 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSongBloom: Coherent Song Generation via Interleaved Autoregressive Sketching and Diffusion Refinement
Jun 09, 2025Generating music with coherent structure, harmonious instrumental and vocal elements remains a significant challenge in song generation. Existing language models and diffusion-based methods often struggle to balance global coherence with local fidelity, resulting in outputs that lack musicality or suffer from incoherent progression and mismatched lyrics. This paper introduces $\textbf{SongBloom}$, a novel framework for full-length song generation that leverages an interleaved paradigm of autoregressive sketching and diffusion-based refinement. SongBloom employs an autoregressive diffusion model that combines the high fidelity of diffusion models with the scalability of language models. Specifically, it gradually extends a musical sketch from short to long and refines the details from coarse to fine-grained. The interleaved generation paradigm effectively integrates prior semantic and acoustic context to guide the generation process. Experimental results demonstrate that SongBloom outperforms existing methods across both subjective and objective metrics and achieves performance comparable to the state-of-the-art commercial music generation platforms. Audio samples are available on our demo page: https://cypress-yang.github.io/SongBloom\_demo.
Exploring Length Generalization For Transformer-based Speech Enhancement
Jun 07, 2025



Transformer network architecture has proven effective in speech enhancement. However, as its core module, self-attention suffers from quadratic complexity, making it infeasible for training on long speech utterances. In practical scenarios, speech enhancement models are often required to perform on noisy speech at run-time that is substantially longer than the training utterances. It remains a challenge how a Transformer-based speech enhancement model can generalize to long speech utterances. In this paper, extensive empirical studies are conducted to explore the model's length generalization ability. In particular, we conduct speech enhancement experiments on four training objectives and evaluate with five metrics. Our studies establish that positional encoding is an effective instrument to dampen the effect of utterance length on speech enhancement. We first explore several existing positional encoding methods, and the results show that relative positional encoding methods exhibit a better length generalization property than absolute positional encoding methods. Additionally, we also explore a simpler and more effective positional encoding scheme, i.e. LearnLin, that uses only one trainable parameter for each attention head to scale the real relative position between time frames, which learns the different preferences on short- or long-term dependencies of these heads. The results demonstrate that our proposal exhibits excellent length generalization ability with comparable or superior performance than other state-of-the-art positional encoding strategies.
Towards Emotionally Consistent Text-Based Speech Editing: Introducing EmoCorrector and The ECD-TSE Dataset
May 24, 2025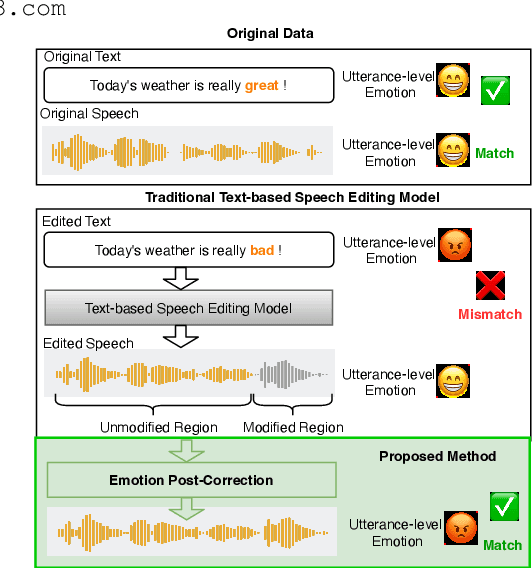


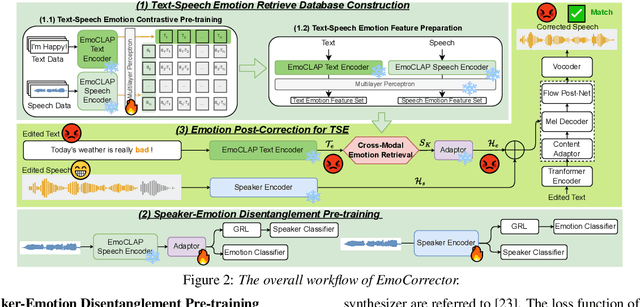
Text-based speech editing (TSE) modifies speech using only text, eliminating re-recording. However, existing TSE methods, mainly focus on the content accuracy and acoustic consistency of synthetic speech segments, and often overlook the emotional shifts or inconsistency issues introduced by text changes. To address this issue, we propose EmoCorrector, a novel post-correction scheme for TSE. EmoCorrector leverages Retrieval-Augmented Generation (RAG) by extracting the edited text's emotional features, retrieving speech samples with matching emotions, and synthesizing speech that aligns with the desired emotion while preserving the speaker's identity and quality. To support the training and evaluation of emotional consistency modeling in TSE, we pioneer the benchmarking Emotion Correction Dataset for TSE (ECD-TSE). The prominent aspect of ECD-TSE is its inclusion of $<$text, speech$>$ paired data featuring diverse text variations and a range of emotional expressions. Subjective and objective experiments and comprehensive analysis on ECD-TSE confirm that EmoCorrector significantly enhances the expression of intended emotion while addressing emotion inconsistency limitations in current TSE methods. Code and audio examples are available at https://github.com/AI-S2-Lab/EmoCorrector.
From Word to World: Evaluate and Mitigate Culture Bias via Word Association Test
May 24, 2025The human-centered word association test (WAT) serves as a cognitive proxy, revealing sociocultural variations through lexical-semantic patterns. We extend this test into an LLM-adaptive, free-relation task to assess the alignment of large language models (LLMs) with cross-cultural cognition. To mitigate the culture preference, we propose CultureSteer, an innovative approach that integrates a culture-aware steering mechanism to guide semantic representations toward culturally specific spaces. Experiments show that current LLMs exhibit significant bias toward Western cultural (notably in American) schemas at the word association level. In contrast, our model substantially improves cross-cultural alignment, surpassing prompt-based methods in capturing diverse semantic associations. Further validation on culture-sensitive downstream tasks confirms its efficacy in fostering cognitive alignment across cultures. This work contributes a novel methodological paradigm for enhancing cultural awareness in LLMs, advancing the development of more inclusive language technologies.
PersonaTAB: Predicting Personality Traits using Textual, Acoustic, and Behavioral Cues in Fully-Duplex Speech Dialogs
May 20, 2025Despite significant progress in neural spoken dialog systems, personality-aware conversation agents -- capable of adapting behavior based on personalities -- remain underexplored due to the absence of personality annotations in speech datasets. We propose a pipeline that preprocesses raw audio recordings to create a dialogue dataset annotated with timestamps, response types, and emotion/sentiment labels. We employ an automatic speech recognition (ASR) system to extract transcripts and timestamps, then generate conversation-level annotations. Leveraging these annotations, we design a system that employs large language models to predict conversational personality. Human evaluators were engaged to identify conversational characteristics and assign personality labels. Our analysis demonstrates that the proposed system achieves stronger alignment with human judgments compared to existing approaches.
Chain-Talker: Chain Understanding and Rendering for Empathetic Conversational Speech Synthesis
May 19, 2025Conversational Speech Synthesis (CSS) aims to align synthesized speech with the emotional and stylistic context of user-agent interactions to achieve empathy. Current generative CSS models face interpretability limitations due to insufficient emotional perception and redundant discrete speech coding. To address the above issues, we present Chain-Talker, a three-stage framework mimicking human cognition: Emotion Understanding derives context-aware emotion descriptors from dialogue history; Semantic Understanding generates compact semantic codes via serialized prediction; and Empathetic Rendering synthesizes expressive speech by integrating both components. To support emotion modeling, we develop CSS-EmCap, an LLM-driven automated pipeline for generating precise conversational speech emotion captions. Experiments on three benchmark datasets demonstrate that Chain-Talker produces more expressive and empathetic speech than existing methods, with CSS-EmCap contributing to reliable emotion modeling. The code and demos are available at: https://github.com/AI-S2-Lab/Chain-Talker.
What Is Next for LLMs? Next-Generation AI Computing Hardware Using Photonic Chips
May 09, 2025



Large language models (LLMs) are rapidly pushing the limits of contemporary computing hardware. For example, training GPT-3 has been estimated to consume around 1300 MWh of electricity, and projections suggest future models may require city-scale (gigawatt) power budgets. These demands motivate exploration of computing paradigms beyond conventional von Neumann architectures. This review surveys emerging photonic hardware optimized for next-generation generative AI computing. We discuss integrated photonic neural network architectures (e.g., Mach-Zehnder interferometer meshes, lasers, wavelength-multiplexed microring resonators) that perform ultrafast matrix operations. We also examine promising alternative neuromorphic devices, including spiking neural network circuits and hybrid spintronic-photonic synapses, which combine memory and processing. The integration of two-dimensional materials (graphene, TMDCs) into silicon photonic platforms is reviewed for tunable modulators and on-chip synaptic elements. Transformer-based LLM architectures (self-attention and feed-forward layers) are analyzed in this context, identifying strategies and challenges for mapping dynamic matrix multiplications onto these novel hardware substrates. We then dissect the mechanisms of mainstream LLMs, such as ChatGPT, DeepSeek, and LLaMA, highlighting their architectural similarities and differences. We synthesize state-of-the-art components, algorithms, and integration methods, highlighting key advances and open issues in scaling such systems to mega-sized LLM models. We find that photonic computing systems could potentially surpass electronic processors by orders of magnitude in throughput and energy efficiency, but require breakthroughs in memory, especially for long-context windows and long token sequences, and in storage of ultra-large datasets.
Nes2Net: A Lightweight Nested Architecture for Foundation Model Driven Speech Anti-spoofing
Apr 08, 2025Speech foundation models have significantly advanced various speech-related tasks by providing exceptional representation capabilities. However, their high-dimensional output features often create a mismatch with downstream task models, which typically require lower-dimensional inputs. A common solution is to apply a dimensionality reduction (DR) layer, but this approach increases parameter overhead, computational costs, and risks losing valuable information. To address these issues, we propose Nested Res2Net (Nes2Net), a lightweight back-end architecture designed to directly process high-dimensional features without DR layers. The nested structure enhances multi-scale feature extraction, improves feature interaction, and preserves high-dimensional information. We first validate Nes2Net on CtrSVDD, a singing voice deepfake detection dataset, and report a 22% performance improvement and an 87% back-end computational cost reduction over the state-of-the-art baseline. Additionally, extensive testing across four diverse datasets: ASVspoof 2021, ASVspoof 5, PartialSpoof, and In-the-Wild, covering fully spoofed speech, adversarial attacks, partial spoofing, and real-world scenarios, consistently highlights Nes2Net's superior robustness and generalization capabilities. The code package and pre-trained models are available at https://github.com/Liu-Tianchi/Nes2Net.
Causal Self-supervised Pretrained Frontend with Predictive Code for Speech Separation
Apr 03, 2025



Speech separation (SS) seeks to disentangle a multi-talker speech mixture into single-talker speech streams. Although SS can be generally achieved using offline methods, such a processing paradigm is not suitable for real-time streaming applications. Causal separation models, which rely only on past and present information, offer a promising solution for real-time streaming. However, these models typically suffer from notable performance degradation due to the absence of future context. In this paper, we introduce a novel frontend that is designed to mitigate the mismatch between training and run-time inference by implicitly incorporating future information into causal models through predictive patterns. The pretrained frontend employs a transformer decoder network with a causal convolutional encoder as the backbone and is pretrained in a self-supervised manner with two innovative pretext tasks: autoregressive hybrid prediction and contextual knowledge distillation. These tasks enable the model to capture predictive patterns directly from mixtures in a self-supervised manner. The pretrained frontend subsequently serves as a feature extractor to generate high-quality predictive patterns. Comprehensive evaluations on synthetic and real-world datasets validated the effectiveness of the proposed pretrained frontend.
$C^2$AV-TSE: Context and Confidence-aware Audio Visual Target Speaker Extraction
Apr 01, 2025Audio-Visual Target Speaker Extraction (AV-TSE) aims to mimic the human ability to enhance auditory perception using visual cues. Although numerous models have been proposed recently, most of them estimate target signals by primarily relying on local dependencies within acoustic features, underutilizing the human-like capacity to infer unclear parts of speech through contextual information. This limitation results in not only suboptimal performance but also inconsistent extraction quality across the utterance, with some segments exhibiting poor quality or inadequate suppression of interfering speakers. To close this gap, we propose a model-agnostic strategy called the Mask-And-Recover (MAR). It integrates both inter- and intra-modality contextual correlations to enable global inference within extraction modules. Additionally, to better target challenging parts within each sample, we introduce a Fine-grained Confidence Score (FCS) model to assess extraction quality and guide extraction modules to emphasize improvement on low-quality segments. To validate the effectiveness of our proposed model-agnostic training paradigm, six popular AV-TSE backbones were adopted for evaluation on the VoxCeleb2 dataset, demonstrating consistent performance improvements across various metrics.