 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePartial Wasserstein Adversarial Network for Non-rigid Point Set Registration
Mar 04, 2022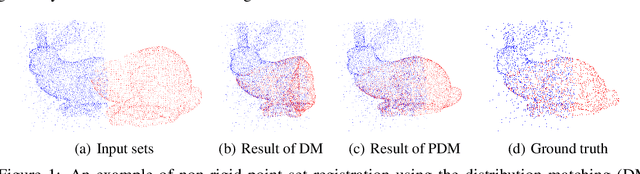

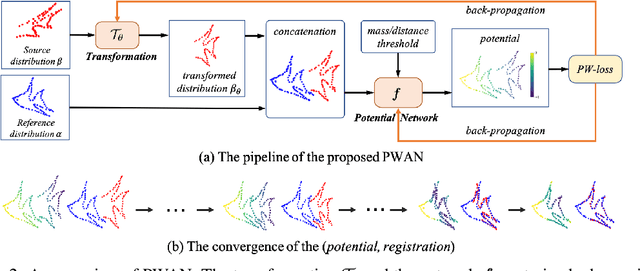

Given two point sets, the problem of registration is to recover a transformation that matches one set to the other. This task is challenging due to the presence of the large number of outliers, the unknown non-rigid deformations and the large sizes of point sets. To obtain strong robustness against outliers, we formulate the registration problem as a partial distribution matching (PDM) problem, where the goal is to partially match the distributions represented by point sets in a metric space. To handle large point sets, we propose a scalable PDM algorithm by utilizing the efficient partial Wasserstein-1 (PW) discrepancy. Specifically, we derive the Kantorovich-Rubinstein duality for the PW discrepancy, and show its gradient can be explicitly computed. Based on these results, we propose a partial Wasserstein adversarial network (PWAN), which is able to approximate the PW discrepancy by a neural network, and minimize it by gradient descent. In addition, it also incorporates an efficient coherence regularizer for non-rigid transformations to avoid unrealistic deformations. We evaluate PWAN on practical point set registration tasks, and show that the proposed PWAN is robust, scalable and performs more favorably than the state-of-the-art methods.
Aerial Scene Parsing: From Tile-level Scene Classification to Pixel-wise Semantic Labeling
Jan 09, 2022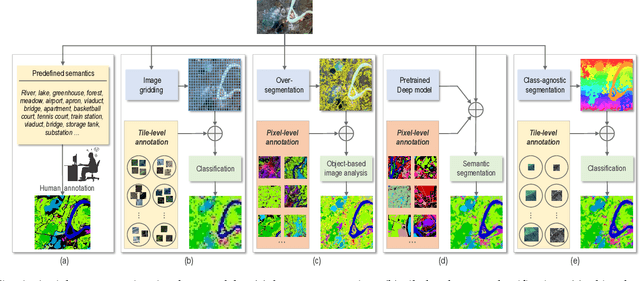
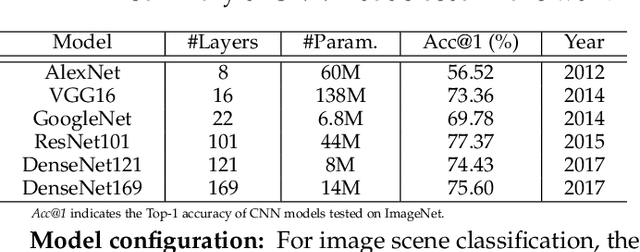
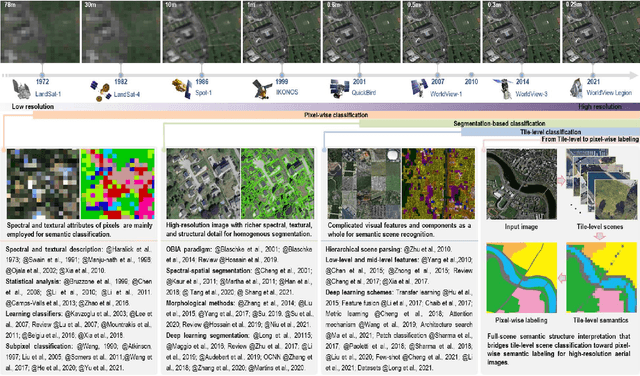

Given an aerial image, aerial scene parsing (ASP) targets to interpret the semantic structure of the image content, e.g., by assigning a semantic label to every pixel of the image. With the popularization of data-driven methods, the past decades have witnessed promising progress on ASP by approaching the problem with the schemes of tile-level scene classification or segmentation-based image analysis, when using high-resolution aerial images. However, the former scheme often produces results with tile-wise boundaries, while the latter one needs to handle the complex modeling process from pixels to semantics, which often requires large-scale and well-annotated image samples with pixel-wise semantic labels. In this paper, we address these issues in ASP, with perspectives from tile-level scene classification to pixel-wise semantic labeling. Specifically, we first revisit aerial image interpretation by a literature review. We then present a large-scale scene classification dataset that contains one million aerial images termed Million-AID. With the presented dataset, we also report benchmarking experiments using classical convolutional neural networks (CNNs). Finally, we perform ASP by unifying the tile-level scene classification and object-based image analysis to achieve pixel-wise semantic labeling. Intensive experiments show that Million-AID is a challenging yet useful dataset, which can serve as a benchmark for evaluating newly developed algorithms. When transferring knowledge from Million-AID, fine-tuning CNN models pretrained on Million-AID perform consistently better than those pretrained ImageNet for aerial scene classification. Moreover, our designed hierarchical multi-task learning method achieves the state-of-the-art pixel-wise classification on the challenging GID, bridging the tile-level scene classification toward pixel-wise semantic labeling for aerial image interpretation.
Decoupling Zero-Shot Semantic Segmentation
Dec 15, 2021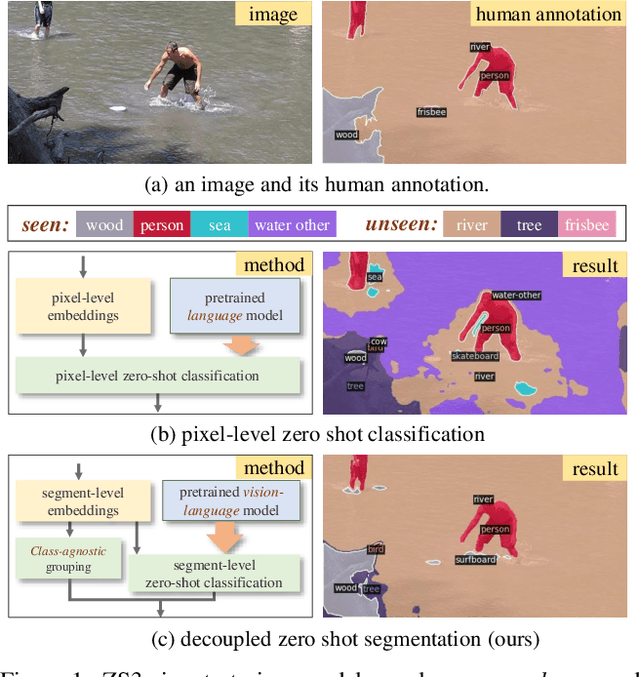
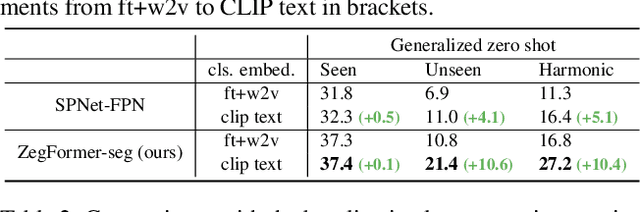
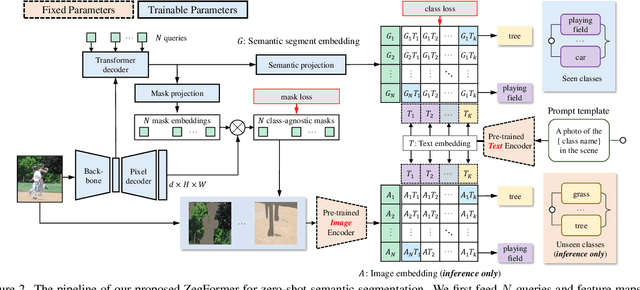
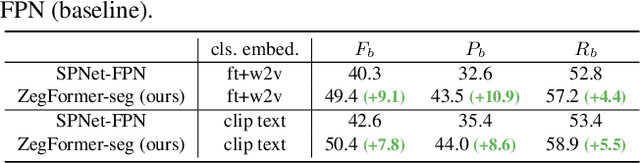
Zero-shot semantic segmentation (ZS3) aims to segment the novel categories that have not been seen in the training. Existing works formulate ZS3 as a pixel-level zero-shot classification problem, and transfer semantic knowledge from seen classes to unseen ones with the help of language models pre-trained only with texts. While simple, the pixel-level ZS3 formulation shows the limited capability to integrate vision-language models that are often pre-trained with image-text pairs and currently demonstrate great potential for vision tasks. Inspired by the observation that humans often perform segment-level semantic labeling, we propose to decouple the ZS3 into two sub-tasks: 1) a class-agnostic grouping task to group the pixels into segments. 2) a zero-shot classification task on segments. The former sub-task does not involve category information and can be directly transferred to group pixels for unseen classes. The latter subtask performs at segment-level and provides a natural way to leverage large-scale vision-language models pre-trained with image-text pairs (e.g. CLIP) for ZS3. Based on the decoupling formulation, we propose a simple and effective zero-shot semantic segmentation model, called ZegFormer, which outperforms the previous methods on ZS3 standard benchmarks by large margins, e.g., 35 points on the PASCAL VOC and 3 points on the COCO-Stuff in terms of mIoU for unseen classes. Code will be released at https://github.com/dingjiansw101/ZegFormer.
Hidden Path Selection Network for Semantic Segmentation of Remote Sensing Images
Dec 09, 2021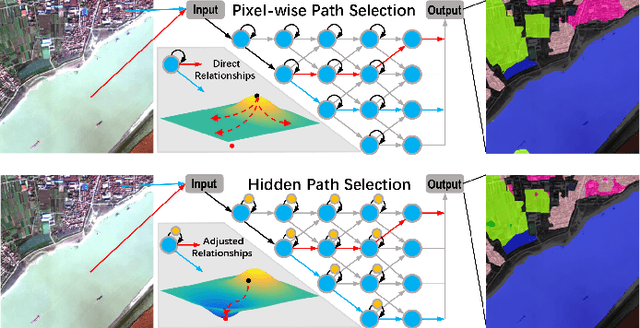
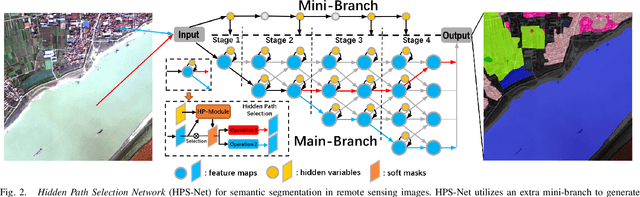
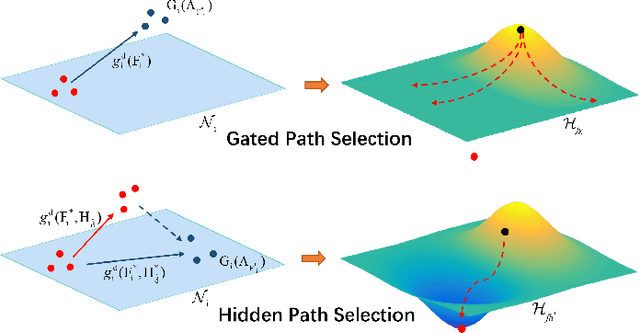
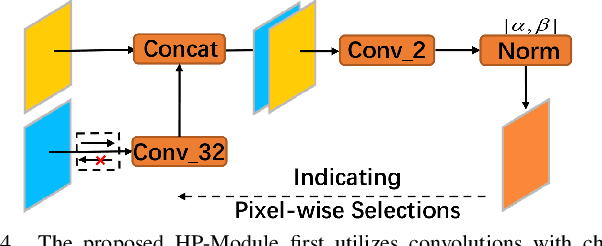
Targeting at depicting land covers with pixel-wise semantic categories, semantic segmentation in remote sensing images needs to portray diverse distributions over vast geographical locations, which is difficult to be achieved by the homogeneous pixel-wise forward paths in the architectures of existing deep models. Although several algorithms have been designed to select pixel-wise adaptive forward paths for natural image analysis, it still lacks theoretical supports on how to obtain optimal selections. In this paper, we provide mathematical analyses in terms of the parameter optimization, which guides us to design a method called Hidden Path Selection Network (HPS-Net). With the help of hidden variables derived from an extra mini-branch, HPS-Net is able to tackle the inherent problem about inaccessible global optimums by adjusting the direct relationships between feature maps and pixel-wise path selections in existing algorithms, which we call hidden path selection. For the better training and evaluation, we further refine and expand the 5-class Gaofen Image Dataset (GID-5) to a new one with 15 land-cover categories, i.e., GID-15. The experimental results on both GID-5 and GID-15 demonstrate that the proposed modules can stably improve the performance of different deep structures, which validates the proposed mathematical analyses.
Motion Deblurring with Real Events
Sep 28, 2021
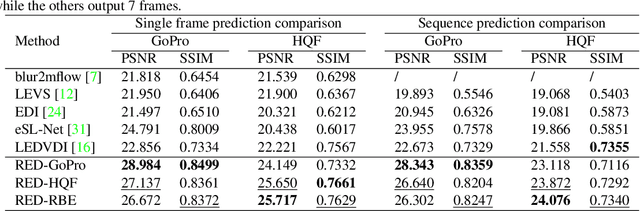
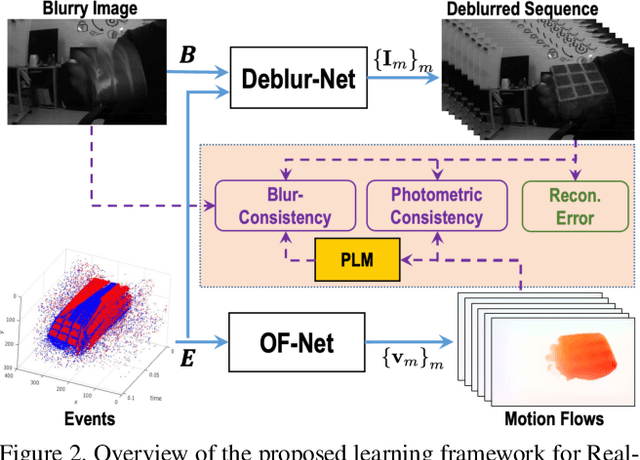
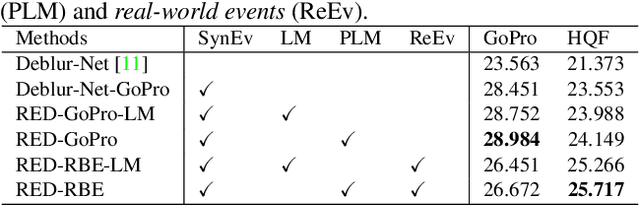
In this paper, we propose an end-to-end learning framework for event-based motion deblurring in a self-supervised manner, where real-world events are exploited to alleviate the performance degradation caused by data inconsistency. To achieve this end, optical flows are predicted from events, with which the blurry consistency and photometric consistency are exploited to enable self-supervision on the deblurring network with real-world data. Furthermore, a piece-wise linear motion model is proposed to take into account motion non-linearities and thus leads to an accurate model for the physical formation of motion blurs in the real-world scenario. Extensive evaluation on both synthetic and real motion blur datasets demonstrates that the proposed algorithm bridges the gap between simulated and real-world motion blurs and shows remarkable performance for event-based motion deblurring in real-world scenarios.
Learning Local-Global Contextual Adaptation for Fully End-to-End Bottom-Up Human Pose Estimation
Sep 08, 2021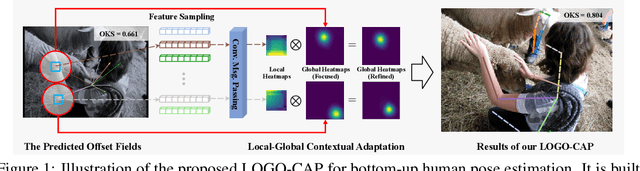
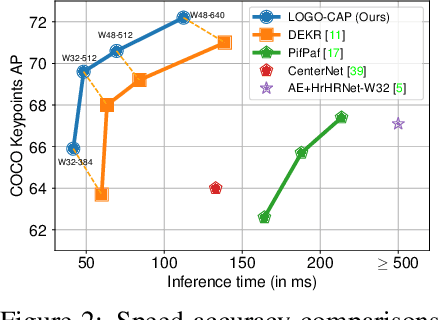
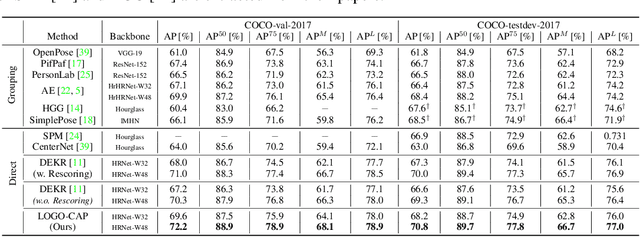
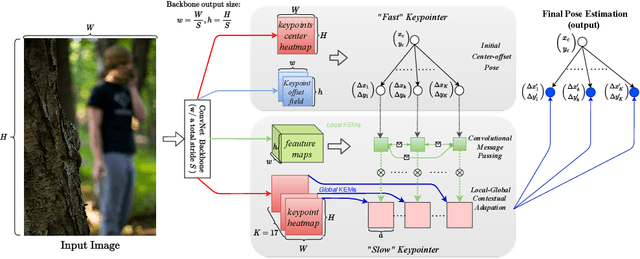
This paper presents a method of learning Local-GlObal Contextual Adaptation for fully end-to-end and fast bottom-up human Pose estimation, dubbed as LOGO-CAP. It is built on the conceptually simple center-offset formulation that lacks inaccuracy for pose estimation. When revisiting the bottom-up human pose estimation with the thought of "thinking, fast and slow" by D. Kahneman, we introduce a "slow keypointer" to remedy the lack of sufficient accuracy of the "fast keypointer". In learning the "slow keypointer", the proposed LOGO-CAP lifts the initial "fast" keypoints by offset predictions to keypoint expansion maps (KEMs) to counter their uncertainty in two modules. Firstly, the local KEMs (e.g., 11x11) are extracted from a low-dimensional feature map. A proposed convolutional message passing module learns to "re-focus" the local KEMs to the keypoint attraction maps (KAMs) by accounting for the structured output prediction nature of human pose estimation, which is directly supervised by the object keypoint similarity (OKS) loss in training. Secondly, the global KEMs are extracted, with a sufficiently large region-of-interest (e.g., 97x97), from the keypoint heatmaps that are computed by a direct map-to-map regression. Then, a local-global contextual adaptation module is proposed to convolve the global KEMs using the learned KAMs as the kernels. This convolution can be understood as the learnable offsets guided deformable and dynamic convolution in a pose-sensitive way. The proposed method is end-to-end trainable with near real-time inference speed, obtaining state-of-the-art performance on the COCO keypoint benchmark for bottom-up human pose estimation. With the COCO trained model, our LOGO-CAP also outperforms prior arts by a large margin on the challenging OCHuman dataset.
Parsing Table Structures in the Wild
Sep 06, 2021
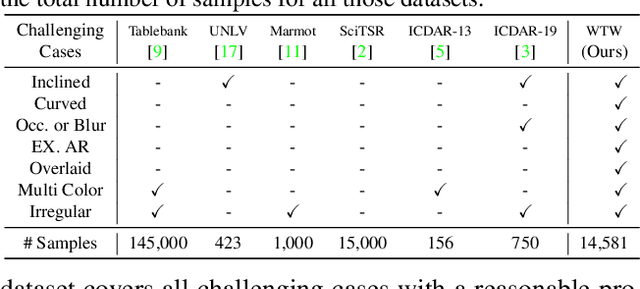
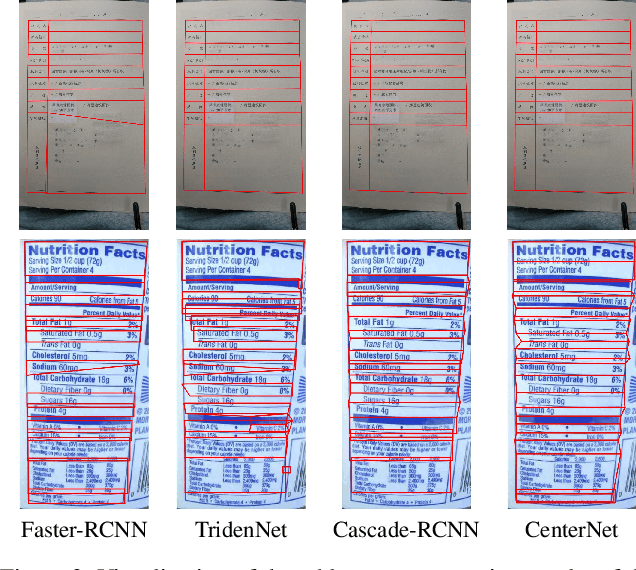
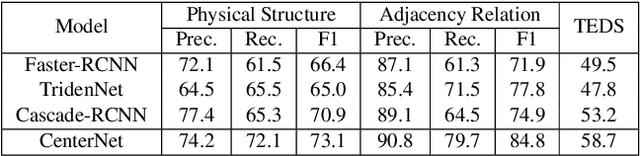
This paper tackles the problem of table structure parsing (TSP) from images in the wild. In contrast to existing studies that mainly focus on parsing well-aligned tabular images with simple layouts from scanned PDF documents, we aim to establish a practical table structure parsing system for real-world scenarios where tabular input images are taken or scanned with severe deformation, bending or occlusions. For designing such a system, we propose an approach named Cycle-CenterNet on the top of CenterNet with a novel cycle-pairing module to simultaneously detect and group tabular cells into structured tables. In the cycle-pairing module, a new pairing loss function is proposed for the network training. Alongside with our Cycle-CenterNet, we also present a large-scale dataset, named Wired Table in the Wild (WTW), which includes well-annotated structure parsing of multiple style tables in several scenes like the photo, scanning files, web pages, \emph{etc.}. In experiments, we demonstrate that our Cycle-CenterNet consistently achieves the best accuracy of table structure parsing on the new WTW dataset by 24.6\% absolute improvement evaluated by the TEDS metric. A more comprehensive experimental analysis also validates the advantages of our proposed methods for the TSP task.
LUAI Challenge 2021 on Learning to Understand Aerial Images
Aug 30, 2021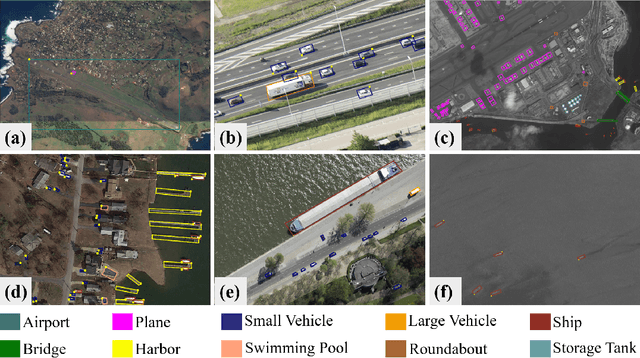

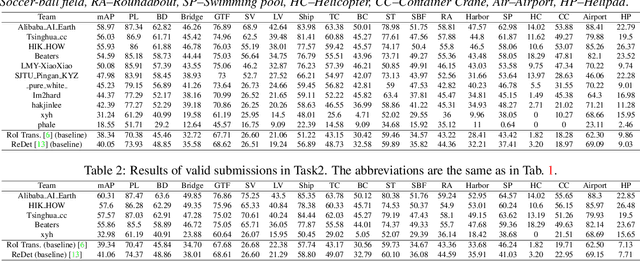
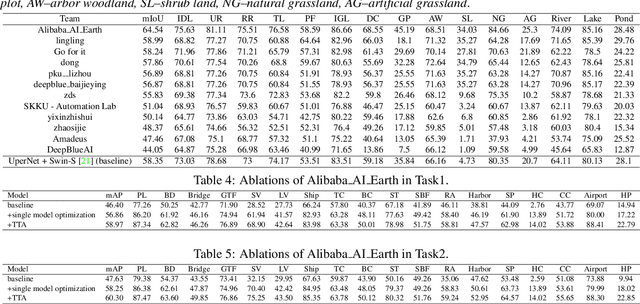
This report summarizes the results of Learning to Understand Aerial Images (LUAI) 2021 challenge held on ICCV 2021, which focuses on object detection and semantic segmentation in aerial images. Using DOTA-v2.0 and GID-15 datasets, this challenge proposes three tasks for oriented object detection, horizontal object detection, and semantic segmentation of common categories in aerial images. This challenge received a total of 146 registrations on the three tasks. Through the challenge, we hope to draw attention from a wide range of communities and call for more efforts on the problems of learning to understand aerial images.
PlaneTR: Structure-Guided Transformers for 3D Plane Recovery
Jul 27, 2021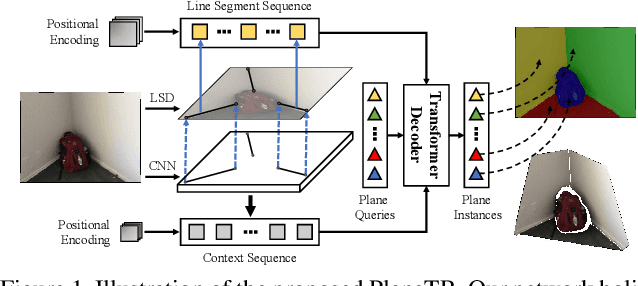
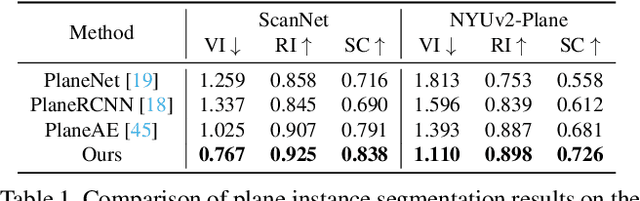
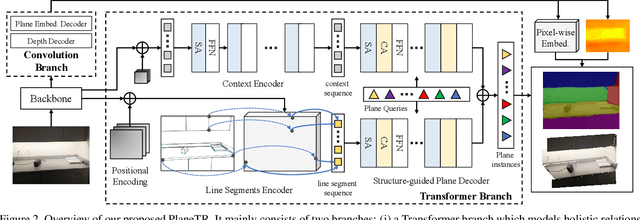
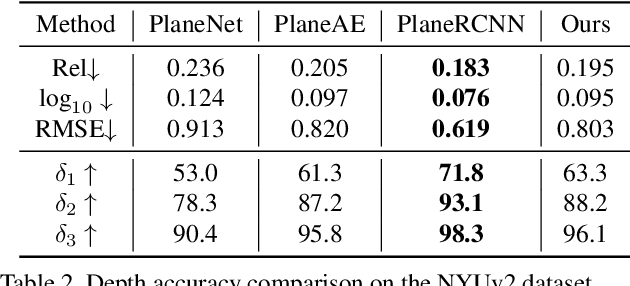
This paper presents a neural network built upon Transformers, namely PlaneTR, to simultaneously detect and reconstruct planes from a single image. Different from previous methods, PlaneTR jointly leverages the context information and the geometric structures in a sequence-to-sequence way to holistically detect plane instances in one forward pass. Specifically, we represent the geometric structures as line segments and conduct the network with three main components: (i) context and line segments encoders, (ii) a structure-guided plane decoder, (iii) a pixel-wise plane embedding decoder. Given an image and its detected line segments, PlaneTR generates the context and line segment sequences via two specially designed encoders and then feeds them into a Transformers-based decoder to directly predict a sequence of plane instances by simultaneously considering the context and global structure cues. Finally, the pixel-wise embeddings are computed to assign each pixel to one predicted plane instance which is nearest to it in embedding space. Comprehensive experiments demonstrate that PlaneTR achieves a state-of-the-art performance on the ScanNet and NYUv2 datasets.
Event-based Synthetic Aperture Imaging with a Hybrid Network
Mar 30, 2021
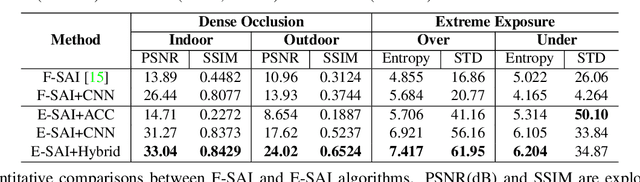


Synthetic aperture imaging (SAI) is able to achieve the see through effect by blurring out the off-focus foreground occlusions and reconstructing the in-focus occluded targets from multi-view images. However, very dense occlusions and extreme lighting conditions may bring significant disturbances to the SAI based on conventional frame-based cameras, leading to performance degeneration. To address these problems, we propose a novel SAI system based on the event camera which can produce asynchronous events with extremely low latency and high dynamic range. Thus, it can eliminate the interference of dense occlusions by measuring with almost continuous views, and simultaneously tackle the over/under exposure problems. To reconstruct the occluded targets, we propose a hybrid encoder-decoder network composed of spiking neural networks (SNNs) and convolutional neural networks (CNNs). In the hybrid network, the spatio-temporal information of the collected events is first encoded by SNN layers, and then transformed to the visual image of the occluded targets by a style-transfer CNN decoder. Through experiments, the proposed method shows remarkable performance in dealing with very dense occlusions and extreme lighting conditions, and high quality visual images can be reconstructed using pure event data.