 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Path to Multimodal Generalist: General-Level and General-Bench
May 07, 2025The Multimodal Large Language Model (MLLM) is currently experiencing rapid growth, driven by the advanced capabilities of LLMs. Unlike earlier specialists, existing MLLMs are evolving towards a Multimodal Generalist paradigm. Initially limited to understanding multiple modalities, these models have advanced to not only comprehend but also generate across modalities. Their capabilities have expanded from coarse-grained to fine-grained multimodal understanding and from supporting limited modalities to arbitrary ones. While many benchmarks exist to assess MLLMs, a critical question arises: Can we simply assume that higher performance across tasks indicates a stronger MLLM capability, bringing us closer to human-level AI? We argue that the answer is not as straightforward as it seems. This project introduces General-Level, an evaluation framework that defines 5-scale levels of MLLM performance and generality, offering a methodology to compare MLLMs and gauge the progress of existing systems towards more robust multimodal generalists and, ultimately, towards AGI. At the core of the framework is the concept of Synergy, which measures whether models maintain consistent capabilities across comprehension and generation, and across multiple modalities. To support this evaluation, we present General-Bench, which encompasses a broader spectrum of skills, modalities, formats, and capabilities, including over 700 tasks and 325,800 instances. The evaluation results that involve over 100 existing state-of-the-art MLLMs uncover the capability rankings of generalists, highlighting the challenges in reaching genuine AI. We expect this project to pave the way for future research on next-generation multimodal foundation models, providing a robust infrastructure to accelerate the realization of AGI. Project page: https://generalist.top/
Unsupervised Visual Chain-of-Thought Reasoning via Preference Optimization
Apr 25, 2025Chain-of-thought (CoT) reasoning greatly improves the interpretability and problem-solving abilities of multimodal large language models (MLLMs). However, existing approaches are focused on text CoT, limiting their ability to leverage visual cues. Visual CoT remains underexplored, and the only work is based on supervised fine-tuning (SFT) that relies on extensive labeled bounding-box data and is hard to generalize to unseen cases. In this paper, we introduce Unsupervised Visual CoT (UV-CoT), a novel framework for image-level CoT reasoning via preference optimization. UV-CoT performs preference comparisons between model-generated bounding boxes (one is preferred and the other is dis-preferred), eliminating the need for bounding-box annotations. We get such preference data by introducing an automatic data generation pipeline. Given an image, our target MLLM (e.g., LLaVA-1.5-7B) generates seed bounding boxes using a template prompt and then answers the question using each bounded region as input. An evaluator MLLM (e.g., OmniLLM-12B) ranks the responses, and these rankings serve as supervision to train the target MLLM with UV-CoT by minimizing negative log-likelihood losses. By emulating human perception--identifying key regions and reasoning based on them--UV-CoT can improve visual comprehension, particularly in spatial reasoning tasks where textual descriptions alone fall short. Our experiments on six datasets demonstrate the superiority of UV-CoT, compared to the state-of-the-art textual and visual CoT methods. Our zero-shot testing on four unseen datasets shows the strong generalization of UV-CoT. The code is available in https://github.com/kesenzhao/UV-CoT.
Reasoning Physical Video Generation with Diffusion Timestep Tokens via Reinforcement Learning
Apr 22, 2025Despite recent progress in video generation, producing videos that adhere to physical laws remains a significant challenge. Traditional diffusion-based methods struggle to extrapolate to unseen physical conditions (eg, velocity) due to their reliance on data-driven approximations. To address this, we propose to integrate symbolic reasoning and reinforcement learning to enforce physical consistency in video generation. We first introduce the Diffusion Timestep Tokenizer (DDT), which learns discrete, recursive visual tokens by recovering visual attributes lost during the diffusion process. The recursive visual tokens enable symbolic reasoning by a large language model. Based on it, we propose the Phys-AR framework, which consists of two stages: The first stage uses supervised fine-tuning to transfer symbolic knowledge, while the second stage applies reinforcement learning to optimize the model's reasoning abilities through reward functions based on physical conditions. Our approach allows the model to dynamically adjust and improve the physical properties of generated videos, ensuring adherence to physical laws. Experimental results demonstrate that PhysAR can generate videos that are physically consistent.
Generative Multimodal Pretraining with Discrete Diffusion Timestep Tokens
Apr 20, 2025



Recent endeavors in Multimodal Large Language Models (MLLMs) aim to unify visual comprehension and generation by combining LLM and diffusion models, the state-of-the-art in each task, respectively. Existing approaches rely on spatial visual tokens, where image patches are encoded and arranged according to a spatial order (e.g., raster scan). However, we show that spatial tokens lack the recursive structure inherent to languages, hence form an impossible language for LLM to master. In this paper, we build a proper visual language by leveraging diffusion timesteps to learn discrete, recursive visual tokens. Our proposed tokens recursively compensate for the progressive attribute loss in noisy images as timesteps increase, enabling the diffusion model to reconstruct the original image at any timestep. This approach allows us to effectively integrate the strengths of LLMs in autoregressive reasoning and diffusion models in precise image generation, achieving seamless multimodal comprehension and generation within a unified framework. Extensive experiments show that we achieve superior performance for multimodal comprehension and generation simultaneously compared with other MLLMs. Project Page: https://DDT-LLaMA.github.io/.
VistaDPO: Video Hierarchical Spatial-Temporal Direct Preference Optimization for Large Video Models
Apr 17, 2025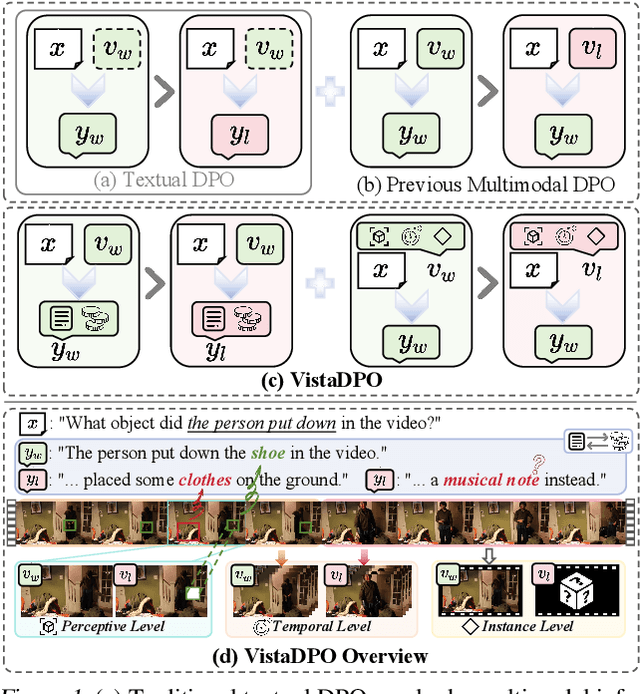
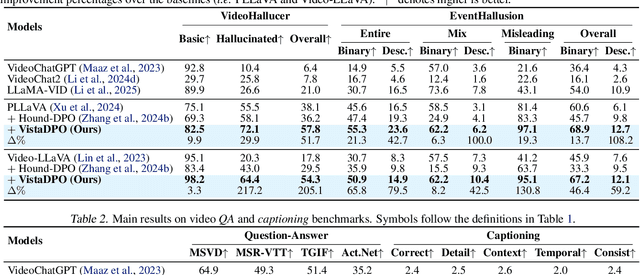
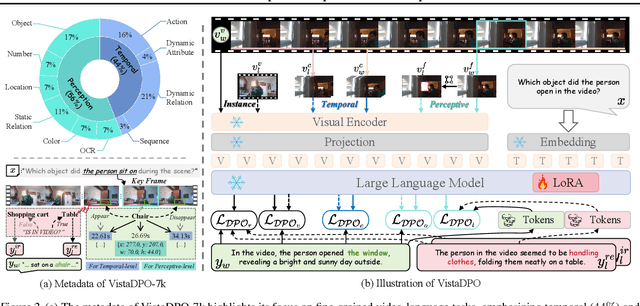
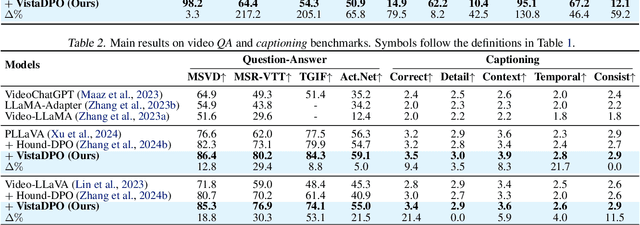
Large Video Models (LVMs) built upon Large Language Models (LLMs) have shown promise in video understanding but often suffer from misalignment with human intuition and video hallucination issues. To address these challenges, we introduce VistaDPO, a novel framework for Video Hierarchical Spatial-Temporal Direct Preference Optimization. VistaDPO enhances text-video preference alignment across three hierarchical levels: i) Instance Level, aligning overall video content with responses; ii) Temporal Level, aligning video temporal semantics with event descriptions; and iii) Perceptive Level, aligning spatial objects with language tokens. Given the lack of datasets for fine-grained video-language preference alignment, we construct VistaDPO-7k, a dataset of 7.2K QA pairs annotated with chosen and rejected responses, along with spatial-temporal grounding information such as timestamps, keyframes, and bounding boxes. Extensive experiments on benchmarks such as Video Hallucination, Video QA, and Captioning performance tasks demonstrate that VistaDPO significantly improves the performance of existing LVMs, effectively mitigating video-language misalignment and hallucination. The code and data are available at https://github.com/HaroldChen19/VistaDPO.
Generalized Visual Relation Detection with Diffusion Models
Apr 16, 2025



Visual relation detection (VRD) aims to identify relationships (or interactions) between object pairs in an image. Although recent VRD models have achieved impressive performance, they are all restricted to pre-defined relation categories, while failing to consider the semantic ambiguity characteristic of visual relations. Unlike objects, the appearance of visual relations is always subtle and can be described by multiple predicate words from different perspectives, e.g., ``ride'' can be depicted as ``race'' and ``sit on'', from the sports and spatial position views, respectively. To this end, we propose to model visual relations as continuous embeddings, and design diffusion models to achieve generalized VRD in a conditional generative manner, termed Diff-VRD. We model the diffusion process in a latent space and generate all possible relations in the image as an embedding sequence. During the generation, the visual and text embeddings of subject-object pairs serve as conditional signals and are injected via cross-attention. After the generation, we design a subsequent matching stage to assign the relation words to subject-object pairs by considering their semantic similarities. Benefiting from the diffusion-based generative process, our Diff-VRD is able to generate visual relations beyond the pre-defined category labels of datasets. To properly evaluate this generalized VRD task, we introduce two evaluation metrics, i.e., text-to-image retrieval and SPICE PR Curve inspired by image captioning. Extensive experiments in both human-object interaction (HOI) detection and scene graph generation (SGG) benchmarks attest to the superiority and effectiveness of Diff-VRD.
Learning 4D Panoptic Scene Graph Generation from Rich 2D Visual Scene
Mar 19, 2025



The latest emerged 4D Panoptic Scene Graph (4D-PSG) provides an advanced-ever representation for comprehensively modeling the dynamic 4D visual real world. Unfortunately, current pioneering 4D-PSG research can primarily suffer from data scarcity issues severely, as well as the resulting out-of-vocabulary problems; also, the pipeline nature of the benchmark generation method can lead to suboptimal performance. To address these challenges, this paper investigates a novel framework for 4D-PSG generation that leverages rich 2D visual scene annotations to enhance 4D scene learning. First, we introduce a 4D Large Language Model (4D-LLM) integrated with a 3D mask decoder for end-to-end generation of 4D-PSG. A chained SG inference mechanism is further designed to exploit LLMs' open-vocabulary capabilities to infer accurate and comprehensive object and relation labels iteratively. Most importantly, we propose a 2D-to-4D visual scene transfer learning framework, where a spatial-temporal scene transcending strategy effectively transfers dimension-invariant features from abundant 2D SG annotations to 4D scenes, effectively compensating for data scarcity in 4D-PSG. Extensive experiments on the benchmark data demonstrate that we strikingly outperform baseline models by a large margin, highlighting the effectiveness of our method.
Project-Probe-Aggregate: Efficient Fine-Tuning for Group Robustness
Mar 12, 2025While image-text foundation models have succeeded across diverse downstream tasks, they still face challenges in the presence of spurious correlations between the input and label. To address this issue, we propose a simple three-step approach,Project-Probe-Aggregate (PPA), that enables parameter-efficient fine-tuning for foundation models without relying on group annotations. Building upon the failure-based debiasing scheme, our method, PPA, improves its two key components: minority samples identification and the robust training algorithm. Specifically, we first train biased classifiers by projecting image features onto the nullspace of class proxies from text encoders. Next, we infer group labels using the biased classifier and probe group targets with prior correction. Finally, we aggregate group weights of each class to produce the debiased classifier. Our theoretical analysis shows that our PPA enhances minority group identification and is Bayes optimal for minimizing the balanced group error, mitigating spurious correlations. Extensive experimental results confirm the effectiveness of our PPA: it outperforms the state-of-the-art by an average worst-group accuracy while requiring less than 0.01% tunable parameters without training group labels.
Generalized Kullback-Leibler Divergence Loss
Mar 11, 2025In this paper, we delve deeper into the Kullback-Leibler (KL) Divergence loss and mathematically prove that it is equivalent to the Decoupled Kullback-Leibler (DKL) Divergence loss that consists of (1) a weighted Mean Square Error (wMSE) loss and (2) a Cross-Entropy loss incorporating soft labels. Thanks to the decoupled structure of DKL loss, we have identified two areas for improvement. Firstly, we address the limitation of KL loss in scenarios like knowledge distillation by breaking its asymmetric optimization property along with a smoother weight function. This modification effectively alleviates convergence challenges in optimization, particularly for classes with high predicted scores in soft labels. Secondly, we introduce class-wise global information into KL/DKL to reduce bias arising from individual samples. With these two enhancements, we derive the Generalized Kullback-Leibler (GKL) Divergence loss and evaluate its effectiveness by conducting experiments on CIFAR-10/100, ImageNet, and vision-language datasets, focusing on adversarial training, and knowledge distillation tasks. Specifically, we achieve new state-of-the-art adversarial robustness on the public leaderboard -- RobustBench and competitive knowledge distillation performance across CIFAR/ImageNet models and CLIP models, demonstrating the substantial practical merits. Our code is available at https://github.com/jiequancui/DKL.
Seeing World Dynamics in a Nutshell
Feb 05, 2025



We consider the problem of efficiently representing casually captured monocular videos in a spatially- and temporally-coherent manner. While existing approaches predominantly rely on 2D/2.5D techniques treating videos as collections of spatiotemporal pixels, they struggle with complex motions, occlusions, and geometric consistency due to absence of temporal coherence and explicit 3D structure. Drawing inspiration from monocular video as a projection of the dynamic 3D world, we explore representing videos in their intrinsic 3D form through continuous flows of Gaussian primitives in space-time. In this paper, we propose NutWorld, a novel framework that efficiently transforms monocular videos into dynamic 3D Gaussian representations in a single forward pass. At its core, NutWorld introduces a structured spatial-temporal aligned Gaussian (STAG) representation, enabling optimization-free scene modeling with effective depth and flow regularization. Through comprehensive experiments, we demonstrate that NutWorld achieves high-fidelity video reconstruction quality while enabling various downstream applications in real-time. Demos and code will be available at https://github.com/Nut-World/NutWorld.