 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3D-WAG: Hierarchical Wavelet-Guided Autoregressive Generation for High-Fidelity 3D Shapes
Nov 28, 2024



Autoregressive (AR) models have achieved remarkable success in natural language and image generation, but their application to 3D shape modeling remains largely unexplored. Unlike diffusion models, AR models enable more efficient and controllable generation with faster inference times, making them especially suitable for data-intensive domains. Traditional 3D generative models using AR approaches often rely on ``next-token" predictions at the voxel or point level. While effective for certain applications, these methods can be restrictive and computationally expensive when dealing with large-scale 3D data. To tackle these challenges, we introduce 3D-WAG, an AR model for 3D implicit distance fields that can perform unconditional shape generation, class-conditioned and also text-conditioned shape generation. Our key idea is to encode shapes as multi-scale wavelet token maps and use a Transformer to predict the ``next higher-resolution token map" in an autoregressive manner. By redefining 3D AR generation task as ``next-scale" prediction, we reduce the computational cost of generation compared to traditional ``next-token" prediction models, while preserving essential geometric details of 3D shapes in a more structured and hierarchical manner. We evaluate 3D-WAG to showcase its benefit by quantitative and qualitative comparisons with state-of-the-art methods on widely used benchmarks. Our results show 3D-WAG achieves superior performance in key metrics like Coverage and MMD, generating high-fidelity 3D shapes that closely match the real data distribution.
Wavelet Latent Diffusion (Wala): Billion-Parameter 3D Generative Model with Compact Wavelet Encodings
Nov 12, 2024



Large-scale 3D generative models require substantial computational resources yet often fall short in capturing fine details and complex geometries at high resolutions. We attribute this limitation to the inefficiency of current representations, which lack the compactness required to model the generative models effectively. To address this, we introduce a novel approach called Wavelet Latent Diffusion, or WaLa, that encodes 3D shapes into wavelet-based, compact latent encodings. Specifically, we compress a $256^3$ signed distance field into a $12^3 \times 4$ latent grid, achieving an impressive 2427x compression ratio with minimal loss of detail. This high level of compression allows our method to efficiently train large-scale generative networks without increasing the inference time. Our models, both conditional and unconditional, contain approximately one billion parameters and successfully generate high-quality 3D shapes at $256^3$ resolution. Moreover, WaLa offers rapid inference, producing shapes within two to four seconds depending on the condition, despite the model's scale. We demonstrate state-of-the-art performance across multiple datasets, with significant improvements in generation quality, diversity, and computational efficiency. We open-source our code and, to the best of our knowledge, release the largest pretrained 3D generative models across different modalities.
VeLoRA: Memory Efficient Training using Rank-1 Sub-Token Projections
May 28, 2024



Large language models (LLMs) have recently emerged as powerful tools for tackling many language-processing tasks. Despite their success, training and fine-tuning these models is still far too computationally and memory intensive. In this paper, we identify and characterise the important components needed for effective model convergence using gradient descent. In doing so we find that the intermediate activations used to implement backpropagation can be excessively compressed without incurring any degradation in performance. This result leads us to a cheap and memory-efficient algorithm for both fine-tuning and pre-training LLMs. The proposed algorithm simply divides the tokens up into smaller sub-tokens before projecting them onto a fixed 1-dimensional subspace during the forward pass. These features are then coarsely reconstructed during the backward pass to implement the update rules. We confirm the effectiveness of our algorithm as being complimentary to many state-of-the-art PEFT methods on the VTAB-1k fine-tuning benchmark. Furthermore, we outperform QLoRA for fine-tuning LLaMA and show competitive performance against other memory-efficient pre-training methods on the large-scale C4 dataset.
G3DR: Generative 3D Reconstruction in ImageNet
Mar 08, 2024



We introduce a novel 3D generative method, Generative 3D Reconstruction (G3DR) in ImageNet, capable of generating diverse and high-quality 3D objects from single images, addressing the limitations of existing methods. At the heart of our framework is a novel depth regularization technique that enables the generation of scenes with high-geometric fidelity. G3DR also leverages a pretrained language-vision model, such as CLIP, to enable reconstruction in novel views and improve the visual realism of generations. Additionally, G3DR designs a simple but effective sampling procedure to further improve the quality of generations. G3DR offers diverse and efficient 3D asset generation based on class or text conditioning. Despite its simplicity, G3DR is able to beat state-of-theart methods, improving over them by up to 22% in perceptual metrics and 90% in geometry scores, while needing only half of the training time. Code is available at https://github.com/preddy5/G3DR
AvatarMMC: 3D Head Avatar Generation and Editing with Multi-Modal Conditioning
Feb 08, 2024We introduce an approach for 3D head avatar generation and editing with multi-modal conditioning based on a 3D Generative Adversarial Network (GAN) and a Latent Diffusion Model (LDM). 3D GANs can generate high-quality head avatars given a single or no condition. However, it is challenging to generate samples that adhere to multiple conditions of different modalities. On the other hand, LDMs excel at learning complex conditional distributions. To this end, we propose to exploit the conditioning capabilities of LDMs to enable multi-modal control over the latent space of a pre-trained 3D GAN. Our method can generate and edit 3D head avatars given a mixture of control signals such as RGB input, segmentation masks, and global attributes. This provides better control over the generation and editing of synthetic avatars both globally and locally. Experiments show that our proposed approach outperforms a solely GAN-based approach both qualitatively and quantitatively on generation and editing tasks. To the best of our knowledge, our approach is the first to introduce multi-modal conditioning to 3D avatar generation and editing. \\href{avatarmmc-sig24.github.io}{Project Page}
AudioSlots: A slot-centric generative model for audio separation
May 09, 2023In a range of recent works, object-centric architectures have been shown to be suitable for unsupervised scene decomposition in the vision domain. Inspired by these methods we present AudioSlots, a slot-centric generative model for blind source separation in the audio domain. AudioSlots is built using permutation-equivariant encoder and decoder networks. The encoder network based on the Transformer architecture learns to map a mixed audio spectrogram to an unordered set of independent source embeddings. The spatial broadcast decoder network learns to generate the source spectrograms from the source embeddings. We train the model in an end-to-end manner using a permutation invariant loss function. Our results on Libri2Mix speech separation constitute a proof of concept that this approach shows promise. We discuss the results and limitations of our approach in detail, and further outline potential ways to overcome the limitations and directions for future work.
Search for Concepts: Discovering Visual Concepts Using Direct Optimization
Oct 25, 2022Finding an unsupervised decomposition of an image into individual objects is a key step to leverage compositionality and to perform symbolic reasoning. Traditionally, this problem is solved using amortized inference, which does not generalize beyond the scope of the training data, may sometimes miss correct decompositions, and requires large amounts of training data. We propose finding a decomposition using direct, unamortized optimization, via a combination of a gradient-based optimization for differentiable object properties and global search for non-differentiable properties. We show that using direct optimization is more generalizable, misses fewer correct decompositions, and typically requires less data than methods based on amortized inference. This highlights a weakness of the current prevalent practice of using amortized inference that can potentially be improved by integrating more direct optimization elements.
A Multi-Implicit Neural Representation for Fonts
Jun 12, 2021
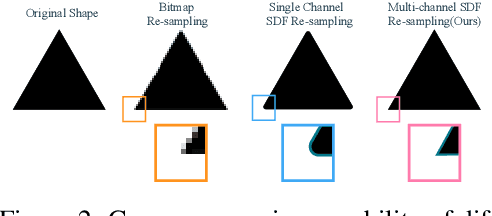
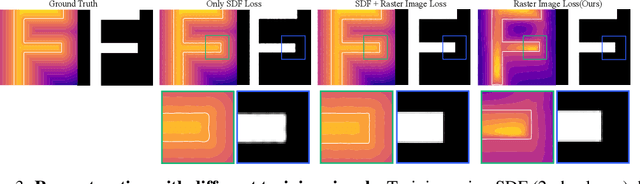

Fonts are ubiquitous across documents and come in a variety of styles. They are either represented in a native vector format or rasterized to produce fixed resolution images. In the first case, the non-standard representation prevents benefiting from latest network architectures for neural representations; while, in the latter case, the rasterized representation, when encoded via networks, results in loss of data fidelity, as font-specific discontinuities like edges and corners are difficult to represent using neural networks. Based on the observation that complex fonts can be represented by a superposition of a set of simpler occupancy functions, we introduce \textit{multi-implicits} to represent fonts as a permutation-invariant set of learned implict functions, without losing features (e.g., edges and corners). However, while multi-implicits locally preserve font features, obtaining supervision in the form of ground truth multi-channel signals is a problem in itself. Instead, we propose how to train such a representation with only local supervision, while the proposed neural architecture directly finds globally consistent multi-implicits for font families. We extensively evaluate the proposed representation for various tasks including reconstruction, interpolation, and synthesis to demonstrate clear advantages with existing alternatives. Additionally, the representation naturally enables glyph completion, wherein a single characteristic font is used to synthesize a whole font family in the target style.
Im2Vec: Synthesizing Vector Graphics without Vector Supervision
Feb 04, 2021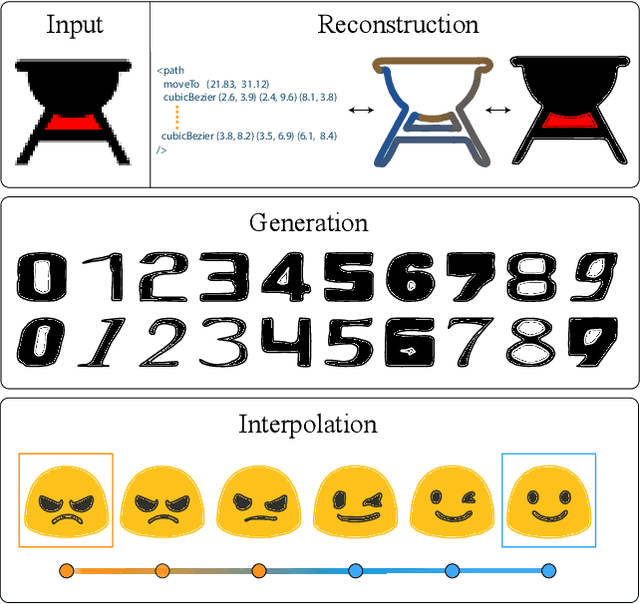
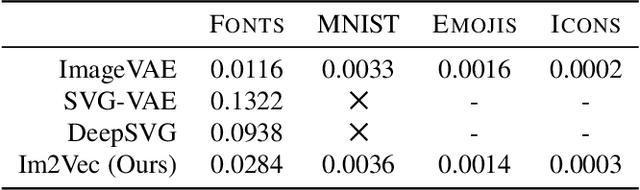

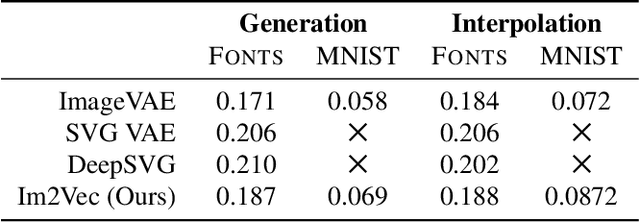
Vector graphics are widely used to represent fonts, logos, digital artworks, and graphic designs. But, while a vast body of work has focused on generative algorithms for raster images, only a handful of options exists for vector graphics. One can always rasterize the input graphic and resort to image-based generative approaches, but this negates the advantages of the vector representation. The current alternative is to use specialized models that require explicit supervision on the vector graphics representation at training time. This is not ideal because large-scale high quality vector-graphics datasets are difficult to obtain. Furthermore, the vector representation for a given design is not unique, so models that supervise on the vector representation are unnecessarily constrained. Instead, we propose a new neural network that can generate complex vector graphics with varying topologies, and only requires indirect supervision from readily-available raster training images (i.e., with no vector counterparts). To enable this, we use a differentiable rasterization pipeline that renders the generated vector shapes and composites them together onto a raster canvas. We demonstrate our method on a range of datasets, and provide comparison with state-of-the-art SVG-VAE and DeepSVG, both of which require explicit vector graphics supervision. Finally, we also demonstrate our approach on the MNIST dataset, for which no groundtruth vector representation is available. Source code, datasets, and more results are available at http://geometry.cs.ucl.ac.uk/projects/2020/Im2Vec/
Discovering Pattern Structure Using Differentiable Compositing
Oct 17, 2020

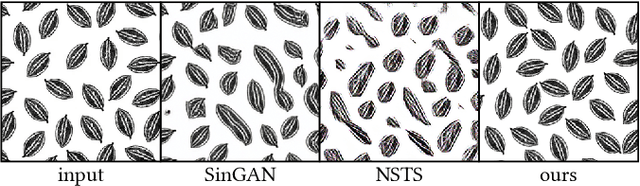
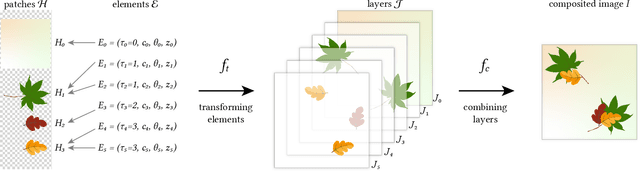
Patterns, which are collections of elements arranged in regular or near-regular arrangements, are an important graphic art form and widely used due to their elegant simplicity and aesthetic appeal. When a pattern is encoded as a flat image without the underlying structure, manually editing the pattern is tedious and challenging as one has to both preserve the individual element shapes and their original relative arrangements. State-of-the-art deep learning frameworks that operate at the pixel level are unsuitable for manipulating such patterns. Specifically, these methods can easily disturb the shapes of the individual elements or their arrangement, and thus fail to preserve the latent structures of the input patterns. We present a novel differentiable compositing operator using pattern elements and use it to discover structures, in the form of a layered representation of graphical objects, directly from raw pattern images. This operator allows us to adapt current deep learning based image methods to effectively handle patterns. We evaluate our method on a range of patterns and demonstrate superiority in the context of pattern manipulations when compared against state-of-the-art