 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemory as Action: Autonomous Context Curation for Long-Horizon Agentic Tasks
Oct 14, 2025



Large Language Models face challenges in long-horizon agentic tasks as their constrained memory is easily overwhelmed by distracting or irrelevant context. Existing working memory methods typically rely on external, heuristic mechanisms that are decoupled from the agent's core policy. In this work, we reframe working memory management as a learnable, intrinsic capability. We propose a novel framework, Memory-as-Action, where an agent actively manages its working memory by executing explicit editing operations as part of a unified policy. This formulation allows an agent, trained via reinforcement learning, to balance memory curation against long-term task objectives under given resource constraints. However, such memory editing actions break the standard assumption of a continuously growing prefix in LLM interactions, leading to what we call trajectory fractures. These non-prefix changes disrupt the causal continuity required by standard policy gradient methods, making those methods inapplicable. To address this, we propose a new algorithm, Dynamic Context Policy Optimization, which enables stable end-to-end reinforcement learning by segmenting trajectories at memory action points and applying trajectory-level advantages to the resulting action segments. Our results demonstrate that jointly optimizing for task reasoning and memory management in an end-to-end fashion not only reduces overall computational consumption but also improves task performance, driven by adaptive context curation strategies tailored to the model's intrinsic capabilities.
o1-Coder: an o1 Replication for Coding
Nov 29, 2024



The technical report introduces O1-CODER, an attempt to replicate OpenAI's o1 model with a focus on coding tasks. It integrates reinforcement learning (RL) and Monte Carlo Tree Search (MCTS) to enhance the model's System-2 thinking capabilities. The framework includes training a Test Case Generator (TCG) for standardized code testing, using MCTS to generate code data with reasoning processes, and iteratively fine-tuning the policy model to initially produce pseudocode, followed by the generation of the full code. The report also addresses the opportunities and challenges in deploying o1-like models in real-world applications, suggesting transitioning to the System-2 paradigm and highlighting the imperative for environment state updates. Updated model progress and experimental results will be reported in subsequent versions. All source code, curated datasets, as well as the derived models will be disclosed at https://github.com/ADaM-BJTU/O1-CODER .
A Disguised Wolf Is More Harmful Than a Toothless Tiger: Adaptive Malicious Code Injection Backdoor Attack Leveraging User Behavior as Triggers
Aug 19, 2024



In recent years, large language models (LLMs) have made significant progress in the field of code generation. However, as more and more users rely on these models for software development, the security risks associated with code generation models have become increasingly significant. Studies have shown that traditional deep learning robustness issues also negatively impact the field of code generation. In this paper, we first present the game-theoretic model that focuses on security issues in code generation scenarios. This framework outlines possible scenarios and patterns where attackers could spread malicious code models to create security threats. We also pointed out for the first time that the attackers can use backdoor attacks to dynamically adjust the timing of malicious code injection, which will release varying degrees of malicious code depending on the skill level of the user. Through extensive experiments on leading code generation models, we validate our proposed game-theoretic model and highlight the significant threats that these new attack scenarios pose to the safe use of code models.
Are You Copying My Model? Protecting the Copyright of Large Language Models for EaaS via Backdoor Watermark
May 17, 2023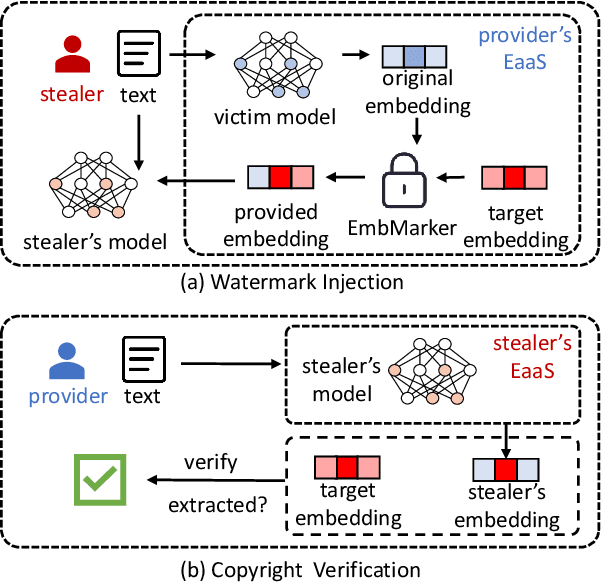
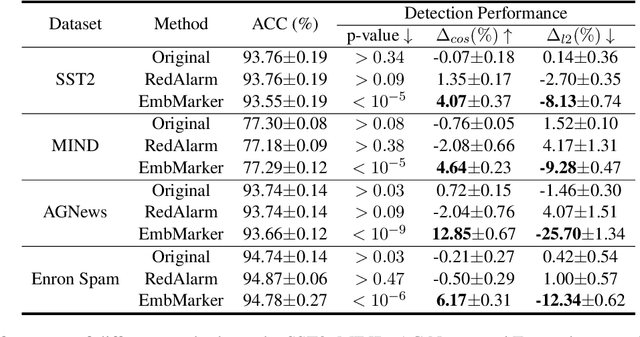
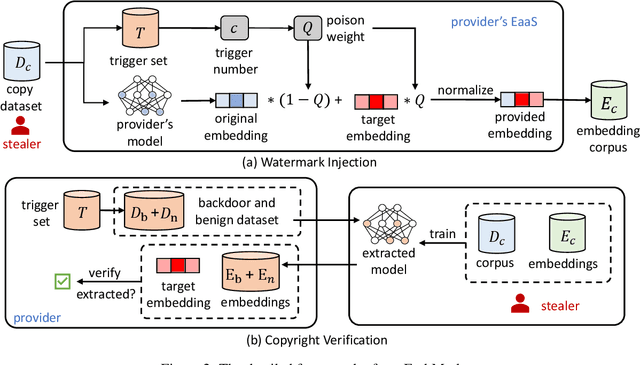
Large language models (LLMs) have demonstrated powerful capabilities in both text understanding and generation. Companies have begun to offer Embedding as a Service (EaaS) based on these LLMs, which can benefit various natural language processing (NLP) tasks for customers. However, previous studies have shown that EaaS is vulnerable to model extraction attacks, which can cause significant losses for the owners of LLMs, as training these models is extremely expensive. To protect the copyright of LLMs for EaaS, we propose an Embedding Watermark method called EmbMarker that implants backdoors on embeddings. Our method selects a group of moderate-frequency words from a general text corpus to form a trigger set, then selects a target embedding as the watermark, and inserts it into the embeddings of texts containing trigger words as the backdoor. The weight of insertion is proportional to the number of trigger words included in the text. This allows the watermark backdoor to be effectively transferred to EaaS-stealer's model for copyright verification while minimizing the adverse impact on the original embeddings' utility. Our extensive experiments on various datasets show that our method can effectively protect the copyright of EaaS models without compromising service quality.
Backdoor for Debias: Mitigating Model Bias with Backdoor Attack-based Artificial Bias
Mar 01, 2023



With the swift advancement of deep learning, state-of-the-art algorithms have been utilized in various social situations. Nonetheless, some algorithms have been discovered to exhibit biases and provide unequal results. The current debiasing methods face challenges such as poor utilization of data or intricate training requirements. In this work, we found that the backdoor attack can construct an artificial bias similar to the model bias derived in standard training. Considering the strong adjustability of backdoor triggers, we are motivated to mitigate the model bias by carefully designing reverse artificial bias created from backdoor attack. Based on this, we propose a backdoor debiasing framework based on knowledge distillation, which effectively reduces the model bias from original data and minimizes security risks from the backdoor attack. The proposed solution is validated on both image and structured datasets, showing promising results. This work advances the understanding of backdoor attacks and highlights its potential for beneficial applications. The code for the study can be found at \url{https://anonymous.4open.science/r/DwB-BC07/}.
Debiasing Backdoor Attack: A Benign Application of Backdoor Attack in Eliminating Data Bias
Feb 18, 2022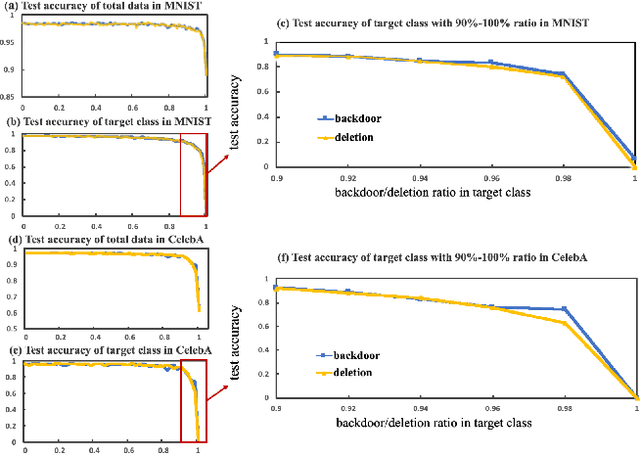
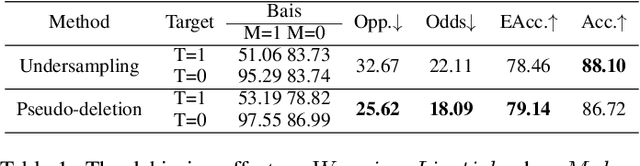
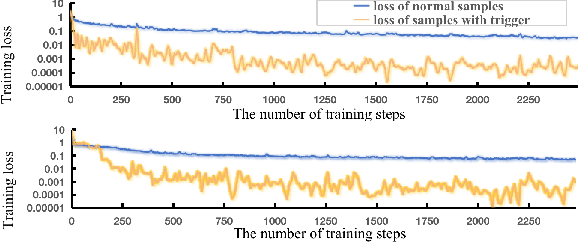
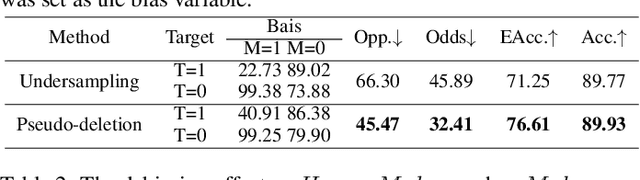
Backdoor attack is a new AI security risk that has emerged in recent years. Drawing on the previous research of adversarial attack, we argue that the backdoor attack has the potential to tap into the model learning process and improve model performance. Based on Clean Accuracy Drop (CAD) in backdoor attack, we found that CAD came out of the effect of pseudo-deletion of data. We provided a preliminary explanation of this phenomenon from the perspective of model classification boundaries and observed that this pseudo-deletion had advantages over direct deletion in the data debiasing problem. Based on the above findings, we proposed Debiasing Backdoor Attack (DBA). It achieves SOTA in the debiasing task and has a broader application scenario than undersampling.
An Experimental Study of Semantic Continuity for Deep Learning Models
Nov 19, 2020
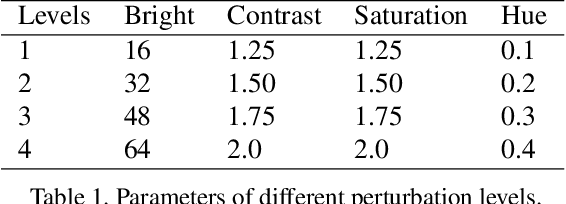

Deep learning models suffer from the problem of semantic discontinuity: small perturbations in the input space tend to cause semantic-level interference to the model output. We argue that the semantic discontinuity results from these inappropriate training targets and contributes to notorious issues such as adversarial robustness, interpretability, etc. We first conduct data analysis to provide evidence of semantic discontinuity in existing deep learning models, and then design a simple semantic continuity constraint which theoretically enables models to obtain smooth gradients and learn semantic-oriented features. Qualitative and quantitative experiments prove that semantically continuous models successfully reduce the use of non-semantic information, which further contributes to the improvement in adversarial robustness, interpretability, model transfer, and machine bias.
Adaptive Adversarial Logits Pairing
May 25, 2020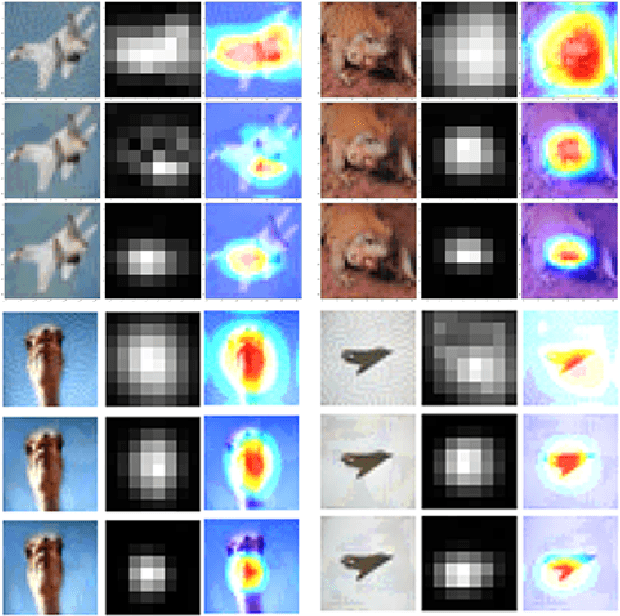
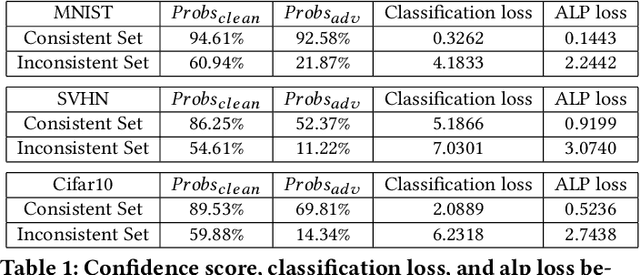
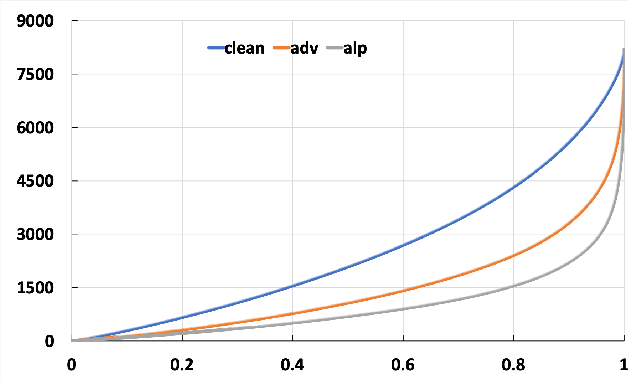
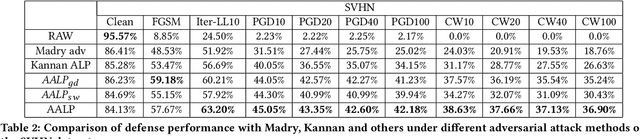
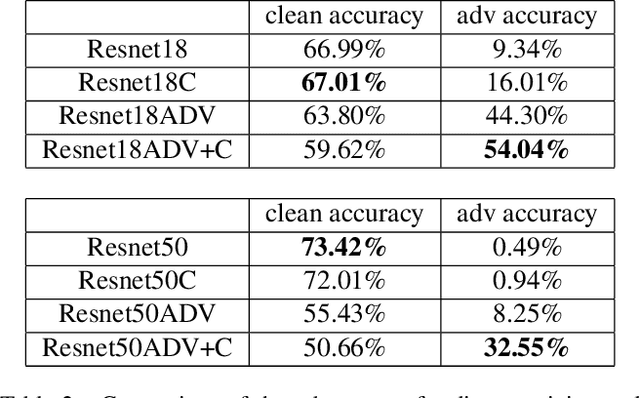
Adversarial examples provide an opportunity as well as impose a challenge for understanding image classification systems. Based on the analysis of state-of-the-art defense solution Adversarial Logits Pairing (ALP), we observed in this work that: (1) The inference of adversarially robust models tends to rely on fewer high-contribution features compared with vulnerable ones. (2) The training target of ALP doesn't fit well to a noticeable part of samples, where the logits pairing loss is overemphasized and obstructs minimizing the classification loss. Motivated by these observations, we designed an Adaptive Adversarial Logits Pairing (AALP) solution by modifying the training process and training target of ALP. Specifically, AALP consists of an adaptive feature optimization module with Guided Dropout to systematically pursue few high-contribution features, and an adaptive sample weighting module by setting sample-specific training weights to balance between logits pairing loss and classification loss. The proposed AALP solution demonstrates superior defense performance on multiple datasets with extensive experiments.
Butterfly detection and classification based on integrated YOLO algorithm
Jan 02, 2020


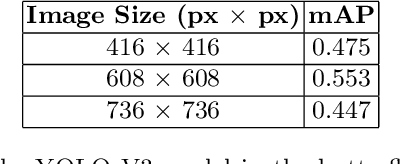
Insects are abundant species on the earth, and the task of identification and identification of insects is complex and arduous. How to apply artificial intelligence technology and digital image processing methods to automatic identification of insect species is a hot issue in current research. In this paper, the problem of automatic detection and classification recognition of butterfly photographs is studied, and a method of bio-labeling suitable for butterfly classification is proposed. On the basis of YOLO algorithm, by synthesizing the results of YOLO models with different training mechanisms, a butterfly automatic detection and classification recognition algorithm based on YOLO algorithm is proposed. It greatly improves the generalization ability of YOLO algorithm and makes it have better ability to solve small sample problems. The experimental results show that the proposed annotation method and integrated YOLO algorithm have high accuracy and recognition rate in butterfly automatic detection and recognition.
blessing in disguise: Designing Robust Turing Test by Employing Algorithm Unrobustness
Apr 22, 2019
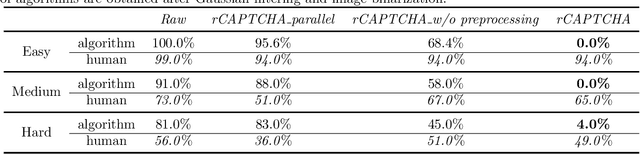
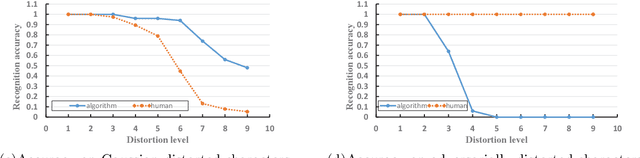
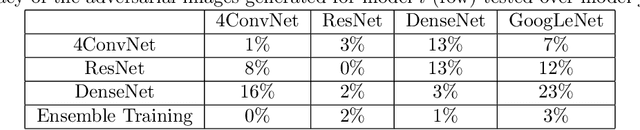
Turing test was originally proposed to examine whether machine's behavior is indistinguishable from a human. The most popular and practical Turing test is CAPTCHA, which is to discriminate algorithm from human by offering recognition-alike questions. The recent development of deep learning has significantly advanced the capability of algorithm in solving CAPTCHA questions, forcing CAPTCHA designers to increase question complexity. Instead of designing questions difficult for both algorithm and human, this study attempts to employ the limitations of algorithm to design robust CAPTCHA questions easily solvable to human. Specifically, our data analysis observes that human and algorithm demonstrates different vulnerability to visual distortions: adversarial perturbation is significantly annoying to algorithm yet friendly to human. We are motivated to employ adversarially perturbed images for robust CAPTCHA design in the context of character-based questions. Three modules of multi-target attack, ensemble adversarial training, and image preprocessing differentiable approximation are proposed to address the characteristics of character-based CAPTCHA cracking. Qualitative and quantitative experimental results demonstrate the effectiveness of the proposed solution. We hope this study can lead to the discussions around adversarial attack/defense in CAPTCHA design and also inspire the future attempts in employing algorithm limitation for practical usage.