 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge Combination to Learn Rotated Detection Without Rotated Annotation
Apr 05, 2023



Rotated bounding boxes drastically reduce output ambiguity of elongated objects, making it superior to axis-aligned bounding boxes. Despite the effectiveness, rotated detectors are not widely employed. Annotating rotated bounding boxes is such a laborious process that they are not provided in many detection datasets where axis-aligned annotations are used instead. In this paper, we propose a framework that allows the model to predict precise rotated boxes only requiring cheaper axis-aligned annotation of the target dataset 1. To achieve this, we leverage the fact that neural networks are capable of learning richer representation of the target domain than what is utilized by the task. The under-utilized representation can be exploited to address a more detailed task. Our framework combines task knowledge of an out-of-domain source dataset with stronger annotation and domain knowledge of the target dataset with weaker annotation. A novel assignment process and projection loss are used to enable the co-training on the source and target datasets. As a result, the model is able to solve the more detailed task in the target domain, without additional computation overhead during inference. We extensively evaluate the method on various target datasets including fresh-produce dataset, HRSC2016 and SSDD. Results show that the proposed method consistently performs on par with the fully supervised approach.
ProtoCon: Pseudo-label Refinement via Online Clustering and Prototypical Consistency for Efficient Semi-supervised Learning
Mar 22, 2023



Confidence-based pseudo-labeling is among the dominant approaches in semi-supervised learning (SSL). It relies on including high-confidence predictions made on unlabeled data as additional targets to train the model. We propose ProtoCon, a novel SSL method aimed at the less-explored label-scarce SSL where such methods usually underperform. ProtoCon refines the pseudo-labels by leveraging their nearest neighbours' information. The neighbours are identified as the training proceeds using an online clustering approach operating in an embedding space trained via a prototypical loss to encourage well-formed clusters. The online nature of ProtoCon allows it to utilise the label history of the entire dataset in one training cycle to refine labels in the following cycle without the need to store image embeddings. Hence, it can seamlessly scale to larger datasets at a low cost. Finally, ProtoCon addresses the poor training signal in the initial phase of training (due to fewer confident predictions) by introducing an auxiliary self-supervised loss. It delivers significant gains and faster convergence over state-of-the-art across 5 datasets, including CIFARs, ImageNet and DomainNet.
Tracking Different Ant Species: An Unsupervised Domain Adaptation Framework and a Dataset for Multi-object Tracking
Jan 25, 2023



Tracking individuals is a vital part of many experiments conducted to understand collective behaviour. Ants are the paradigmatic model system for such experiments but their lack of individually distinguishing visual features and their high colony densities make it extremely difficult to perform reliable tracking automatically. Additionally, the wide diversity of their species' appearances makes a generalized approach even harder. In this paper, we propose a data-driven multi-object tracker that, for the first time, employs domain adaptation to achieve the required generalisation. This approach is built upon a joint-detection-and-tracking framework that is extended by a set of domain discriminator modules integrating an adversarial training strategy in addition to the tracking loss. In addition to this novel domain-adaptive tracking framework, we present a new dataset and a benchmark for the ant tracking problem. The dataset contains 57 video sequences with full trajectory annotation, including 30k frames captured from two different ant species moving on different background patterns. It comprises 33 and 24 sequences for source and target domains, respectively. We compare our proposed framework against other domain-adaptive and non-domain-adaptive multi-object tracking baselines using this dataset and show that incorporating domain adaptation at multiple levels of the tracking pipeline yields significant improvements. The code and the dataset are available at https://github.com/chamathabeysinghe/da-tracker.
Predicting Topological Maps for Visual Navigation in Unexplored Environments
Nov 23, 2022



We propose a robotic learning system for autonomous exploration and navigation in unexplored environments. We are motivated by the idea that even an unseen environment may be familiar from previous experiences in similar environments. The core of our method, therefore, is a process for building, predicting, and using probabilistic layout graphs for assisting goal-based visual navigation. We describe a navigation system that uses the layout predictions to satisfy high-level goals (e.g. "go to the kitchen") more rapidly and accurately than the prior art. Our proposed navigation framework comprises three stages: (1) Perception and Mapping: building a multi-level 3D scene graph; (2) Prediction: predicting probabilistic 3D scene graph for the unexplored environment; (3) Navigation: assisting navigation with the graphs. We test our framework in Matterport3D and show more success and efficient navigation in unseen environments.
ActiveRMAP: Radiance Field for Active Mapping And Planning
Nov 23, 2022A high-quality 3D reconstruction of a scene from a collection of 2D images can be achieved through offline/online mapping methods. In this paper, we explore active mapping from the perspective of implicit representations, which have recently produced compelling results in a variety of applications. One of the most popular implicit representations - Neural Radiance Field (NeRF), first demonstrated photorealistic rendering results using multi-layer perceptrons, with promising offline 3D reconstruction as a by-product of the radiance field. More recently, researchers also applied this implicit representation for online reconstruction and localization (i.e. implicit SLAM systems). However, the study on using implicit representation for active vision tasks is still very limited. In this paper, we are particularly interested in applying the neural radiance field for active mapping and planning problems, which are closely coupled tasks in an active system. We, for the first time, present an RGB-only active vision framework using radiance field representation for active 3D reconstruction and planning in an online manner. Specifically, we formulate this joint task as an iterative dual-stage optimization problem, where we alternatively optimize for the radiance field representation and path planning. Experimental results suggest that the proposed method achieves competitive results compared to other offline methods and outperforms active reconstruction methods using NeRFs.
MARLIN: Masked Autoencoder for facial video Representation LearnINg
Nov 12, 2022



This paper proposes a self-supervised approach to learn universal facial representations from videos, that can transfer across a variety of facial analysis tasks such as Facial Attribute Recognition (FAR), Facial Expression Recognition (FER), DeepFake Detection (DFD), and Lip Synchronization (LS). Our proposed framework, named MARLIN, is a facial video masked autoencoder, that learns highly robust and generic facial embeddings from abundantly available non-annotated web crawled facial videos. As a challenging auxiliary task, MARLIN reconstructs the spatio-temporal details of the face from the densely masked facial regions which mainly include eyes, nose, mouth, lips, and skin to capture local and global aspects that in turn help in encoding generic and transferable features. Through a variety of experiments on diverse downstream tasks, we demonstrate MARLIN to be an excellent facial video encoder as well as feature extractor, that performs consistently well across a variety of downstream tasks including FAR (1.13% gain over supervised benchmark), FER (2.64% gain over unsupervised benchmark), DFD (1.86% gain over unsupervised benchmark), LS (29.36% gain for Frechet Inception Distance), and even in low data regime. Our codes and pre-trained models will be made public.
Unifying Flow, Stereo and Depth Estimation
Nov 10, 2022



We present a unified formulation and model for three motion and 3D perception tasks: optical flow, rectified stereo matching and unrectified stereo depth estimation from posed images. Unlike previous specialized architectures for each specific task, we formulate all three tasks as a unified dense correspondence matching problem, which can be solved with a single model by directly comparing feature similarities. Such a formulation calls for discriminative feature representations, which we achieve using a Transformer, in particular the cross-attention mechanism. We demonstrate that cross-attention enables integration of knowledge from another image via cross-view interactions, which greatly improves the quality of the extracted features. Our unified model naturally enables cross-task transfer since the model architecture and parameters are shared across tasks. We outperform RAFT with our unified model on the challenging Sintel dataset, and our final model that uses a few additional task-specific refinement steps outperforms or compares favorably to recent state-of-the-art methods on 10 popular flow, stereo and depth datasets, while being simpler and more efficient in terms of model design and inference speed.
LAVA: Label-efficient Visual Learning and Adaptation
Oct 19, 2022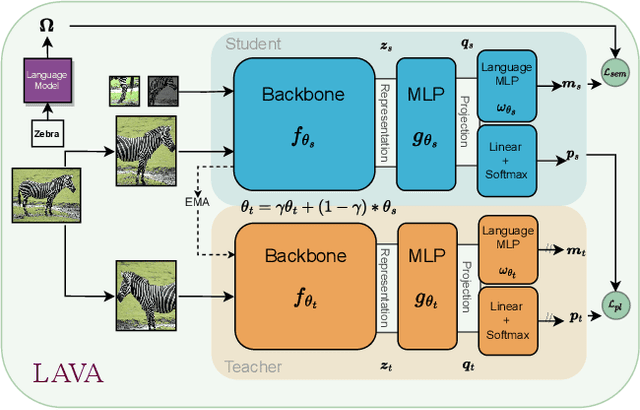


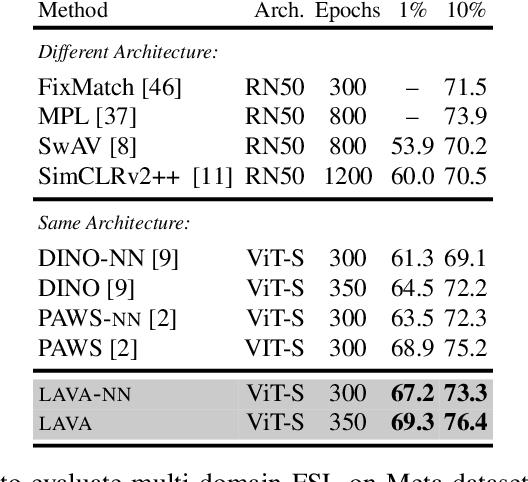
We present LAVA, a simple yet effective method for multi-domain visual transfer learning with limited data. LAVA builds on a few recent innovations to enable adapting to partially labelled datasets with class and domain shifts. First, LAVA learns self-supervised visual representations on the source dataset and ground them using class label semantics to overcome transfer collapse problems associated with supervised pretraining. Secondly, LAVA maximises the gains from unlabelled target data via a novel method which uses multi-crop augmentations to obtain highly robust pseudo-labels. By combining these ingredients, LAVA achieves a new state-of-the-art on ImageNet semi-supervised protocol, as well as on 7 out of 10 datasets in multi-domain few-shot learning on the Meta-dataset. Code and models are made available.
SoMoFormer: Multi-Person Pose Forecasting with Transformers
Aug 30, 2022
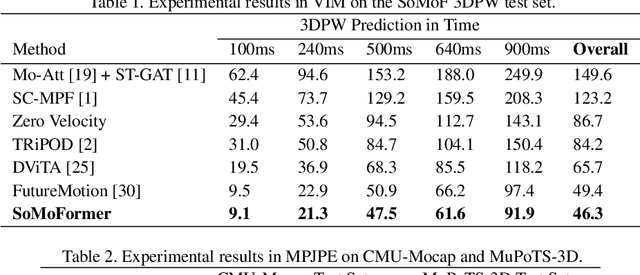
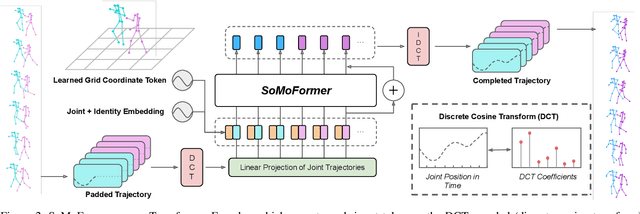
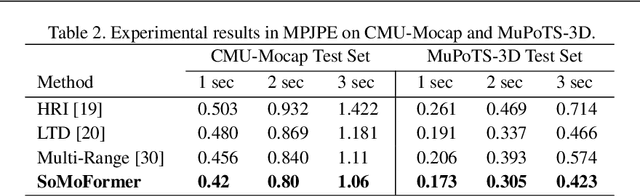
Human pose forecasting is a challenging problem involving complex human body motion and posture dynamics. In cases that there are multiple people in the environment, one's motion may also be influenced by the motion and dynamic movements of others. Although there are several previous works targeting the problem of multi-person dynamic pose forecasting, they often model the entire pose sequence as time series (ignoring the underlying relationship between joints) or only output the future pose sequence of one person at a time. In this paper, we present a new method, called Social Motion Transformer (SoMoFormer), for multi-person 3D pose forecasting. Our transformer architecture uniquely models human motion input as a joint sequence rather than a time sequence, allowing us to perform attention over joints while predicting an entire future motion sequence for each joint in parallel. We show that with this problem reformulation, SoMoFormer naturally extends to multi-person scenes by using the joints of all people in a scene as input queries. Using learned embeddings to denote the type of joint, person identity, and global position, our model learns the relationships between joints and between people, attending more strongly to joints from the same or nearby people. SoMoFormer outperforms state-of-the-art methods for long-term motion prediction on the SoMoF benchmark as well as the CMU-Mocap and MuPoTS-3D datasets. Code will be made available after publication.
Learning of Global Objective for Network Flow in Multi-Object Tracking
Mar 30, 2022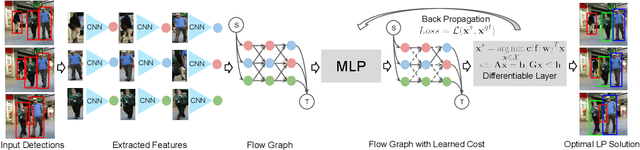
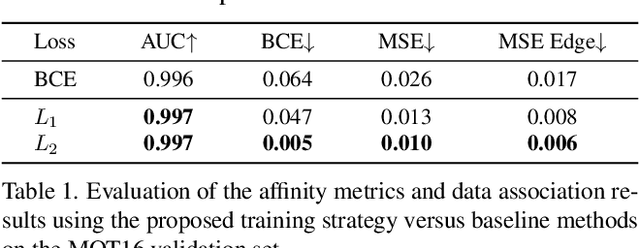

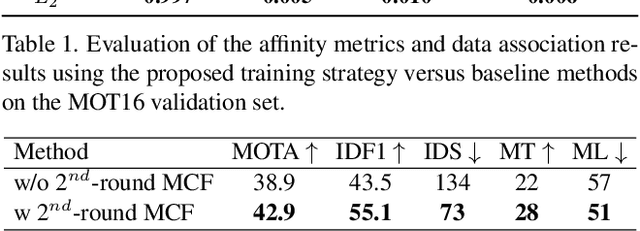
This paper concerns the problem of multi-object tracking based on the min-cost flow (MCF) formulation, which is conventionally studied as an instance of linear program. Given its computationally tractable inference, the success of MCF tracking largely relies on the learned cost function of underlying linear program. Most previous studies focus on learning the cost function by only taking into account two frames during training, therefore the learned cost function is sub-optimal for MCF where a multi-frame data association must be considered during inference. In order to address this problem, in this paper we propose a novel differentiable framework that ties training and inference together during learning by solving a bi-level optimization problem, where the lower-level solves a linear program and the upper-level contains a loss function that incorporates global tracking result. By back-propagating the loss through differentiable layers via gradient descent, the globally parameterized cost function is explicitly learned and regularized. With this approach, we are able to learn a better objective for global MCF tracking. As a result, we achieve competitive performances compared to the current state-of-the-art methods on the popular multi-object tracking benchmarks such as MOT16, MOT17 and MOT20.