 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNatural Language Outlines for Code: Literate Programming in the LLM Era
Aug 09, 2024



We propose using natural language outlines as a novel modality and interaction surface for providing AI assistance to developers throughout the software development process. An NL outline for a code function comprises multiple statements written in concise prose, which partition the code and summarize its main ideas in the style of literate programming. Crucially, we find that modern LLMs can generate accurate and high-quality NL outlines in practice. Moreover, NL outlines enable a bidirectional sync between code and NL, allowing changes in one to be automatically reflected in the other. We discuss many use cases for NL outlines: they can accelerate understanding and navigation of code and diffs, simplify code maintenance, augment code search, steer code generation, and more. We then propose and compare multiple LLM prompting techniques for generating outlines and ask professional developers to judge outline quality. Finally, we present two case studies applying NL outlines toward code review and the difficult task of malware detection.
NExT: Teaching Large Language Models to Reason about Code Execution
Apr 23, 2024



A fundamental skill among human developers is the ability to understand and reason about program execution. As an example, a programmer can mentally simulate code execution in natural language to debug and repair code (aka. rubber duck debugging). However, large language models (LLMs) of code are typically trained on the surface textual form of programs, thus may lack a semantic understanding of how programs execute at run-time. To address this issue, we propose NExT, a method to teach LLMs to inspect the execution traces of programs (variable states of executed lines) and reason about their run-time behavior through chain-of-thought (CoT) rationales. Specifically, NExT uses self-training to bootstrap a synthetic training set of execution-aware rationales that lead to correct task solutions (e.g., fixed programs) without laborious manual annotation. Experiments on program repair tasks based on MBPP and HumanEval demonstrate that NExT improves the fix rate of a PaLM 2 model, by 26.1% and 14.3% absolute, respectively, with significantly improved rationale quality as verified by automated metrics and human raters. Our model can also generalize to scenarios where program traces are absent at test-time.
Grounding Data Science Code Generation with Input-Output Specifications
Feb 12, 2024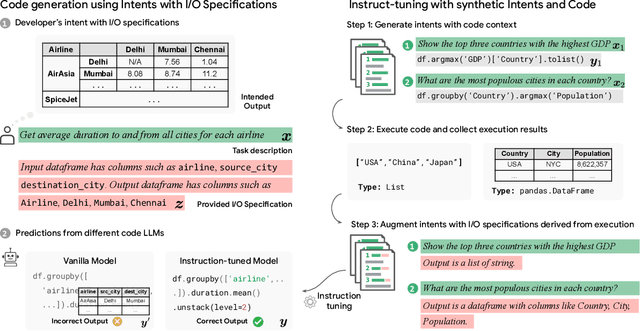

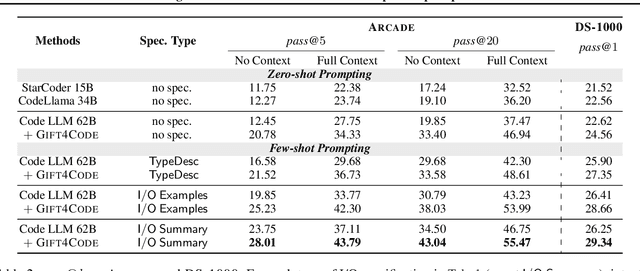

Large language models (LLMs) have recently demonstrated a remarkable ability to generate code from natural language (NL) prompts. However, in the real world, NL is often too ambiguous to capture the true intent behind programming problems, requiring additional input-output (I/O) specifications. Unfortunately, LLMs can have difficulty aligning their outputs with both the NL prompt and the I/O specification. In this paper, we give a way to mitigate this issue in the context of data science programming, where tasks require explicit I/O specifications for clarity. Specifically, we propose GIFT4Code, a novel approach for the instruction fine-tuning of LLMs with respect to I/O specifications. Our method leverages synthetic data produced by the LLM itself and utilizes execution-derived feedback as a key learning signal. This feedback, in the form of program I/O specifications, is provided to the LLM to facilitate instruction fine-tuning. We evaluated our approach on two challenging data science benchmarks, Arcade and DS-1000. The results demonstrate a significant improvement in the LLM's ability to generate code that is not only executable but also accurately aligned with user specifications, substantially improving the quality of code generation for complex data science tasks.
ExeDec: Execution Decomposition for Compositional Generalization in Neural Program Synthesis
Jul 26, 2023When writing programs, people have the ability to tackle a new complex task by decomposing it into smaller and more familiar subtasks. While it is difficult to measure whether neural program synthesis methods have similar capabilities, we can measure whether they compositionally generalize, that is, whether a model that has been trained on the simpler subtasks is subsequently able to solve more complex tasks. In this paper, we characterize several different forms of compositional generalization that are desirable in program synthesis, forming a meta-benchmark which we use to create generalization tasks for two popular datasets, RobustFill and DeepCoder. We then propose ExeDec, a novel decomposition-based synthesis strategy that predicts execution subgoals to solve problems step-by-step informed by program execution at each step. ExeDec has better synthesis performance and greatly improved compositional generalization ability compared to baselines.
LambdaBeam: Neural Program Search with Higher-Order Functions and Lambdas
Jun 03, 2023Search is an important technique in program synthesis that allows for adaptive strategies such as focusing on particular search directions based on execution results. Several prior works have demonstrated that neural models are effective at guiding program synthesis searches. However, a common drawback of those approaches is the inability to handle iterative loops, higher-order functions, or lambda functions, thus limiting prior neural searches from synthesizing longer and more general programs. We address this gap by designing a search algorithm called LambdaBeam that can construct arbitrary lambda functions that compose operations within a given DSL. We create semantic vector representations of the execution behavior of the lambda functions and train a neural policy network to choose which lambdas to construct during search, and pass them as arguments to higher-order functions to perform looping computations. Our experiments show that LambdaBeam outperforms neural, symbolic, and LLM-based techniques in an integer list manipulation domain.
Natural Language to Code Generation in Interactive Data Science Notebooks
Dec 19, 2022



Computational notebooks, such as Jupyter notebooks, are interactive computing environments that are ubiquitous among data scientists to perform data wrangling and analytic tasks. To measure the performance of AI pair programmers that automatically synthesize programs for those tasks given natural language (NL) intents from users, we build ARCADE, a benchmark of 1082 code generation problems using the pandas data analysis framework in data science notebooks. ARCADE features multiple rounds of NL-to-code problems from the same notebook. It requires a model to understand rich multi-modal contexts, such as existing notebook cells and their execution states as well as previous turns of interaction. To establish a strong baseline on this challenging task, we develop PaChiNCo, a 62B code language model (LM) for Python computational notebooks, which significantly outperforms public code LMs. Finally, we explore few-shot prompting strategies to elicit better code with step-by-step decomposition and NL explanation, showing the potential to improve the diversity and explainability of model predictions.
A Library for Representing Python Programs as Graphs for Machine Learning
Aug 15, 2022



Graph representations of programs are commonly a central element of machine learning for code research. We introduce an open source Python library python_graphs that applies static analysis to construct graph representations of Python programs suitable for training machine learning models. Our library admits the construction of control-flow graphs, data-flow graphs, and composite ``program graphs'' that combine control-flow, data-flow, syntactic, and lexical information about a program. We present the capabilities and limitations of the library, perform a case study applying the library to millions of competitive programming submissions, and showcase the library's utility for machine learning research.
PaLM: Scaling Language Modeling with Pathways
Apr 19, 2022



Large language models have been shown to achieve remarkable performance across a variety of natural language tasks using few-shot learning, which drastically reduces the number of task-specific training examples needed to adapt the model to a particular application. To further our understanding of the impact of scale on few-shot learning, we trained a 540-billion parameter, densely activated, Transformer language model, which we call Pathways Language Model PaLM. We trained PaLM on 6144 TPU v4 chips using Pathways, a new ML system which enables highly efficient training across multiple TPU Pods. We demonstrate continued benefits of scaling by achieving state-of-the-art few-shot learning results on hundreds of language understanding and generation benchmarks. On a number of these tasks, PaLM 540B achieves breakthrough performance, outperforming the finetuned state-of-the-art on a suite of multi-step reasoning tasks, and outperforming average human performance on the recently released BIG-bench benchmark. A significant number of BIG-bench tasks showed discontinuous improvements from model scale, meaning that performance steeply increased as we scaled to our largest model. PaLM also has strong capabilities in multilingual tasks and source code generation, which we demonstrate on a wide array of benchmarks. We additionally provide a comprehensive analysis on bias and toxicity, and study the extent of training data memorization with respect to model scale. Finally, we discuss the ethical considerations related to large language models and discuss potential mitigation strategies.
Compositional Generalization and Decomposition in Neural Program Synthesis
Apr 07, 2022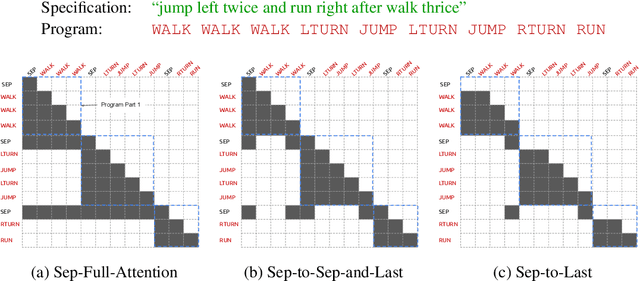
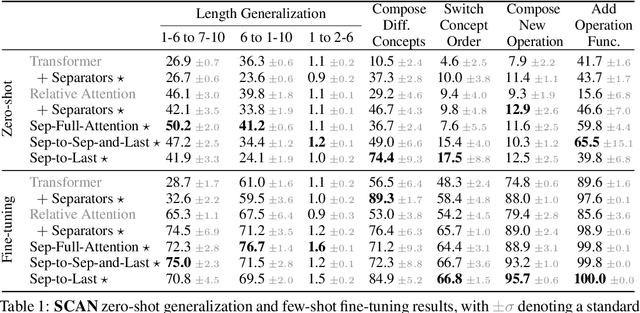
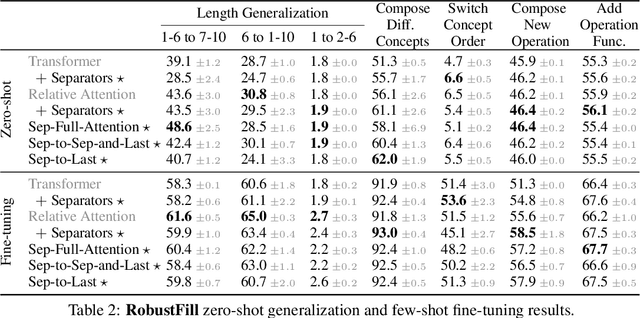

When writing programs, people have the ability to tackle a new complex task by decomposing it into smaller and more familiar subtasks. While it is difficult to measure whether neural program synthesis methods have similar capabilities, what we can measure is whether they compositionally generalize, that is, whether a model that has been trained on the simpler subtasks is subsequently able to solve more complex tasks. In this paper, we focus on measuring the ability of learned program synthesizers to compositionally generalize. We first characterize several different axes along which program synthesis methods would be desired to generalize, e.g., length generalization, or the ability to combine known subroutines in new ways that do not occur in the training data. Based on this characterization, we introduce a benchmark suite of tasks to assess these abilities based on two popular existing datasets, SCAN and RobustFill. Finally, we make first attempts to improve the compositional generalization ability of Transformer models along these axes through novel attention mechanisms that draw inspiration from a human-like decomposition strategy. Empirically, we find our modified Transformer models generally perform better than natural baselines, but the tasks remain challenging.
CrossBeam: Learning to Search in Bottom-Up Program Synthesis
Mar 20, 2022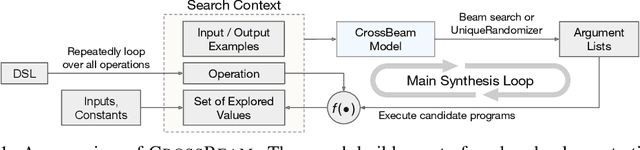
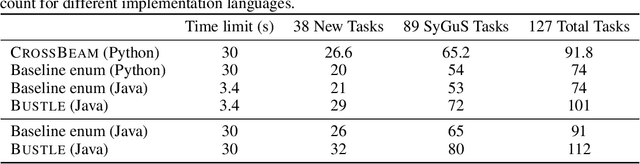
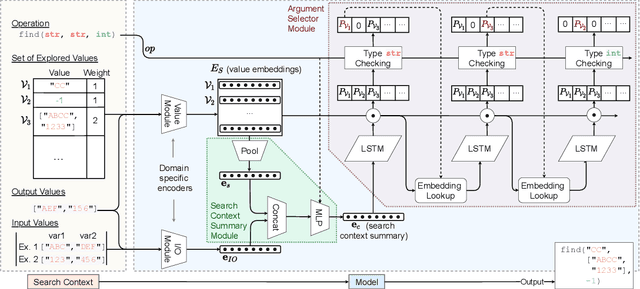
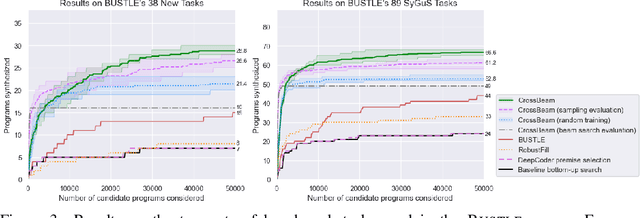
Many approaches to program synthesis perform a search within an enormous space of programs to find one that satisfies a given specification. Prior works have used neural models to guide combinatorial search algorithms, but such approaches still explore a huge portion of the search space and quickly become intractable as the size of the desired program increases. To tame the search space blowup, we propose training a neural model to learn a hands-on search policy for bottom-up synthesis, instead of relying on a combinatorial search algorithm. Our approach, called CrossBeam, uses the neural model to choose how to combine previously-explored programs into new programs, taking into account the search history and partial program executions. Motivated by work in structured prediction on learning to search, CrossBeam is trained on-policy using data extracted from its own bottom-up searches on training tasks. We evaluate CrossBeam in two very different domains, string manipulation and logic programming. We observe that CrossBeam learns to search efficiently, exploring much smaller portions of the program space compared to the state-of-the-art.