 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAMatcher: Co-Visibility Modeling with Segment Anything for Robust Feature Matching
Jun 02, 2026Reliable correspondence estimation is a fundamental problem in image processing, underpinning applications such as Structure from Motion, visual localization, and image registration. Existing learning-based methods have significantly improved local feature representations, yet most still operate at the pixel or patch level and lack explicit modeling of regions that are jointly visible across views. We propose SAMatcher, a feature matching framework that formulates correspondence estimation through co-visibility modeling. Instead of directly matching local features, SAMatcher first predicts co-visible region masks and bounding boxes as structured priors for correspondence estimation. Built upon the Segment Anything Model (SAM), it introduces a symmetric cross-view interaction mechanism that enables bidirectional feature exchange and cross-view semantic alignment. We further develop a unified supervision scheme that jointly optimizes mask prediction and box localization through mask learning, box regression, and mask-box consistency constraints. Extensive experiments on challenging benchmarks demonstrate substantial improvements over existing matching pipelines, particularly under large viewpoint and scale variations. Our results show that foundation models originally designed for monocular segmentation can be effectively extended to multi-view correspondence reasoning through explicit co-visibility modeling, offering a new perspective on structured representation learning for image matching. Code and project page: https://xupan.top/Projects/samatcher
SA-VLA: Spatially-Aware Flow-Matching for Vision-Language-Action Reinforcement Learning
Jan 31, 2026Vision-Language-Action (VLA) models exhibit strong generalization in robotic manipulation, yet reinforcement learning (RL) fine-tuning often degrades robustness under spatial distribution shifts. For flow-matching VLA policies, this degradation is closely associated with the erosion of spatial inductive bias during RL adaptation, as sparse rewards and spatially agnostic exploration increasingly favor short-horizon visual cues. To address this issue, we propose \textbf{SA-VLA}, a spatially-aware RL adaptation framework that preserves spatial grounding during policy optimization by aligning representation learning, reward design, and exploration with task geometry. SA-VLA fuses implicit spatial representations with visual tokens, provides dense rewards that reflect geometric progress, and employs \textbf{SCAN}, a spatially-conditioned annealed exploration strategy tailored to flow-matching dynamics. Across challenging multi-object and cluttered manipulation benchmarks, SA-VLA enables stable RL fine-tuning and improves zero-shot spatial generalization, yielding more robust and transferable behaviors. Code and project page are available at https://xupan.top/Projects/savla.
PointLAMA: Latent Attention meets Mamba for Efficient Point Cloud Pretraining
Jul 23, 2025Mamba has recently gained widespread attention as a backbone model for point cloud modeling, leveraging a state-space architecture that enables efficient global sequence modeling with linear complexity. However, its lack of local inductive bias limits its capacity to capture fine-grained geometric structures in 3D data. To address this limitation, we propose \textbf{PointLAMA}, a point cloud pretraining framework that combines task-aware point cloud serialization, a hybrid encoder with integrated Latent Attention and Mamba blocks, and a conditional diffusion mechanism built upon the Mamba backbone. Specifically, the task-aware point cloud serialization employs Hilbert/Trans-Hilbert space-filling curves and axis-wise sorting to structurally align point tokens for classification and segmentation tasks, respectively. Our lightweight Latent Attention block features a Point-wise Multi-head Latent Attention (PMLA) module, which is specifically designed to align with the Mamba architecture by leveraging the shared latent space characteristics of PMLA and Mamba. This enables enhanced local context modeling while preserving overall efficiency. To further enhance representation learning, we incorporate a conditional diffusion mechanism during pretraining, which denoises perturbed feature sequences without relying on explicit point-wise reconstruction. Experimental results demonstrate that PointLAMA achieves competitive performance on multiple benchmark datasets with minimal parameter count and FLOPs, validating its effectiveness for efficient point cloud pretraining.
ScaleLSD: Scalable Deep Line Segment Detection Streamlined
Jun 11, 2025



This paper studies the problem of Line Segment Detection (LSD) for the characterization of line geometry in images, with the aim of learning a domain-agnostic robust LSD model that works well for any natural images. With the focus of scalable self-supervised learning of LSD, we revisit and streamline the fundamental designs of (deep and non-deep) LSD approaches to have a high-performing and efficient LSD learner, dubbed as ScaleLSD, for the curation of line geometry at scale from over 10M unlabeled real-world images. Our ScaleLSD works very well to detect much more number of line segments from any natural images even than the pioneered non-deep LSD approach, having a more complete and accurate geometric characterization of images using line segments. Experimentally, our proposed ScaleLSD is comprehensively testified under zero-shot protocols in detection performance, single-view 3D geometry estimation, two-view line segment matching, and multiview 3D line mapping, all with excellent performance obtained. Based on the thorough evaluation, our ScaleLSD is observed to be the first deep approach that outperforms the pioneered non-deep LSD in all aspects we have tested, significantly expanding and reinforcing the versatility of the line geometry of images. Code and Models are available at https://github.com/ant-research/scalelsd
Seeing through Satellite Images at Street Views
May 22, 2025This paper studies the task of SatStreet-view synthesis, which aims to render photorealistic street-view panorama images and videos given any satellite image and specified camera positions or trajectories. We formulate to learn neural radiance field from paired images captured from satellite and street viewpoints, which comes to be a challenging learning problem due to the sparse-view natural and the extremely-large viewpoint changes between satellite and street-view images. We tackle the challenges based on a task-specific observation that street-view specific elements, including the sky and illumination effects are only visible in street-view panoramas, and present a novel approach Sat2Density++ to accomplish the goal of photo-realistic street-view panoramas rendering by modeling these street-view specific in neural networks. In the experiments, our method is testified on both urban and suburban scene datasets, demonstrating that Sat2Density++ is capable of rendering photorealistic street-view panoramas that are consistent across multiple views and faithful to the satellite image.
CoMatcher: Multi-View Collaborative Feature Matching
Apr 02, 2025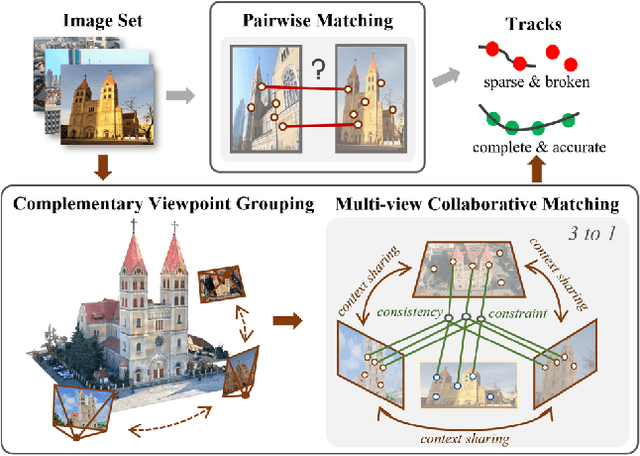



This paper proposes a multi-view collaborative matching strategy for reliable track construction in complex scenarios. We observe that the pairwise matching paradigms applied to image set matching often result in ambiguous estimation when the selected independent pairs exhibit significant occlusions or extreme viewpoint changes. This challenge primarily stems from the inherent uncertainty in interpreting intricate 3D structures based on limited two-view observations, as the 3D-to-2D projection leads to significant information loss. To address this, we introduce CoMatcher, a deep multi-view matcher to (i) leverage complementary context cues from different views to form a holistic 3D scene understanding and (ii) utilize cross-view projection consistency to infer a reliable global solution. Building on CoMatcher, we develop a groupwise framework that fully exploits cross-view relationships for large-scale matching tasks. Extensive experiments on various complex scenarios demonstrate the superiority of our method over the mainstream two-view matching paradigm.
* 15 pages, 7 figures, to be published in CVPR 2025
Deferred Poisoning: Making the Model More Vulnerable via Hessian Singularization
Nov 06, 2024Recent studies have shown that deep learning models are very vulnerable to poisoning attacks. Many defense methods have been proposed to address this issue. However, traditional poisoning attacks are not as threatening as commonly believed. This is because they often cause differences in how the model performs on the training set compared to the validation set. Such inconsistency can alert defenders that their data has been poisoned, allowing them to take the necessary defensive actions. In this paper, we introduce a more threatening type of poisoning attack called the Deferred Poisoning Attack. This new attack allows the model to function normally during the training and validation phases but makes it very sensitive to evasion attacks or even natural noise. We achieve this by ensuring the poisoned model's loss function has a similar value as a normally trained model at each input sample but with a large local curvature. A similar model loss ensures that there is no obvious inconsistency between the training and validation accuracy, demonstrating high stealthiness. On the other hand, the large curvature implies that a small perturbation may cause a significant increase in model loss, leading to substantial performance degradation, which reflects a worse robustness. We fulfill this purpose by making the model have singular Hessian information at the optimal point via our proposed Singularization Regularization term. We have conducted both theoretical and empirical analyses of the proposed method and validated its effectiveness through experiments on image classification tasks. Furthermore, we have confirmed the hazards of this form of poisoning attack under more general scenarios using natural noise, offering a new perspective for research in the field of security.
PolyRoom: Room-aware Transformer for Floorplan Reconstruction
Jul 15, 2024



Reconstructing geometry and topology structures from raw unstructured data has always been an important research topic in indoor mapping research. In this paper, we aim to reconstruct the floorplan with a vectorized representation from point clouds. Despite significant advancements achieved in recent years, current methods still encounter several challenges, such as missing corners or edges, inaccuracies in corner positions or angles, self-intersecting or overlapping polygons, and potentially implausible topology. To tackle these challenges, we present PolyRoom, a room-aware Transformer that leverages uniform sampling representation, room-aware query initialization, and room-aware self-attention for floorplan reconstruction. Specifically, we adopt a uniform sampling floorplan representation to enable dense supervision during training and effective utilization of angle information. Additionally, we propose a room-aware query initialization scheme to prevent non-polygonal sequences and introduce room-aware self-attention to enhance memory efficiency and model performance. Experimental results on two widely used datasets demonstrate that PolyRoom surpasses current state-of-the-art methods both quantitatively and qualitatively. Our code is available at: https://github.com/3dv-casia/PolyRoom/.
Stratified Avatar Generation from Sparse Observations
Jun 03, 2024



Estimating 3D full-body avatars from AR/VR devices is essential for creating immersive experiences in AR/VR applications. This task is challenging due to the limited input from Head Mounted Devices, which capture only sparse observations from the head and hands. Predicting the full-body avatars, particularly the lower body, from these sparse observations presents significant difficulties. In this paper, we are inspired by the inherent property of the kinematic tree defined in the Skinned Multi-Person Linear (SMPL) model, where the upper body and lower body share only one common ancestor node, bringing the potential of decoupled reconstruction. We propose a stratified approach to decouple the conventional full-body avatar reconstruction pipeline into two stages, with the reconstruction of the upper body first and a subsequent reconstruction of the lower body conditioned on the previous stage. To implement this straightforward idea, we leverage the latent diffusion model as a powerful probabilistic generator, and train it to follow the latent distribution of decoupled motions explored by a VQ-VAE encoder-decoder model. Extensive experiments on AMASS mocap dataset demonstrate our state-of-the-art performance in the reconstruction of full-body motions.
Learning Deformable Hypothesis Sampling for Accurate PatchMatch Multi-View Stereo
Dec 26, 2023This paper introduces a learnable Deformable Hypothesis Sampler (DeformSampler) to address the challenging issue of noisy depth estimation for accurate PatchMatch Multi-View Stereo (MVS). We observe that the heuristic depth hypothesis sampling modes employed by PatchMatch MVS solvers are insensitive to (i) the piece-wise smooth distribution of depths across the object surface, and (ii) the implicit multi-modal distribution of depth prediction probabilities along the ray direction on the surface points. Accordingly, we develop DeformSampler to learn distribution-sensitive sample spaces to (i) propagate depths consistent with the scene's geometry across the object surface, and (ii) fit a Laplace Mixture model that approaches the point-wise probabilities distribution of the actual depths along the ray direction. We integrate DeformSampler into a learnable PatchMatch MVS system to enhance depth estimation in challenging areas, such as piece-wise discontinuous surface boundaries and weakly-textured regions. Experimental results on DTU and Tanks \& Temples datasets demonstrate its superior performance and generalization capabilities compared to state-of-the-art competitors. Code is available at https://github.com/Geo-Tell/DS-PMNet.