 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeALERT: Zero-shot LLM Jailbreak Detection via Internal Discrepancy Amplification
Jan 07, 2026Despite rich safety alignment strategies, large language models (LLMs) remain highly susceptible to jailbreak attacks, which compromise safety guardrails and pose serious security risks. Existing detection methods mainly detect jailbreak status relying on jailbreak templates present in the training data. However, few studies address the more realistic and challenging zero-shot jailbreak detection setting, where no jailbreak templates are available during training. This setting better reflects real-world scenarios where new attacks continually emerge and evolve. To address this challenge, we propose a layer-wise, module-wise, and token-wise amplification framework that progressively magnifies internal feature discrepancies between benign and jailbreak prompts. We uncover safety-relevant layers, identify specific modules that inherently encode zero-shot discriminative signals, and localize informative safety tokens. Building upon these insights, we introduce ALERT (Amplification-based Jailbreak Detector), an efficient and effective zero-shot jailbreak detector that introduces two independent yet complementary classifiers on amplified representations. Extensive experiments on three safety benchmarks demonstrate that ALERT achieves consistently strong zero-shot detection performance. Specifically, (i) across all datasets and attack strategies, ALERT reliably ranks among the top two methods, and (ii) it outperforms the second-best baseline by at least 10% in average Accuracy and F1-score, and sometimes by up to 40%.
Adversarial Bias: Data Poisoning Attacks on Fairness
Nov 11, 2025With the growing adoption of AI and machine learning systems in real-world applications, ensuring their fairness has become increasingly critical. The majority of the work in algorithmic fairness focus on assessing and improving the fairness of machine learning systems. There is relatively little research on fairness vulnerability, i.e., how an AI system's fairness can be intentionally compromised. In this work, we first provide a theoretical analysis demonstrating that a simple adversarial poisoning strategy is sufficient to induce maximally unfair behavior in naive Bayes classifiers. Our key idea is to strategically inject a small fraction of carefully crafted adversarial data points into the training set, biasing the model's decision boundary to disproportionately affect a protected group while preserving generalizable performance. To illustrate the practical effectiveness of our method, we conduct experiments across several benchmark datasets and models. We find that our attack significantly outperforms existing methods in degrading fairness metrics across multiple models and datasets, often achieving substantially higher levels of unfairness with a comparable or only slightly worse impact on accuracy. Notably, our method proves effective on a wide range of models, in contrast to prior work, demonstrating a robust and potent approach to compromising the fairness of machine learning systems.
Beyond Log Likelihood: Probability-Based Objectives for Supervised Fine-Tuning across the Model Capability Continuum
Oct 01, 2025Supervised fine-tuning (SFT) is the standard approach for post-training large language models (LLMs), yet it often shows limited generalization. We trace this limitation to its default training objective: negative log likelihood (NLL). While NLL is classically optimal when training from scratch, post-training operates in a different paradigm and could violate its optimality assumptions, where models already encode task-relevant priors and supervision can be long and noisy. To this end, we study a general family of probability-based objectives and characterize their effectiveness under different conditions. Through comprehensive experiments and extensive ablation studies across 7 model backbones, 14 benchmarks, and 3 domains, we uncover a critical dimension that governs objective behavior: the model-capability continuum. Near the model-strong end, prior-leaning objectives that downweight low-probability tokens (e.g., $-p$, $-p^{10}$, thresholded variants) consistently outperform NLL; toward the model-weak end, NLL dominates; in between, no single objective prevails. Our theoretical analysis further elucidates how objectives trade places across the continuum, providing a principled foundation for adapting objectives to model capability. Our code is available at https://github.com/GaotangLi/Beyond-Log-Likelihood.
Graph Homophily Booster: Rethinking the Role of Discrete Features on Heterophilic Graphs
Sep 16, 2025Graph neural networks (GNNs) have emerged as a powerful tool for modeling graph-structured data. However, existing GNNs often struggle with heterophilic graphs, where connected nodes tend to have dissimilar features or labels. While numerous methods have been proposed to address this challenge, they primarily focus on architectural designs without directly targeting the root cause of the heterophily problem. These approaches still perform even worse than the simplest MLPs on challenging heterophilic datasets. For instance, our experiments show that 21 latest GNNs still fall behind the MLP on the Actor dataset. This critical challenge calls for an innovative approach to addressing graph heterophily beyond architectural designs. To bridge this gap, we propose and study a new and unexplored paradigm: directly increasing the graph homophily via a carefully designed graph transformation. In this work, we present a simple yet effective framework called GRAPHITE to address graph heterophily. To the best of our knowledge, this work is the first method that explicitly transforms the graph to directly improve the graph homophily. Stemmed from the exact definition of homophily, our proposed GRAPHITE creates feature nodes to facilitate homophilic message passing between nodes that share similar features. Furthermore, we both theoretically and empirically show that our proposed GRAPHITE significantly increases the homophily of originally heterophilic graphs, with only a slight increase in the graph size. Extensive experiments on challenging datasets demonstrate that our proposed GRAPHITE significantly outperforms state-of-the-art methods on heterophilic graphs while achieving comparable accuracy with state-of-the-art methods on homophilic graphs.
Flow Matching Meets Biology and Life Science: A Survey
Jul 23, 2025Over the past decade, advances in generative modeling, such as generative adversarial networks, masked autoencoders, and diffusion models, have significantly transformed biological research and discovery, enabling breakthroughs in molecule design, protein generation, drug discovery, and beyond. At the same time, biological applications have served as valuable testbeds for evaluating the capabilities of generative models. Recently, flow matching has emerged as a powerful and efficient alternative to diffusion-based generative modeling, with growing interest in its application to problems in biology and life sciences. This paper presents the first comprehensive survey of recent developments in flow matching and its applications in biological domains. We begin by systematically reviewing the foundations and variants of flow matching, and then categorize its applications into three major areas: biological sequence modeling, molecule generation and design, and peptide and protein generation. For each, we provide an in-depth review of recent progress. We also summarize commonly used datasets and software tools, and conclude with a discussion of potential future directions. The corresponding curated resources are available at https://github.com/Violet24K/Awesome-Flow-Matching-Meets-Biology.
Saffron-1: Towards an Inference Scaling Paradigm for LLM Safety Assurance
Jun 06, 2025Existing safety assurance research has primarily focused on training-phase alignment to instill safe behaviors into LLMs. However, recent studies have exposed these methods' susceptibility to diverse jailbreak attacks. Concurrently, inference scaling has significantly advanced LLM reasoning capabilities but remains unexplored in the context of safety assurance. Addressing this gap, our work pioneers inference scaling for robust and effective LLM safety against emerging threats. We reveal that conventional inference scaling techniques, despite their success in reasoning tasks, perform poorly in safety contexts, even falling short of basic approaches like Best-of-N Sampling. We attribute this inefficiency to a newly identified challenge, the exploration--efficiency dilemma, arising from the high computational overhead associated with frequent process reward model (PRM) evaluations. To overcome this dilemma, we propose SAFFRON, a novel inference scaling paradigm tailored explicitly for safety assurance. Central to our approach is the introduction of a multifurcation reward model (MRM) that significantly reduces the required number of reward model evaluations. To operationalize this paradigm, we further propose: (i) a partial supervision training objective for MRM, (ii) a conservative exploration constraint to prevent out-of-distribution explorations, and (iii) a Trie-based key--value caching strategy that facilitates cache sharing across sequences during tree search. Extensive experiments validate the effectiveness of our method. Additionally, we publicly release our trained multifurcation reward model (Saffron-1) and the accompanying token-level safety reward dataset (Safety4M) to accelerate future research in LLM safety. Our code, model, and data are publicly available at https://github.com/q-rz/saffron , and our project homepage is at https://q-rz.github.io/p/saffron .
From Images to Signals: Are Large Vision Models Useful for Time Series Analysis?
May 29, 2025Transformer-based models have gained increasing attention in time series research, driving interest in Large Language Models (LLMs) and foundation models for time series analysis. As the field moves toward multi-modality, Large Vision Models (LVMs) are emerging as a promising direction. In the past, the effectiveness of Transformer and LLMs in time series has been debated. When it comes to LVMs, a similar question arises: are LVMs truely useful for time series analysis? To address it, we design and conduct the first principled study involving 4 LVMs, 8 imaging methods, 18 datasets and 26 baselines across both high-level (classification) and low-level (forecasting) tasks, with extensive ablation analysis. Our findings indicate LVMs are indeed useful for time series classification but face challenges in forecasting. Although effective, the contemporary best LVM forecasters are limited to specific types of LVMs and imaging methods, exhibit a bias toward forecasting periods, and have limited ability to utilize long look-back windows. We hope our findings could serve as a cornerstone for future research on LVM- and multimodal-based solutions to different time series tasks.
PLANETALIGN: A Comprehensive Python Library for Benchmarking Network Alignment
May 27, 2025


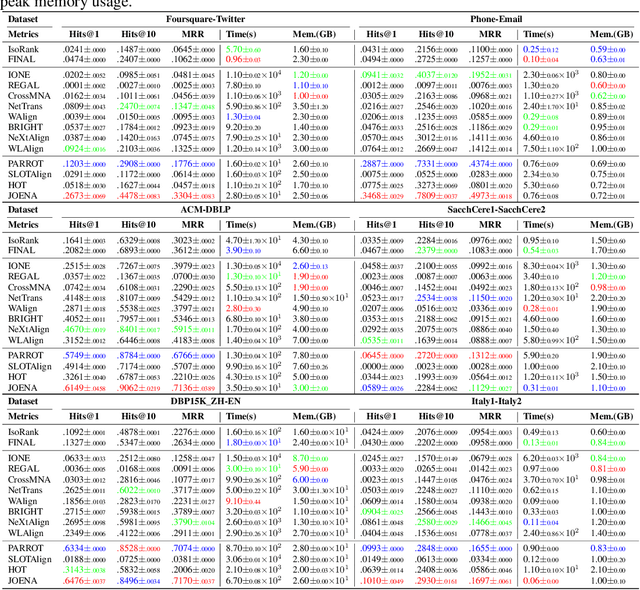
Network alignment (NA) aims to identify node correspondence across different networks and serves as a critical cornerstone behind various downstream multi-network learning tasks. Despite growing research in NA, there lacks a comprehensive library that facilitates the systematic development and benchmarking of NA methods. In this work, we introduce PLANETALIGN, a comprehensive Python library for network alignment that features a rich collection of built-in datasets, methods, and evaluation pipelines with easy-to-use APIs. Specifically, PLANETALIGN integrates 18 datasets and 14 NA methods with extensible APIs for easy use and development of NA methods. Our standardized evaluation pipeline encompasses a wide range of metrics, enabling a systematic assessment of the effectiveness, scalability, and robustness of NA methods. Through extensive comparative studies, we reveal practical insights into the strengths and limitations of existing NA methods. We hope that PLANETALIGN can foster a deeper understanding of the NA problem and facilitate the development and benchmarking of more effective, scalable, and robust methods in the future. The source code of PLANETALIGN is available at https://github.com/yq-leo/PlanetAlign.
Breaking Silos: Adaptive Model Fusion Unlocks Better Time Series Forecasting
May 24, 2025Time-series forecasting plays a critical role in many real-world applications. Although increasingly powerful models have been developed and achieved superior results on benchmark datasets, through a fine-grained sample-level inspection, we find that (i) no single model consistently outperforms others across different test samples, but instead (ii) each model excels in specific cases. These findings prompt us to explore how to adaptively leverage the distinct strengths of various forecasting models for different samples. We introduce TimeFuse, a framework for collective time-series forecasting with sample-level adaptive fusion of heterogeneous models. TimeFuse utilizes meta-features to characterize input time series and trains a learnable fusor to predict optimal model fusion weights for any given input. The fusor can leverage samples from diverse datasets for joint training, allowing it to adapt to a wide variety of temporal patterns and thus generalize to new inputs, even from unseen datasets. Extensive experiments demonstrate the effectiveness of TimeFuse in various long-/short-term forecasting tasks, achieving near-universal improvement over the state-of-the-art individual models. Code is available at https://github.com/ZhiningLiu1998/TimeFuse.
CLIMB: Class-imbalanced Learning Benchmark on Tabular Data
May 23, 2025Class-imbalanced learning (CIL) on tabular data is important in many real-world applications where the minority class holds the critical but rare outcomes. In this paper, we present CLIMB, a comprehensive benchmark for class-imbalanced learning on tabular data. CLIMB includes 73 real-world datasets across diverse domains and imbalance levels, along with unified implementations of 29 representative CIL algorithms. Built on a high-quality open-source Python package with unified API designs, detailed documentation, and rigorous code quality controls, CLIMB supports easy implementation and comparison between different CIL algorithms. Through extensive experiments, we provide practical insights on method accuracy and efficiency, highlighting the limitations of naive rebalancing, the effectiveness of ensembles, and the importance of data quality. Our code, documentation, and examples are available at https://github.com/ZhiningLiu1998/imbalanced-ensemble.