 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRe-assembling the past: The RePAIR dataset and benchmark for real world 2D and 3D puzzle solving
Oct 31, 2024



This paper proposes the RePAIR dataset that represents a challenging benchmark to test modern computational and data driven methods for puzzle-solving and reassembly tasks. Our dataset has unique properties that are uncommon to current benchmarks for 2D and 3D puzzle solving. The fragments and fractures are realistic, caused by a collapse of a fresco during a World War II bombing at the Pompeii archaeological park. The fragments are also eroded and have missing pieces with irregular shapes and different dimensions, challenging further the reassembly algorithms. The dataset is multi-modal providing high resolution images with characteristic pictorial elements, detailed 3D scans of the fragments and meta-data annotated by the archaeologists. Ground truth has been generated through several years of unceasing fieldwork, including the excavation and cleaning of each fragment, followed by manual puzzle solving by archaeologists of a subset of approx. 1000 pieces among the 16000 available. After digitizing all the fragments in 3D, a benchmark was prepared to challenge current reassembly and puzzle-solving methods that often solve more simplistic synthetic scenarios. The tested baselines show that there clearly exists a gap to fill in solving this computationally complex problem.
Nash Meets Wertheimer: Using Good Continuation in Jigsaw Puzzles
Oct 22, 2024



Jigsaw puzzle solving is a challenging task for computer vision since it requires high-level spatial and semantic reasoning. To solve the problem, existing approaches invariably use color and/or shape information but in many real-world scenarios, such as in archaeological fresco reconstruction, this kind of clues is often unreliable due to severe physical and pictorial deterioration of the individual fragments. This makes state-of-the-art approaches entirely unusable in practice. On the other hand, in such cases, simple geometrical patterns such as lines or curves offer a powerful yet unexplored clue. In an attempt to fill in this gap, in this paper we introduce a new challenging version of the puzzle solving problem in which one deliberately ignores conventional color and shape features and relies solely on the presence of linear geometrical patterns. The reconstruction process is then only driven by one of the most fundamental principles of Gestalt perceptual organization, namely Wertheimer's {\em law of good continuation}. In order to tackle this problem, we formulate the puzzle solving problem as the problem of finding a Nash equilibrium of a (noncooperative) multiplayer game and use classical multi-population replicator dynamics to solve it. The proposed approach is general and allows us to deal with pieces of arbitrary shape, size and orientation. We evaluate our approach on both synthetic and real-world data and compare it with state-of-the-art algorithms. The results show the intrinsic complexity of our purely line-based puzzle problem as well as the relative effectiveness of our game-theoretic formulation.
* to be published in ACCV2024
Boosting CNN-based Handwriting Recognition Systems with Learnable Relaxation Labeling
Sep 09, 2024



The primary challenge for handwriting recognition systems lies in managing long-range contextual dependencies, an issue that traditional models often struggle with. To mitigate it, attention mechanisms have recently been employed to enhance context-aware labelling, thereby achieving state-of-the-art performance. In the field of pattern recognition and image analysis, however, the use of contextual information in labelling problems has a long history and goes back at least to the early 1970's. Among the various approaches developed in those years, Relaxation Labelling (RL) processes have played a prominent role and have been the method of choice in the field for more than a decade. Contrary to recent transformer-based architectures, RL processes offer a principled approach to the use of contextual constraints, having a solid theoretic foundation grounded on variational inequality and game theory, as well as effective algorithms with convergence guarantees. In this paper, we propose a novel approach to handwriting recognition that integrates the strengths of two distinct methodologies. In particular, we propose integrating (trainable) RL processes with various well-established neural architectures and we introduce a sparsification technique that accelerates the convergence of the algorithm and enhances the overall system's performance. Experiments over several benchmark datasets show that RL processes can improve the generalisation ability, even surpassing in some cases transformer-based architectures.
Understanding XAI Through the Philosopher's Lens: A Historical Perspective
Jul 26, 2024
Despite explainable AI (XAI) has recently become a hot topic and several different approaches have been developed, there is still a widespread belief that it lacks a convincing unifying foundation. On the other hand, over the past centuries, the very concept of explanation has been the subject of extensive philosophical analysis in an attempt to address the fundamental question of "why" in the context of scientific law. However, this discussion has rarely been connected with XAI. This paper tries to fill in this gap and aims to explore the concept of explanation in AI through an epistemological lens. By comparing the historical development of both the philosophy of science and AI, an intriguing picture emerges. Specifically, we show that a gradual progression has independently occurred in both domains from logical-deductive to statistical models of explanation, thereby experiencing in both cases a paradigm shift from deterministic to nondeterministic and probabilistic causality. Interestingly, we also notice that similar concepts have independently emerged in both realms such as, for example, the relation between explanation and understanding and the importance of pragmatic factors. Our study aims to be the first step towards understanding the philosophical underpinnings of the notion of explanation in AI, and we hope that our findings will shed some fresh light on the elusive nature of XAI.
$σ$-zero: Gradient-based Optimization of $\ell_0$-norm Adversarial Examples
Feb 02, 2024Evaluating the adversarial robustness of deep networks to gradient-based attacks is challenging. While most attacks consider $\ell_2$- and $\ell_\infty$-norm constraints to craft input perturbations, only a few investigate sparse $\ell_1$- and $\ell_0$-norm attacks. In particular, $\ell_0$-norm attacks remain the least studied due to the inherent complexity of optimizing over a non-convex and non-differentiable constraint. However, evaluating adversarial robustness under these attacks could reveal weaknesses otherwise left untested with more conventional $\ell_2$- and $\ell_\infty$-norm attacks. In this work, we propose a novel $\ell_0$-norm attack, called $\sigma$-zero, which leverages an ad hoc differentiable approximation of the $\ell_0$ norm to facilitate gradient-based optimization, and an adaptive projection operator to dynamically adjust the trade-off between loss minimization and perturbation sparsity. Extensive evaluations using MNIST, CIFAR10, and ImageNet datasets, involving robust and non-robust models, show that $\sigma$-zero finds minimum $\ell_0$-norm adversarial examples without requiring any time-consuming hyperparameter tuning, and that it outperforms all competing sparse attacks in terms of success rate, perturbation size, and scalability.
Minimizing Energy Consumption of Deep Learning Models by Energy-Aware Training
Jul 01, 2023



Deep learning models undergo a significant increase in the number of parameters they possess, leading to the execution of a larger number of operations during inference. This expansion significantly contributes to higher energy consumption and prediction latency. In this work, we propose EAT, a gradient-based algorithm that aims to reduce energy consumption during model training. To this end, we leverage a differentiable approximation of the $\ell_0$ norm, and use it as a sparse penalty over the training loss. Through our experimental analysis conducted on three datasets and two deep neural networks, we demonstrate that our energy-aware training algorithm EAT is able to train networks with a better trade-off between classification performance and energy efficiency.
Reassembling Broken Objects using Breaking Curves
Jun 05, 2023Reassembling 3D broken objects is a challenging task. A robust solution that generalizes well must deal with diverse patterns associated with different types of broken objects. We propose a method that tackles the pairwise assembly of 3D point clouds, that is agnostic on the type of object, and that relies solely on their geometrical information, without any prior information on the shape of the reconstructed object. The method receives two point clouds as input and segments them into regions using detected closed boundary contours, known as breaking curves. Possible alignment combinations of the regions of each broken object are evaluated and the best one is selected as the final alignment. Experiments were carried out both on available 3D scanned objects and on a recent benchmark for synthetic broken objects. Results show that our solution performs well in reassembling different kinds of broken objects.
Multi-Phase Relaxation Labeling for Square Jigsaw Puzzle Solving
Mar 26, 2023We present a novel method for solving square jigsaw puzzles based on global optimization. The method is fully automatic, assumes no prior information, and can handle puzzles with known or unknown piece orientation. At the core of the optimization process is nonlinear relaxation labeling, a well-founded approach for deducing global solutions from local constraints, but unlike the classical scheme here we propose a multi-phase approach that guarantees convergence to feasible puzzle solutions. Next to the algorithmic novelty, we also present a new compatibility function for the quantification of the affinity between adjacent puzzle pieces. Competitive results and the advantage of the multi-phase approach are demonstrated on standard datasets.
* 10 pages, 7 figures. Published in Proceedings of the 18th International Joint Conference on Computer Vision, Imaging and Computer Graphics Theory and Applications - Volume 4 VISAPP: VISAPP, 785-795, 2023
Geolocation of Cultural Heritage using Multi-View Knowledge Graph Embedding
Sep 08, 2022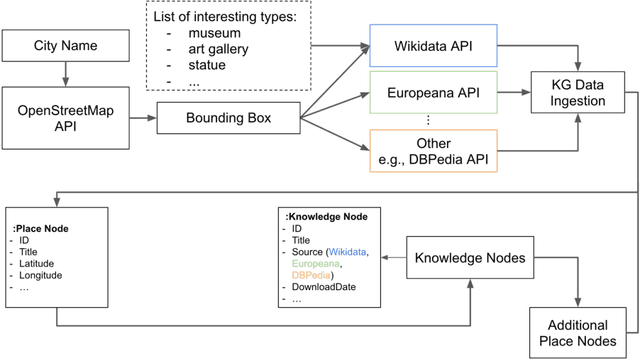

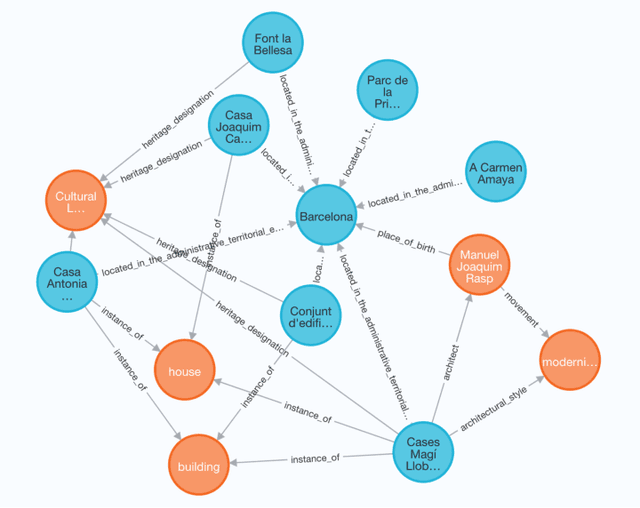
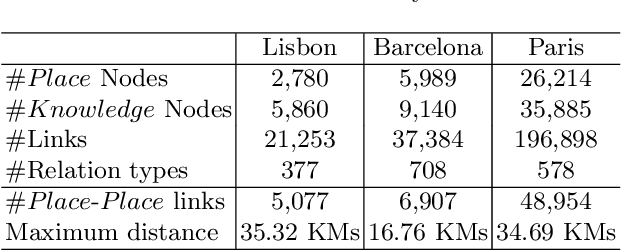
Knowledge Graphs (KGs) have proven to be a reliable way of structuring data. They can provide a rich source of contextual information about cultural heritage collections. However, cultural heritage KGs are far from being complete. They are often missing important attributes such as geographical location, especially for sculptures and mobile or indoor entities such as paintings. In this paper, we first present a framework for ingesting knowledge about tangible cultural heritage entities from various data sources and their connected multi-hop knowledge into a geolocalized KG. Secondly, we propose a multi-view learning model for estimating the relative distance between a given pair of cultural heritage entities, based on the geographical as well as the knowledge connections of the entities.
Wild Patterns Reloaded: A Survey of Machine Learning Security against Training Data Poisoning
May 04, 2022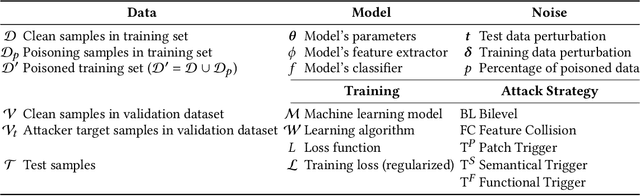
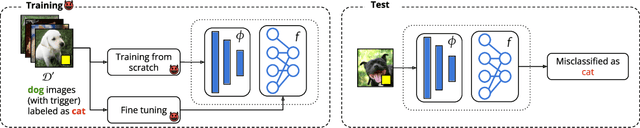

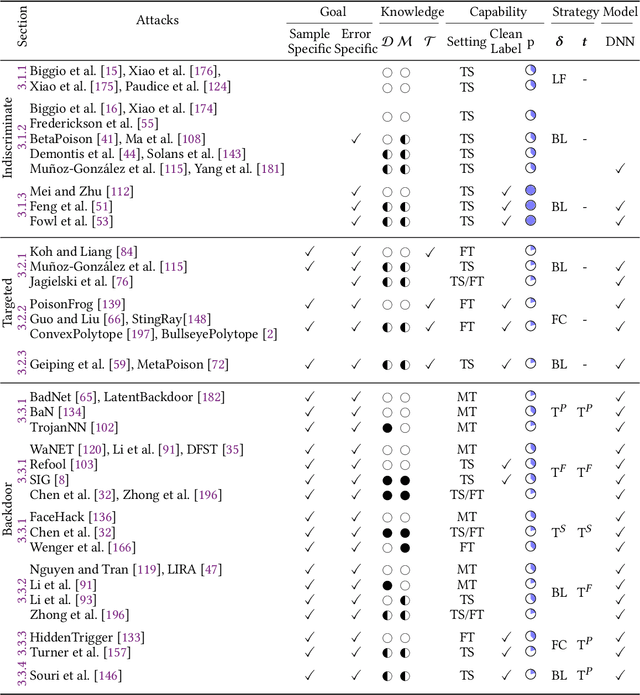
The success of machine learning is fueled by the increasing availability of computing power and large training datasets. The training data is used to learn new models or update existing ones, assuming that it is sufficiently representative of the data that will be encountered at test time. This assumption is challenged by the threat of poisoning, an attack that manipulates the training data to compromise the model's performance at test time. Although poisoning has been acknowledged as a relevant threat in industry applications, and a variety of different attacks and defenses have been proposed so far, a complete systematization and critical review of the field is still missing. In this survey, we provide a comprehensive systematization of poisoning attacks and defenses in machine learning, reviewing more than 200 papers published in the field in the last 15 years. We start by categorizing the current threat models and attacks, and then organize existing defenses accordingly. While we focus mostly on computer-vision applications, we argue that our systematization also encompasses state-of-the-art attacks and defenses for other data modalities. Finally, we discuss existing resources for research in poisoning, and shed light on the current limitations and open research questions in this research field.