 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTailorSQL: An NL2SQL System Tailored to Your Query Workload
May 29, 2025NL2SQL (natural language to SQL) translates natural language questions into SQL queries, thereby making structured data accessible to non-technical users, serving as the foundation for intelligent data applications. State-of-the-art NL2SQL techniques typically perform translation by retrieving database-specific information, such as the database schema, and invoking a pre-trained large language model (LLM) using the question and retrieved information to generate the SQL query. However, existing NL2SQL techniques miss a key opportunity which is present in real-world settings: NL2SQL is typically applied on existing databases which have already served many SQL queries in the past. The past query workload implicitly contains information which is helpful for accurate NL2SQL translation and is not apparent from the database schema alone, such as common join paths and the semantics of obscurely-named tables and columns. We introduce TailorSQL, a NL2SQL system that takes advantage of information in the past query workload to improve both the accuracy and latency of translating natural language questions into SQL. By specializing to a given workload, TailorSQL achieves up to 2$\times$ improvement in execution accuracy on standardized benchmarks.
Assaying Out-Of-Distribution Generalization in Transfer Learning
Jul 19, 2022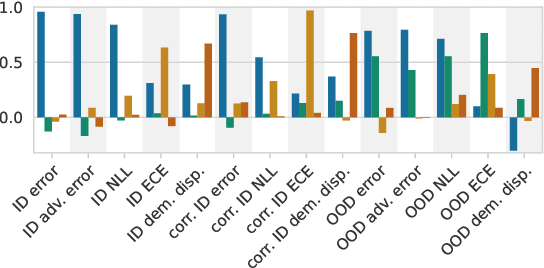
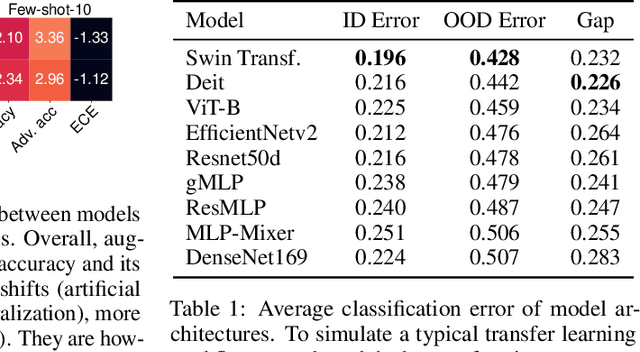
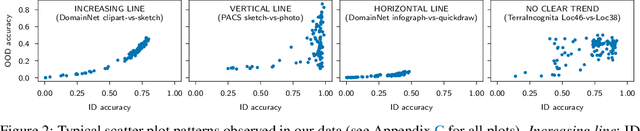
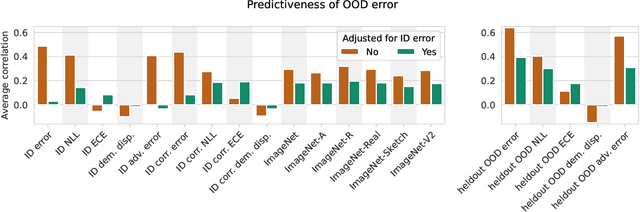
Since out-of-distribution generalization is a generally ill-posed problem, various proxy targets (e.g., calibration, adversarial robustness, algorithmic corruptions, invariance across shifts) were studied across different research programs resulting in different recommendations. While sharing the same aspirational goal, these approaches have never been tested under the same experimental conditions on real data. In this paper, we take a unified view of previous work, highlighting message discrepancies that we address empirically, and providing recommendations on how to measure the robustness of a model and how to improve it. To this end, we collect 172 publicly available dataset pairs for training and out-of-distribution evaluation of accuracy, calibration error, adversarial attacks, environment invariance, and synthetic corruptions. We fine-tune over 31k networks, from nine different architectures in the many- and few-shot setting. Our findings confirm that in- and out-of-distribution accuracies tend to increase jointly, but show that their relation is largely dataset-dependent, and in general more nuanced and more complex than posited by previous, smaller scale studies.
Testing Granger Non-Causality in Panels with Cross-Sectional Dependencies
Feb 23, 2022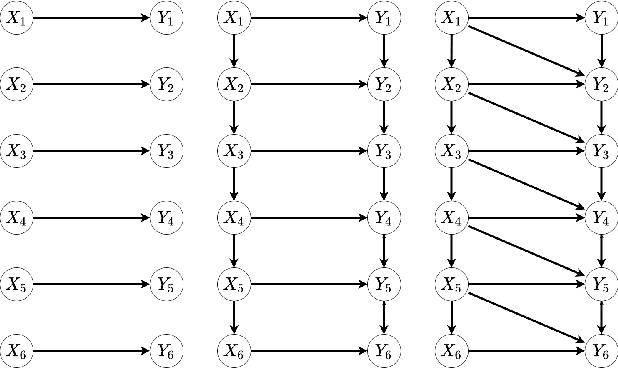
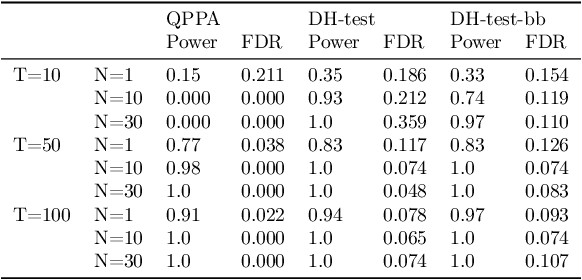
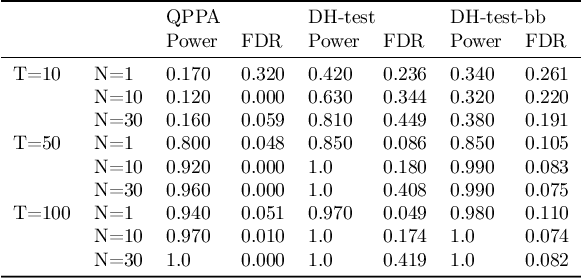
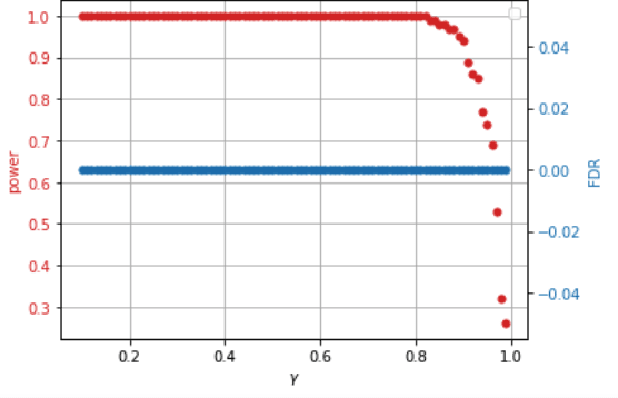
This paper proposes a new approach for testing Granger non-causality on panel data. Instead of aggregating panel member statistics, we aggregate their corresponding p-values and show that the resulting p-value approximately bounds the type I error by the chosen significance level even if the panel members are dependent. We compare our approach against the most widely used Granger causality algorithm on panel data and show that our approach yields lower FDR at the same power for large sample sizes and panels with cross-sectional dependencies. Finally, we examine COVID-19 data about confirmed cases and deaths measured in countries/regions worldwide and show that our approach is able to discover the true causal relation between confirmed cases and deaths while state-of-the-art approaches fail.