 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWildDoc: How Far Are We from Achieving Comprehensive and Robust Document Understanding in the Wild?
May 16, 2025The rapid advancements in Multimodal Large Language Models (MLLMs) have significantly enhanced capabilities in Document Understanding. However, prevailing benchmarks like DocVQA and ChartQA predominantly comprise \textit{scanned or digital} documents, inadequately reflecting the intricate challenges posed by diverse real-world scenarios, such as variable illumination and physical distortions. This paper introduces WildDoc, the inaugural benchmark designed specifically for assessing document understanding in natural environments. WildDoc incorporates a diverse set of manually captured document images reflecting real-world conditions and leverages document sources from established benchmarks to facilitate comprehensive comparisons with digital or scanned documents. Further, to rigorously evaluate model robustness, each document is captured four times under different conditions. Evaluations of state-of-the-art MLLMs on WildDoc expose substantial performance declines and underscore the models' inadequate robustness compared to traditional benchmarks, highlighting the unique challenges posed by real-world document understanding. Our project homepage is available at https://bytedance.github.io/WildDoc.
Fine-Tuning without Performance Degradation
May 01, 2025



Fine-tuning policies learned offline remains a major challenge in application domains. Monotonic performance improvement during \emph{fine-tuning} is often challenging, as agents typically experience performance degradation at the early fine-tuning stage. The community has identified multiple difficulties in fine-tuning a learned network online, however, the majority of progress has focused on improving learning efficiency during fine-tuning. In practice, this comes at a serious cost during fine-tuning: initially, agent performance degrades as the agent explores and effectively overrides the policy learned offline. We show across a range of settings, many offline-to-online algorithms exhibit either (1) performance degradation or (2) slow learning (sometimes effectively no improvement) during fine-tuning. We introduce a new fine-tuning algorithm, based on an algorithm called Jump Start, that gradually allows more exploration based on online estimates of performance. Empirically, this approach achieves fast fine-tuning and significantly reduces performance degradations compared with existing algorithms designed to do the same.
PRISM: Projection-based Reward Integration for Scene-Aware Real-to-Sim-to-Real Transfer with Few Demonstrations
Apr 29, 2025Learning from few demonstrations to develop policies robust to variations in robot initial positions and object poses is a problem of significant practical interest in robotics. Compared to imitation learning, which often struggles to generalize from limited samples, reinforcement learning (RL) can autonomously explore to obtain robust behaviors. Training RL agents through direct interaction with the real world is often impractical and unsafe, while building simulation environments requires extensive manual effort, such as designing scenes and crafting task-specific reward functions. To address these challenges, we propose an integrated real-to-sim-to-real pipeline that constructs simulation environments based on expert demonstrations by identifying scene objects from images and retrieving their corresponding 3D models from existing libraries. We introduce a projection-based reward model for RL policy training that is supervised by a vision-language model (VLM) using human-guided object projection relationships as prompts, with the policy further fine-tuned using expert demonstrations. In general, our work focuses on the construction of simulation environments and RL-based policy training, ultimately enabling the deployment of reliable robotic control policies in real-world scenarios.
Time's Up! An Empirical Study of LLM Reasoning Ability Under Output Length Constraint
Apr 22, 2025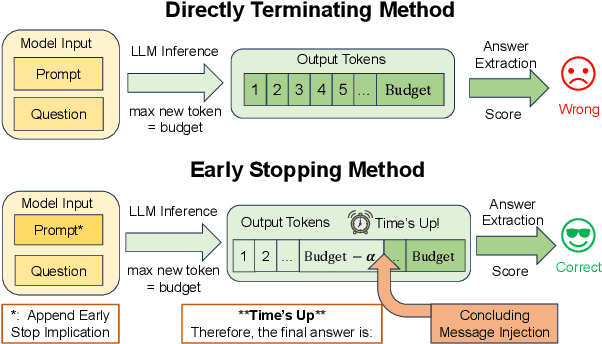
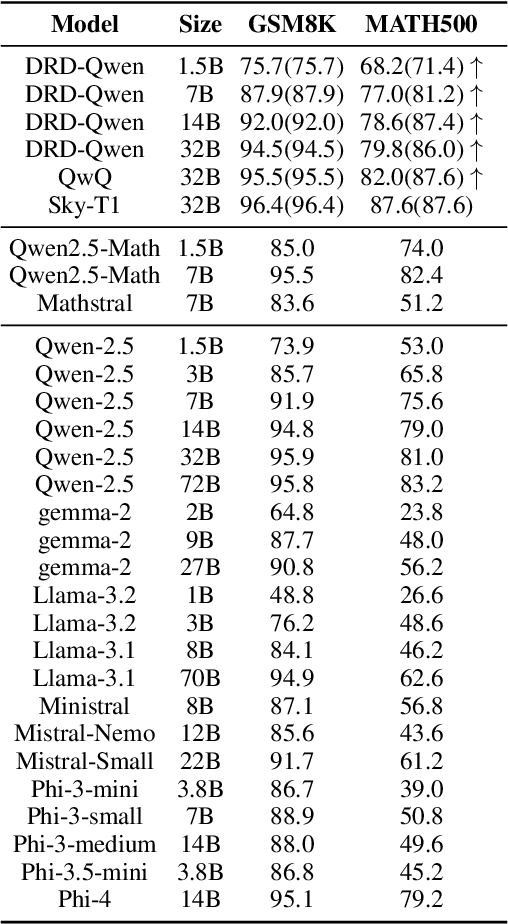
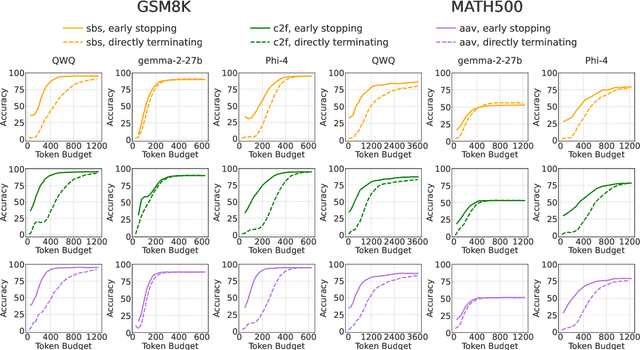
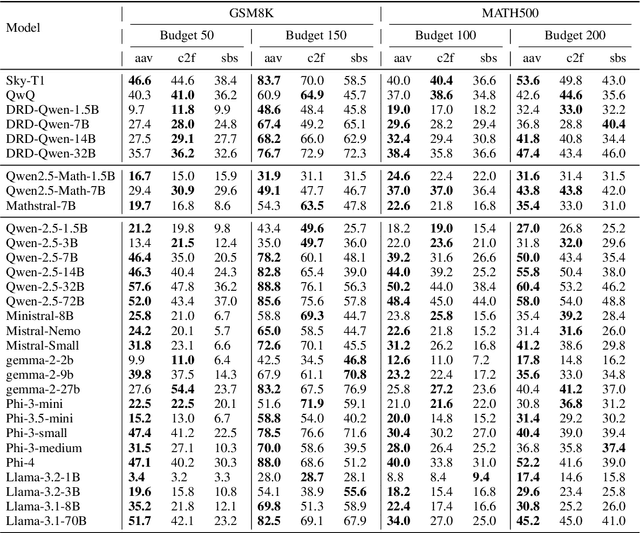
Recent work has demonstrated the remarkable potential of Large Language Models (LLMs) in test-time scaling. By making the models think before answering, they are able to achieve much higher accuracy with extra inference computation. However, in many real-world scenarios, models are used under time constraints, where an answer should be given to the user within a certain output length. It is unclear whether and how the reasoning abilities of LLMs remain effective under such constraints. We take a first look at this problem by conducting an in-depth empirical study. Specifically, we test more than 25 LLMs on common reasoning datasets under a wide range of output length budgets, and we analyze the correlation between the inference accuracy and various properties including model type, model size, prompt style, etc. We also consider the mappings between the token budgets and the actual on-device latency budgets. The results have demonstrated several interesting findings regarding the budget-aware LLM reasoning that differ from the unconstrained situation, e.g. the optimal choices of model sizes and prompts change under different budgets. These findings offer practical guidance for users to deploy LLMs under real-world latency constraints.
Vision-Centric Representation-Efficient Fine-Tuning for Robust Universal Foreground Segmentation
Apr 20, 2025Foreground segmentation is crucial for scene understanding, yet parameter-efficient fine-tuning (PEFT) of vision foundation models (VFMs) often fails in complex scenarios, such as camouflage and infrared imagery. We attribute this challenge to the inherent texture bias in VFMs, which is exacerbated during fine-tuning and limits generalization in texture-sparse environments. To address this, we propose Ladder Shape-bias Representation Side-tuning (LSR-ST), a lightweight PEFT framework that enhances model robustness by introducing shape-biased inductive priors. LSR-ST captures shape-aware features using a simple HDConv Block, which integrates large-kernel attention and residual learning. The method satisfies three key conditions for inducing shape bias: large receptive fields, multi-order feature interactions, and sparse connectivity. Our analysis reveals that these improvements stem from representation efficiency-the ability to extract task-relevant, structurally grounded features while minimizing redundancy. We formalize this concept via Information Bottleneck theory and advocate for it as a key PEFT objective. Unlike traditional NLP paradigms that focus on optimizing parameters and memory, visual tasks require models that extract task-defined semantics, rather than just relying on pre-encoded features. This shift enables our approach to move beyond conventional trade-offs, offering more robust and generalizable solutions for vision tasks. With minimal changes to SAM2-UNet, LSR-ST achieves consistent improvements across 17 datasets and 6 tasks using only 4.719M trainable parameters. These results highlight the potential of representation efficiency for robust and adaptable VFMs within complex visual environments.
Vision as LoRA
Mar 26, 2025We introduce Vision as LoRA (VoRA), a novel paradigm for transforming an LLM into an MLLM. Unlike prevalent MLLM architectures that rely on external vision modules for vision encoding, VoRA internalizes visual capabilities by integrating vision-specific LoRA layers directly into the LLM. This design allows the added parameters to be seamlessly merged into the LLM during inference, eliminating structural complexity and minimizing computational overhead. Moreover, inheriting the LLM's ability of handling flexible context, VoRA can process inputs at arbitrary resolutions. To further strengthen VoRA's visual capabilities, we introduce a block-wise distillation method that transfers visual priors from a pre-trained ViT into the LoRA layers, effectively accelerating training by injecting visual knowledge. Additionally, we apply bi-directional attention masks to better capture the context information of an image. We successfully demonstrate that with additional pre-training data, VoRA can perform comparably with conventional encode-based MLLMs. All training data, codes, and model weights will be released at https://github.com/Hon-Wong/VoRA.
The Emperor's New Clothes in Benchmarking? A Rigorous Examination of Mitigation Strategies for LLM Benchmark Data Contamination
Mar 20, 2025



Benchmark Data Contamination (BDC)-the inclusion of benchmark testing samples in the training set-has raised increasing concerns in Large Language Model (LLM) evaluation, leading to falsely inflated performance estimates and undermining evaluation reliability. To address this, researchers have proposed various mitigation strategies to update existing benchmarks, including modifying original questions or generating new ones based on them. However, a rigorous examination of the effectiveness of these mitigation strategies remains lacking. In this paper, we design a systematic and controlled pipeline along with two novel metrics-fidelity and contamination resistance-to provide a fine-grained and comprehensive assessment of existing BDC mitigation strategies. Previous assessment methods, such as accuracy drop and accuracy matching, focus solely on aggregate accuracy, often leading to incomplete or misleading conclusions. Our metrics address this limitation by emphasizing question-level evaluation result matching. Extensive experiments with 10 LLMs, 5 benchmarks, 20 BDC mitigation strategies, and 2 contamination scenarios reveal that no existing strategy significantly improves resistance over the vanilla case (i.e., no benchmark update) across all benchmarks, and none effectively balances fidelity and contamination resistance. These findings underscore the urgent need for designing more effective BDC mitigation strategies. Our code repository is available at https://github.com/ASTRAL-Group/BDC_mitigation_assessment.
Bench2FreeAD: A Benchmark for Vision-based End-to-end Navigation in Unstructured Robotic Environments
Mar 15, 2025Most current end-to-end (E2E) autonomous driving algorithms are built on standard vehicles in structured transportation scenarios, lacking exploration of robot navigation for unstructured scenarios such as auxiliary roads, campus roads, and indoor settings. This paper investigates E2E robot navigation in unstructured road environments. First, we introduce two data collection pipelines - one for real-world robot data and another for synthetic data generated using the Isaac Sim simulator, which together produce an unstructured robotics navigation dataset -- FreeWorld Dataset. Second, we fine-tuned an efficient E2E autonomous driving model -- VAD -- using our datasets to validate the performance and adaptability of E2E autonomous driving models in these environments. Results demonstrate that fine-tuning through our datasets significantly enhances the navigation potential of E2E autonomous driving models in unstructured robotic environments. Thus, this paper presents the first dataset targeting E2E robot navigation tasks in unstructured scenarios, and provides a benchmark based on vision-based E2E autonomous driving algorithms to facilitate the development of E2E navigation technology for logistics and service robots. The project is available on Github.
EVE: Towards End-to-End Video Subtitle Extraction with Vision-Language Models
Mar 06, 2025The advent of Large Vision-Language Models (LVLMs) has advanced the video-based tasks, such as video captioning and video understanding. Some previous research indicates that taking texts in videos as input can further improve the performance of video understanding. As a type of indispensable information in short videos or movies, subtitles can assist LVLMs to better understand videos. Most existing methods for video subtitle extraction are based on a multi-stage framework, handling each frame independently. They can hardly exploit the temporal information of videos. Although some LVLMs exhibit the robust OCR capability, predicting accurate timestamps for subtitle texts is still challenging. In this paper, we propose an End-to-end Video Subtitle Extraction method, called EVE, which consists of three modules: a vision encoder, an adapter module, and a large language model. To effectively compress the visual tokens from the vision encoder, we propose a novel adapter InterleavedVT to interleave two modalities. It contains a visual compressor and a textual region compressor. The proposed InterleavedVT exploits both the merits of average pooling and Q-Former in token compression. Taking the temporal information of videos into account, we introduce a sliding-window mechanism in the textual region compressor. To benchmark the video subtitle extraction task, we propose a large dataset ViSa including 2.5M videos. Extensive experiments on ViSa demonstrate that the proposed EVE can outperform existing open-sourced tools and LVLMs.
Low-Level Matters: An Efficient Hybrid Architecture for Robust Multi-frame Infrared Small Target Detection
Mar 04, 2025Multi-frame infrared small target detection (IRSTD) plays a crucial role in low-altitude and maritime surveillance. The hybrid architecture combining CNNs and Transformers shows great promise for enhancing multi-frame IRSTD performance. In this paper, we propose LVNet, a simple yet powerful hybrid architecture that redefines low-level feature learning in hybrid frameworks for multi-frame IRSTD. Our key insight is that the standard linear patch embeddings in Vision Transformers are insufficient for capturing the scale-sensitive local features critical to infrared small targets. To address this limitation, we introduce a multi-scale CNN frontend that explicitly models local features by leveraging the local spatial bias of convolution. Additionally, we design a U-shaped video Transformer for multi-frame spatiotemporal context modeling, effectively capturing the motion characteristics of targets. Experiments on the publicly available datasets IRDST and NUDT-MIRSDT demonstrate that LVNet outperforms existing state-of-the-art methods. Notably, compared to the current best-performing method, LMAFormer, LVNet achieves an improvement of 5.63\% / 18.36\% in nIoU, while using only 1/221 of the parameters and 1/92 / 1/21 of the computational cost. Ablation studies further validate the importance of low-level representation learning in hybrid architectures. Our code and trained models are available at https://github.com/ZhihuaShen/LVNet.