 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSQLPrompt: In-Context Text-to-SQL with Minimal Labeled Data
Nov 06, 2023



Text-to-SQL aims to automate the process of generating SQL queries on a database from natural language text. In this work, we propose "SQLPrompt", tailored to improve the few-shot prompting capabilities of Text-to-SQL for Large Language Models (LLMs). Our methods include innovative prompt design, execution-based consistency decoding strategy which selects the SQL with the most consistent execution outcome among other SQL proposals, and a method that aims to improve performance by diversifying the SQL proposals during consistency selection with different prompt designs ("MixPrompt") and foundation models ("MixLLMs"). We show that \emph{SQLPrompt} outperforms previous approaches for in-context learning with few labeled data by a large margin, closing the gap with finetuning state-of-the-art with thousands of labeled data.
On Task-personalized Multimodal Few-shot Learning for Visually-rich Document Entity Retrieval
Nov 01, 2023Visually-rich document entity retrieval (VDER), which extracts key information (e.g. date, address) from document images like invoices and receipts, has become an important topic in industrial NLP applications. The emergence of new document types at a constant pace, each with its unique entity types, presents a unique challenge: many documents contain unseen entity types that occur only a couple of times. Addressing this challenge requires models to have the ability of learning entities in a few-shot manner. However, prior works for Few-shot VDER mainly address the problem at the document level with a predefined global entity space, which doesn't account for the entity-level few-shot scenario: target entity types are locally personalized by each task and entity occurrences vary significantly among documents. To address this unexplored scenario, this paper studies a novel entity-level few-shot VDER task. The challenges lie in the uniqueness of the label space for each task and the increased complexity of out-of-distribution (OOD) contents. To tackle this novel task, we present a task-aware meta-learning based framework, with a central focus on achieving effective task personalization that distinguishes between in-task and out-of-task distribution. Specifically, we adopt a hierarchical decoder (HC) and employ contrastive learning (ContrastProtoNet) to achieve this goal. Furthermore, we introduce a new dataset, FewVEX, to boost future research in the field of entity-level few-shot VDER. Experimental results demonstrate our approaches significantly improve the robustness of popular meta-learning baselines.
* 20 pages, 6 figures; regular long paper, EMNLP 2023
Large Language Models can Learn Rules
Oct 10, 2023



When prompted with a few examples and intermediate steps, large language models (LLMs) have demonstrated impressive performance in various reasoning tasks. However, prompting methods that rely on implicit knowledge in an LLM often hallucinate incorrect answers when the implicit knowledge is wrong or inconsistent with the task. To tackle this problem, we present Hypotheses-to-Theories (HtT), a framework that learns a rule library for reasoning with LLMs. HtT contains two stages, an induction stage and a deduction stage. In the induction stage, an LLM is first asked to generate and verify rules over a set of training examples. Rules that appear and lead to correct answers sufficiently often are collected to form a rule library. In the deduction stage, the LLM is then prompted to employ the learned rule library to perform reasoning to answer test questions. Experiments on both numerical reasoning and relational reasoning problems show that HtT improves existing prompting methods, with an absolute gain of 11-27% in accuracy. The learned rules are also transferable to different models and to different forms of the same problem.
Video Timeline Modeling For News Story Understanding
Sep 23, 2023



In this paper, we present a novel problem, namely video timeline modeling. Our objective is to create a video-associated timeline from a set of videos related to a specific topic, thereby facilitating the content and structure understanding of the story being told. This problem has significant potential in various real-world applications, such as news story summarization. To bootstrap research in this area, we curate a realistic benchmark dataset, YouTube-News-Timeline, consisting of over $12$k timelines and $300$k YouTube news videos. Additionally, we propose a set of quantitative metrics as the protocol to comprehensively evaluate and compare methodologies. With such a testbed, we further develop and benchmark exploratory deep learning approaches to tackle this problem. We anticipate that this exploratory work will pave the way for further research in video timeline modeling. The assets are available via https://github.com/google-research/google-research/tree/master/video_timeline_modeling.
Document Entity Retrieval with Massive and Noisy Pre-training
Jun 15, 2023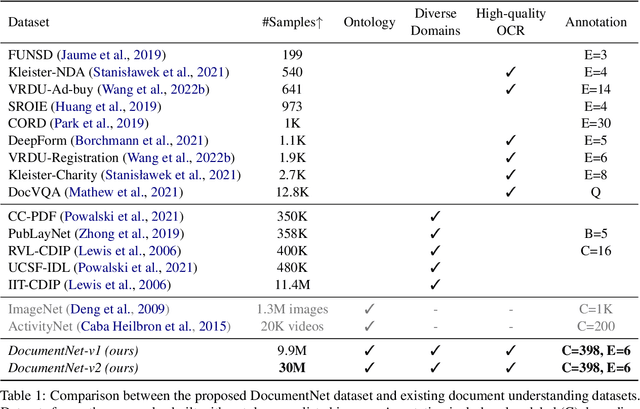

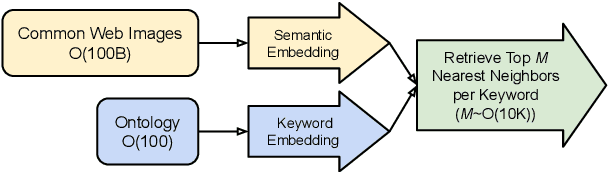

Visually-Rich Document Entity Retrieval (VDER) is a type of machine learning task that aims at recovering text spans in the documents for each of the entities in question. VDER has gained significant attention in recent years thanks to its broad applications in enterprise AI. Unfortunately, as document images often contain personally identifiable information (PII), publicly available data have been scarce, not only because of privacy constraints but also the costs of acquiring annotations. To make things worse, each dataset would often define its own sets of entities, and the non-overlapping entity spaces between datasets make it difficult to transfer knowledge between documents. In this paper, we propose a method to collect massive-scale, noisy, and weakly labeled data from the web to benefit the training of VDER models. Such a method will generate a huge amount of document image data to compensate for the lack of training data in many VDER settings. Moreover, the collected dataset named DocuNet would not need to be dependent on specific document types or entity sets, making it universally applicable to all VDER tasks. Empowered by DocuNet, we present a lightweight multimodal architecture named UniFormer, which can learn a unified representation from text, layout, and image crops without needing extra visual pertaining. We experiment with our methods on popular VDER models in various settings and show the improvements when this massive dataset is incorporated with UniFormer on both classic entity retrieval and few-shot learning settings.
SQL-PaLM: Improved Large Language Model Adaptation for Text-to-SQL
Jun 07, 2023



One impressive emergent capability of large language models (LLMs) is generation of code, including Structured Query Language (SQL) for databases. For the task of converting natural language text to SQL queries, Text-to-SQL, adaptation of LLMs is of paramount importance, both in in-context learning and fine-tuning settings, depending on the amount of adaptation data used. In this paper, we propose an LLM-based Text-to-SQL model SQL-PaLM, leveraging on PaLM-2, that pushes the state-of-the-art in both settings. Few-shot SQL-PaLM is based on an execution-based self-consistency prompting approach designed for Text-to-SQL, and achieves 77.3% in test-suite accuracy on Spider, which to our best knowledge is the first to outperform previous state-of-the-art with fine-tuning by a significant margin, 4%. Furthermore, we demonstrate that the fine-tuned SQL-PALM outperforms it further by another 1%. Towards applying SQL-PaLM to real-world scenarios we further evaluate its robustness on other challenging variants of Spider and demonstrate the superior generalization capability of SQL-PaLM. In addition, via extensive case studies, we demonstrate the impressive intelligent capabilities and various success enablers of LLM-based Text-to-SQL.
LambdaBeam: Neural Program Search with Higher-Order Functions and Lambdas
Jun 03, 2023Search is an important technique in program synthesis that allows for adaptive strategies such as focusing on particular search directions based on execution results. Several prior works have demonstrated that neural models are effective at guiding program synthesis searches. However, a common drawback of those approaches is the inability to handle iterative loops, higher-order functions, or lambda functions, thus limiting prior neural searches from synthesizing longer and more general programs. We address this gap by designing a search algorithm called LambdaBeam that can construct arbitrary lambda functions that compose operations within a given DSL. We create semantic vector representations of the execution behavior of the lambda functions and train a neural policy network to choose which lambdas to construct during search, and pass them as arguments to higher-order functions to perform looping computations. Our experiments show that LambdaBeam outperforms neural, symbolic, and LLM-based techniques in an integer list manipulation domain.
Let the Flows Tell: Solving Graph Combinatorial Optimization Problems with GFlowNets
May 26, 2023



Combinatorial optimization (CO) problems are often NP-hard and thus out of reach for exact algorithms, making them a tempting domain to apply machine learning methods. The highly structured constraints in these problems can hinder either optimization or sampling directly in the solution space. On the other hand, GFlowNets have recently emerged as a powerful machinery to efficiently sample from composite unnormalized densities sequentially and have the potential to amortize such solution-searching processes in CO, as well as generate diverse solution candidates. In this paper, we design Markov decision processes (MDPs) for different combinatorial problems and propose to train conditional GFlowNets to sample from the solution space. Efficient training techniques are also developed to benefit long-range credit assignment. Through extensive experiments on a variety of different CO tasks with synthetic and realistic data, we demonstrate that GFlowNet policies can efficiently find high-quality solutions.
Universal Self-adaptive Prompting
May 24, 2023



A hallmark of modern large language models (LLMs) is their impressive general zero-shot and few-shot abilities, often elicited through prompt-based and/or in-context learning. However, while highly coveted and being the most general, zero-shot performances in LLMs are still typically weaker due to the lack of guidance and the difficulty of applying existing automatic prompt design methods in general tasks when ground-truth labels are unavailable. In this study, we address this by presenting Universal Self-adaptive Prompting (USP), an automatic prompt design approach specifically tailored for zero-shot learning (while compatible with few-shot). Requiring only a small amount of unlabeled data & an inference-only LLM, USP is highly versatile: to achieve universal prompting, USP categorizes a possible NLP task into one of the three possible task types, and then uses a corresponding selector to select the most suitable queries & zero-shot model-generated responses as pseudo-demonstrations, thereby generalizing ICL to the zero-shot setup in a fully automated way. We evaluate zero-shot USP with two PaLM models, and demonstrate performances that are considerably stronger than standard zero-shot baselines and are comparable to or even superior than few-shot baselines across more than 20 natural language understanding (NLU) and natural language generation (NLG) tasks.
Better Zero-Shot Reasoning with Self-Adaptive Prompting
May 23, 2023



Modern large language models (LLMs) have demonstrated impressive capabilities at sophisticated tasks, often through step-by-step reasoning similar to humans. This is made possible by their strong few and zero-shot abilities -- they can effectively learn from a handful of handcrafted, completed responses ("in-context examples"), or are prompted to reason spontaneously through specially designed triggers. Nonetheless, some limitations have been observed. First, performance in the few-shot setting is sensitive to the choice of examples, whose design requires significant human effort. Moreover, given the diverse downstream tasks of LLMs, it may be difficult or laborious to handcraft per-task labels. Second, while the zero-shot setting does not require handcrafting, its performance is limited due to the lack of guidance to the LLMs. To address these limitations, we propose Consistency-based Self-adaptive Prompting (COSP), a novel prompt design method for LLMs. Requiring neither handcrafted responses nor ground-truth labels, COSP selects and builds the set of examples from the LLM zero-shot outputs via carefully designed criteria that combine consistency, diversity and repetition. In the zero-shot setting for three different LLMs, we show that using only LLM predictions, COSP improves performance up to 15% compared to zero-shot baselines and matches or exceeds few-shot baselines for a range of reasoning tasks.