 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeINQUIRE-Search: A Framework for Interactive Discovery in Large-Scale Biodiversity Databases
Nov 19, 2025



Large community science platforms such as iNaturalist contain hundreds of millions of biodiversity images that often capture ecological context on behaviors, interactions, phenology, and habitat. Yet most ecological workflows rely on metadata filtering or manual inspection, leaving this secondary information inaccessible at scale. We introduce INQUIRE-Search, an open-source system that enables scientists to rapidly and interactively search within an ecological image database for specific concepts using natural language, verify and export relevant observations, and utilize this discovered data for novel scientific analysis. Compared to traditional methods, INQUIRE-Search takes a fraction of the time, opening up new possibilities for scientific questions that can be explored. Through five case studies, we show the diversity of scientific applications that a tool like INQUIRE-Search can support, from seasonal variation in behavior across species to forest regrowth after wildfires. These examples demonstrate a new paradigm for interactive, efficient, and scalable scientific discovery that can begin to unlock previously inaccessible scientific value in large-scale biodiversity datasets. Finally, we emphasize using such AI-enabled discovery tools for science call for experts to reframe the priorities of the scientific process and develop novel methods for experiment design, data collection, survey effort, and uncertainty analysis.
Do Large Language Model Benchmarks Test Reliability?
Feb 05, 2025When deploying large language models (LLMs), it is important to ensure that these models are not only capable, but also reliable. Many benchmarks have been created to track LLMs' growing capabilities, however there has been no similar focus on measuring their reliability. To understand the potential ramifications of this gap, we investigate how well current benchmarks quantify model reliability. We find that pervasive label errors can compromise these evaluations, obscuring lingering model failures and hiding unreliable behavior. Motivated by this gap in the evaluation of reliability, we then propose the concept of so-called platinum benchmarks, i.e., benchmarks carefully curated to minimize label errors and ambiguity. As a first attempt at constructing such benchmarks, we revise examples from fifteen existing popular benchmarks. We evaluate a wide range of models on these platinum benchmarks and find that, indeed, frontier LLMs still exhibit failures on simple tasks such as elementary-level math word problems. Analyzing these failures further reveals previously unidentified patterns of problems on which frontier models consistently struggle. We provide code at https://github.com/MadryLab/platinum-benchmarks
Humanity's Last Exam
Jan 24, 2025Benchmarks are important tools for tracking the rapid advancements in large language model (LLM) capabilities. However, benchmarks are not keeping pace in difficulty: LLMs now achieve over 90\% accuracy on popular benchmarks like MMLU, limiting informed measurement of state-of-the-art LLM capabilities. In response, we introduce Humanity's Last Exam (HLE), a multi-modal benchmark at the frontier of human knowledge, designed to be the final closed-ended academic benchmark of its kind with broad subject coverage. HLE consists of 3,000 questions across dozens of subjects, including mathematics, humanities, and the natural sciences. HLE is developed globally by subject-matter experts and consists of multiple-choice and short-answer questions suitable for automated grading. Each question has a known solution that is unambiguous and easily verifiable, but cannot be quickly answered via internet retrieval. State-of-the-art LLMs demonstrate low accuracy and calibration on HLE, highlighting a significant gap between current LLM capabilities and the expert human frontier on closed-ended academic questions. To inform research and policymaking upon a clear understanding of model capabilities, we publicly release HLE at https://lastexam.ai.
INQUIRE: A Natural World Text-to-Image Retrieval Benchmark
Nov 04, 2024We introduce INQUIRE, a text-to-image retrieval benchmark designed to challenge multimodal vision-language models on expert-level queries. INQUIRE includes iNaturalist 2024 (iNat24), a new dataset of five million natural world images, along with 250 expert-level retrieval queries. These queries are paired with all relevant images comprehensively labeled within iNat24, comprising 33,000 total matches. Queries span categories such as species identification, context, behavior, and appearance, emphasizing tasks that require nuanced image understanding and domain expertise. Our benchmark evaluates two core retrieval tasks: (1) INQUIRE-Fullrank, a full dataset ranking task, and (2) INQUIRE-Rerank, a reranking task for refining top-100 retrievals. Detailed evaluation of a range of recent multimodal models demonstrates that INQUIRE poses a significant challenge, with the best models failing to achieve an mAP@50 above 50%. In addition, we show that reranking with more powerful multimodal models can enhance retrieval performance, yet there remains a significant margin for improvement. By focusing on scientifically-motivated ecological challenges, INQUIRE aims to bridge the gap between AI capabilities and the needs of real-world scientific inquiry, encouraging the development of retrieval systems that can assist with accelerating ecological and biodiversity research. Our dataset and code are available at https://inquire-benchmark.github.io
Few-Shot Classification of Interactive Activities of Daily Living (InteractADL)
Jun 03, 2024



Understanding Activities of Daily Living (ADLs) is a crucial step for different applications including assistive robots, smart homes, and healthcare. However, to date, few benchmarks and methods have focused on complex ADLs, especially those involving multi-person interactions in home environments. In this paper, we propose a new dataset and benchmark, InteractADL, for understanding complex ADLs that involve interaction between humans (and objects). Furthermore, complex ADLs occurring in home environments comprise a challenging long-tailed distribution due to the rarity of multi-person interactions, and pose fine-grained visual recognition tasks due to the presence of semantically and visually similar classes. To address these issues, we propose a novel method for fine-grained few-shot video classification called Name Tuning that enables greater semantic separability by learning optimal class name vectors. We show that Name Tuning can be combined with existing prompt tuning strategies to learn the entire input text (rather than only learning the prompt or class names) and demonstrate improved performance for few-shot classification on InteractADL and 4 other fine-grained visual classification benchmarks. For transparency and reproducibility, we release our code at https://github.com/zanedurante/vlm_benchmark.
Agile Modeling: Image Classification with Domain Experts in the Loop
Feb 25, 2023



Machine learning is not readily accessible to domain experts from many fields, blocked by issues ranging from data mining to model training. We argue that domain experts should be at the center of the modeling process, and we introduce the "Agile Modeling" problem: the process of turning any visual concept from an idea into a well-trained ML classifier through a human-in-the-loop interaction driven by the domain expert in a way that minimizes domain expert time. We propose a solution to the problem that enables domain experts to create classifiers in real-time and build upon recent advances in image-text co-embeddings such as CLIP or ALIGN to implement it. We show the feasibility of this solution through live experiments with 14 domain experts, each modeling their own concept. Finally, we compare a domain expert driven process with the traditional crowdsourcing paradigm and find that difficult concepts see pronounced improvements with domain experts.
SoMoFormer: Multi-Person Pose Forecasting with Transformers
Aug 30, 2022
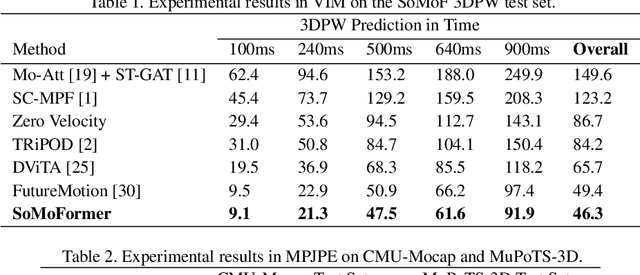
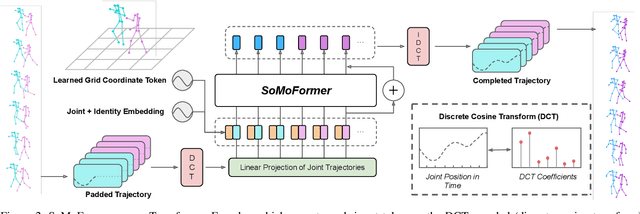
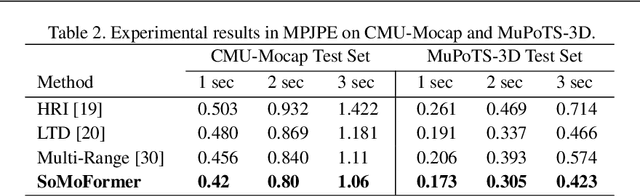
Human pose forecasting is a challenging problem involving complex human body motion and posture dynamics. In cases that there are multiple people in the environment, one's motion may also be influenced by the motion and dynamic movements of others. Although there are several previous works targeting the problem of multi-person dynamic pose forecasting, they often model the entire pose sequence as time series (ignoring the underlying relationship between joints) or only output the future pose sequence of one person at a time. In this paper, we present a new method, called Social Motion Transformer (SoMoFormer), for multi-person 3D pose forecasting. Our transformer architecture uniquely models human motion input as a joint sequence rather than a time sequence, allowing us to perform attention over joints while predicting an entire future motion sequence for each joint in parallel. We show that with this problem reformulation, SoMoFormer naturally extends to multi-person scenes by using the joints of all people in a scene as input queries. Using learned embeddings to denote the type of joint, person identity, and global position, our model learns the relationships between joints and between people, attending more strongly to joints from the same or nearby people. SoMoFormer outperforms state-of-the-art methods for long-term motion prediction on the SoMoF benchmark as well as the CMU-Mocap and MuPoTS-3D datasets. Code will be made available after publication.
Understanding Transfer Learning for Chest Radiograph Clinical Report Generation with Modified Transformer Architectures
May 05, 2022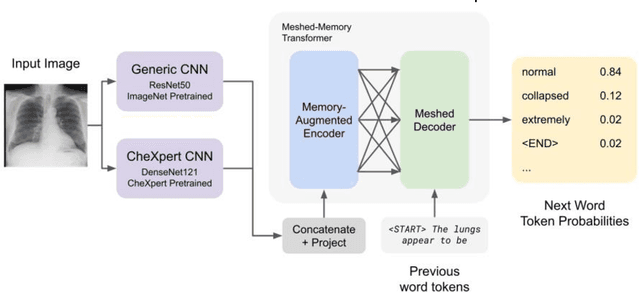
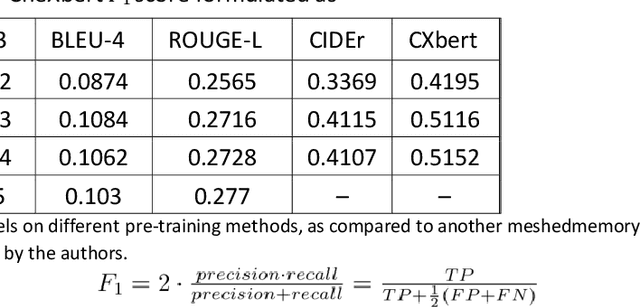
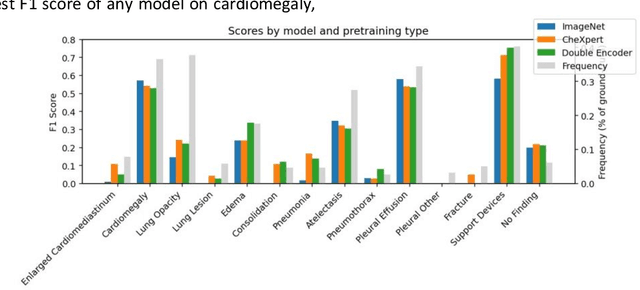

The image captioning task is increasingly prevalent in artificial intelligence applications for medicine. One important application is clinical report generation from chest radiographs. The clinical writing of unstructured reports is time consuming and error-prone. An automated system would improve standardization, error reduction, time consumption, and medical accessibility. In this paper we demonstrate the importance of domain specific pre-training and propose a modified transformer architecture for the medical image captioning task. To accomplish this, we train a series of modified transformers to generate clinical reports from chest radiograph image input. These modified transformers include: a meshed-memory augmented transformer architecture with visual extractor using ImageNet pre-trained weights, a meshed-memory augmented transformer architecture with visual extractor using CheXpert pre-trained weights, and a meshed-memory augmented transformer whose encoder is passed the concatenated embeddings using both ImageNet pre-trained weights and CheXpert pre-trained weights. We use BLEU(1-4), ROUGE-L, CIDEr, and the clinical CheXbert F1 scores to validate our models and demonstrate competitive scores with state of the art models. We provide evidence that ImageNet pre-training is ill-suited for the medical image captioning task, especially for less frequent conditions (eg: enlarged cardiomediastinum, lung lesion, pneumothorax). Furthermore, we demonstrate that the double feature model improves performance for specific medical conditions (edema, consolidation, pneumothorax, support devices) and overall CheXbert F1 score, and should be further developed in future work. Such a double feature model, including both ImageNet pre-training as well as domain specific pre-training, could be used in a wide range of image captioning models in medicine.