 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActive Refinement for Multi-Label Learning: A Pseudo-Label Approach
Sep 29, 2021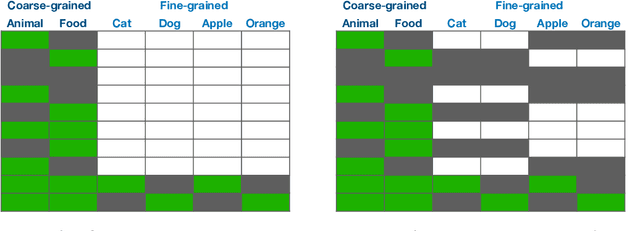
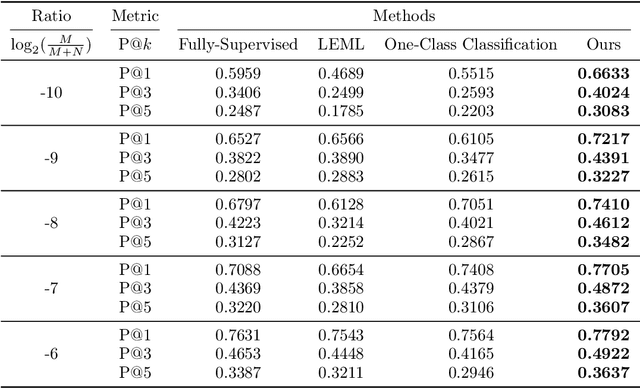
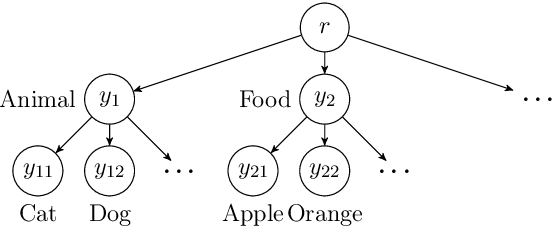
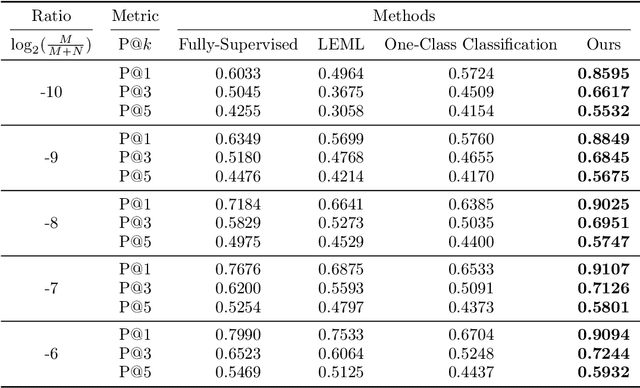
The goal of multi-label learning (MLL) is to associate a given instance with its relevant labels from a set of concepts. Previous works of MLL mainly focused on the setting where the concept set is assumed to be fixed, while many real-world applications require introducing new concepts into the set to meet new demands. One common need is to refine the original coarse concepts and split them into finer-grained ones, where the refinement process typically begins with limited labeled data for the finer-grained concepts. To address the need, we formalize the problem into a special weakly supervised MLL problem to not only learn the fine-grained concepts efficiently but also allow interactive queries to strategically collect more informative annotations to further improve the classifier. The key idea within our approach is to learn to assign pseudo-labels to the unlabeled entries, and in turn leverage the pseudo-labels to train the underlying classifier and to inform a better query strategy. Experimental results demonstrate that our pseudo-label approach is able to accurately recover the missing ground truth, boosting the prediction performance significantly over the baseline methods and facilitating a competitive active learning strategy.
Instance-dependent Label-noise Learning under a Structural Causal Model
Sep 12, 2021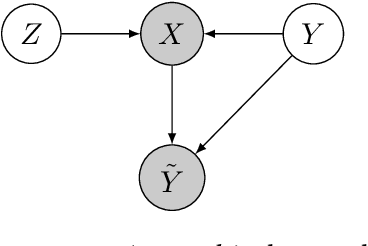
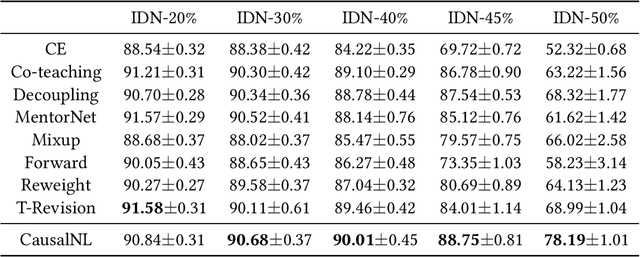
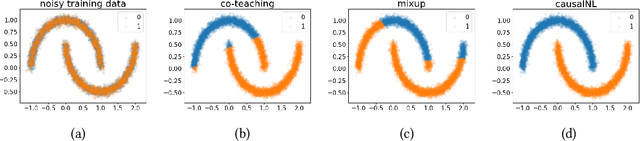
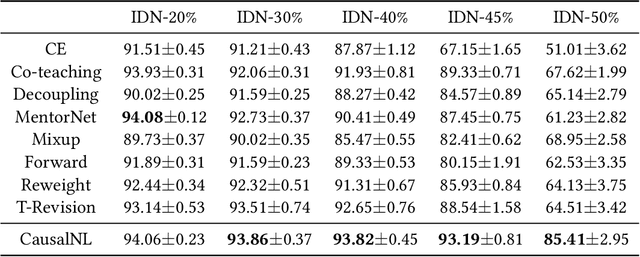
Label noise will degenerate the performance of deep learning algorithms because deep neural networks easily overfit label errors. Let X and Y denote the instance and clean label, respectively. When Y is a cause of X, according to which many datasets have been constructed, e.g., SVHN and CIFAR, the distributions of P(X) and P(Y|X) are entangled. This means that the unsupervised instances are helpful to learn the classifier and thus reduce the side effect of label noise. However, it remains elusive on how to exploit the causal information to handle the label noise problem. In this paper, by leveraging a structural causal model, we propose a novel generative approach for instance-dependent label-noise learning. In particular, we show that properly modeling the instances will contribute to the identifiability of the label noise transition matrix and thus lead to a better classifier. Empirically, our method outperforms all state-of-the-art methods on both synthetic and real-world label-noise datasets.
Understanding and Improving Early Stopping for Learning with Noisy Labels
Jun 30, 2021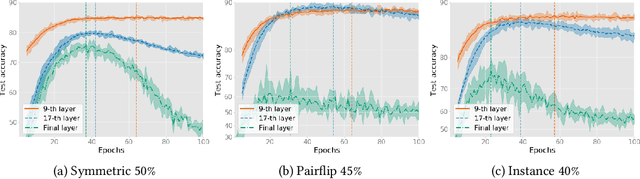
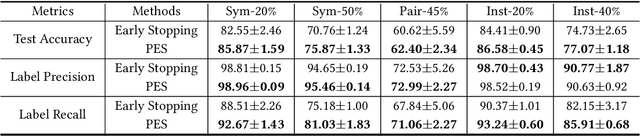
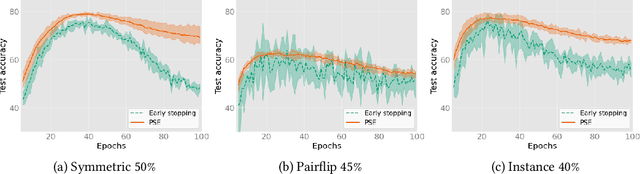
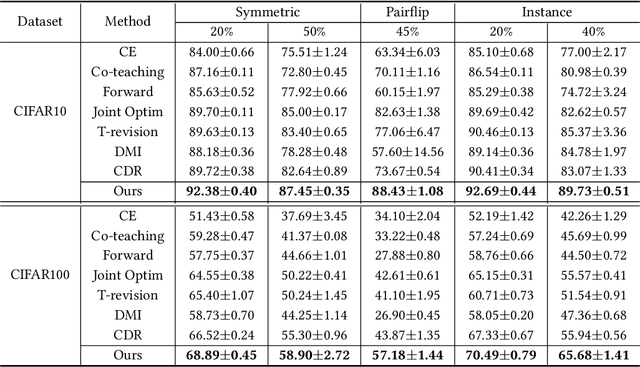
The memorization effect of deep neural network (DNN) plays a pivotal role in many state-of-the-art label-noise learning methods. To exploit this property, the early stopping trick, which stops the optimization at the early stage of training, is usually adopted. Current methods generally decide the early stopping point by considering a DNN as a whole. However, a DNN can be considered as a composition of a series of layers, and we find that the latter layers in a DNN are much more sensitive to label noise, while their former counterparts are quite robust. Therefore, selecting a stopping point for the whole network may make different DNN layers antagonistically affected each other, thus degrading the final performance. In this paper, we propose to separate a DNN into different parts and progressively train them to address this problem. Instead of the early stopping, which trains a whole DNN all at once, we initially train former DNN layers by optimizing the DNN with a relatively large number of epochs. During training, we progressively train the latter DNN layers by using a smaller number of epochs with the preceding layers fixed to counteract the impact of noisy labels. We term the proposed method as progressive early stopping (PES). Despite its simplicity, compared with the early stopping, PES can help to obtain more promising and stable results. Furthermore, by combining PES with existing approaches on noisy label training, we achieve state-of-the-art performance on image classification benchmarks.
Local Reweighting for Adversarial Training
Jun 30, 2021Instances-reweighted adversarial training (IRAT) can significantly boost the robustness of trained models, where data being less/more vulnerable to the given attack are assigned smaller/larger weights during training. However, when tested on attacks different from the given attack simulated in training, the robustness may drop significantly (e.g., even worse than no reweighting). In this paper, we study this problem and propose our solution--locally reweighted adversarial training (LRAT). The rationale behind IRAT is that we do not need to pay much attention to an instance that is already safe under the attack. We argue that the safeness should be attack-dependent, so that for the same instance, its weight can change given different attacks based on the same model. Thus, if the attack simulated in training is mis-specified, the weights of IRAT are misleading. To this end, LRAT pairs each instance with its adversarial variants and performs local reweighting inside each pair, while performing no global reweighting--the rationale is to fit the instance itself if it is immune to the attack, but not to skip the pair, in order to passively defend different attacks in future. Experiments show that LRAT works better than both IRAT (i.e., global reweighting) and the standard AT (i.e., no reweighting) when trained with an attack and tested on different attacks.
Multi-Class Classification from Single-Class Data with Confidences
Jun 16, 2021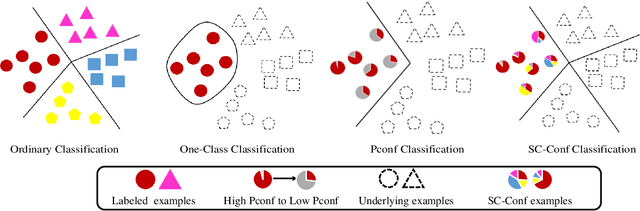
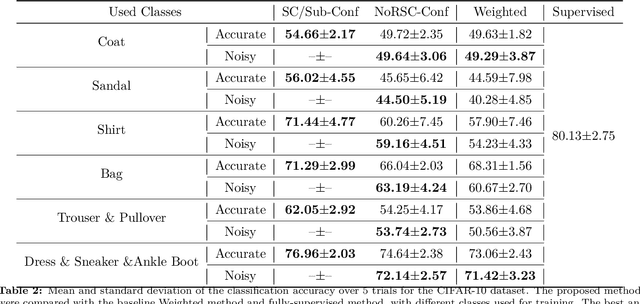
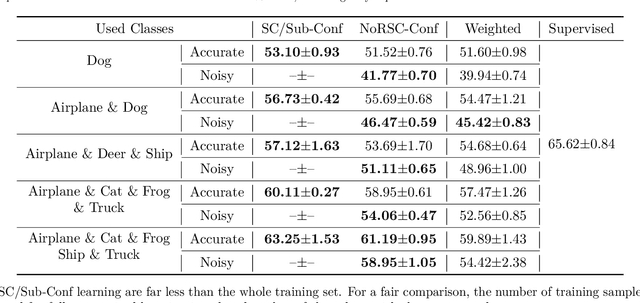
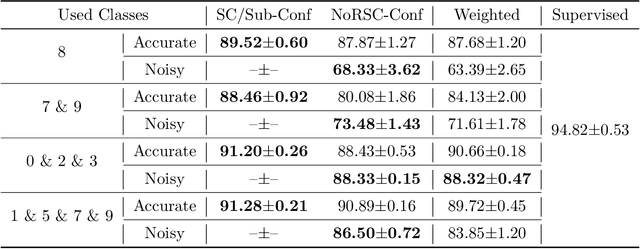
Can we learn a multi-class classifier from only data of a single class? We show that without any assumptions on the loss functions, models, and optimizers, we can successfully learn a multi-class classifier from only data of a single class with a rigorous consistency guarantee when confidences (i.e., the class-posterior probabilities for all the classes) are available. Specifically, we propose an empirical risk minimization framework that is loss-/model-/optimizer-independent. Instead of constructing a boundary between the given class and other classes, our method can conduct discriminative classification between all the classes even if no data from the other classes are provided. We further theoretically and experimentally show that our method can be Bayes-consistent with a simple modification even if the provided confidences are highly noisy. Then, we provide an extension of our method for the case where data from a subset of all the classes are available. Experimental results demonstrate the effectiveness of our methods.
Probabilistic Margins for Instance Reweighting in Adversarial Training
Jun 15, 2021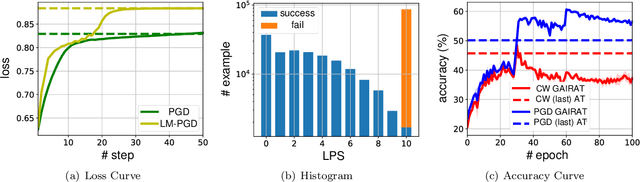
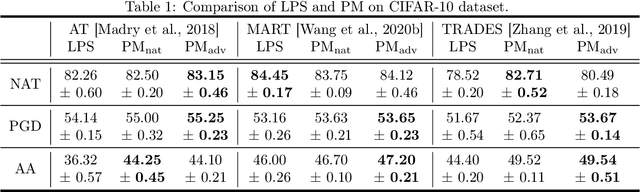
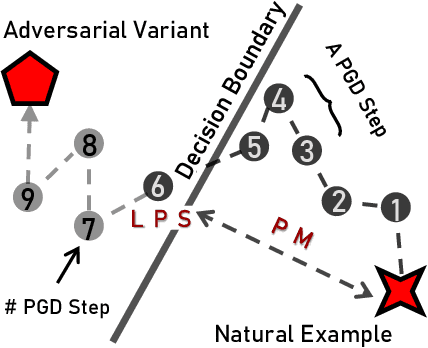
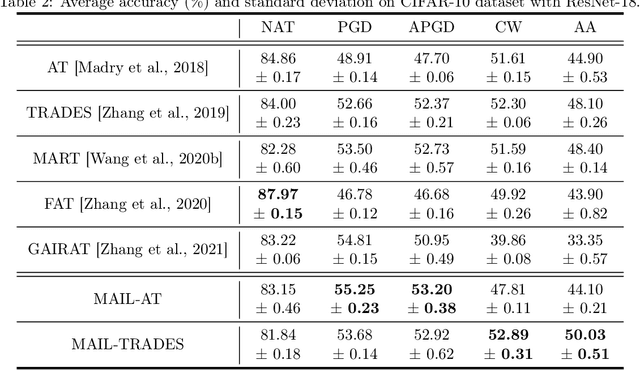
Reweighting adversarial data during training has been recently shown to improve adversarial robustness, where data closer to the current decision boundaries are regarded as more critical and given larger weights. However, existing methods measuring the closeness are not very reliable: they are discrete and can take only a few values, and they are path-dependent, i.e., they may change given the same start and end points with different attack paths. In this paper, we propose three types of probabilistic margin (PM), which are continuous and path-independent, for measuring the aforementioned closeness and reweighting adversarial data. Specifically, a PM is defined as the difference between two estimated class-posterior probabilities, e.g., such the probability of the true label minus the probability of the most confusing label given some natural data. Though different PMs capture different geometric properties, all three PMs share a negative correlation with the vulnerability of data: data with larger/smaller PMs are safer/riskier and should have smaller/larger weights. Experiments demonstrate that PMs are reliable measurements and PM-based reweighting methods outperform state-of-the-art methods.
Adversarial Robustness through the Lens of Causality
Jun 11, 2021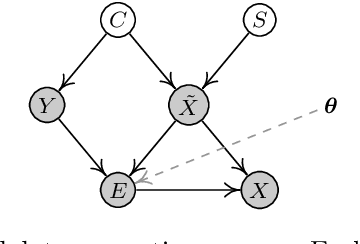
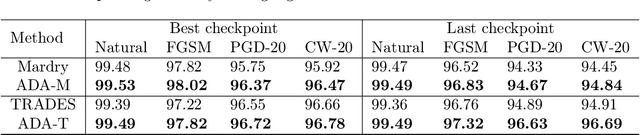
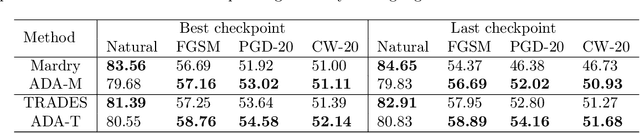
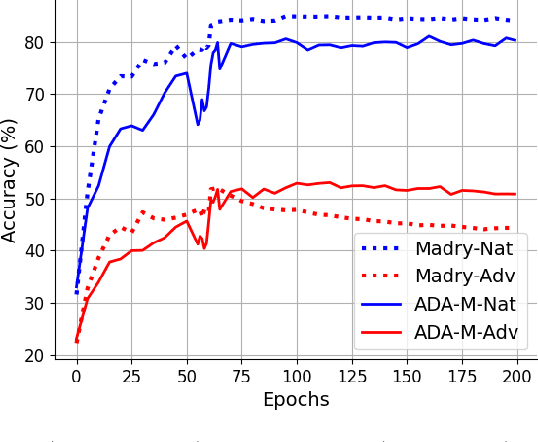
The adversarial vulnerability of deep neural networks has attracted significant attention in machine learning. From a causal viewpoint, adversarial attacks can be considered as a specific type of distribution change on natural data. As causal reasoning has an instinct for modeling distribution change, we propose to incorporate causality into mitigating adversarial vulnerability. However, causal formulations of the intuition of adversarial attack and the development of robust DNNs are still lacking in the literature. To bridge this gap, we construct a causal graph to model the generation process of adversarial examples and define the adversarial distribution to formalize the intuition of adversarial attacks. From a causal perspective, we find that the label is spuriously correlated with the style (content-independent) information when an instance is given. The spurious correlation implies that the adversarial distribution is constructed via making the statistical conditional association between style information and labels drastically different from that in natural distribution. Thus, DNNs that fit the spurious correlation are vulnerable to the adversarial distribution. Inspired by the observation, we propose the adversarial distribution alignment method to eliminate the difference between the natural distribution and the adversarial distribution. Extensive experiments demonstrate the efficacy of the proposed method. Our method can be seen as the first attempt to leverage causality for mitigating adversarial vulnerability.
On the Robustness of Average Losses for Partial-Label Learning
Jun 11, 2021
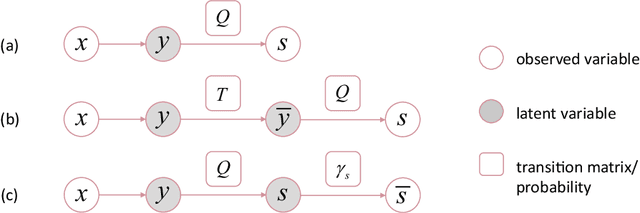
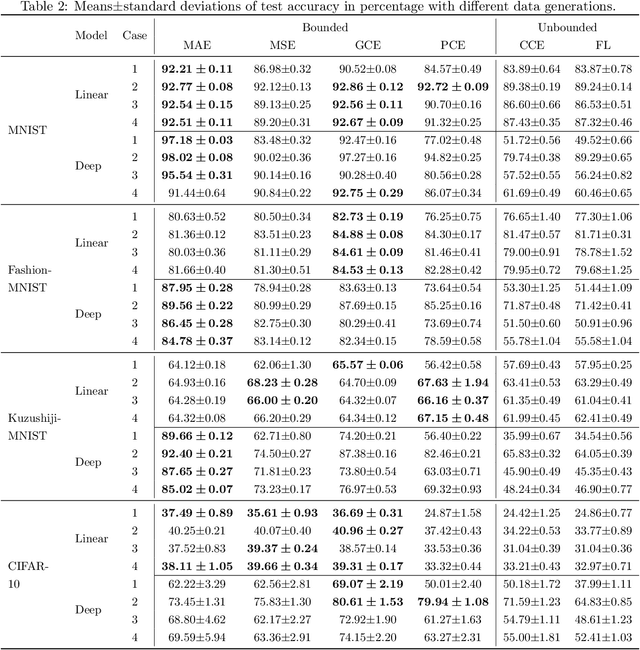
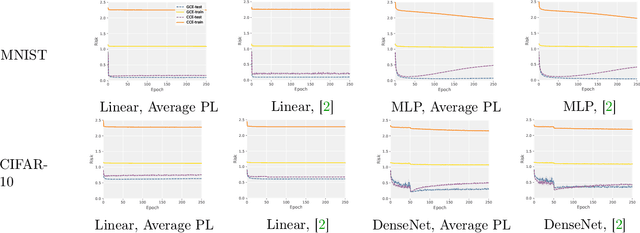
Partial-label (PL) learning is a typical weakly supervised classification problem, where a PL of an instance is a set of candidate labels such that a fixed but unknown candidate is the true label. For PL learning, there are two lines of research: (a) the identification-based strategy (IBS) purifies each label set and extracts the true label; (b) the average-based strategy (ABS) treats all candidates equally for training. In the past two decades, IBS was a much hotter topic than ABS, since it was believed that IBS is more promising. In this paper, we theoretically analyze ABS and find it also promising in the sense of the robustness of its loss functions. Specifically, we consider five problem settings for the generation of clean or noisy PLs, and we prove that average PL losses with bounded multi-class losses are always robust under mild assumptions on the domination of true labels, while average PL losses with unbounded multi-class losses (e.g., the cross-entropy loss) may not be robust. We also conduct experiments to validate our theoretical findings. Note that IBS is heuristic, and we cannot prove its robustness by a similar proof technique; hence, ABS is more advantageous from a theoretical point of view, and it is worth paying attention to the design of more advanced PL learning methods following ABS.
Reliable Adversarial Distillation with Unreliable Teachers
Jun 09, 2021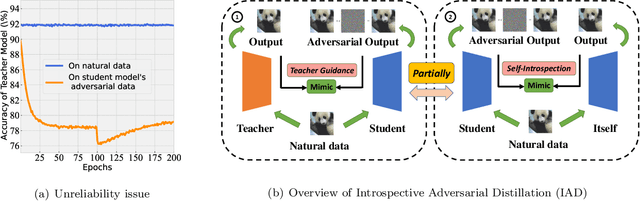
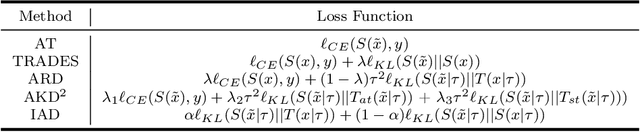
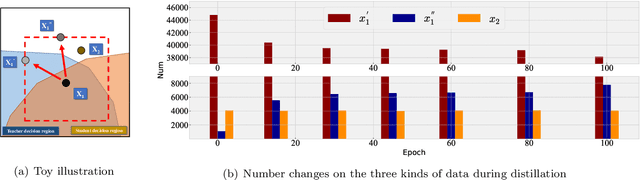
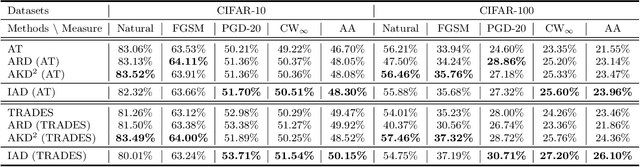
In ordinary distillation, student networks are trained with soft labels (SLs) given by pretrained teacher networks, and students are expected to improve upon teachers since SLs are stronger supervision than the original hard labels. However, when considering adversarial robustness, teachers may become unreliable and adversarial distillation may not work: teachers are pretrained on their own adversarial data, and it is too demanding to require that teachers are also good at every adversarial data queried by students. Therefore, in this paper, we propose reliable introspective adversarial distillation (IAD) where students partially instead of fully trust their teachers. Specifically, IAD distinguishes between three cases given a query of a natural data (ND) and the corresponding adversarial data (AD): (a) if a teacher is good at AD, its SL is fully trusted; (b) if a teacher is good at ND but not AD, its SL is partially trusted and the student also takes its own SL into account; (c) otherwise, the student only relies on its own SL. Experiments demonstrate the effectiveness of IAD for improving upon teachers in terms of adversarial robustness.
Understanding (Generalized) Label Smoothing when Learning with Noisy Labels
Jun 09, 2021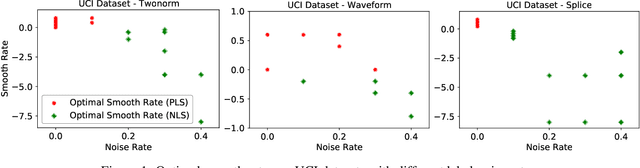
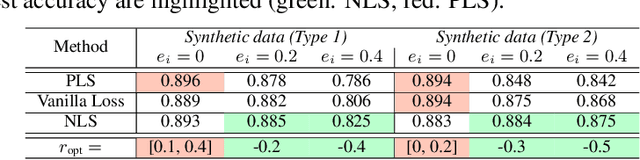
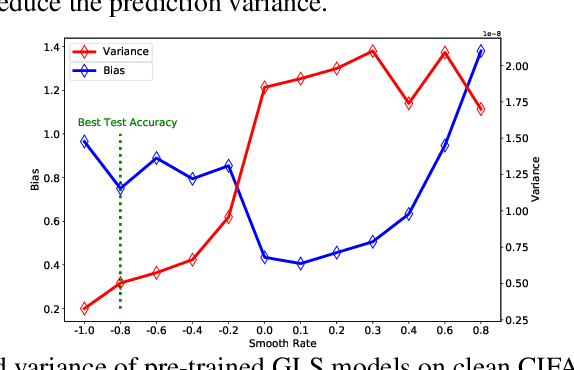
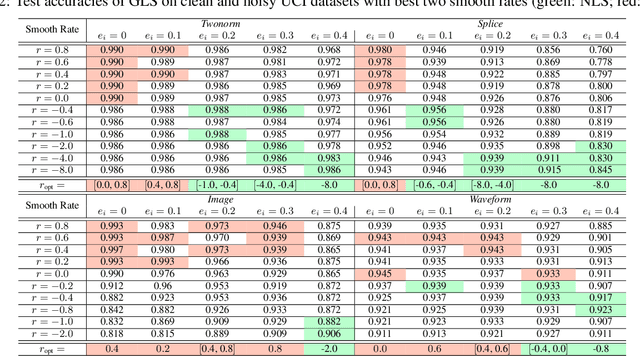
Label smoothing (LS) is an arising learning paradigm that uses the positively weighted average of both the hard training labels and uniformly distributed soft labels. It was shown that LS serves as a regularizer for training data with hard labels and therefore improves the generalization of the model. Later it was reported LS even helps with improving robustness when learning with noisy labels. However, we observe that the advantage of LS vanishes when we operate in a high label noise regime. Puzzled by the observation, we proceeded to discover that several proposed learning-with-noisy-labels solutions in the literature instead relate more closely to negative label smoothing (NLS), which defines as using a negative weight to combine the hard and soft labels! We show that NLS functions substantially differently from LS in their achieved model confidence. To differentiate the two cases, we will call LS the positive label smoothing (PLS), and this paper unifies PLS and NLS into generalized label smoothing (GLS). We provide understandings for the properties of GLS when learning with noisy labels. Among other established properties, we theoretically show NLS is considered more beneficial when the label noise rates are high. We provide experimental results to support our findings too.