 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross Modal Retrieval with Querybank Normalisation
Dec 23, 2021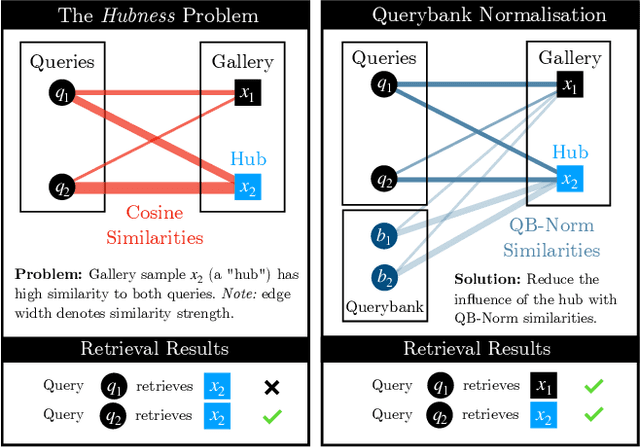

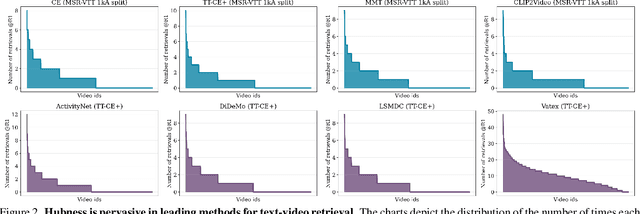
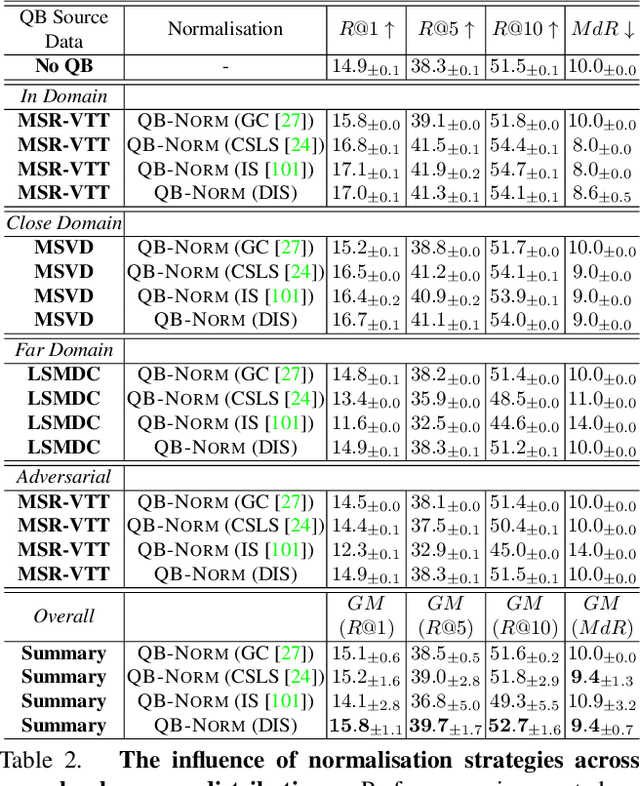
Profiting from large-scale training datasets, advances in neural architecture design and efficient inference, joint embeddings have become the dominant approach for tackling cross-modal retrieval. In this work we first show that, despite their effectiveness, state-of-the-art joint embeddings suffer significantly from the longstanding hubness problem in which a small number of gallery embeddings form the nearest neighbours of many queries. Drawing inspiration from the NLP literature, we formulate a simple but effective framework called Querybank Normalisation (QB-Norm) that re-normalises query similarities to account for hubs in the embedding space. QB-Norm improves retrieval performance without requiring retraining. Differently from prior work, we show that QB-Norm works effectively without concurrent access to any test set queries. Within the QB-Norm framework, we also propose a novel similarity normalisation method, the Dynamic Inverted Softmax, that is significantly more robust than existing approaches. We showcase QB-Norm across a range of cross modal retrieval models and benchmarks where it consistently enhances strong baselines beyond the state of the art. Code is available at https://vladbogo.github.io/QB-Norm/.
Time-Equivariant Contrastive Video Representation Learning
Dec 07, 2021
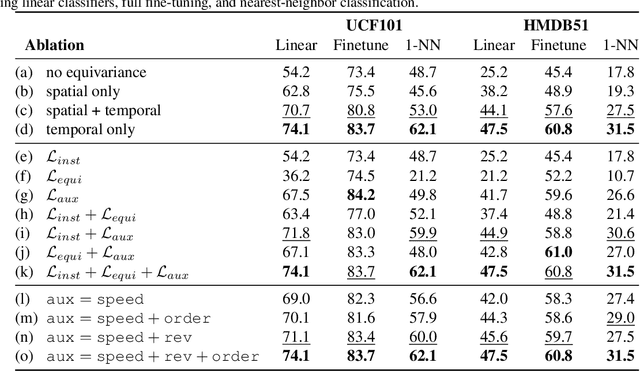
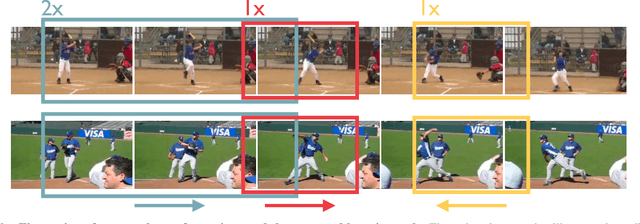
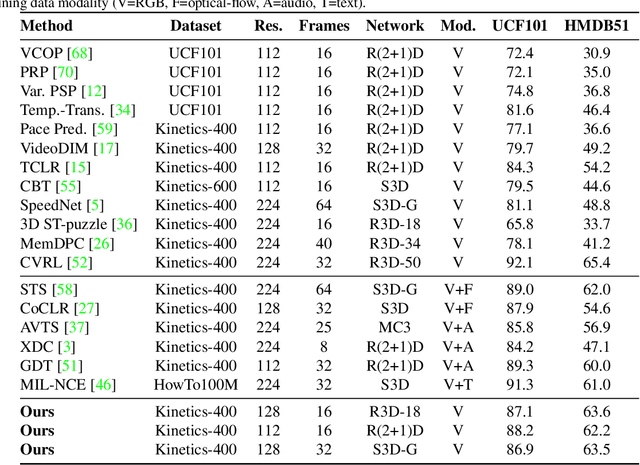
We introduce a novel self-supervised contrastive learning method to learn representations from unlabelled videos. Existing approaches ignore the specifics of input distortions, e.g., by learning invariance to temporal transformations. Instead, we argue that video representation should preserve video dynamics and reflect temporal manipulations of the input. Therefore, we exploit novel constraints to build representations that are equivariant to temporal transformations and better capture video dynamics. In our method, relative temporal transformations between augmented clips of a video are encoded in a vector and contrasted with other transformation vectors. To support temporal equivariance learning, we additionally propose the self-supervised classification of two clips of a video into 1. overlapping 2. ordered, or 3. unordered. Our experiments show that time-equivariant representations achieve state-of-the-art results in video retrieval and action recognition benchmarks on UCF101, HMDB51, and Diving48.
Look at What I'm Doing: Self-Supervised Spatial Grounding of Narrations in Instructional Videos
Oct 20, 2021
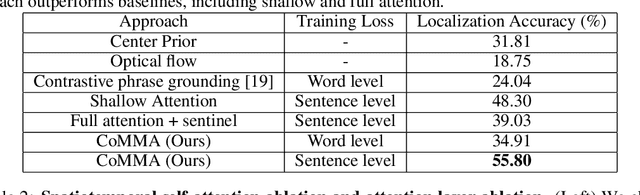
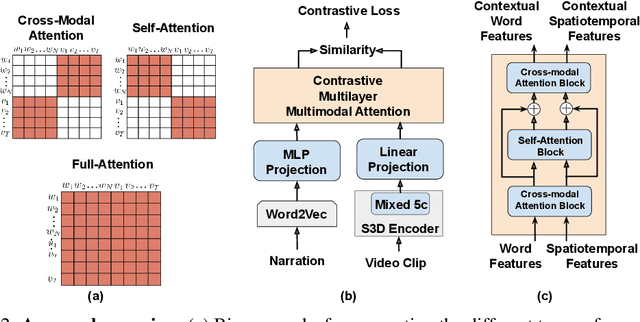
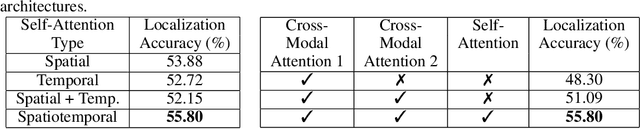
We introduce the task of spatially localizing narrated interactions in videos. Key to our approach is the ability to learn to spatially localize interactions with self-supervision on a large corpus of videos with accompanying transcribed narrations. To achieve this goal, we propose a multilayer cross-modal attention network that enables effective optimization of a contrastive loss during training. We introduce a divided strategy that alternates between computing inter- and intra-modal attention across the visual and natural language modalities, which allows effective training via directly contrasting the two modalities' representations. We demonstrate the effectiveness of our approach by self-training on the HowTo100M instructional video dataset and evaluating on a newly collected dataset of localized described interactions in the YouCook2 dataset. We show that our approach outperforms alternative baselines, including shallow co-attention and full cross-modal attention. We also apply our approach to grounding phrases in images with weak supervision on Flickr30K and show that stacking multiple attention layers is effective and, when combined with a word-to-region loss, achieves state of the art on recall-at-one and pointing hand accuracies.
StreamHover: Livestream Transcript Summarization and Annotation
Sep 11, 2021
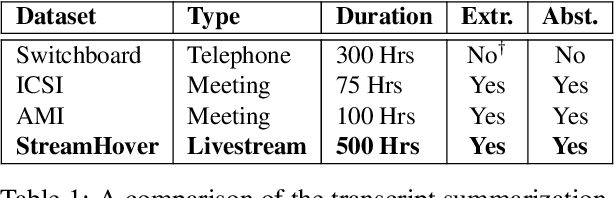

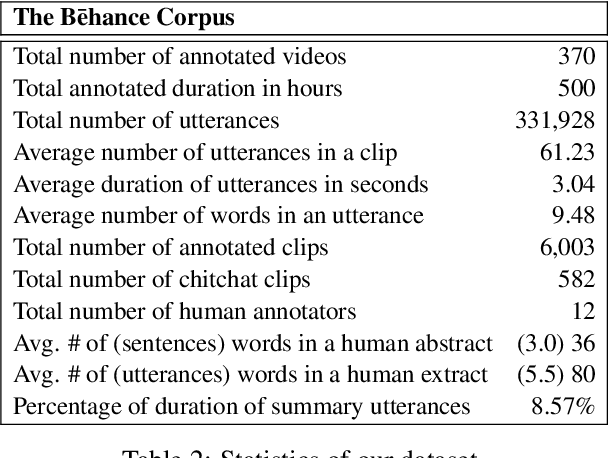
With the explosive growth of livestream broadcasting, there is an urgent need for new summarization technology that enables us to create a preview of streamed content and tap into this wealth of knowledge. However, the problem is nontrivial due to the informal nature of spoken language. Further, there has been a shortage of annotated datasets that are necessary for transcript summarization. In this paper, we present StreamHover, a framework for annotating and summarizing livestream transcripts. With a total of over 500 hours of videos annotated with both extractive and abstractive summaries, our benchmark dataset is significantly larger than currently existing annotated corpora. We explore a neural extractive summarization model that leverages vector-quantized variational autoencoder to learn latent vector representations of spoken utterances and identify salient utterances from the transcripts to form summaries. We show that our model generalizes better and improves performance over strong baselines. The results of this study provide an avenue for future research to improve summarization solutions for efficient browsing of livestreams.
Font Completion and Manipulation by Cycling Between Multi-Modality Representations
Aug 30, 2021

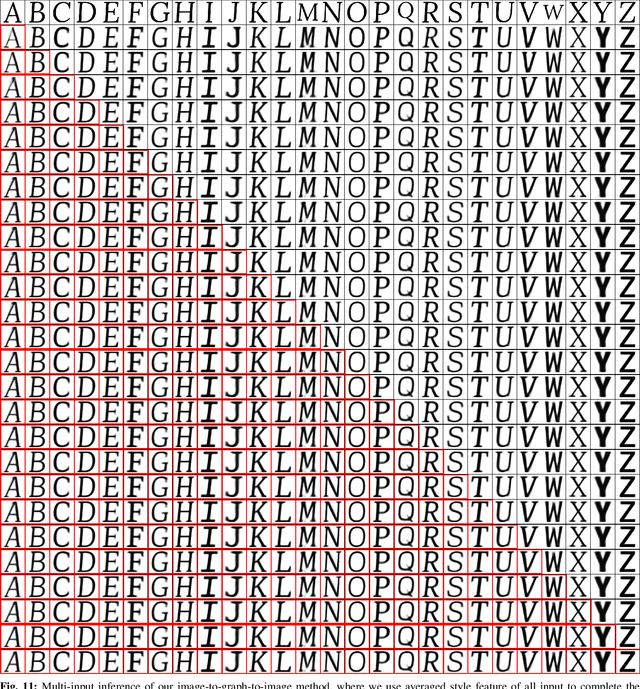

Generating font glyphs of consistent style from one or a few reference glyphs, i.e., font completion, is an important task in topographical design. As the problem is more well-defined than general image style transfer tasks, thus it has received interest from both vision and machine learning communities. Existing approaches address this problem as a direct image-to-image translation task. In this work, we innovate to explore the generation of font glyphs as 2D graphic objects with the graph as an intermediate representation, so that more intrinsic graphic properties of font styles can be captured. Specifically, we formulate a cross-modality cycled image-to-image model structure with a graph constructor between an image encoder and an image renderer. The novel graph constructor maps a glyph's latent code to its graph representation that matches expert knowledge, which is trained to help the translation task. Our model generates improved results than both image-to-image baseline and previous state-of-the-art methods for glyph completion. Furthermore, the graph representation output by our model also provides an intuitive interface for users to do local editing and manipulation. Our proposed cross-modality cycled representation learning has the potential to be applied to other domains with prior knowledge from different data modalities. Our code is available at https://github.com/VITA-Group/Font_Completion_Graph.
Cross-Sentence Temporal and Semantic Relations in Video Activity Localisation
Aug 17, 2021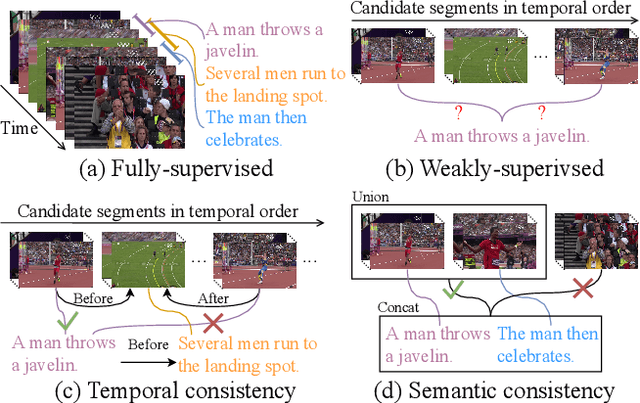
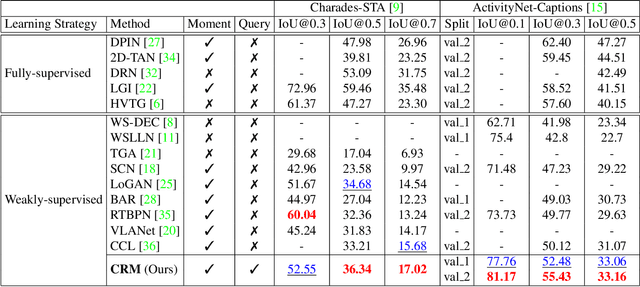
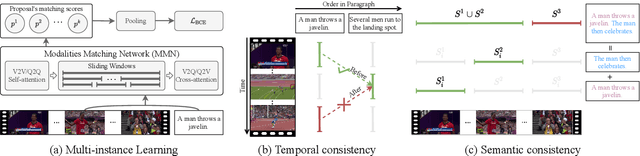
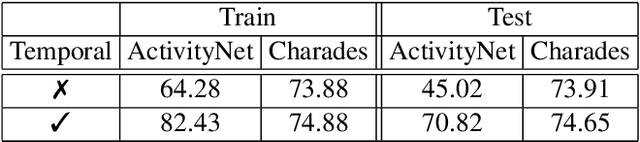
Video activity localisation has recently attained increasing attention due to its practical values in automatically localising the most salient visual segments corresponding to their language descriptions (sentences) from untrimmed and unstructured videos. For supervised model training, a temporal annotation of both the start and end time index of each video segment for a sentence (a video moment) must be given. This is not only very expensive but also sensitive to ambiguity and subjective annotation bias, a much harder task than image labelling. In this work, we develop a more accurate weakly-supervised solution by introducing Cross-Sentence Relations Mining (CRM) in video moment proposal generation and matching when only a paragraph description of activities without per-sentence temporal annotation is available. Specifically, we explore two cross-sentence relational constraints: (1) Temporal ordering and (2) semantic consistency among sentences in a paragraph description of video activities. Existing weakly-supervised techniques only consider within-sentence video segment correlations in training without considering cross-sentence paragraph context. This can mislead due to ambiguous expressions of individual sentences with visually indiscriminate video moment proposals in isolation. Experiments on two publicly available activity localisation datasets show the advantages of our approach over the state-of-the-art weakly supervised methods, especially so when the video activity descriptions become more complex.
Black-Box Diagnosis and Calibration on GAN Intra-Mode Collapse: A Pilot Study
Jul 23, 2021

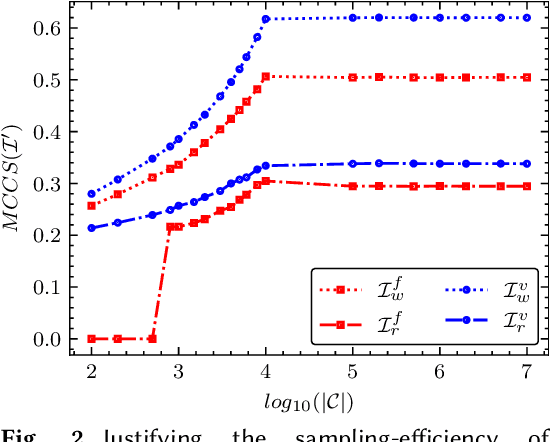

Generative adversarial networks (GANs) nowadays are capable of producing images of incredible realism. One concern raised is whether the state-of-the-art GAN's learned distribution still suffers from mode collapse, and what to do if so. Existing diversity tests of samples from GANs are usually conducted qualitatively on a small scale, and/or depends on the access to original training data as well as the trained model parameters. This paper explores to diagnose GAN intra-mode collapse and calibrate that, in a novel black-box setting: no access to training data, nor the trained model parameters, is assumed. The new setting is practically demanded, yet rarely explored and significantly more challenging. As a first stab, we devise a set of statistical tools based on sampling, that can visualize, quantify, and rectify intra-mode collapse. We demonstrate the effectiveness of our proposed diagnosis and calibration techniques, via extensive simulations and experiments, on unconditional GAN image generation (e.g., face and vehicle). Our study reveals that the intra-mode collapse is still a prevailing problem in state-of-the-art GANs and the mode collapse is diagnosable and calibratable in black-box settings. Our codes are available at: https://github.com/VITA-Group/BlackBoxGANCollapse.
Compositional Sketch Search
Jun 15, 2021
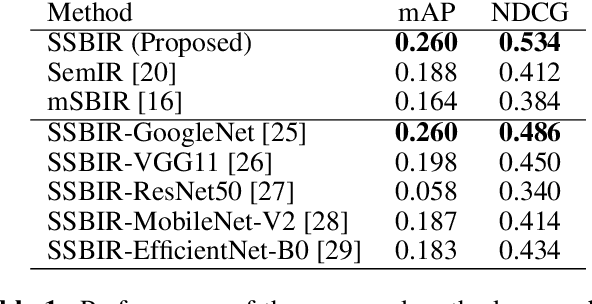
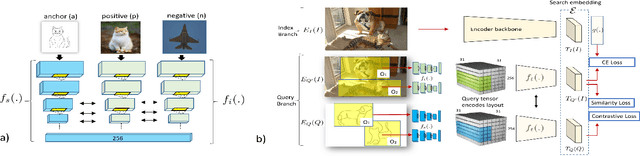
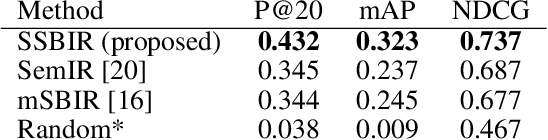
We present an algorithm for searching image collections using free-hand sketches that describe the appearance and relative positions of multiple objects. Sketch based image retrieval (SBIR) methods predominantly match queries containing a single, dominant object invariant to its position within an image. Our work exploits drawings as a concise and intuitive representation for specifying entire scene compositions. We train a convolutional neural network (CNN) to encode masked visual features from sketched objects, pooling these into a spatial descriptor encoding the spatial relationships and appearances of objects in the composition. Training the CNN backbone as a Siamese network under triplet loss yields a metric search embedding for measuring compositional similarity which may be efficiently leveraged for visual search by applying product quantization.
Magic Layouts: Structural Prior for Component Detection in User Interface Designs
Jun 14, 2021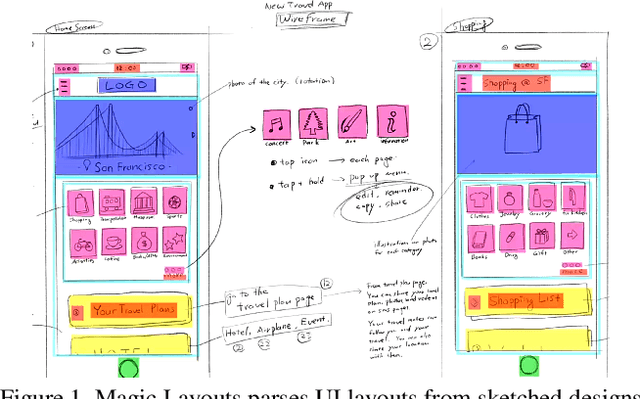
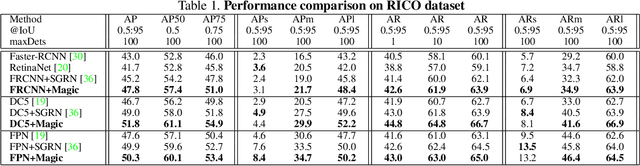
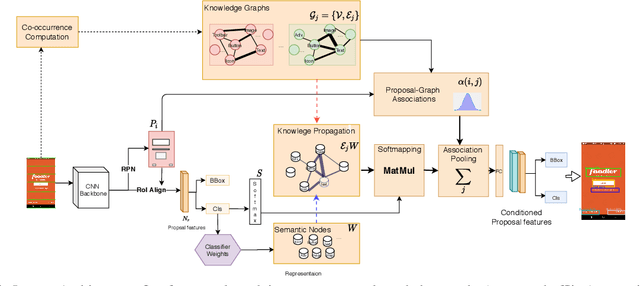
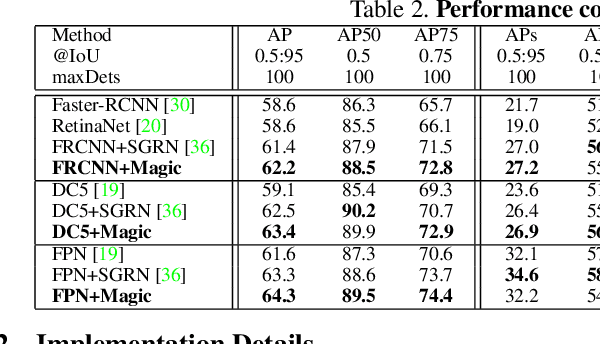
We present Magic Layouts; a method for parsing screenshots or hand-drawn sketches of user interface (UI) layouts. Our core contribution is to extend existing detectors to exploit a learned structural prior for UI designs, enabling robust detection of UI components; buttons, text boxes and similar. Specifically we learn a prior over mobile UI layouts, encoding common spatial co-occurrence relationships between different UI components. Conditioning region proposals using this prior leads to performance gains on UI layout parsing for both hand-drawn UIs and app screenshots, which we demonstrate within the context an interactive application for rapidly acquiring digital prototypes of user experience (UX) designs.
A Multi-Implicit Neural Representation for Fonts
Jun 12, 2021
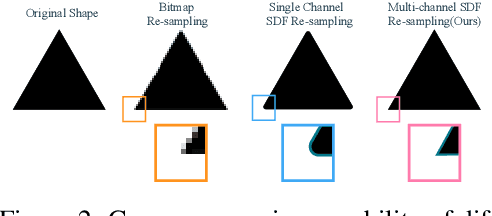
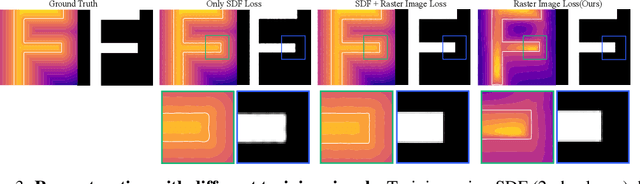

Fonts are ubiquitous across documents and come in a variety of styles. They are either represented in a native vector format or rasterized to produce fixed resolution images. In the first case, the non-standard representation prevents benefiting from latest network architectures for neural representations; while, in the latter case, the rasterized representation, when encoded via networks, results in loss of data fidelity, as font-specific discontinuities like edges and corners are difficult to represent using neural networks. Based on the observation that complex fonts can be represented by a superposition of a set of simpler occupancy functions, we introduce \textit{multi-implicits} to represent fonts as a permutation-invariant set of learned implict functions, without losing features (e.g., edges and corners). However, while multi-implicits locally preserve font features, obtaining supervision in the form of ground truth multi-channel signals is a problem in itself. Instead, we propose how to train such a representation with only local supervision, while the proposed neural architecture directly finds globally consistent multi-implicits for font families. We extensively evaluate the proposed representation for various tasks including reconstruction, interpolation, and synthesis to demonstrate clear advantages with existing alternatives. Additionally, the representation naturally enables glyph completion, wherein a single characteristic font is used to synthesize a whole font family in the target style.