 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiversity-Aware Meta Visual Prompting
Mar 14, 2023



We present Diversity-Aware Meta Visual Prompting~(DAM-VP), an efficient and effective prompting method for transferring pre-trained models to downstream tasks with frozen backbone. A challenging issue in visual prompting is that image datasets sometimes have a large data diversity whereas a per-dataset generic prompt can hardly handle the complex distribution shift toward the original pretraining data distribution properly. To address this issue, we propose a dataset Diversity-Aware prompting strategy whose initialization is realized by a Meta-prompt. Specifically, we cluster the downstream dataset into small homogeneity subsets in a diversity-adaptive way, with each subset has its own prompt optimized separately. Such a divide-and-conquer design reduces the optimization difficulty greatly and significantly boosts the prompting performance. Furthermore, all the prompts are initialized with a meta-prompt, which is learned across several datasets. It is a bootstrapped paradigm, with the key observation that the prompting knowledge learned from previous datasets could help the prompt to converge faster and perform better on a new dataset. During inference, we dynamically select a proper prompt for each input, based on the feature distance between the input and each subset. Through extensive experiments, our DAM-VP demonstrates superior efficiency and effectiveness, clearly surpassing previous prompting methods in a series of downstream datasets for different pretraining models. Our code is available at: \url{https://github.com/shikiw/DAM-VP}.
Exploring Discrete Diffusion Models for Image Captioning
Dec 09, 2022



The image captioning task is typically realized by an auto-regressive method that decodes the text tokens one by one. We present a diffusion-based captioning model, dubbed the name DDCap, to allow more decoding flexibility. Unlike image generation, where the output is continuous and redundant with a fixed length, texts in image captions are categorical and short with varied lengths. Therefore, naively applying the discrete diffusion model to text decoding does not work well, as shown in our experiments. To address the performance gap, we propose several key techniques including best-first inference, concentrated attention mask, text length prediction, and image-free training. On COCO without additional caption pre-training, it achieves a CIDEr score of 117.8, which is +5.0 higher than the auto-regressive baseline with the same architecture in the controlled setting. It also performs +26.8 higher CIDEr score than the auto-regressive baseline (230.3 v.s.203.5) on a caption infilling task. With 4M vision-language pre-training images and the base-sized model, we reach a CIDEr score of 125.1 on COCO, which is competitive to the best well-developed auto-regressive frameworks. The code is available at https://github.com/buxiangzhiren/DDCap.
Boosted Dynamic Neural Networks
Nov 30, 2022



Early-exiting dynamic neural networks (EDNN), as one type of dynamic neural networks, has been widely studied recently. A typical EDNN has multiple prediction heads at different layers of the network backbone. During inference, the model will exit at either the last prediction head or an intermediate prediction head where the prediction confidence is higher than a predefined threshold. To optimize the model, these prediction heads together with the network backbone are trained on every batch of training data. This brings a train-test mismatch problem that all the prediction heads are optimized on all types of data in training phase while the deeper heads will only see difficult inputs in testing phase. Treating training and testing inputs differently at the two phases will cause the mismatch between training and testing data distributions. To mitigate this problem, we formulate an EDNN as an additive model inspired by gradient boosting, and propose multiple training techniques to optimize the model effectively. We name our method BoostNet. Our experiments show it achieves the state-of-the-art performance on CIFAR100 and ImageNet datasets in both anytime and budgeted-batch prediction modes. Our code is released at https://github.com/SHI-Labs/Boosted-Dynamic-Networks.
PointCAT: Contrastive Adversarial Training for Robust Point Cloud Recognition
Sep 16, 2022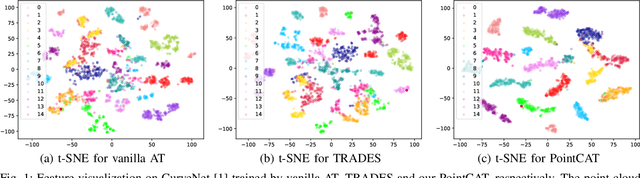
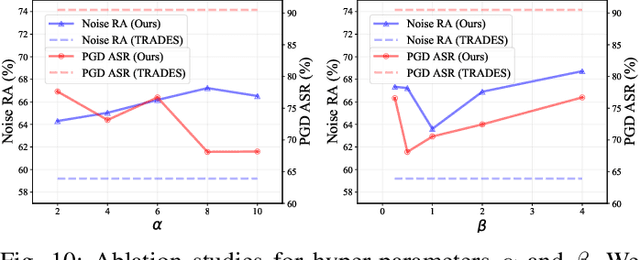
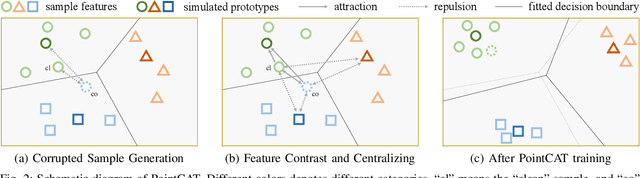
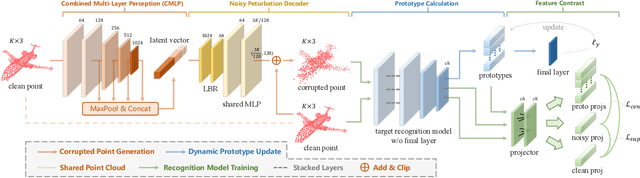
Notwithstanding the prominent performance achieved in various applications, point cloud recognition models have often suffered from natural corruptions and adversarial perturbations. In this paper, we delve into boosting the general robustness of point cloud recognition models and propose Point-Cloud Contrastive Adversarial Training (PointCAT). The main intuition of PointCAT is encouraging the target recognition model to narrow the decision gap between clean point clouds and corrupted point clouds. Specifically, we leverage a supervised contrastive loss to facilitate the alignment and uniformity of the hypersphere features extracted by the recognition model, and design a pair of centralizing losses with the dynamic prototype guidance to avoid these features deviating from their belonging category clusters. To provide the more challenging corrupted point clouds, we adversarially train a noise generator along with the recognition model from the scratch, instead of using gradient-based attack as the inner loop like previous adversarial training methods. Comprehensive experiments show that the proposed PointCAT outperforms the baseline methods and dramatically boosts the robustness of different point cloud recognition models, under a variety of corruptions including isotropic point noises, the LiDAR simulated noises, random point dropping and adversarial perturbations.
Social Interpretable Tree for Pedestrian Trajectory Prediction
May 26, 2022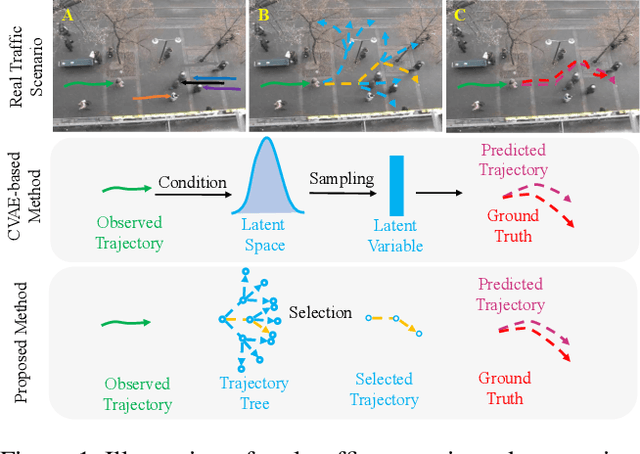
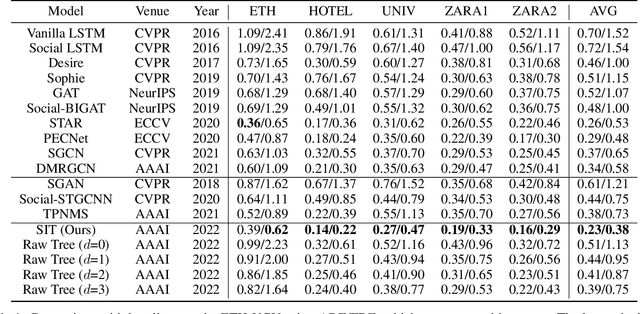
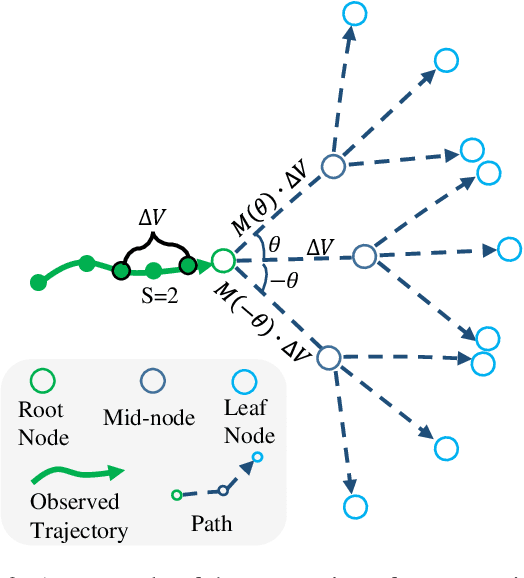
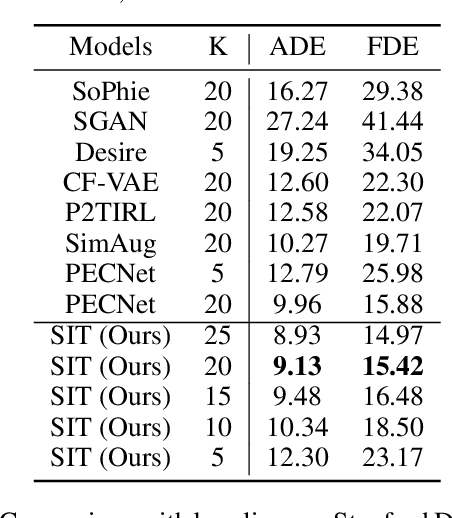
Understanding the multiple socially-acceptable future behaviors is an essential task for many vision applications. In this paper, we propose a tree-based method, termed as Social Interpretable Tree (SIT), to address this multi-modal prediction task, where a hand-crafted tree is built depending on the prior information of observed trajectory to model multiple future trajectories. Specifically, a path in the tree from the root to leaf represents an individual possible future trajectory. SIT employs a coarse-to-fine optimization strategy, in which the tree is first built by high-order velocity to balance the complexity and coverage of the tree and then optimized greedily to encourage multimodality. Finally, a teacher-forcing refining operation is used to predict the final fine trajectory. Compared with prior methods which leverage implicit latent variables to represent possible future trajectories, the path in the tree can explicitly explain the rough moving behaviors (e.g., go straight and then turn right), and thus provides better interpretability. Despite the hand-crafted tree, the experimental results on ETH-UCY and Stanford Drone datasets demonstrate that our method is capable of matching or exceeding the performance of state-of-the-art methods. Interestingly, the experiments show that the raw built tree without training outperforms many prior deep neural network based approaches. Meanwhile, our method presents sufficient flexibility in long-term prediction and different best-of-$K$ predictions.
E^2TAD: An Energy-Efficient Tracking-based Action Detector
Apr 09, 2022

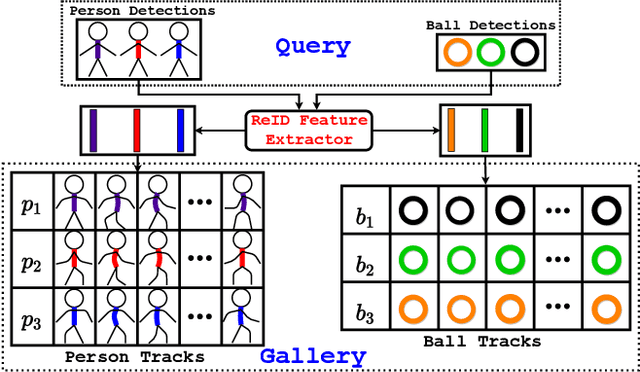
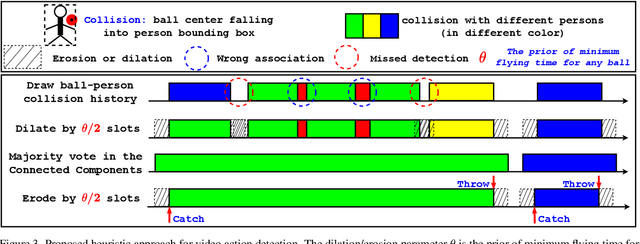
Video action detection (spatio-temporal action localization) is usually the starting point for human-centric intelligent analysis of videos nowadays. It has high practical impacts for many applications across robotics, security, healthcare, etc. The two-stage paradigm of Faster R-CNN inspires a standard paradigm of video action detection in object detection, i.e., firstly generating person proposals and then classifying their actions. However, none of the existing solutions could provide fine-grained action detection to the "who-when-where-what" level. This paper presents a tracking-based solution to accurately and efficiently localize predefined key actions spatially (by predicting the associated target IDs and locations) and temporally (by predicting the time in exact frame indices). This solution won first place in the UAV-Video Track of 2021 Low-Power Computer Vision Challenge (LPCVC).
Implicit Autoencoder for Point Cloud Self-supervised Representation Learning
Jan 03, 2022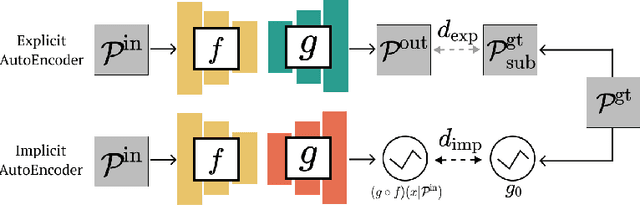
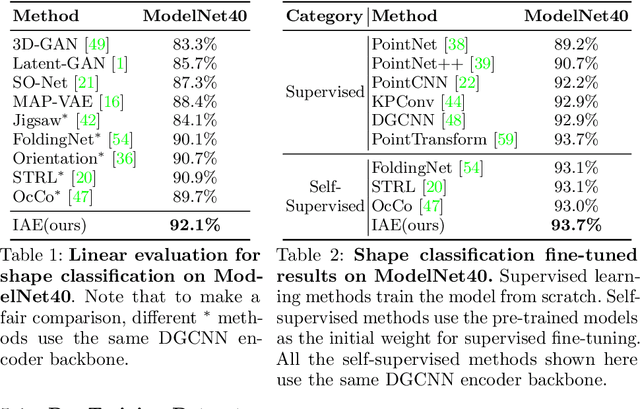
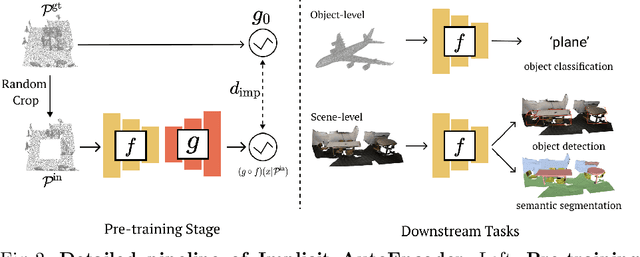

Many 3D representations (e.g., point clouds) are discrete samples of the underlying continuous 3D surface. This process inevitably introduces sampling variations on the underlying 3D shapes. In learning 3D representation, the variations should be disregarded while transferable knowledge of the underlying 3D shape should be captured. This becomes a grand challenge in existing representation learning paradigms. This paper studies autoencoding on point clouds. The standard autoencoding paradigm forces the encoder to capture such sampling variations as the decoder has to reconstruct the original point cloud that has sampling variations. We introduce Implicit Autoencoder(IAE), a simple yet effective method that addresses this challenge by replacing the point cloud decoder with an implicit decoder. The implicit decoder outputs a continuous representation that is shared among different point cloud sampling of the same model. Reconstructing under the implicit representation can prioritize that the encoder discards sampling variations, introducing more space to learn useful features. We theoretically justify this claim under a simple linear autoencoder. Moreover, the implicit decoder offers a rich space to design suitable implicit representations for different tasks. We demonstrate the usefulness of IAE across various self-supervised learning tasks for both 3D objects and 3D scenes. Experimental results show that IAE consistently outperforms the state-of-the-art in each task.
DSSL: Deep Surroundings-person Separation Learning for Text-based Person Retrieval
Sep 12, 2021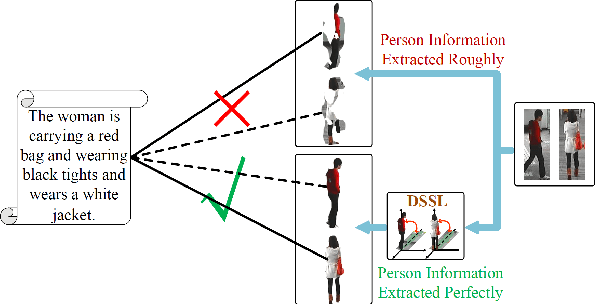

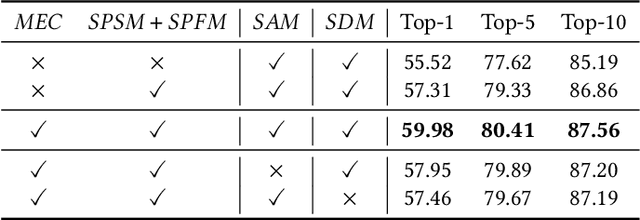
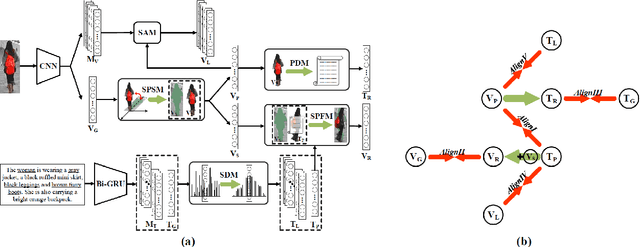
Many previous methods on text-based person retrieval tasks are devoted to learning a latent common space mapping, with the purpose of extracting modality-invariant features from both visual and textual modality. Nevertheless, due to the complexity of high-dimensional data, the unconstrained mapping paradigms are not able to properly catch discriminative clues about the corresponding person while drop the misaligned information. Intuitively, the information contained in visual data can be divided into person information (PI) and surroundings information (SI), which are mutually exclusive from each other. To this end, we propose a novel Deep Surroundings-person Separation Learning (DSSL) model in this paper to effectively extract and match person information, and hence achieve a superior retrieval accuracy. A surroundings-person separation and fusion mechanism plays the key role to realize an accurate and effective surroundings-person separation under a mutually exclusion constraint. In order to adequately utilize multi-modal and multi-granular information for a higher retrieval accuracy, five diverse alignment paradigms are adopted. Extensive experiments are carried out to evaluate the proposed DSSL on CUHK-PEDES, which is currently the only accessible dataset for text-base person retrieval task. DSSL achieves the state-of-the-art performance on CUHK-PEDES. To properly evaluate our proposed DSSL in the real scenarios, a Real Scenarios Text-based Person Reidentification (RSTPReid) dataset is constructed to benefit future research on text-based person retrieval, which will be publicly available.
Unlimited Neighborhood Interaction for Heterogeneous Trajectory Prediction
Aug 16, 2021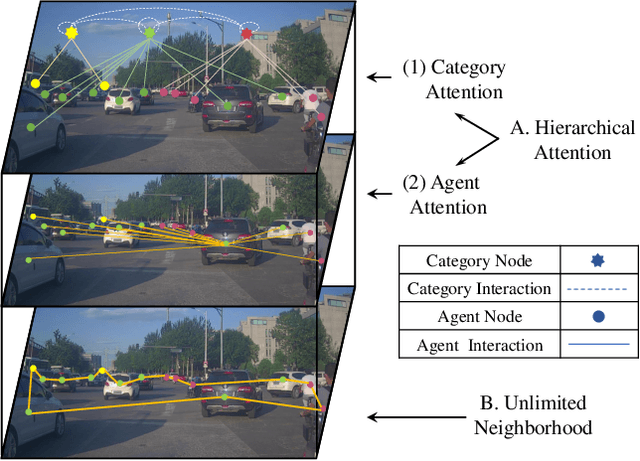
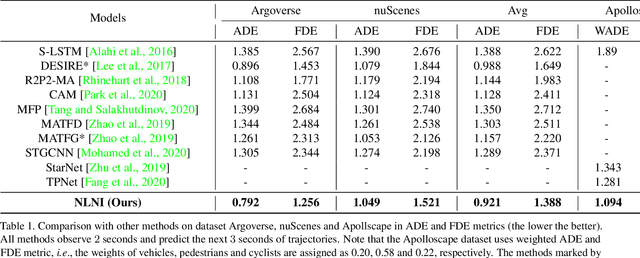
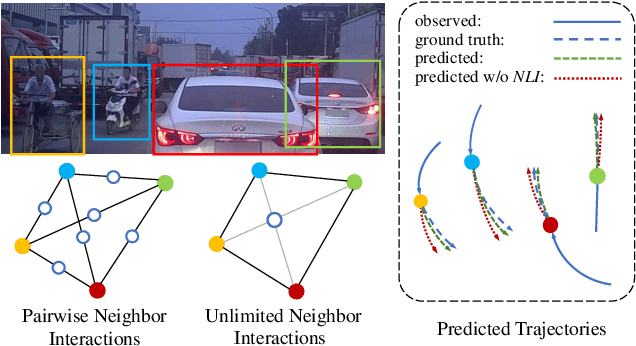
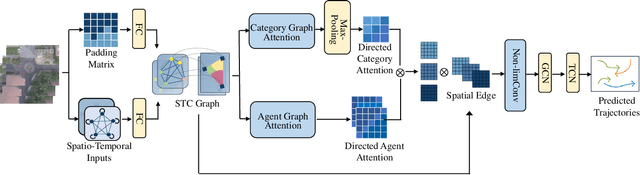
Understanding complex social interactions among agents is a key challenge for trajectory prediction. Most existing methods consider the interactions between pairwise traffic agents or in a local area, while the nature of interactions is unlimited, involving an uncertain number of agents and non-local areas simultaneously. Besides, they treat heterogeneous traffic agents the same, namely those among agents of different categories, while neglecting people's diverse reaction patterns toward traffic agents in ifferent categories. To address these problems, we propose a simple yet effective Unlimited Neighborhood Interaction Network (UNIN), which predicts trajectories of heterogeneous agents in multiple categories. Specifically, the proposed unlimited neighborhood interaction module generates the fused-features of all agents involved in an interaction simultaneously, which is adaptive to any number of agents and any range of interaction area. Meanwhile, a hierarchical graph attention module is proposed to obtain category-to-category interaction and agent-to-agent interaction. Finally, parameters of a Gaussian Mixture Model are estimated for generating the future trajectories. Extensive experimental results on benchmark datasets demonstrate a significant performance improvement of our method over the state-of-the-art methods.
Poison Ink: Robust and Invisible Backdoor Attack
Aug 14, 2021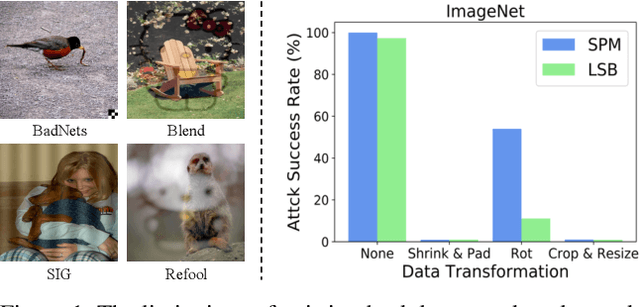
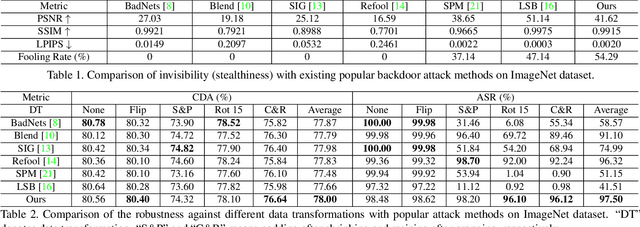
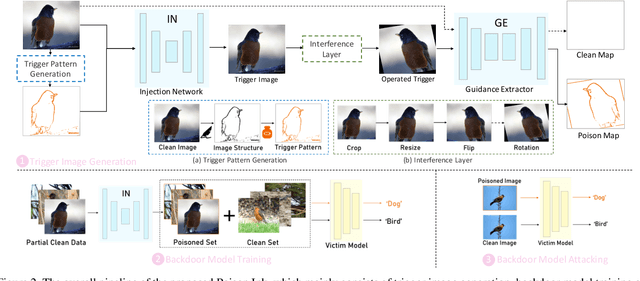

Recent research shows deep neural networks are vulnerable to different types of attacks, such as adversarial attack, data poisoning attack and backdoor attack. Among them, backdoor attack is the most cunning one and can occur in almost every stage of deep learning pipeline. Therefore, backdoor attack has attracted lots of interests from both academia and industry. However, most existing backdoor attack methods are either visible or fragile to some effortless pre-processing such as common data transformations. To address these limitations, we propose a robust and invisible backdoor attack called "Poison Ink". Concretely, we first leverage the image structures as target poisoning areas, and fill them with poison ink (information) to generate the trigger pattern. As the image structure can keep its semantic meaning during the data transformation, such trigger pattern is inherently robust to data transformations. Then we leverage a deep injection network to embed such trigger pattern into the cover image to achieve stealthiness. Compared to existing popular backdoor attack methods, Poison Ink outperforms both in stealthiness and robustness. Through extensive experiments, we demonstrate Poison Ink is not only general to different datasets and network architectures, but also flexible for different attack scenarios. Besides, it also has very strong resistance against many state-of-the-art defense techniques.