 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNTIRE 2021 Challenge on Quality Enhancement of Compressed Video: Methods and Results
May 02, 2021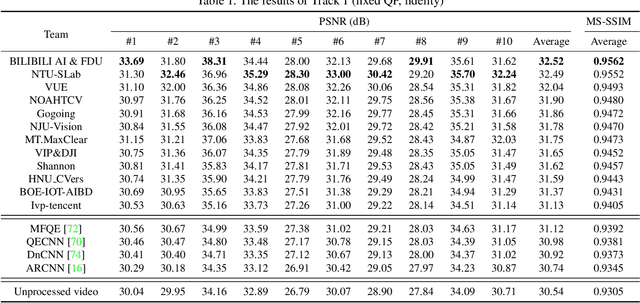
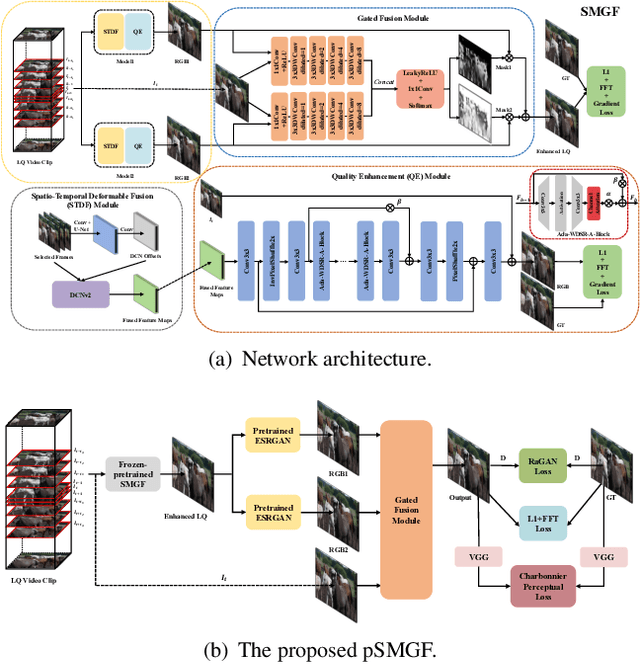
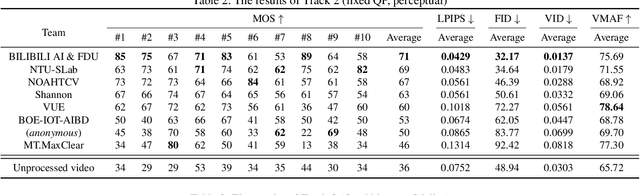
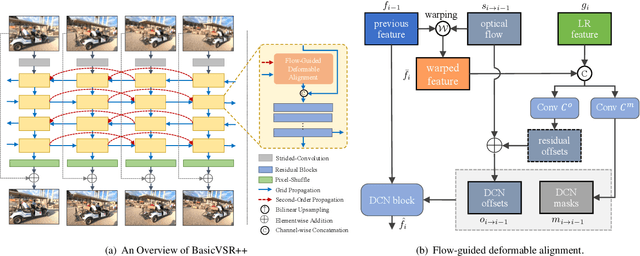
This paper reviews the first NTIRE challenge on quality enhancement of compressed video, with a focus on the proposed methods and results. In this challenge, the new Large-scale Diverse Video (LDV) dataset is employed. The challenge has three tracks. Tracks 1 and 2 aim at enhancing the videos compressed by HEVC at a fixed QP, while Track 3 is designed for enhancing the videos compressed by x265 at a fixed bit-rate. Besides, the quality enhancement of Tracks 1 and 3 targets at improving the fidelity (PSNR), and Track 2 targets at enhancing the perceptual quality. The three tracks totally attract 482 registrations. In the test phase, 12 teams, 8 teams and 11 teams submitted the final results of Tracks 1, 2 and 3, respectively. The proposed methods and solutions gauge the state-of-the-art of video quality enhancement. The homepage of the challenge: https://github.com/RenYang-home/NTIRE21_VEnh
Constrained Radar Waveform Design for Range Profiling
Mar 18, 2021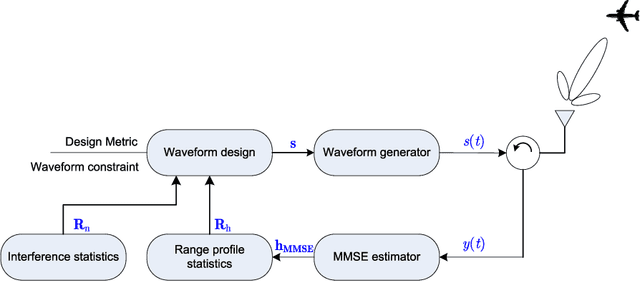
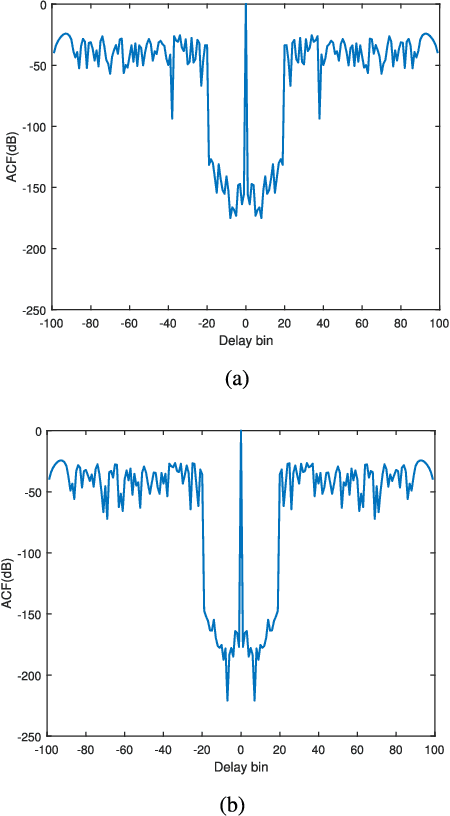
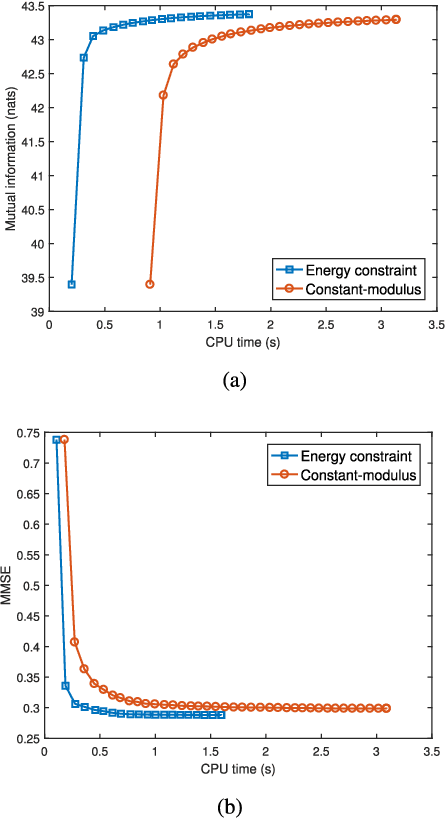
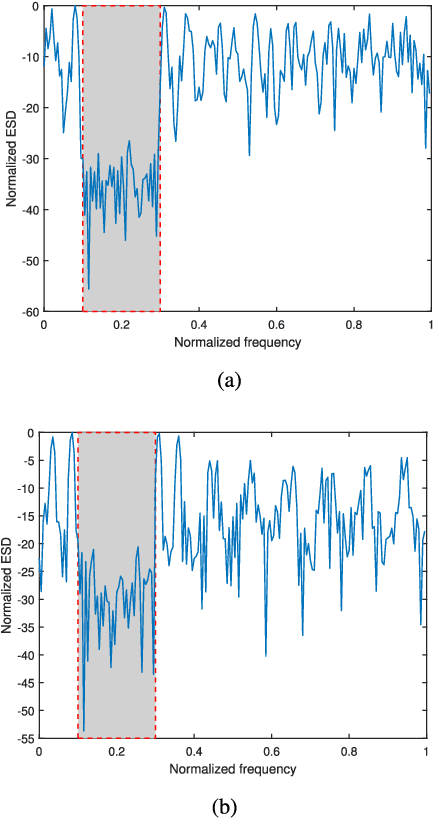
Range profiling refers to the measurement of target response along the radar slant range. It plays an important role in automatic target recognition. In this paper, we consider the design of transmit waveform to improve the range profiling performance of radar systems. Two design metrics are adopted for the waveform optimization problem: one is to maximize the mutual information between the received signal and the target impulse response (TIR); the other is to minimize the minimum mean-square error for estimating the TIR. In addition, practical constraints on the waveforms are considered, including an energy constraint, a peak-to-average-power-ratio constraint, and a spectral constraint. Based on minorization-maximization, we propose a unified optimization framework to tackle the constrained waveform design problem. Numerical examples show the superiority of the waveforms synthesized by the proposed algorithms.
Contextual Heterogeneous Graph Network for Human-Object Interaction Detection
Oct 20, 2020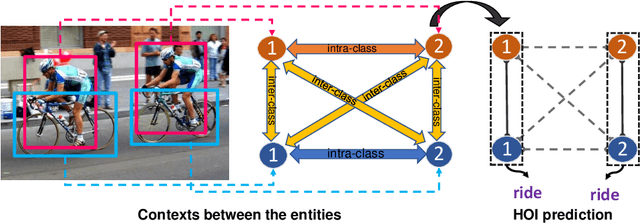
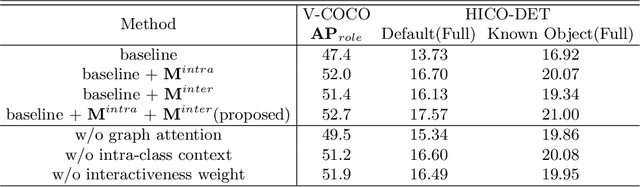
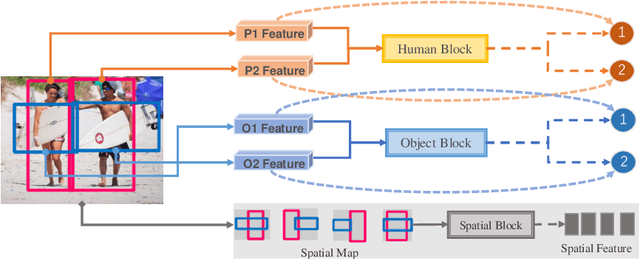

Human-object interaction(HOI) detection is an important task for understanding human activity. Graph structure is appropriate to denote the HOIs in the scene. Since there is an subordination between human and object---human play subjective role and object play objective role in HOI, the relations between homogeneous entities and heterogeneous entities in the scene should also not be equally the same. However, previous graph models regard human and object as the same kind of nodes and do not consider that the messages are not equally the same between different entities. In this work, we address such a problem for HOI task by proposing a heterogeneous graph network that models humans and objects as different kinds of nodes and incorporates intra-class messages between homogeneous nodes and inter-class messages between heterogeneous nodes. In addition, a graph attention mechanism based on the intra-class context and inter-class context is exploited to improve the learning. Extensive experiments on the benchmark datasets V-COCO and HICO-DET demonstrate that the intra-class and inter-class messages are very important in HOI detection and verify the effectiveness of our method.
Knowledge Efficient Deep Learning for Natural Language Processing
Aug 28, 2020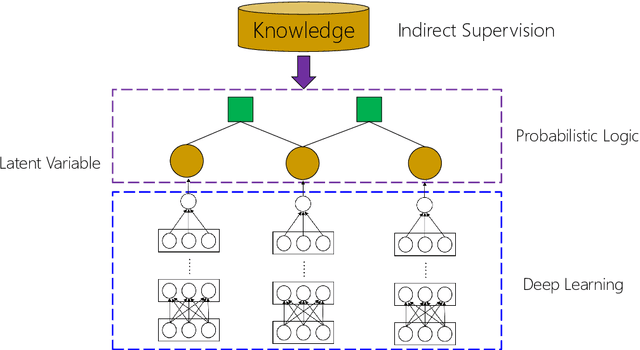
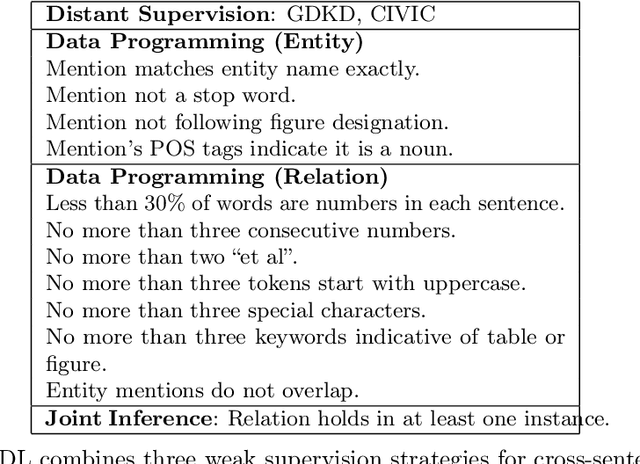

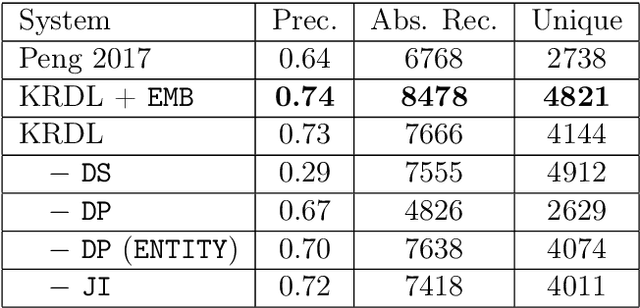
Deep learning has become the workhorse for a wide range of natural language processing applications. But much of the success of deep learning relies on annotated examples. Annotation is time-consuming and expensive to produce at scale. Here we are interested in methods for reducing the required quantity of annotated data -- by making the learning methods more knowledge efficient so as to make them more applicable in low annotation (low resource) settings. There are various classical approaches to making the models more knowledge efficient such as multi-task learning, transfer learning, weakly supervised and unsupervised learning etc. This thesis focuses on adapting such classical methods to modern deep learning models and algorithms. This thesis describes four works aimed at making machine learning models more knowledge efficient. First, we propose a knowledge rich deep learning model (KRDL) as a unifying learning framework for incorporating prior knowledge into deep models. In particular, we apply KRDL built on Markov logic networks to denoise weak supervision. Second, we apply a KRDL model to assist the machine reading models to find the correct evidence sentences that can support their decision. Third, we investigate the knowledge transfer techniques in multilingual setting, where we proposed a method that can improve pre-trained multilingual BERT based on the bilingual dictionary. Fourth, we present an episodic memory network for language modelling, in which we encode the large external knowledge for the pre-trained GPT.
On-The-Fly Information Retrieval Augmentation for Language Models
Jul 03, 2020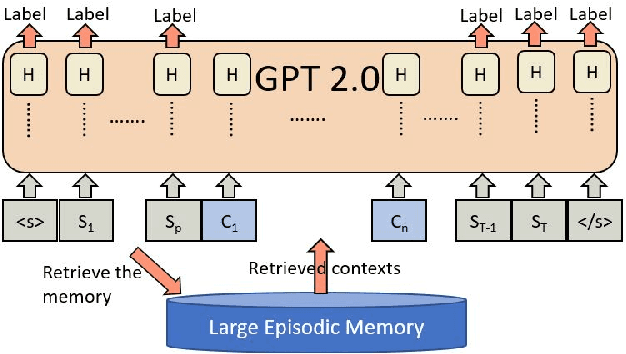

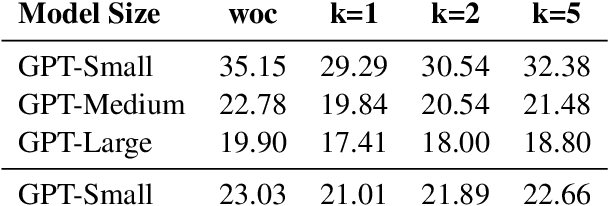
Here we experiment with the use of information retrieval as an augmentation for pre-trained language models. The text corpus used in information retrieval can be viewed as form of episodic memory which grows over time. By augmenting GPT 2.0 with information retrieval we achieve a zero shot 15% relative reduction in perplexity on Gigaword corpus without any re-training. We also validate our IR augmentation on an event co-reference task.
MixPUL: Consistency-based Augmentation for Positive and Unlabeled Learning
Apr 20, 2020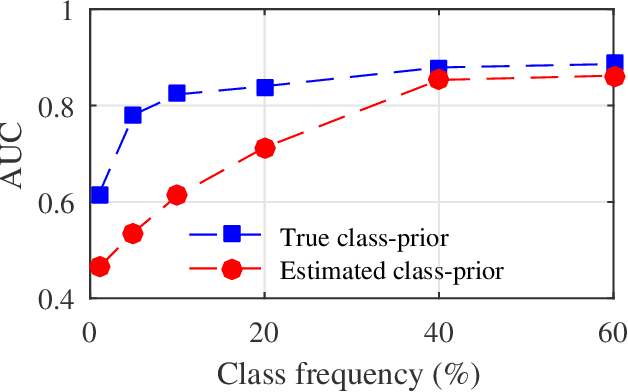
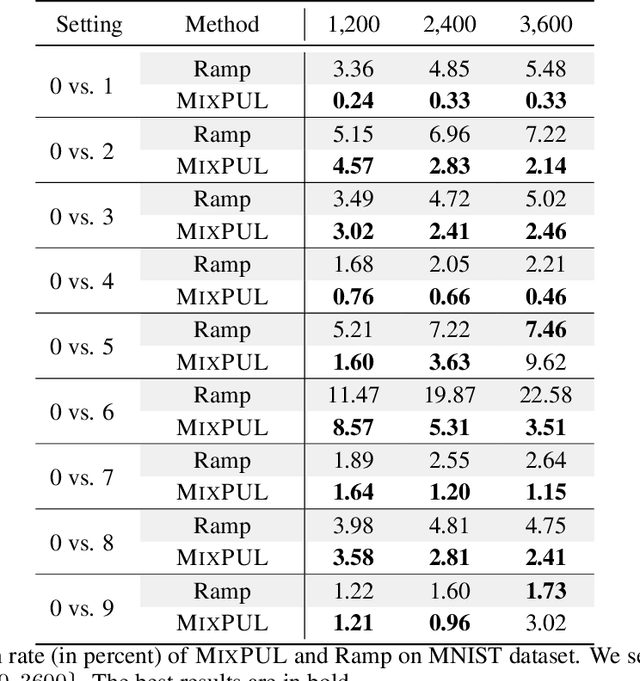
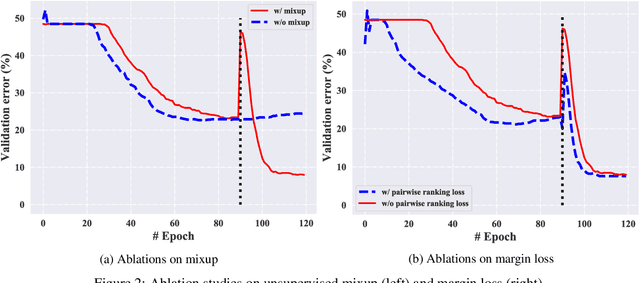
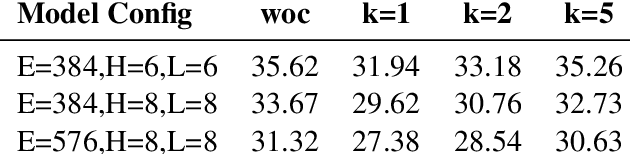
Learning from positive and unlabeled data (PU learning) is prevalent in practical applications where only a couple of examples are positively labeled. Previous PU learning studies typically rely on existing samples such that the data distribution is not extensively explored. In this work, we propose a simple yet effective data augmentation method, coined~\algo, based on \emph{consistency regularization} which provides a new perspective of using PU data. In particular, the proposed~\algo~incorporates supervised and unsupervised consistency training to generate augmented data. To facilitate supervised consistency, reliable negative examples are mined from unlabeled data due to the absence of negative samples. Unsupervised consistency is further encouraged between unlabeled datapoints. In addition,~\algo~reduces margin loss between positive and unlabeled pairs, which explicitly optimizes AUC and yields faster convergence. Finally, we conduct a series of studies to demonstrate the effectiveness of consistency regularization. We examined three kinds of reliable negative mining methods. We show that~\algo~achieves an averaged improvement of classification error from 16.49 to 13.09 on the CIFAR-10 dataset across different positive data amount.
Improving Pre-Trained Multilingual Models with Vocabulary Expansion
Sep 26, 2019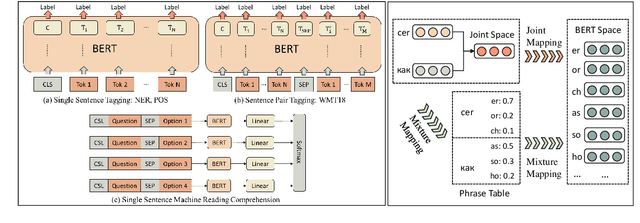
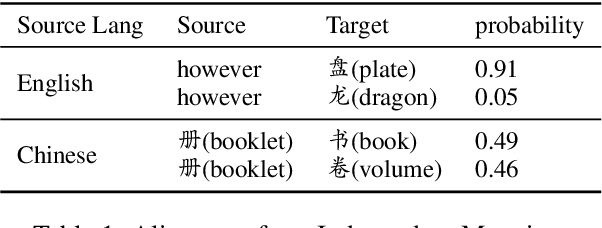
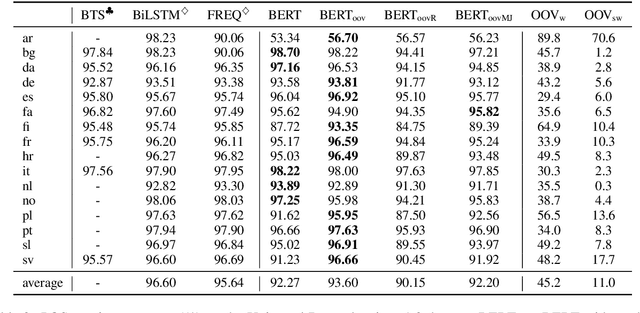
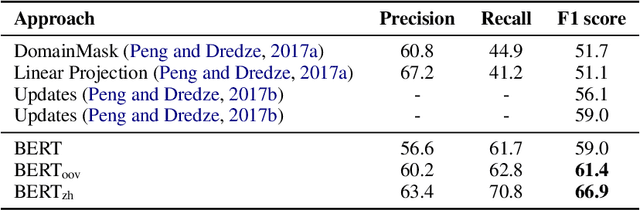
Recently, pre-trained language models have achieved remarkable success in a broad range of natural language processing tasks. However, in multilingual setting, it is extremely resource-consuming to pre-train a deep language model over large-scale corpora for each language. Instead of exhaustively pre-training monolingual language models independently, an alternative solution is to pre-train a powerful multilingual deep language model over large-scale corpora in hundreds of languages. However, the vocabulary size for each language in such a model is relatively small, especially for low-resource languages. This limitation inevitably hinders the performance of these multilingual models on tasks such as sequence labeling, wherein in-depth token-level or sentence-level understanding is essential. In this paper, inspired by previous methods designed for monolingual settings, we investigate two approaches (i.e., joint mapping and mixture mapping) based on a pre-trained multilingual model BERT for addressing the out-of-vocabulary (OOV) problem on a variety of tasks, including part-of-speech tagging, named entity recognition, machine translation quality estimation, and machine reading comprehension. Experimental results show that using mixture mapping is more promising. To the best of our knowledge, this is the first work that attempts to address and discuss the OOV issue in multilingual settings.
Evidence Sentence Extraction for Machine Reading Comprehension
Feb 23, 2019
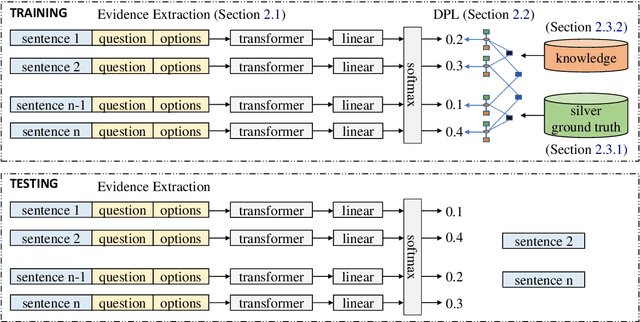
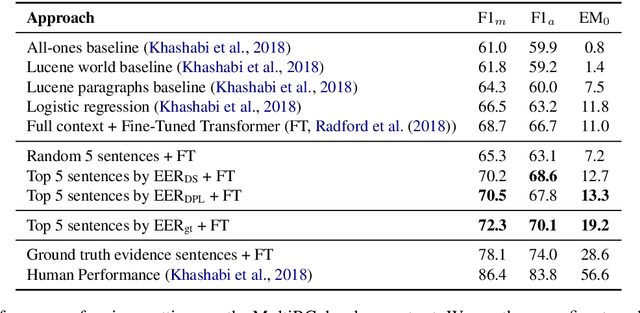
Recently remarkable success has been achieved in machine reading comprehension (MRC). However, it is still difficult to interpret the predictions of existing MRC models. In this paper, we focus on: extracting evidence sentences that can explain/support answer predictions for multiple-choice MRC tasks, where the majority of answer options cannot be directly extracted from reference documents; studying the impacts of using the extracted sentences as the input of MRC models. Due to the lack of ground truth evidence sentence labels in most cases, we apply distant supervision to generate imperfect labels and then use them to train a neural evidence extractor. To denoise the noisy labels, we treat labels as latent variables and define priors over these latent variables by incorporating rich linguistic knowledge under a recently proposed deep probabilistic logic learning framework. We feed the extracted evidence sentences into existing MRC models and evaluate the end-to-end performance on three challenging multiple-choice MRC datasets: MultiRC, DREAM, and RACE, achieving comparable or better performance than the same models that take the full context as input. Our evidence extractor also outperforms a state-of-the-art sentence selector by a large margin on two open-domain question answering datasets: Quasar-T and SearchQA. To the best of our knowledge, this is the first work addressing evidence sentence extraction for multiple-choice MRC.
To Compress, or Not to Compress: Characterizing Deep Learning Model Compression for Embedded Inference
Oct 21, 2018
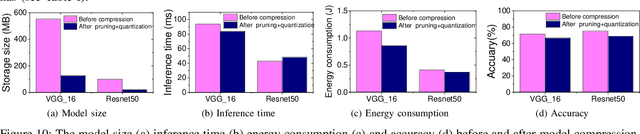

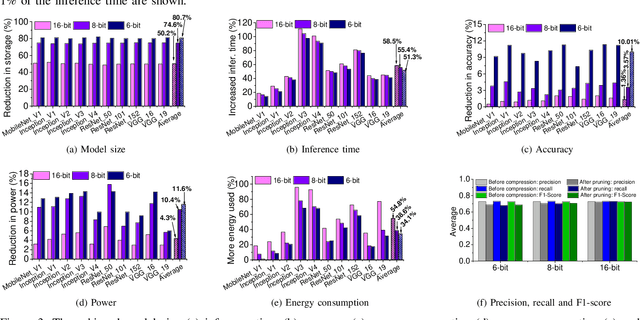
The recent advances in deep neural networks (DNNs) make them attractive for embedded systems. However, it can take a long time for DNNs to make an inference on resource-constrained computing devices. Model compression techniques can address the computation issue of deep inference on embedded devices. This technique is highly attractive, as it does not rely on specialized hardware, or computation-offloading that is often infeasible due to privacy concerns or high latency. However, it remains unclear how model compression techniques perform across a wide range of DNNs. To design efficient embedded deep learning solutions, we need to understand their behaviors. This work develops a quantitative approach to characterize model compression techniques on a representative embedded deep learning architecture, the NVIDIA Jetson Tx2. We perform extensive experiments by considering 11 influential neural network architectures from the image classification and the natural language processing domains. We experimentally show that how two mainstream compression techniques, data quantization and pruning, perform on these network architectures and the implications of compression techniques to the model storage size, inference time, energy consumption and performance metrics. We demonstrate that there are opportunities to achieve fast deep inference on embedded systems, but one must carefully choose the compression settings. Our results provide insights on when and how to apply model compression techniques and guidelines for designing efficient embedded deep learning systems.
Learning to Globally Edit Images with Textual Description
Oct 13, 2018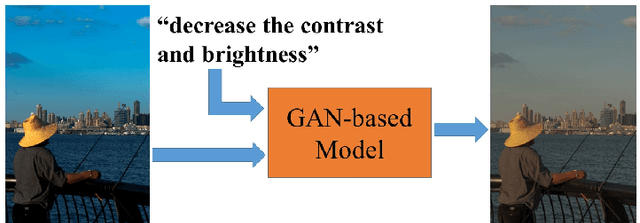


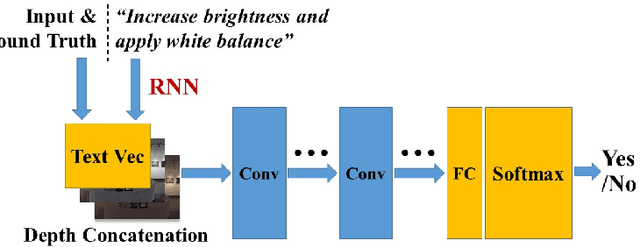
We show how we can globally edit images using textual instructions: given a source image and a textual instruction for the edit, generate a new image transformed under this instruction. To tackle this novel problem, we develop three different trainable models based on RNN and Generative Adversarial Network (GAN). The models (bucket, filter bank, and end-to-end) differ in how much expert knowledge is encoded, with the most general version being purely end-to-end. To train these systems, we use Amazon Mechanical Turk to collect textual descriptions for around 2000 image pairs sampled from several datasets. Experimental results evaluated on our dataset validate our approaches. In addition, given that the filter bank model is a good compromise between generality and performance, we investigate it further by replacing RNN with Graph RNN, and show that Graph RNN improves performance. To the best of our knowledge, this is the first computational photography work on global image editing that is purely based on free-form textual instructions.