An Ensemble Deep Learning Approach
Feb 03, 2026The rapid expansion of online shopping has increased the demand for timely parcel delivery, compelling logistics service providers to enhance the efficiency, agility, and predictability of their hub networks. In order to solve the problem, we propose a novel deep learning-based ensemble framework that leverages historical arrival patterns and real-time parcel status updates to forecast upcoming workloads at logistic hubs. This approach not only facilitates the generation of short-term forecasts, but also improves the accuracy of future hub workload predictions for more strategic planning and resource management. Empirical tests of the algorithm, conducted through a case study of a major city's parcel logistics, demonstrate the ensemble method's superiority over both traditional forecasting techniques and standalone deep learning models. Our findings highlight the significant potential of this method to improve operational efficiency in logistics hubs and advocate for its broader adoption.
RepText: Rendering Visual Text via Replicating
Apr 28, 2025Although contemporary text-to-image generation models have achieved remarkable breakthroughs in producing visually appealing images, their capacity to generate precise and flexible typographic elements, especially non-Latin alphabets, remains constrained. To address these limitations, we start from an naive assumption that text understanding is only a sufficient condition for text rendering, but not a necessary condition. Based on this, we present RepText, which aims to empower pre-trained monolingual text-to-image generation models with the ability to accurately render, or more precisely, replicate, multilingual visual text in user-specified fonts, without the need to really understand them. Specifically, we adopt the setting from ControlNet and additionally integrate language agnostic glyph and position of rendered text to enable generating harmonized visual text, allowing users to customize text content, font and position on their needs. To improve accuracy, a text perceptual loss is employed along with the diffusion loss. Furthermore, to stabilize rendering process, at the inference phase, we directly initialize with noisy glyph latent instead of random initialization, and adopt region masks to restrict the feature injection to only the text region to avoid distortion of the background. We conducted extensive experiments to verify the effectiveness of our RepText relative to existing works, our approach outperforms existing open-source methods and achieves comparable results to native multi-language closed-source models. To be more fair, we also exhaustively discuss its limitations in the end.
Leveraging Large Language Models for Risk Assessment in Hyperconnected Logistic Hub Network Deployment
Mar 27, 2025The growing emphasis on energy efficiency and environmental sustainability in global supply chains introduces new challenges in the deployment of hyperconnected logistic hub networks. In current volatile, uncertain, complex, and ambiguous (VUCA) environments, dynamic risk assessment becomes essential to ensure successful hub deployment. However, traditional methods often struggle to effectively capture and analyze unstructured information. In this paper, we design an Large Language Model (LLM)-driven risk assessment pipeline integrated with multiple analytical tools to evaluate logistic hub deployment. This framework enables LLMs to systematically identify potential risks by analyzing unstructured data, such as geopolitical instability, financial trends, historical storm events, traffic conditions, and emerging risks from news sources. These data are processed through a suite of analytical tools, which are automatically called by LLMs to support a structured and data-driven decision-making process for logistic hub selection. In addition, we design prompts that instruct LLMs to leverage these tools for assessing the feasibility of hub selection by evaluating various risk types and levels. Through risk-based similarity analysis, LLMs cluster logistic hubs with comparable risk profiles, enabling a structured approach to risk assessment. In conclusion, the framework incorporates scalability with long-term memory and enhances decision-making through explanation and interpretation, enabling comprehensive risk assessments for logistic hub deployment in hyperconnected supply chain networks.
Improving COVID-19 CT Classification of CNNs by Learning Parameter-Efficient Representation
Aug 09, 2022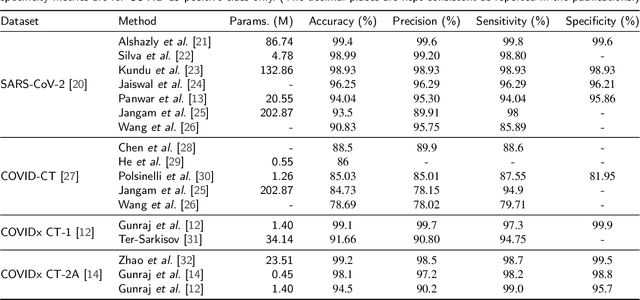
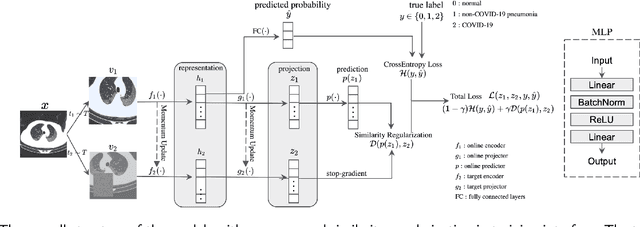
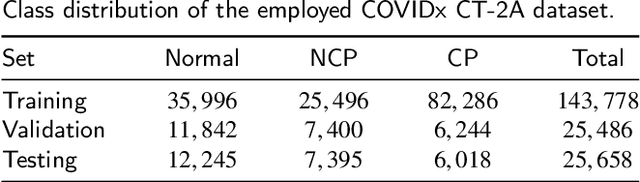
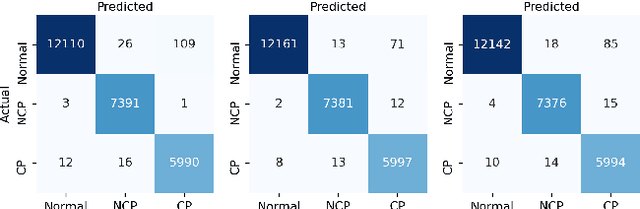
COVID-19 pandemic continues to spread rapidly over the world and causes a tremendous crisis in global human health and the economy. Its early detection and diagnosis are crucial for controlling the further spread. Many deep learning-based methods have been proposed to assist clinicians in automatic COVID-19 diagnosis based on computed tomography imaging. However, challenges still remain, including low data diversity in existing datasets, and unsatisfied detection resulting from insufficient accuracy and sensitivity of deep learning models. To enhance the data diversity, we design augmentation techniques of incremental levels and apply them to the largest open-access benchmark dataset, COVIDx CT-2A. Meanwhile, similarity regularization (SR) derived from contrastive learning is proposed in this study to enable CNNs to learn more parameter-efficient representations, thus improving the accuracy and sensitivity of CNNs. The results on seven commonly used CNNs demonstrate that CNN performance can be improved stably through applying the designed augmentation and SR techniques. In particular, DenseNet121 with SR achieves an average test accuracy of 99.44% in three trials for three-category classification, including normal, non-COVID-19 pneumonia, and COVID-19 pneumonia. And the achieved precision, sensitivity, and specificity for the COVID-19 pneumonia category are 98.40%, 99.59%, and 99.50%, respectively. These statistics suggest that our method has surpassed the existing state-of-the-art methods on the COVIDx CT-2A dataset.
Time-Frequency Distributions of Heart Sound Signals: A Comparative Study using Convolutional Neural Networks
Aug 05, 2022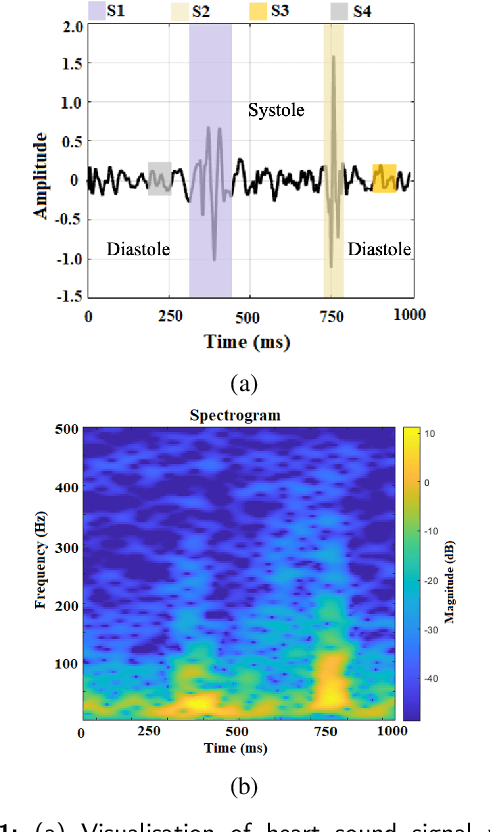
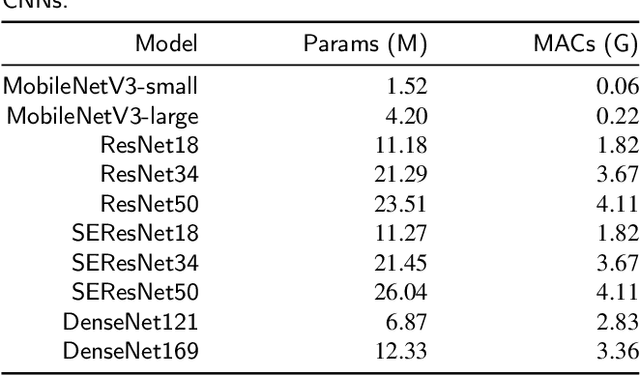
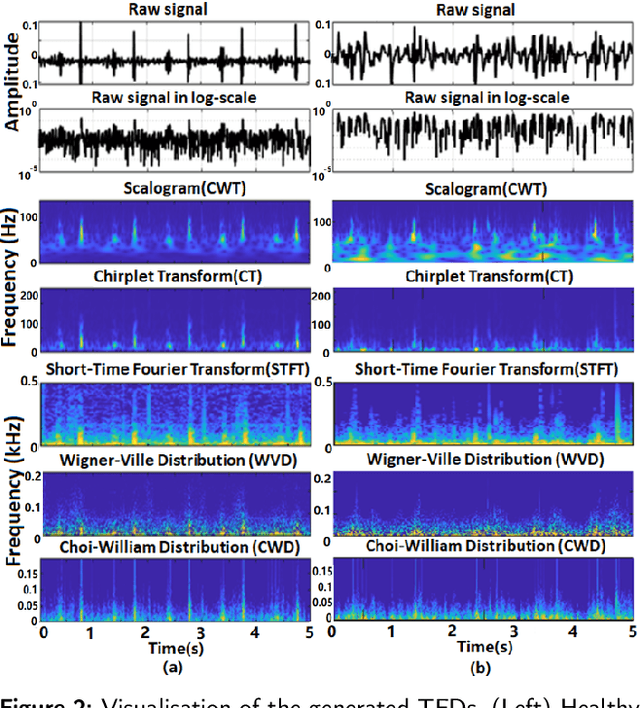

Time-Frequency Distributions (TFDs) support the heart sound characterisation and classification in early cardiac screening. However, despite the frequent use of TFDs in signal analysis, no study comprehensively compared their performances on deep learning for automatic diagnosis. Furthermore, the combination of signal processing methods as inputs for Convolutional Neural Networks (CNNs) has been proved as a practical approach to increasing signal classification performance. Therefore, this study aimed to investigate the optimal use of TFD/ combined TFDs as input for CNNs. The presented results revealed that: 1) The transformation of the heart sound signal into the TF domain achieves higher classification performance than using of raw signals. Among the TFDs, the difference in the performance was slight for all the CNN models (within $1.3\%$ in average accuracy). However, Continuous wavelet transform (CWT) and Chirplet transform (CT) outperformed the rest. 2) The appropriate increase of the CNN capacity and architecture optimisation can improve the performance, while the network architecture should not be overly complicated. Based on the ResNet or SEResNet family results, the increase in the number of parameters and the depth of the structure do not improve the performance apparently. 3) Combining TFDs as CNN inputs did not significantly improve the classification results. The findings of this study provided the knowledge for selecting TFDs as CNN input and designing CNN architecture for heart sound classification.