 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGS4City: Hierarchical Semantic Gaussian Splatting via City-Model Priors
Apr 13, 2026Recent semantic 3D Gaussian Splatting (3DGS) methods primarily rely on 2D foundation models, often yielding ambiguous boundaries and limited support for structured urban semantics. While city models such as CityGML encode hierarchically organized semantics together with building geometry, these labels cannot be directly mapped to Gaussian primitives. We present GS4City, a hierarchical semantic Gaussian Splatting method that incorporates city-model priors for urban scene understanding. GS4City derives reliable image-aligned masks from Level of Detail (LoD) 3 CityGML models via two-pass raycasting, explicitly using parent-child relations to validate and recover fine-grained facade elements. It then fuses these geometry-grounded masks with foundation-model predictions to establish scene-consistent instance correspondences, and learns a compact identity encoding for each Gaussian under joint 2D identity supervision and 3D spatial regularization. Experiments on the TUM2TWIN and Gold Coast datasets show that GS4City effectively incorporates structured building semantics into Gaussian scene representations, outperforming existing 2D-driven semantic 3DGS baselines, including LangSplat and Gaga, by up to 15.8 IoU points in coarse building segmentation and 14.2 mIoU points in fine-grained semantic segmentation. By bridging structured city models and photorealistic Gaussian scene representations, GS4City enables semantically queryable and structure-aware urban reconstruction. Code is available at https://github.com/Jinyzzz/GS4City.
VLM-Loc: Localization in Point Cloud Maps via Vision-Language Models
Mar 10, 2026Text-to-point-cloud (T2P) localization aims to infer precise spatial positions within 3D point cloud maps from natural language descriptions, reflecting how humans perceive and communicate spatial layouts through language. However, existing methods largely rely on shallow text-point cloud correspondence without effective spatial reasoning, limiting their accuracy in complex environments. To address this limitation, we propose VLM-Loc, a framework that leverages the spatial reasoning capability of large vision-language models (VLMs) for T2P localization. Specifically, we transform point clouds into bird's-eye-view (BEV) images and scene graphs that jointly encode geometric and semantic context, providing structured inputs for the VLM to learn cross-modal representations bridging linguistic and spatial semantics. On top of these representations, we introduce a partial node assignment mechanism that explicitly associates textual cues with scene graph nodes, enabling interpretable spatial reasoning for accurate localization. To facilitate systematic evaluation across diverse scenes, we present CityLoc, a benchmark built from multi-source point clouds for fine-grained T2P localization. Experiments on CityLoc demonstrate VLM-Loc achieves superior accuracy and robustness compared to state-of-the-art methods. Our code, model, and dataset are available at \href{https://github.com/MCG-NKU/nku-3d-vision}{repository}.
TrueCity: Real and Simulated Urban Data for Cross-Domain 3D Scene Understanding
Nov 10, 2025



3D semantic scene understanding remains a long-standing challenge in the 3D computer vision community. One of the key issues pertains to limited real-world annotated data to facilitate generalizable models. The common practice to tackle this issue is to simulate new data. Although synthetic datasets offer scalability and perfect labels, their designer-crafted scenes fail to capture real-world complexity and sensor noise, resulting in a synthetic-to-real domain gap. Moreover, no benchmark provides synchronized real and simulated point clouds for segmentation-oriented domain shift analysis. We introduce TrueCity, the first urban semantic segmentation benchmark with cm-accurate annotated real-world point clouds, semantic 3D city models, and annotated simulated point clouds representing the same city. TrueCity proposes segmentation classes aligned with international 3D city modeling standards, enabling consistent evaluation of synthetic-to-real gap. Our extensive experiments on common baselines quantify domain shift and highlight strategies for exploiting synthetic data to enhance real-world 3D scene understanding. We are convinced that the TrueCity dataset will foster further development of sim-to-real gap quantification and enable generalizable data-driven models. The data, code, and 3D models are available online: https://tum-gis.github.io/TrueCity/
GS4Buildings: Prior-Guided Gaussian Splatting for 3D Building Reconstruction
Aug 10, 2025
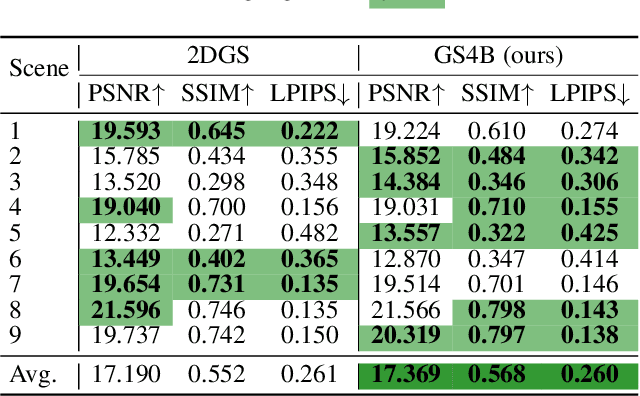
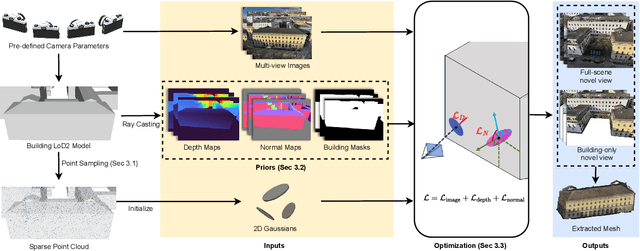

Recent advances in Gaussian Splatting (GS) have demonstrated its effectiveness in photo-realistic rendering and 3D reconstruction. Among these, 2D Gaussian Splatting (2DGS) is particularly suitable for surface reconstruction due to its flattened Gaussian representation and integrated normal regularization. However, its performance often degrades in large-scale and complex urban scenes with frequent occlusions, leading to incomplete building reconstructions. We propose GS4Buildings, a novel prior-guided Gaussian Splatting method leveraging the ubiquity of semantic 3D building models for robust and scalable building surface reconstruction. Instead of relying on traditional Structure-from-Motion (SfM) pipelines, GS4Buildings initializes Gaussians directly from low-level Level of Detail (LoD)2 semantic 3D building models. Moreover, we generate prior depth and normal maps from the planar building geometry and incorporate them into the optimization process, providing strong geometric guidance for surface consistency and structural accuracy. We also introduce an optional building-focused mode that limits reconstruction to building regions, achieving a 71.8% reduction in Gaussian primitives and enabling a more efficient and compact representation. Experiments on urban datasets demonstrate that GS4Buildings improves reconstruction completeness by 20.5% and geometric accuracy by 32.8%. These results highlight the potential of semantic building model integration to advance GS-based reconstruction toward real-world urban applications such as smart cities and digital twins. Our project is available: https://github.com/zqlin0521/GS4Buildings.
To Glue or Not to Glue? Classical vs Learned Image Matching for Mobile Mapping Cameras to Textured Semantic 3D Building Models
May 23, 2025



Feature matching is a necessary step for many computer vision and photogrammetry applications such as image registration, structure-from-motion, and visual localization. Classical handcrafted methods such as SIFT feature detection and description combined with nearest neighbour matching and RANSAC outlier removal have been state-of-the-art for mobile mapping cameras. With recent advances in deep learning, learnable methods have been introduced and proven to have better robustness and performance under complex conditions. Despite their growing adoption, a comprehensive comparison between classical and learnable feature matching methods for the specific task of semantic 3D building camera-to-model matching is still missing. This submission systematically evaluates the effectiveness of different feature-matching techniques in visual localization using textured CityGML LoD2 models. We use standard benchmark datasets (HPatches, MegaDepth-1500) and custom datasets consisting of facade textures and corresponding camera images (terrestrial and drone). For the latter, we evaluate the achievable accuracy of the absolute pose estimated using a Perspective-n-Point (PnP) algorithm, with geometric ground truth derived from geo-referenced trajectory data. The results indicate that the learnable feature matching methods vastly outperform traditional approaches regarding accuracy and robustness on our challenging custom datasets with zero to 12 RANSAC-inliers and zero to 0.16 area under the curve. We believe that this work will foster the development of model-based visual localization methods. Link to the code: https://github.com/simBauer/To\_Glue\_or\_not\_to\_Glue
TUM2TWIN: Introducing the Large-Scale Multimodal Urban Digital Twin Benchmark Dataset
May 13, 2025



Urban Digital Twins (UDTs) have become essential for managing cities and integrating complex, heterogeneous data from diverse sources. Creating UDTs involves challenges at multiple process stages, including acquiring accurate 3D source data, reconstructing high-fidelity 3D models, maintaining models' updates, and ensuring seamless interoperability to downstream tasks. Current datasets are usually limited to one part of the processing chain, hampering comprehensive UDTs validation. To address these challenges, we introduce the first comprehensive multimodal Urban Digital Twin benchmark dataset: TUM2TWIN. This dataset includes georeferenced, semantically aligned 3D models and networks along with various terrestrial, mobile, aerial, and satellite observations boasting 32 data subsets over roughly 100,000 $m^2$ and currently 767 GB of data. By ensuring georeferenced indoor-outdoor acquisition, high accuracy, and multimodal data integration, the benchmark supports robust analysis of sensors and the development of advanced reconstruction methods. Additionally, we explore downstream tasks demonstrating the potential of TUM2TWIN, including novel view synthesis of NeRF and Gaussian Splatting, solar potential analysis, point cloud semantic segmentation, and LoD3 building reconstruction. We are convinced this contribution lays a foundation for overcoming current limitations in UDT creation, fostering new research directions and practical solutions for smarter, data-driven urban environments. The project is available under: https://tum2t.win
CDGS: Confidence-Aware Depth Regularization for 3D Gaussian Splatting
Feb 20, 20253D Gaussian Splatting (3DGS) has shown significant advantages in novel view synthesis (NVS), particularly in achieving high rendering speeds and high-quality results. However, its geometric accuracy in 3D reconstruction remains limited due to the lack of explicit geometric constraints during optimization. This paper introduces CDGS, a confidence-aware depth regularization approach developed to enhance 3DGS. We leverage multi-cue confidence maps of monocular depth estimation and sparse Structure-from-Motion depth to adaptively adjust depth supervision during the optimization process. Our method demonstrates improved geometric detail preservation in early training stages and achieves competitive performance in both NVS quality and geometric accuracy. Experiments on the publicly available Tanks and Temples benchmark dataset show that our method achieves more stable convergence behavior and more accurate geometric reconstruction results, with improvements of up to 2.31 dB in PSNR for NVS and consistently lower geometric errors in M3C2 distance metrics. Notably, our method reaches comparable F-scores to the original 3DGS with only 50% of the training iterations. We expect this work will facilitate the development of efficient and accurate 3D reconstruction systems for real-world applications such as digital twin creation, heritage preservation, or forestry applications.
Adversarial Attack and Defense in Deep Ranking
Jun 07, 2021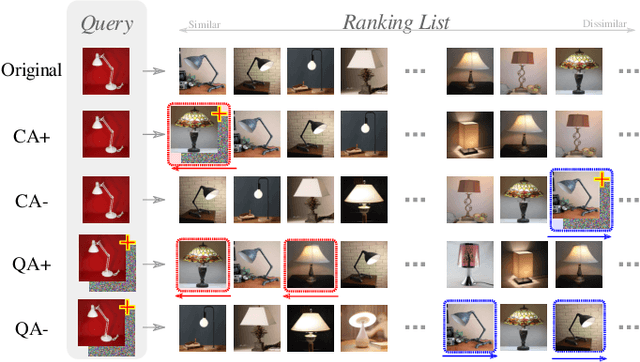
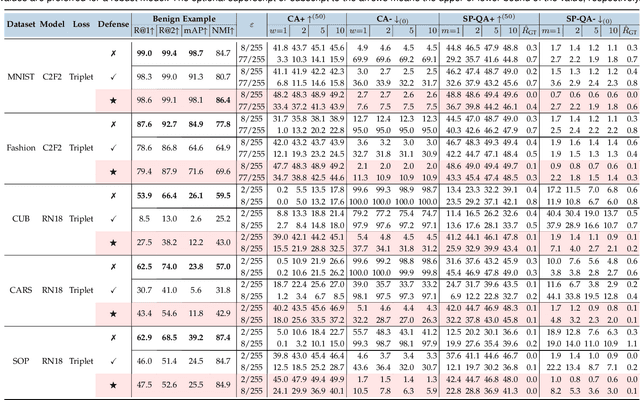
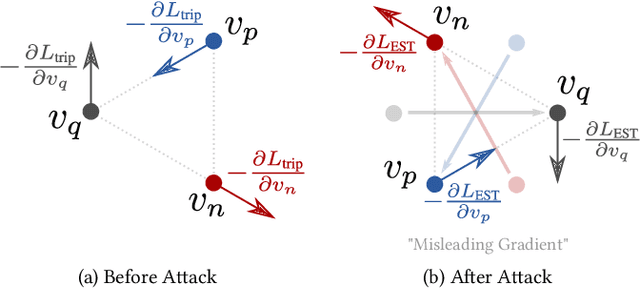
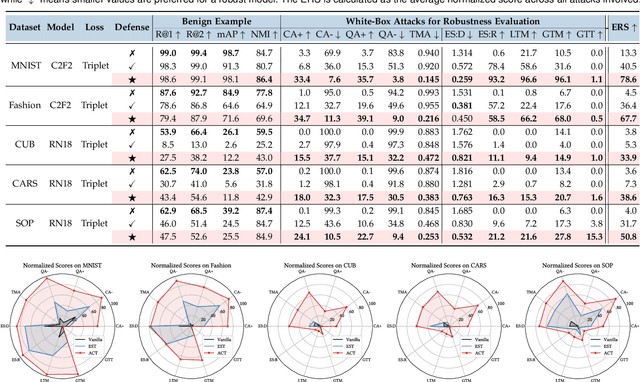
Deep Neural Network classifiers are vulnerable to adversarial attack, where an imperceptible perturbation could result in misclassification. However, the vulnerability of DNN-based image ranking systems remains under-explored. In this paper, we propose two attacks against deep ranking systems, i.e., Candidate Attack and Query Attack, that can raise or lower the rank of chosen candidates by adversarial perturbations. Specifically, the expected ranking order is first represented as a set of inequalities, and then a triplet-like objective function is designed to obtain the optimal perturbation. Conversely, an anti-collapse triplet defense is proposed to improve the ranking model robustness against all proposed attacks, where the model learns to prevent the positive and negative samples being pulled close to each other by adversarial attack. To comprehensively measure the empirical adversarial robustness of a ranking model with our defense, we propose an empirical robustness score, which involves a set of representative attacks against ranking models. Our adversarial ranking attacks and defenses are evaluated on MNIST, Fashion-MNIST, CUB200-2011, CARS196 and Stanford Online Products datasets. Experimental results demonstrate that a typical deep ranking system can be effectively compromised by our attacks. Nevertheless, our defense can significantly improve the ranking system robustness, and simultaneously mitigate a wide range of attacks.
ACSNet: Action-Context Separation Network for Weakly Supervised Temporal Action Localization
Mar 28, 2021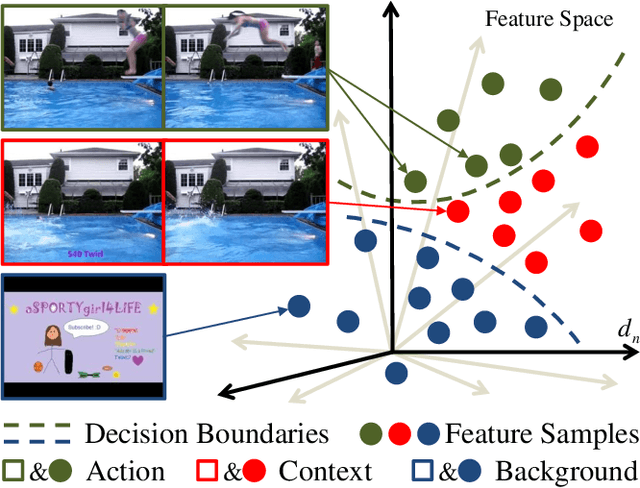
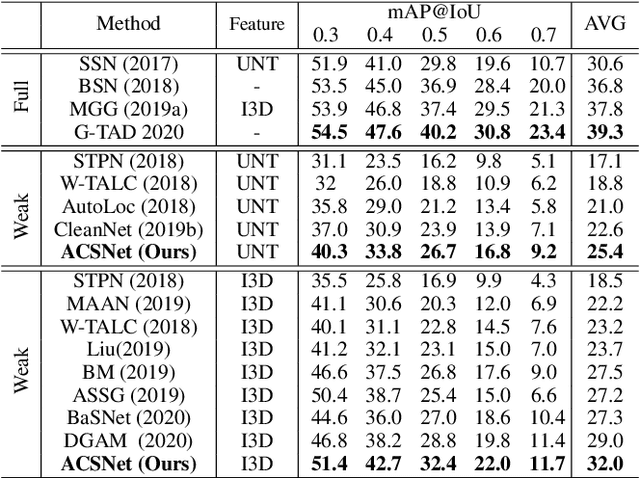
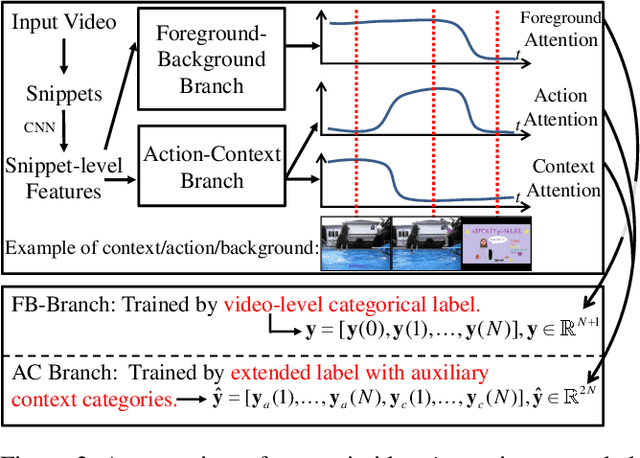
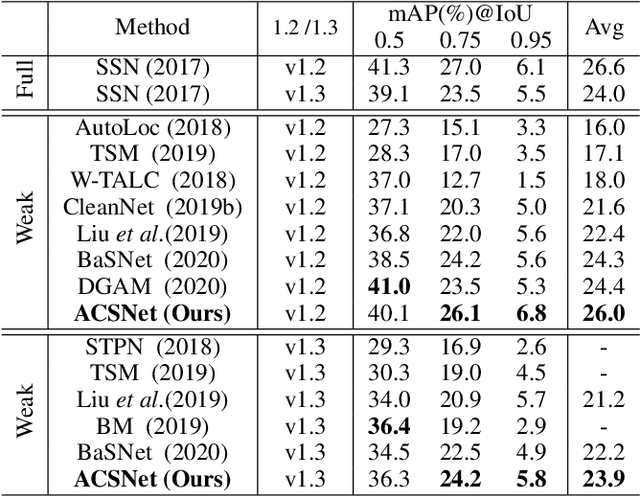
The object of Weakly-supervised Temporal Action Localization (WS-TAL) is to localize all action instances in an untrimmed video with only video-level supervision. Due to the lack of frame-level annotations during training, current WS-TAL methods rely on attention mechanisms to localize the foreground snippets or frames that contribute to the video-level classification task. This strategy frequently confuse context with the actual action, in the localization result. Separating action and context is a core problem for precise WS-TAL, but it is very challenging and has been largely ignored in the literature. In this paper, we introduce an Action-Context Separation Network (ACSNet) that explicitly takes into account context for accurate action localization. It consists of two branches (i.e., the Foreground-Background branch and the Action-Context branch). The Foreground- Background branch first distinguishes foreground from background within the entire video while the Action-Context branch further separates the foreground as action and context. We associate video snippets with two latent components (i.e., a positive component and a negative component), and their different combinations can effectively characterize foreground, action and context. Furthermore, we introduce extended labels with auxiliary context categories to facilitate the learning of action-context separation. Experiments on THUMOS14 and ActivityNet v1.2/v1.3 datasets demonstrate the ACSNet outperforms existing state-of-the-art WS-TAL methods by a large margin.
Practical Relative Order Attack in Deep Ranking
Mar 20, 2021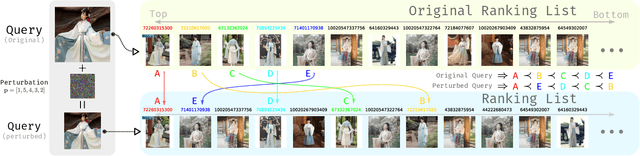

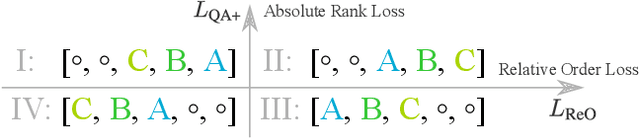
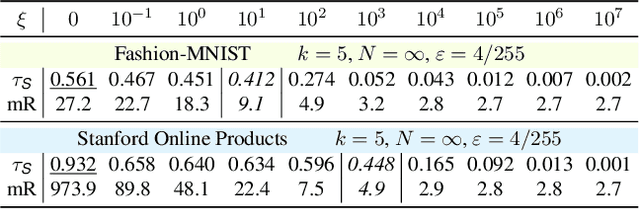
Recent studies unveil the vulnerabilities of deep ranking models, where an imperceptible perturbation can trigger dramatic changes in the ranking result. While previous attempts focus on manipulating absolute ranks of certain candidates, the possibility of adjusting their relative order remains under-explored. In this paper, we formulate a new adversarial attack against deep ranking systems, i.e., the Order Attack, which covertly alters the relative order among a selected set of candidates according to an attacker-specified permutation, with limited interference to other unrelated candidates. Specifically, it is formulated as a triplet-style loss imposing an inequality chain reflecting the specified permutation. However, direct optimization of such white-box objective is infeasible in a real-world attack scenario due to various black-box limitations. To cope with them, we propose a Short-range Ranking Correlation metric as a surrogate objective for black-box Order Attack to approximate the white-box method. The Order Attack is evaluated on the Fashion-MNIST and Stanford-Online-Products datasets under both white-box and black-box threat models. The black-box attack is also successfully implemented on a major e-commerce platform. Comprehensive experimental evaluations demonstrate the effectiveness of the proposed methods, revealing a new type of ranking model vulnerability.