 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHarnessing Vision Models for Time Series Analysis: A Survey
Feb 13, 2025



Time series analysis has witnessed the inspiring development from traditional autoregressive models, deep learning models, to recent Transformers and Large Language Models (LLMs). Efforts in leveraging vision models for time series analysis have also been made along the way but are less visible to the community due to the predominant research on sequence modeling in this domain. However, the discrepancy between continuous time series and the discrete token space of LLMs, and the challenges in explicitly modeling the correlations of variates in multivariate time series have shifted some research attentions to the equally successful Large Vision Models (LVMs) and Vision Language Models (VLMs). To fill the blank in the existing literature, this survey discusses the advantages of vision models over LLMs in time series analysis. It provides a comprehensive and in-depth overview of the existing methods, with dual views of detailed taxonomy that answer the key research questions including how to encode time series as images and how to model the imaged time series for various tasks. Additionally, we address the challenges in the pre- and post-processing steps involved in this framework and outline future directions to further advance time series analysis with vision models.
Language in the Flow of Time: Time-Series-Paired Texts Weaved into a Unified Temporal Narrative
Feb 13, 2025While many advances in time series models focus exclusively on numerical data, research on multimodal time series, particularly those involving contextual textual information commonly encountered in real-world scenarios, remains in its infancy. Consequently, effectively integrating the text modality remains challenging. In this work, we highlight an intuitive yet significant observation that has been overlooked by existing works: time-series-paired texts exhibit periodic properties that closely mirror those of the original time series. Building on this insight, we propose a novel framework, Texts as Time Series (TaTS), which considers the time-series-paired texts to be auxiliary variables of the time series. TaTS can be plugged into any existing numerical-only time series models and enable them to handle time series data with paired texts effectively. Through extensive experiments on both multimodal time series forecasting and imputation tasks across benchmark datasets with various existing time series models, we demonstrate that TaTS can enhance predictive performance and achieve outperformance without modifying model architectures.
SelfElicit: Your Language Model Secretly Knows Where is the Relevant Evidence
Feb 12, 2025



Providing Language Models (LMs) with relevant evidence in the context (either via retrieval or user-provided) can significantly improve their ability to provide factually correct grounded responses. However, recent studies have found that LMs often struggle to fully comprehend and utilize key evidence from the context, especially when it contains noise and irrelevant information - an issue common in real-world scenarios. To address this, we propose SelfElicit, an inference-time approach that helps LMs focus on key contextual evidence through self-guided explicit highlighting. By leveraging the inherent evidence-finding capabilities of LMs using the attention scores of deeper layers, our method automatically identifies and emphasizes key evidence within the input context, facilitating more accurate and factually grounded responses without additional training or iterative prompting. We demonstrate that SelfElicit brings consistent and significant improvement on multiple evidence-based QA tasks for various LM families while maintaining computational efficiency. Our code and documentation are available at https://github.com/ZhiningLiu1998/SelfElicit.
PyG-SSL: A Graph Self-Supervised Learning Toolkit
Dec 30, 2024



Graph Self-Supervised Learning (SSL) has emerged as a pivotal area of research in recent years. By engaging in pretext tasks to learn the intricate topological structures and properties of graphs using unlabeled data, these graph SSL models achieve enhanced performance, improved generalization, and heightened robustness. Despite the remarkable achievements of these graph SSL methods, their current implementation poses significant challenges for beginners and practitioners due to the complex nature of graph structures, inconsistent evaluation metrics, and concerns regarding reproducibility hinder further progress in this field. Recognizing the growing interest within the research community, there is an urgent need for a comprehensive, beginner-friendly, and accessible toolkit consisting of the most representative graph SSL algorithms. To address these challenges, we present a Graph SSL toolkit named PyG-SSL, which is built upon PyTorch and is compatible with various deep learning and scientific computing backends. Within the toolkit, we offer a unified framework encompassing dataset loading, hyper-parameter configuration, model training, and comprehensive performance evaluation for diverse downstream tasks. Moreover, we provide beginner-friendly tutorials and the best hyper-parameters of each graph SSL algorithm on different graph datasets, facilitating the reproduction of results. The GitHub repository of the library is https://github.com/iDEA-iSAIL-Lab-UIUC/pyg-ssl.
THeGCN: Temporal Heterophilic Graph Convolutional Network
Dec 21, 2024Graph Neural Networks (GNNs) have exhibited remarkable efficacy in diverse graph learning tasks, particularly on static homophilic graphs. Recent attention has pivoted towards more intricate structures, encompassing (1) static heterophilic graphs encountering the edge heterophily issue in the spatial domain and (2) event-based continuous graphs in the temporal domain. State-of-the-art (SOTA) has been concurrently addressing these two lines of work but tends to overlook the presence of heterophily in the temporal domain, constituting the temporal heterophily issue. Furthermore, we highlight that the edge heterophily issue and the temporal heterophily issue often co-exist in event-based continuous graphs, giving rise to the temporal edge heterophily challenge. To tackle this challenge, this paper first introduces the temporal edge heterophily measurement. Subsequently, we propose the Temporal Heterophilic Graph Convolutional Network (THeGCN), an innovative model that incorporates the low/high-pass graph signal filtering technique to accurately capture both edge (spatial) heterophily and temporal heterophily. Specifically, the THeGCN model consists of two key components: a sampler and an aggregator. The sampler selects events relevant to a node at a given moment. Then, the aggregator executes message-passing, encoding temporal information, node attributes, and edge attributes into node embeddings. Extensive experiments conducted on 5 real-world datasets validate the efficacy of THeGCN.
Transforming the Hybrid Cloud for Emerging AI Workloads
Nov 20, 2024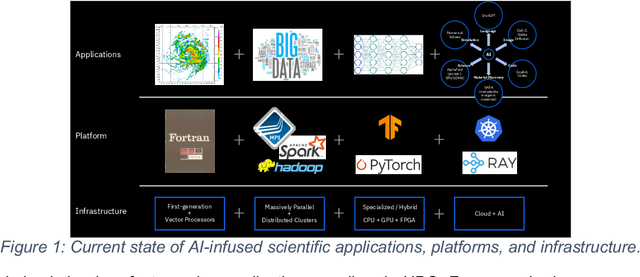
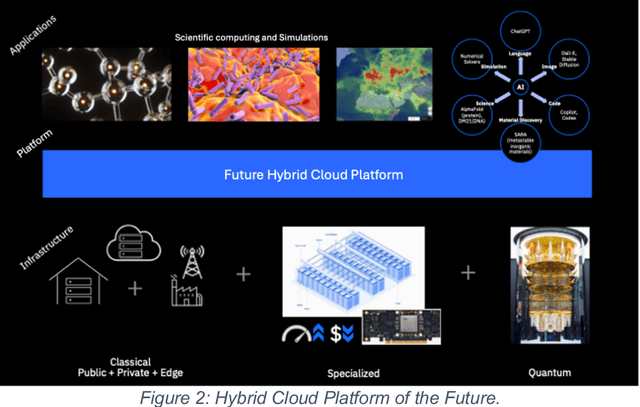
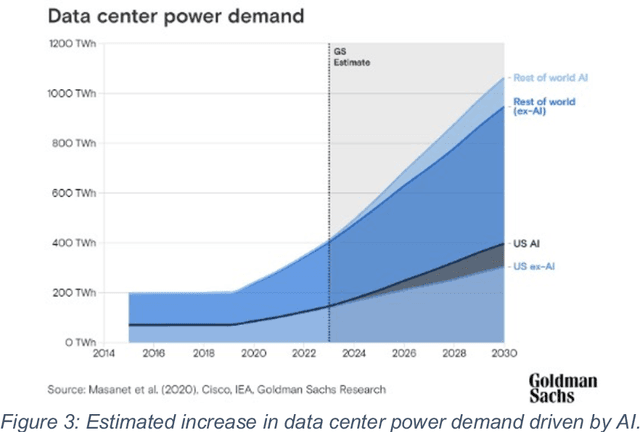
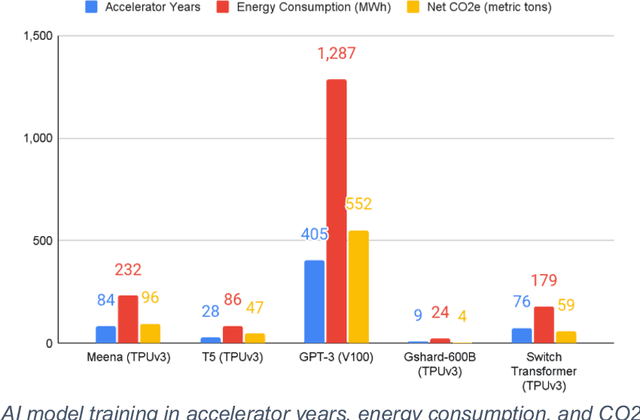
This white paper, developed through close collaboration between IBM Research and UIUC researchers within the IIDAI Institute, envisions transforming hybrid cloud systems to meet the growing complexity of AI workloads through innovative, full-stack co-design approaches, emphasizing usability, manageability, affordability, adaptability, efficiency, and scalability. By integrating cutting-edge technologies such as generative and agentic AI, cross-layer automation and optimization, unified control plane, and composable and adaptive system architecture, the proposed framework addresses critical challenges in energy efficiency, performance, and cost-effectiveness. Incorporating quantum computing as it matures will enable quantum-accelerated simulations for materials science, climate modeling, and other high-impact domains. Collaborative efforts between academia and industry are central to this vision, driving advancements in foundation models for material design and climate solutions, scalable multimodal data processing, and enhanced physics-based AI emulators for applications like weather forecasting and carbon sequestration. Research priorities include advancing AI agentic systems, LLM as an Abstraction (LLMaaA), AI model optimization and unified abstractions across heterogeneous infrastructure, end-to-end edge-cloud transformation, efficient programming model, middleware and platform, secure infrastructure, application-adaptive cloud systems, and new quantum-classical collaborative workflows. These ideas and solutions encompass both theoretical and practical research questions, requiring coordinated input and support from the research community. This joint initiative aims to establish hybrid clouds as secure, efficient, and sustainable platforms, fostering breakthroughs in AI-driven applications and scientific discovery across academia, industry, and society.
A Collaborative Ensemble Framework for CTR Prediction
Nov 20, 2024



Recent advances in foundation models have established scaling laws that enable the development of larger models to achieve enhanced performance, motivating extensive research into large-scale recommendation models. However, simply increasing the model size in recommendation systems, even with large amounts of data, does not always result in the expected performance improvements. In this paper, we propose a novel framework, Collaborative Ensemble Training Network (CETNet), to leverage multiple distinct models, each with its own embedding table, to capture unique feature interaction patterns. Unlike naive model scaling, our approach emphasizes diversity and collaboration through collaborative learning, where models iteratively refine their predictions. To dynamically balance contributions from each model, we introduce a confidence-based fusion mechanism using general softmax, where model confidence is computed via negation entropy. This design ensures that more confident models have a greater influence on the final prediction while benefiting from the complementary strengths of other models. We validate our framework on three public datasets (AmazonElectronics, TaobaoAds, and KuaiVideo) as well as a large-scale industrial dataset from Meta, demonstrating its superior performance over individual models and state-of-the-art baselines. Additionally, we conduct further experiments on the Criteo and Avazu datasets to compare our method with the multi-embedding paradigm. Our results show that our framework achieves comparable or better performance with smaller embedding sizes, offering a scalable and efficient solution for CTR prediction tasks.
InterFormer: Towards Effective Heterogeneous Interaction Learning for Click-Through Rate Prediction
Nov 15, 2024



Click-through rate (CTR) prediction, which predicts the probability of a user clicking an ad, is a fundamental task in recommender systems. The emergence of heterogeneous information, such as user profile and behavior sequences, depicts user interests from different aspects. A mutually beneficial integration of heterogeneous information is the cornerstone towards the success of CTR prediction. However, most of the existing methods suffer from two fundamental limitations, including (1) insufficient inter-mode interaction due to the unidirectional information flow between modes, and (2) aggressive information aggregation caused by early summarization, resulting in excessive information loss. To address the above limitations, we propose a novel module named InterFormer to learn heterogeneous information interaction in an interleaving style. To achieve better interaction learning, InterFormer enables bidirectional information flow for mutually beneficial learning across different modes. To avoid aggressive information aggregation, we retain complete information in each data mode and use a separate bridging arch for effective information selection and summarization. Our proposed InterFormer achieves state-of-the-art performance on three public datasets and a large-scale industrial dataset.
DeBaTeR: Denoising Bipartite Temporal Graph for Recommendation
Nov 14, 2024



Due to the difficulty of acquiring large-scale explicit user feedback, implicit feedback (e.g., clicks or other interactions) is widely applied as an alternative source of data, where user-item interactions can be modeled as a bipartite graph. Due to the noisy and biased nature of implicit real-world user-item interactions, identifying and rectifying noisy interactions are vital to enhance model performance and robustness. Previous works on purifying user-item interactions in collaborative filtering mainly focus on mining the correlation between user/item embeddings and noisy interactions, neglecting the benefit of temporal patterns in determining noisy interactions. Time information, while enhancing the model utility, also bears its natural advantage in helping to determine noisy edges, e.g., if someone usually watches horror movies at night and talk shows in the morning, a record of watching a horror movie in the morning is more likely to be noisy interaction. Armed with this observation, we introduce a simple yet effective mechanism for generating time-aware user/item embeddings and propose two strategies for denoising bipartite temporal graph in recommender systems (DeBaTeR): the first is through reweighting the adjacency matrix (DeBaTeR-A), where a reliability score is defined to reweight the edges through both soft assignment and hard assignment; the second is through reweighting the loss function (DeBaTeR-L), where weights are generated to reweight user-item samples in the losses. Extensive experiments have been conducted to demonstrate the efficacy of our methods and illustrate how time information indeed helps identifying noisy edges.
Ask, and it shall be given: Turing completeness of prompting
Nov 04, 2024Since the success of GPT, large language models (LLMs) have been revolutionizing machine learning and have initiated the so-called LLM prompting paradigm. In the era of LLMs, people train a single general-purpose LLM and provide the LLM with different prompts to perform different tasks. However, such empirical success largely lacks theoretical understanding. Here, we present the first theoretical study on the LLM prompting paradigm to the best of our knowledge. In this work, we show that prompting is in fact Turing-complete: there exists a finite-size Transformer such that for any computable function, there exists a corresponding prompt following which the Transformer computes the function. Furthermore, we show that even though we use only a single finite-size Transformer, it can still achieve nearly the same complexity bounds as that of the class of all unbounded-size Transformers. Overall, our result reveals that prompting can enable a single finite-size Transformer to be efficiently universal, which establishes a theoretical underpinning for prompt engineering in practice.