 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Pixels to Words -- Towards Native One-Vision Models at Scale
May 27, 2026Current vision-language models (VLMs) typically stitch together separate image encoders and language decoders via multi-stage alignment, a modular framework that inevitably fragments pixel-level signals across frames and scatters early pixel-word interactions. In parallel, native VLMs, despite impressive performance on single images, remain largely unexplored in multi-image, video understanding, and spatial intelligence. Hence, we introduce NEO-ov, a native foundation model that learns cross-frame and pixel-word correspondence end-to-end, without any external encoders, auxiliary adapters, or post-hoc fusion. By eliminating module boundaries entirely, NEO-ov enables fine-grained and unified spatiotemporal modeling to emerge natively inside the model. Notably, NEO-ov largely narrows the gap to modular counterparts while excelling at fine-grained visual perception, validating that native "one-vision" architectures are not only feasible but competitive at scale. Beyond empirical performance, we unveil systematic architectural analyses and detailed training recipes to facilitate subsequent native multimodal modeling. Our code and models are publicly available at: https://github.com/EvolvingLMMs-Lab/NEO.
AnchorSeg: Language Grounded Query Banks for Reasoning Segmentation
Apr 22, 2026Reasoning segmentation requires models to ground complex, implicit textual queries into precise pixel-level masks. Existing approaches rely on a single segmentation token $\texttt{<SEG>}$, whose hidden state implicitly encodes both semantic reasoning and spatial localization, limiting the model's ability to explicitly disentangle what to segment from where to segment. We introduce AnchorSeg, which reformulates reasoning segmentation as a structured conditional generation process over image tokens, conditioned on language grounded query banks. Instead of compressing all semantic reasoning and spatial localization into a single embedding, AnchorSeg constructs an ordered sequence of query banks: latent reasoning tokens that capture intermediate semantic states, and a segmentation anchor token that provides explicit spatial grounding. We model spatial conditioning as a factorized distribution over image tokens, where the anchor query determines localization signals while contextual queries provide semantic modulation. To bridge token-level predictions and pixel-level supervision, we propose Token--Mask Cycle Consistency (TMCC), a bidirectional training objective that enforces alignment across resolutions. By explicitly decoupling spatial grounding from semantic reasoning through structured language grounded query banks, AnchorSeg achieves state-of-the-art results on ReasonSeg test set (67.7\% gIoU and 68.1\% cIoU). All code and models are publicly available at https://github.com/rui-qian/AnchorSeg.
NeuroLoRA: Context-Aware Neuromodulation for Parameter-Efficient Multi-Task Adaptation
Mar 12, 2026Parameter-Efficient Fine-Tuning (PEFT) techniques, particularly Low-Rank Adaptation (LoRA), have become essential for adapting Large Language Models (LLMs) to downstream tasks. While the recent FlyLoRA framework successfully leverages bio-inspired sparse random projections to mitigate parameter interference, it relies on a static, magnitude-based routing mechanism that is agnostic to input context. In this paper, we propose NeuroLoRA, a novel Mixture-of-Experts (MoE) based LoRA framework inspired by biological neuromodulation -- the dynamic regulation of neuronal excitability based on context. NeuroLoRA retains the computational efficiency of frozen random projections while introducing a lightweight, learnable neuromodulation gate that contextually rescales the projection space prior to expert selection. We further propose a Contrastive Orthogonality Loss to explicitly enforce separation between expert subspaces, enhancing both task decoupling and continual learning capacity. Extensive experiments on MMLU, GSM8K, and ScienceQA demonstrate that NeuroLoRA consistently outperforms FlyLoRA and other strong baselines across single-task adaptation, multi-task model merging, and sequential continual learning scenarios, while maintaining comparable parameter efficiency.
AmbiBench: Benchmarking Mobile GUI Agents Beyond One-Shot Instructions in the Wild
Feb 12, 2026Benchmarks are paramount for gauging progress in the domain of Mobile GUI Agents. In practical scenarios, users frequently fail to articulate precise directives containing full task details at the onset, and their expressions are typically ambiguous. Consequently, agents are required to converge on the user's true intent via active clarification and interaction during execution. However, existing benchmarks predominantly operate under the idealized assumption that user-issued instructions are complete and unequivocal. This paradigm focuses exclusively on assessing single-turn execution while overlooking the alignment capability of the agent. To address this limitation, we introduce AmbiBench, the first benchmark incorporating a taxonomy of instruction clarity to shift evaluation from unidirectional instruction following to bidirectional intent alignment. Grounded in Cognitive Gap theory, we propose a taxonomy of four clarity levels: Detailed, Standard, Incomplete, and Ambiguous. We construct a rigorous dataset of 240 ecologically valid tasks across 25 applications, subject to strict review protocols. Furthermore, targeting evaluation in dynamic environments, we develop MUSE (Mobile User Satisfaction Evaluator), an automated framework utilizing an MLLM-as-a-judge multi-agent architecture. MUSE performs fine-grained auditing across three dimensions: Outcome Effectiveness, Execution Quality, and Interaction Quality. Empirical results on AmbiBench reveal the performance boundaries of SoTA agents across different clarity levels, quantify the gains derived from active interaction, and validate the strong correlation between MUSE and human judgment. This work redefines evaluation standards, laying the foundation for next-generation agents capable of truly understanding user intent.
Confounding Robust Continuous Control via Automatic Reward Shaping
Feb 10, 2026Reward shaping has been applied widely to accelerate Reinforcement Learning (RL) agents' training. However, a principled way of designing effective reward shaping functions, especially for complex continuous control problems, remains largely under-explained. In this work, we propose to automatically learn a reward shaping function for continuous control problems from offline datasets, potentially contaminated by unobserved confounding variables. Specifically, our method builds upon the recently proposed causal Bellman equation to learn a tight upper bound on the optimal state values, which is then used as the potentials in the Potential-Based Reward Shaping (PBRS) framework. Our proposed reward shaping algorithm is tested with Soft-Actor-Critic (SAC) on multiple commonly used continuous control benchmarks and exhibits strong performance guarantees under unobserved confounders. More broadly, our work marks a solid first step towards confounding robust continuous control from a causal perspective. Code for training our reward shaping functions can be found at https://github.com/mateojuliani/confounding_robust_cont_control.
DR.Experts: Differential Refinement of Distortion-Aware Experts for Blind Image Quality Assessment
Feb 10, 2026Blind Image Quality Assessment, aiming to replicate human perception of visual quality without reference, plays a key role in vision tasks, yet existing models often fail to effectively capture subtle distortion cues, leading to a misalignment with human subjective judgments. We identify that the root cause of this limitation lies in the lack of reliable distortion priors, as methods typically learn shallow relationships between unified image features and quality scores, resulting in their insensitive nature to distortions and thus limiting their performance. To address this, we introduce DR.Experts, a novel prior-driven BIQA framework designed to explicitly incorporate distortion priors, enabling a reliable quality assessment. DR.Experts begins by leveraging a degradation-aware vision-language model to obtain distortion-specific priors, which are further refined and enhanced by the proposed Distortion-Saliency Differential Module through distinguishing them from semantic attentions, thereby ensuring the genuine representations of distortions. The refined priors, along with semantics and bridging representation, are then fused by a proposed mixture-of-experts style module named the Dynamic Distortion Weighting Module. This mechanism weights each distortion-specific feature as per its perceptual impact, ensuring that the final quality prediction aligns with human perception. Extensive experiments conducted on five challenging BIQA benchmarks demonstrate the superiority of DR.Experts over current methods and showcase its excellence in terms of generalization and data efficiency.
Causal Flow Q-Learning for Robust Offline Reinforcement Learning
Feb 02, 2026Expressive policies based on flow-matching have been successfully applied in reinforcement learning (RL) more recently due to their ability to model complex action distributions from offline data. These algorithms build on standard policy gradients, which assume that there is no unmeasured confounding in the data. However, this condition does not necessarily hold for pixel-based demonstrations when a mismatch exists between the demonstrator's and the learner's sensory capabilities, leading to implicit confounding biases in offline data. We address the challenge by investigating the problem of confounded observations in offline RL from a causal perspective. We develop a novel causal offline RL objective that optimizes policies' worst-case performance that may arise due to confounding biases. Based on this new objective, we introduce a practical implementation that learns expressive flow-matching policies from confounded demonstrations, employing a deep discriminator to assess the discrepancy between the target policy and the nominal behavioral policy. Experiments across 25 pixel-based tasks demonstrate that our proposed confounding-robust augmentation procedure achieves a success rate 120\% that of confounding-unaware, state-of-the-art offline RL methods.
IFG: Internet-Scale Guidance for Functional Grasping Generation
Nov 12, 2025



Large Vision Models trained on internet-scale data have demonstrated strong capabilities in segmenting and semantically understanding object parts, even in cluttered, crowded scenes. However, while these models can direct a robot toward the general region of an object, they lack the geometric understanding required to precisely control dexterous robotic hands for 3D grasping. To overcome this, our key insight is to leverage simulation with a force-closure grasping generation pipeline that understands local geometries of the hand and object in the scene. Because this pipeline is slow and requires ground-truth observations, the resulting data is distilled into a diffusion model that operates in real-time on camera point clouds. By combining the global semantic understanding of internet-scale models with the geometric precision of a simulation-based locally-aware force-closure, \our achieves high-performance semantic grasping without any manually collected training data. For visualizations of this please visit our website at https://ifgrasping.github.io/
Solvaformer: an SE(3)-equivariant graph transformer for small molecule solubility prediction
Nov 12, 2025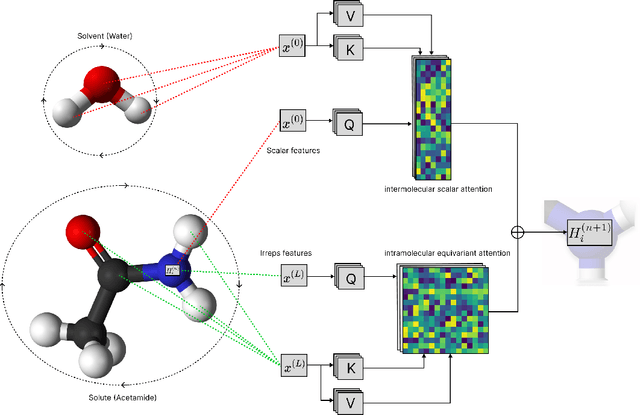
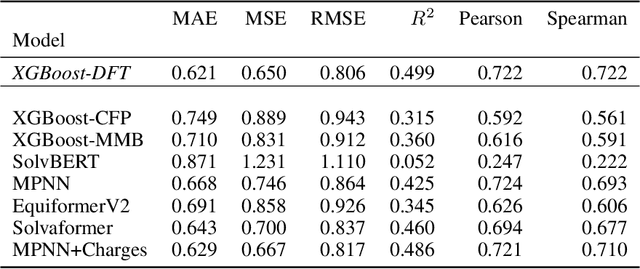
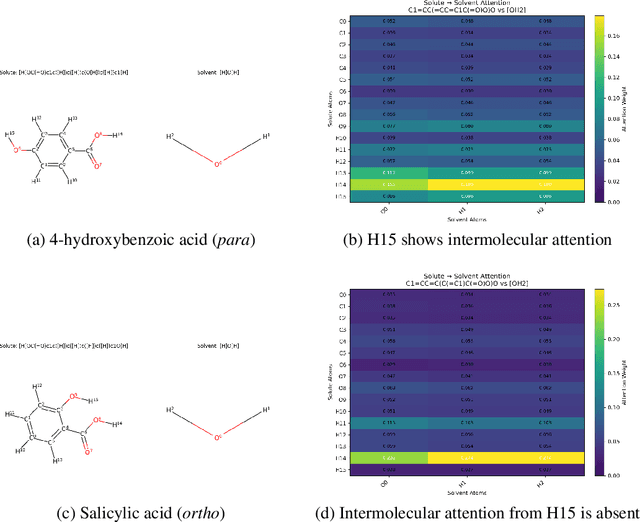

Accurate prediction of small molecule solubility using material-sparing approaches is critical for accelerating synthesis and process optimization, yet experimental measurement is costly and many learning approaches either depend on quantumderived descriptors or offer limited interpretability. We introduce Solvaformer, a geometry-aware graph transformer that models solutions as multiple molecules with independent SE(3) symmetries. The architecture combines intramolecular SE(3)-equivariant attention with intermolecular scalar attention, enabling cross-molecular communication without imposing spurious relative geometry. We train Solvaformer in a multi-task setting to predict both solubility (log S) and solvation free energy, using an alternating-batch regimen that trains on quantum-mechanical data (CombiSolv-QM) and on experimental measurements (BigSolDB 2.0). Solvaformer attains the strongest overall performance among the learned models and approaches a DFT-assisted gradient-boosting baseline, while outperforming an EquiformerV2 ablation and sequence-based alternatives. In addition, token-level attention produces chemically coherent attributions: case studies recover known intra- vs. inter-molecular hydrogen-bonding patterns that govern solubility differences in positional isomers. Taken together, Solvaformer provides an accurate, scalable, and interpretable approach to solution-phase property prediction by uniting geometric inductive bias with a mixed dataset training strategy on complementary computational and experimental data.
From Pixels to Words -- Towards Native Vision-Language Primitives at Scale
Oct 16, 2025The edifice of native Vision-Language Models (VLMs) has emerged as a rising contender to typical modular VLMs, shaped by evolving model architectures and training paradigms. Yet, two lingering clouds cast shadows over its widespread exploration and promotion: (-) What fundamental constraints set native VLMs apart from modular ones, and to what extent can these barriers be overcome? (-) How to make research in native VLMs more accessible and democratized, thereby accelerating progress in the field. In this paper, we clarify these challenges and outline guiding principles for constructing native VLMs. Specifically, one native VLM primitive should: (i) effectively align pixel and word representations within a shared semantic space; (ii) seamlessly integrate the strengths of formerly separate vision and language modules; (iii) inherently embody various cross-modal properties that support unified vision-language encoding, aligning, and reasoning. Hence, we launch NEO, a novel family of native VLMs built from first principles, capable of rivaling top-tier modular counterparts across diverse real-world scenarios. With only 390M image-text examples, NEO efficiently develops visual perception from scratch while mitigating vision-language conflicts inside a dense and monolithic model crafted from our elaborate primitives. We position NEO as a cornerstone for scalable and powerful native VLMs, paired with a rich set of reusable components that foster a cost-effective and extensible ecosystem. Our code and models are publicly available at: https://github.com/EvolvingLMMs-Lab/NEO.