 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuman-in-the-Loop Policy Optimization for Preference-Based Multi-Objective Reinforcement Learning
Jan 04, 2024



Multi-objective reinforcement learning (MORL) aims to find a set of high-performing and diverse policies that address trade-offs between multiple conflicting objectives. However, in practice, decision makers (DMs) often deploy only one or a limited number of trade-off policies. Providing too many diversified trade-off policies to the DM not only significantly increases their workload but also introduces noise in multi-criterion decision-making. With this in mind, we propose a human-in-the-loop policy optimization framework for preference-based MORL that interactively identifies policies of interest. Our method proactively learns the DM's implicit preference information without requiring any a priori knowledge, which is often unavailable in real-world black-box decision scenarios. The learned preference information is used to progressively guide policy optimization towards policies of interest. We evaluate our approach against three conventional MORL algorithms that do not consider preference information and four state-of-the-art preference-based MORL algorithms on two MORL environments for robot control and smart grid management. Experimental results fully demonstrate the effectiveness of our proposed method in comparison to the other peer algorithms.
LQ-LoRA: Low-rank Plus Quantized Matrix Decomposition for Efficient Language Model Finetuning
Nov 20, 2023



We propose a simple approach for memory-efficient adaptation of pretrained language models. Our approach uses an iterative algorithm to decompose each pretrained matrix into a high-precision low-rank component and a memory-efficient quantized component. During finetuning, the quantized component remains fixed and only the low-rank component is updated. We present an integer linear programming formulation of the quantization component which enables dynamic configuration of quantization parameters (e.g., bit-width, block size) for each matrix given an overall target memory budget. We further explore a data-aware version of the algorithm which uses an approximation of the Fisher information matrix to weight the reconstruction objective during matrix decomposition. Experiments on adapting RoBERTa and LLaMA-2 (7B and 70B) demonstrate that our low-rank plus quantized matrix decomposition approach (LQ-LoRA) outperforms strong QLoRA and GPTQ-LoRA baselines and moreover enables more aggressive quantization. For example, on the OpenAssistant benchmark LQ-LoRA is able to learn a 2.5-bit LLaMA-2 model that is competitive with a model finetuned with 4-bit QLoRA. When finetuned on a language modeling calibration dataset, LQ-LoRA can also be used for model compression; in this setting our 2.75-bit LLaMA-2-70B model (which has 2.85 bits on average when including the low-rank components and requires 27GB of GPU memory) is competitive with the original model in full precision.
Recouple Event Field via Probabilistic Bias for Event Extraction
May 19, 2023



Event Extraction (EE), aiming to identify and classify event triggers and arguments from event mentions, has benefited from pre-trained language models (PLMs). However, existing PLM-based methods ignore the information of trigger/argument fields, which is crucial for understanding event schemas. To this end, we propose a Probabilistic reCoupling model enhanced Event extraction framework (ProCE). Specifically, we first model the syntactic-related event fields as probabilistic biases, to clarify the event fields from ambiguous entanglement. Furthermore, considering multiple occurrences of the same triggers/arguments in EE, we explore probabilistic interaction strategies among multiple fields of the same triggers/arguments, to recouple the corresponding clarified distributions and capture more latent information fields. Experiments on EE datasets demonstrate the effectiveness and generalization of our proposed approach.
Federated Learning as Variational Inference: A Scalable Expectation Propagation Approach
Feb 08, 2023



The canonical formulation of federated learning treats it as a distributed optimization problem where the model parameters are optimized against a global loss function that decomposes across client loss functions. A recent alternative formulation instead treats federated learning as a distributed inference problem, where the goal is to infer a global posterior from partitioned client data (Al-Shedivat et al., 2021). This paper extends the inference view and describes a variational inference formulation of federated learning where the goal is to find a global variational posterior that well-approximates the true posterior. This naturally motivates an expectation propagation approach to federated learning (FedEP), where approximations to the global posterior are iteratively refined through probabilistic message-passing between the central server and the clients. We conduct an extensive empirical study across various algorithmic considerations and describe practical strategies for scaling up expectation propagation to the modern federated setting. We apply FedEP on standard federated learning benchmarks and find that it outperforms strong baselines in terms of both convergence speed and accuracy.
TencentPretrain: A Scalable and Flexible Toolkit for Pre-training Models of Different Modalities
Dec 13, 2022



Recently, the success of pre-training in text domain has been fully extended to vision, audio, and cross-modal scenarios. The proposed pre-training models of different modalities are showing a rising trend of homogeneity in their model structures, which brings the opportunity to implement different pre-training models within a uniform framework. In this paper, we present TencentPretrain, a toolkit supporting pre-training models of different modalities. The core feature of TencentPretrain is the modular design. The toolkit uniformly divides pre-training models into 5 components: embedding, encoder, target embedding, decoder, and target. As almost all of common modules are provided in each component, users can choose the desired modules from different components to build a complete pre-training model. The modular design enables users to efficiently reproduce existing pre-training models or build brand-new one. We test the toolkit on text, vision, and audio benchmarks and show that it can match the performance of the original implementations.
MPCFormer: fast, performant and private Transformer inference with MPC
Nov 02, 2022Enabling private inference is crucial for many cloud inference services that are based on Transformer models. However, existing private inference solutions for Transformers can increase the inference latency by more than 60x or significantly compromise the quality of inference results. In this paper, we design the framework MPCFORMER using secure multi-party computation (MPC) and Knowledge Distillation (KD). It can be used in tandem with many specifically designed MPC-friendly approximations and trained Transformer models. MPCFORMER significantly speeds up Transformer model inference in MPC settings while achieving similar ML performance to the input model. We evaluate MPCFORMER with various settings in MPC. On the IMDb dataset, we achieve similar performance to BERTBASE, while being 5.3x faster. On the GLUE benchmark, we achieve 97% performance of BERTBASE with a 2.2x speedup. We show that MPCFORMER remains effective with different trained Transformer weights such as ROBERTABASE and larger models including BERTLarge. In particular, we achieve similar performance to BERTLARGE, while being 5.93x faster on the IMDb dataset.
RLPrompt: Optimizing Discrete Text Prompts With Reinforcement Learning
May 25, 2022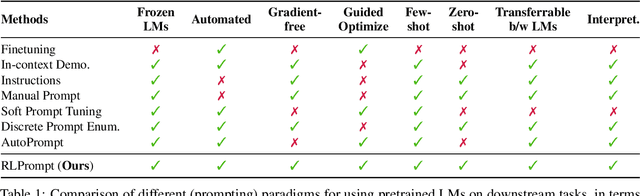
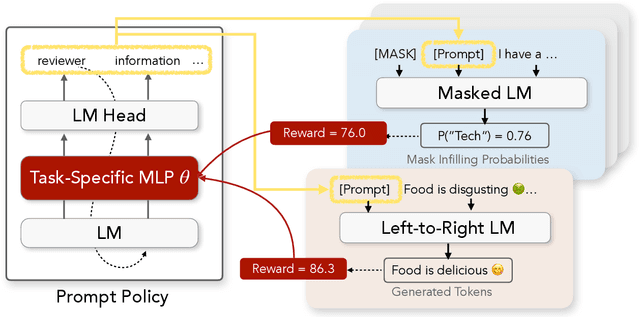
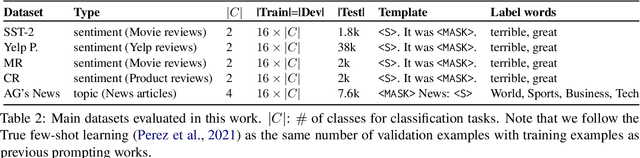
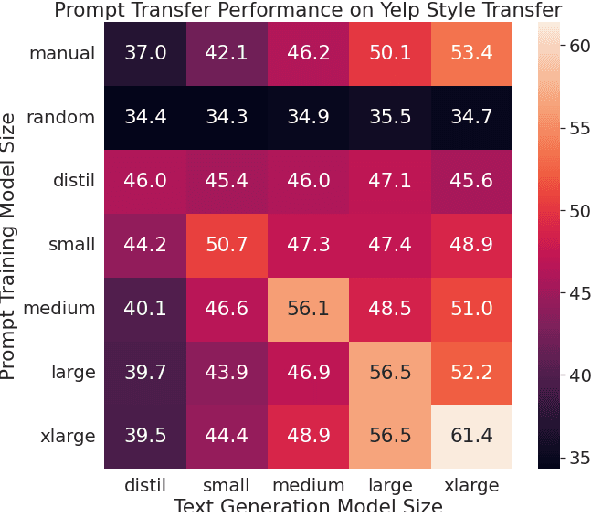
Prompting has shown impressive success in enabling large pretrained language models (LMs) to perform diverse NLP tasks, especially when only few downstream data are available. Automatically finding the optimal prompt for each task, however, is challenging. Most existing work resorts to tuning soft prompt (e.g., embeddings) which falls short of interpretability, reusability across LMs, and applicability when gradients are not accessible. Discrete prompt, on the other hand, is difficult to optimize, and is often created by "enumeration (e.g., paraphrasing)-then-selection" heuristics that do not explore the prompt space systematically. This paper proposes RLPrompt, an efficient discrete prompt optimization approach with reinforcement learning (RL). RLPrompt formulates a parameter-efficient policy network that generates the desired discrete prompt after training with reward. To overcome the complexity and stochasticity of reward signals by the large LM environment, we incorporate effective reward stabilization that substantially enhances the training efficiency. RLPrompt is flexibly applicable to different types of LMs, such as masked (e.g., BERT) and left-to-right models (e.g., GPTs), for both classification and generation tasks. Experiments on few-shot classification and unsupervised text style transfer show superior performance over a wide range of existing finetuning or prompting methods. Interestingly, the resulting optimized prompts are often ungrammatical gibberish text; and surprisingly, those gibberish prompts are transferrable between different LMs to retain significant performance, indicating LM prompting may not follow human language patterns.
Ligandformer: A Graph Neural Network for Predicting Compound Property with Robust Interpretation
Feb 24, 2022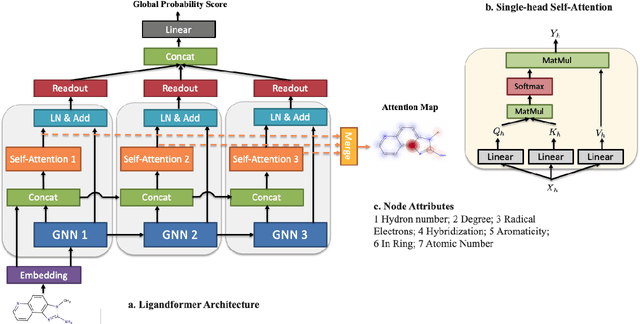

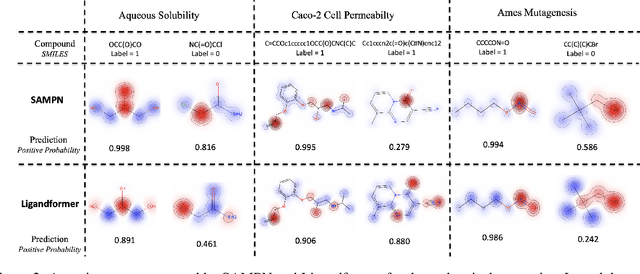
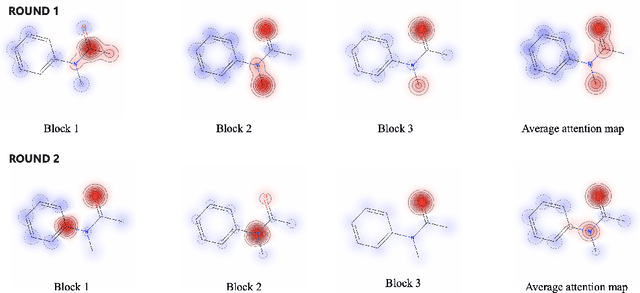
Robust and efficient interpretation of QSAR methods is quite useful to validate AI prediction rationales with subjective opinion (chemist or biologist expertise), understand sophisticated chemical or biological process mechanisms, and provide heuristic ideas for structure optimization in pharmaceutical industry. For this purpose, we construct a multi-layer self-attention based Graph Neural Network framework, namely Ligandformer, for predicting compound property with interpretation. Ligandformer integrates attention maps on compound structure from different network blocks. The integrated attention map reflects the machine's local interest on compound structure, and indicates the relationship between predicted compound property and its structure. This work mainly contributes to three aspects: 1. Ligandformer directly opens the black-box of deep learning methods, providing local prediction rationales on chemical structures. 2. Ligandformer gives robust prediction in different experimental rounds, overcoming the ubiquitous prediction instability of deep learning methods. 3. Ligandformer can be generalized to predict different chemical or biological properties with high performance. Furthermore, Ligandformer can simultaneously output specific property score and visible attention map on structure, which can support researchers to investigate chemical or biological property and optimize structure efficiently. Our framework outperforms over counterparts in terms of accuracy, robustness and generalization, and can be applied in complex system study.
Uncertainty Toolbox: an Open-Source Library for Assessing, Visualizing, and Improving Uncertainty Quantification
Sep 21, 2021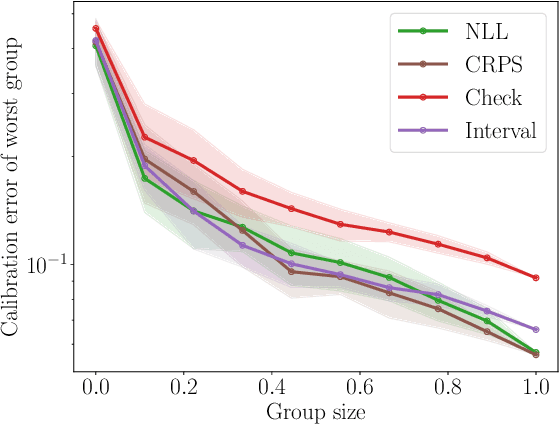
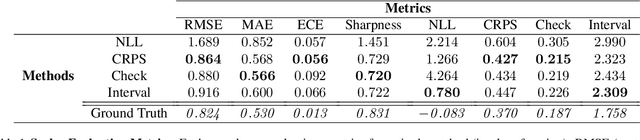
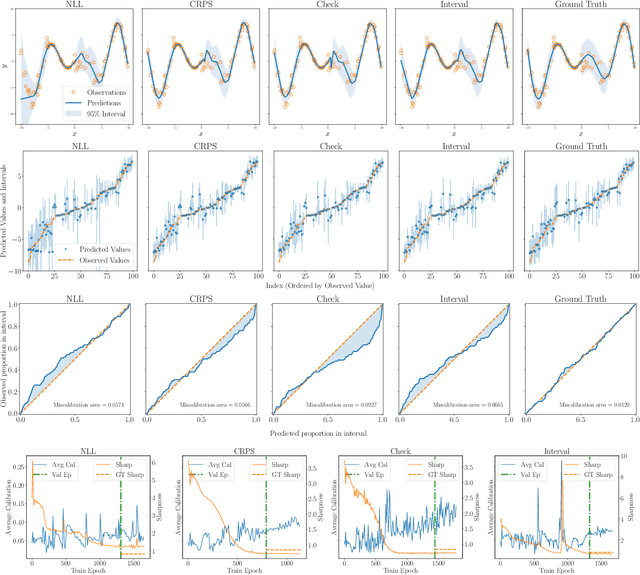
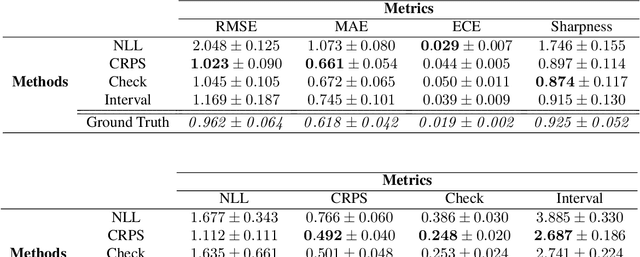
With increasing deployment of machine learning systems in various real-world tasks, there is a greater need for accurate quantification of predictive uncertainty. While the common goal in uncertainty quantification (UQ) in machine learning is to approximate the true distribution of the target data, many works in UQ tend to be disjoint in the evaluation metrics utilized, and disparate implementations for each metric lead to numerical results that are not directly comparable across different works. To address this, we introduce Uncertainty Toolbox, an open-source python library that helps to assess, visualize, and improve UQ. Uncertainty Toolbox additionally provides pedagogical resources, such as a glossary of key terms and an organized collection of key paper references. We hope that this toolbox is useful for accelerating and uniting research efforts in uncertainty in machine learning.
Text Generation with Efficient (Soft) Q-Learning
Jun 17, 2021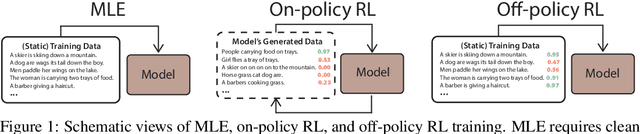
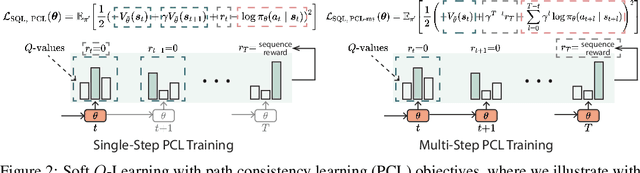
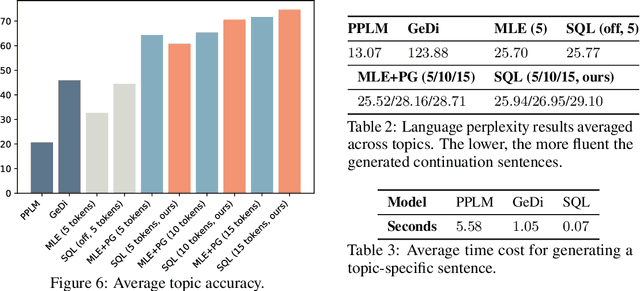
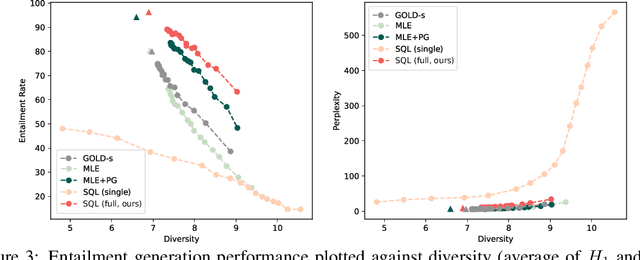
Maximum likelihood estimation (MLE) is the predominant algorithm for training text generation models. This paradigm relies on direct supervision examples, which is not applicable to many applications, such as generating adversarial attacks or generating prompts to control language models. Reinforcement learning (RL) on the other hand offers a more flexible solution by allowing users to plug in arbitrary task metrics as reward. Yet previous RL algorithms for text generation, such as policy gradient (on-policy RL) and Q-learning (off-policy RL), are often notoriously inefficient or unstable to train due to the large sequence space and the sparse reward received only at the end of sequences. In this paper, we introduce a new RL formulation for text generation from the soft Q-learning perspective. It further enables us to draw from the latest RL advances, such as path consistency learning, to combine the best of on-/off-policy updates, and learn effectively from sparse reward. We apply the approach to a wide range of tasks, including learning from noisy/negative examples, adversarial attacks, and prompt generation. Experiments show our approach consistently outperforms both task-specialized algorithms and the previous RL methods. On standard supervised tasks where MLE prevails, our approach also achieves competitive performance and stability by training text generation from scratch.